夜雨聆风
夜雨聆风





昇腾以AICore为中心的DeepEP细粒度并行实践:基于超节点的细粒度乱序优化

DeepSeek的创新风暴带来了丰富的高价值洞察与技术分享,我们从业务和开发者的视角分享Ascend-DeepEP的实践经验,为昇腾上的性能优化提供一种参考路径——AICore细粒度并行,重点介绍昇腾Atlas A3 SuperPoD液冷超节点及Atlas 800 A3风冷超节点上Ascend- DeepEP的案例实践,以及AICore细粒度性能分析方法。
以AICore细粒度并行为中心,以DeepEP大融合算子优化为主线,针对昇腾的硬件微架构特征,Token细粒度乱序的软硬协同设计可以突破大同步范式的串行依赖,较粗粒度基线性能提升47%。
Atlas A3 SuperPoD液冷超节点及Atlas 800 A3风冷超节点Token细粒度乱序实践
背景和瓶颈
超节点凭借HCCS互联能力,能够支持大规模EP集群通信,Dispatch算子天然适合采用Mesh算法。同时,HCCS支持全局地址统一的共享内存,通信无需类似RDMA通信的SendBuffer与RecvBuffer数据拷贝。基于Dispatch算子整体流程,以粗粒度并行版本为例:在算子总耗时84us中,AICore实际数据传输仅仅17us(占比仅20%),数据传输的Flag发送与校验耗时最高达37.5us,发送端与接收端的地址计算(cumSum)耗时约15us,OutputBuffer的Token重排耗时为12us。
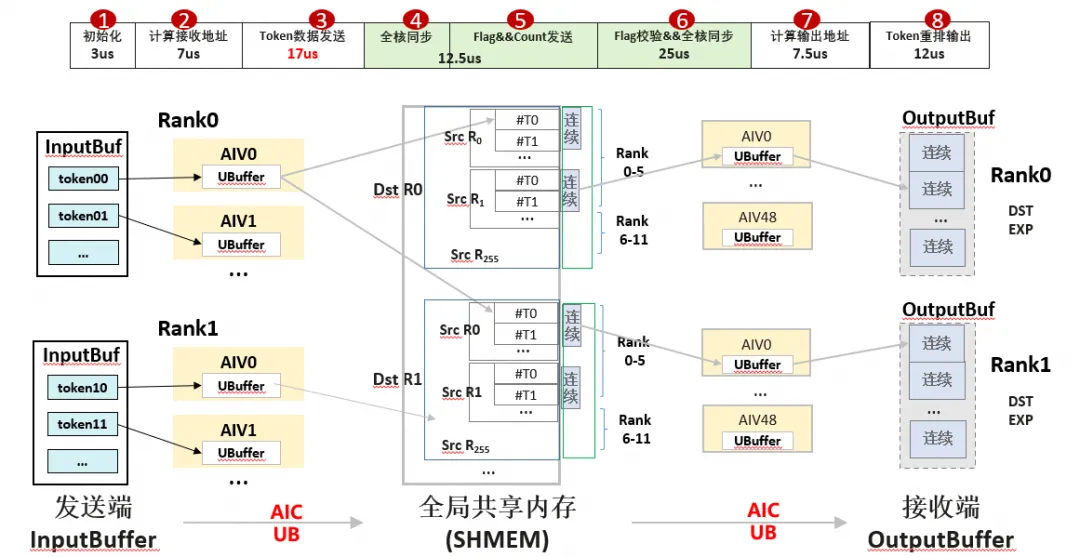
Dispatch数据排布可以分为三阶段:InputBuffer(按Token稠密)→SHMEM(按专家稀疏)→OutputBuffer(按专家稠密)。以下重点分析各子过程的并行策略与同步开销:
数据发送阶段(上图阶段3):数据发送按Token分核(BS/aivNum),每个AICore负责部分Token。由于每个Token需发往topK个专家,每个AICore会将Token发送至多个专家,而每个专家也会接收来自多个AICore的数据。
Flag发送阶段(上图阶段4-5):为确保Flag在所有Token数据发送完成后才发出,通过数据发送阶段后插入SyncAll操作,确定所有核均发送完成后,负责发送Flag的核向对应专家发送Flag同步信号;
Flag接收阶段(上图阶段6):Flag校验同样按专家分核并行,每个AICore负责部分源端数据的校验,然后通过SyncAll以保其他核也完成Flag校验,以保证数据正确性。
综合以上过程,Dispatch算子的性能瓶颈有以下原因:核间同步过多、Flag校验开销大、地址计算耗时长、以及最重要的一点——BSP大同步强行阻塞各个子过程。
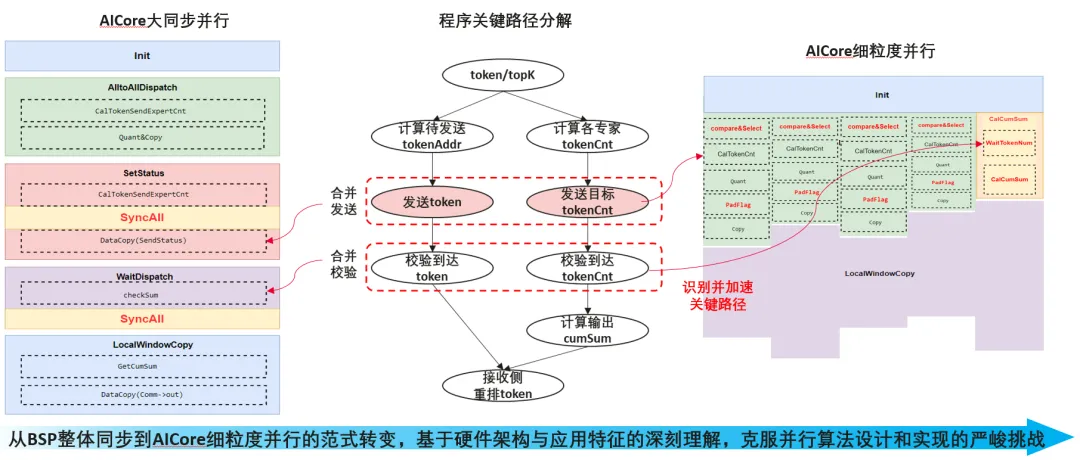
关键路径的细粒度分核
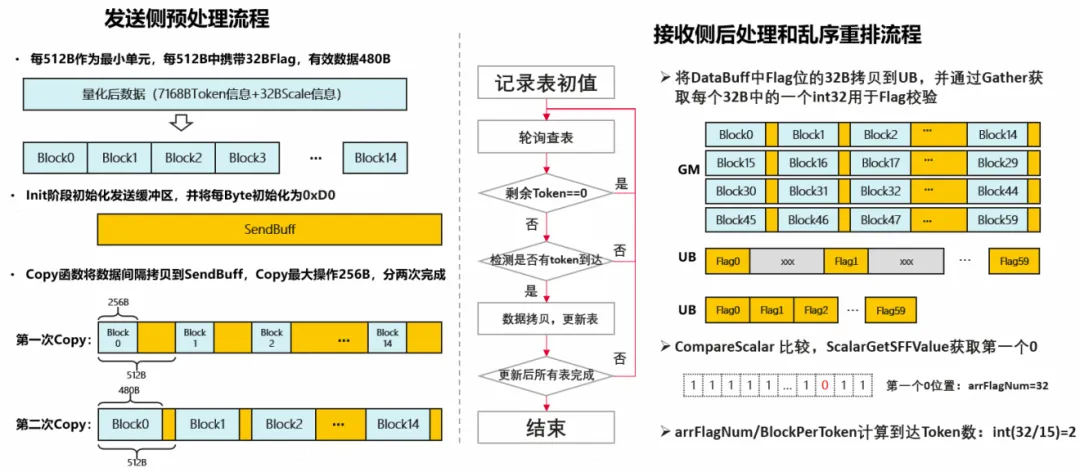
从数据依赖视角分析,BSP范式无法真正识别子过程间的关键路径,也就难以实现计算与通信的有效掩盖。具体到Dispatch算子,其最终接收侧的重排过程依赖于两方面输入:各专家对应的Token累加和(cumSum),以及实际Token数据到达。其中,cumSum依赖于发送侧统计的Token-Expert对应计数信息(TokenCnt),而真实Token数据则依赖于网络带宽传输能力。如图所示,为了简化程序设计和实现,将Token和TokenCnt合并发送与校验,在此基础上,再将TokenCount信息与Token数据信息分离处理:1、发送侧优先计算并传输TokenCnt信息,使接收侧尽早开始计算输出地址cumSum,提前完成重排准备;2、发送侧随后发送Token数据,接收侧提前计算cumSum,按照Token的实际到达顺序,动态调度专家Token并乱序重排至OutputBuffer:
识别并加速关键路径上的子任务,预留1个专用AICore等待TokenCnt到达,并立即计算输出地址cumSum;
利用Token数据传输掩盖TokenCount预处理,其他AICore首先计算并发送各专家的TokenCnt,随后发送Token数据;
一旦接收侧完成cumSum计算,所有接收侧AICore即可并行校验到达的Token数据,直接开始后处理重排。
基于异步数据信号的AICore级软同步:相比阻塞式的SyncAll全核同步,基于异步数据信号的AICore级软同步方法,利用GM中特定缓冲区的读写操作,实现AICore间的轻量级数据信号的异步交互。例如,当AICore-0将某共享缓冲区的初值从0改为1后,其他AICore只需检测到该地址值为1,即可判定AICore-0已完成对应操作,无需等待全局同步。具体应用中,负责计算输出地址(cumSum)的AICore在完成计算后,将结果写入GM指定位置,其他负责Token重排的AICore即使未参与计算,也能通过读取该位置获取正确地址,实现异步协作。这种借助“以数据为信号”(Data-as-Flag)的理念,有效缓解Ascend C的Block级编程跨核通信能力不足的问题,是软硬协同优化以软件灵活性补充硬件能力的典型范式。尽管软同步会占用AICore算力与GM带宽,但能灵活支持一对一、一对多、多对多等同步需求,尤其适用于细粒度分核并行场景——例如接收侧主动校验已到达数据,实现专家Token的乱序重排。
向量化按专家分核多个AICore按Token处理topK位图并共享中间topKFlag信息,实现全核负载均衡,提出解决大BS的性能瓶颈。除了AICore间的并行化,我们还可以进一步利用AICore内的向量化并行方法,充分发挥硬件并发能力,通过单条指令同时处理多个数据元素,大幅提升计算效率。虽然向量算力通常远大于标量算力,此类优化的实际效果高度依赖于底层硬件所支持的指令集范围。
筛选目标专家:以全部BS个Token的topK信息作为输入,利用CompareScalar向量指令并行筛选出当前AICore所负责专家的TokenMask。各AICore处理的输入均为完整的BS×topK数据,但每个AICore根据自身分配的专家编号,筛选出对应的Token子集;
统计TokenCount:基于上一步得到的TokenMask,使用ScalarGetCountOfValue指令统计Mask中值为“1”的元素数量,即可获得当前专家对应的TokenCount信息。通过两个向量指令的组合,实现了Token数量的提前计算与发送准备;
逐Token发送:逐个提取TokenMask中标记为“1”的Token,按序发送至对应专家。由于AICore按专家分核,同一专家的所有Token由同一AICore处理。每发送一个Token数据,更新本地记录的对端地址:DstAddr = DstAddr + TokenLen,实现连续地址写入。

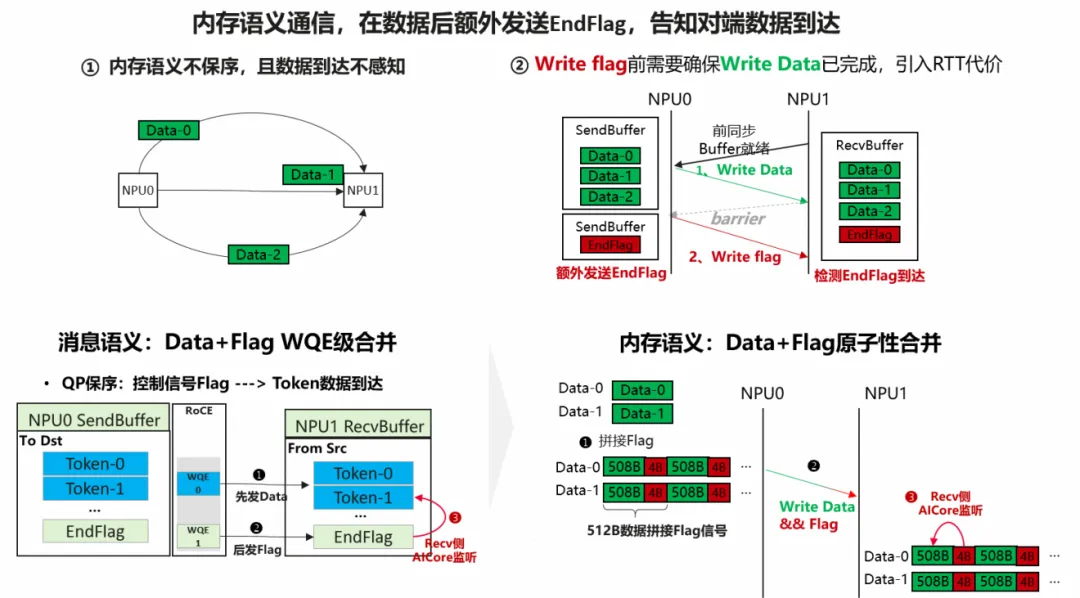
DataAsFlag消除后同步
从最基础的通信流程来看,一次完整的点对点通信通常包含三个关键阶段,构成了一个“握手-传输-确认”的闭环:
接收缓冲就绪(前同步):接收方首先向发送方发送“就绪”信号,表明其接收缓冲区(RecvBuffer)已准备妥当,可安全接收数据,从而避免数据写入冲突或踩踏风险;
真实数据发送(数据传输):发送方在收到就绪信号后,开始向约定的RecvBuffer写入有效数据。在集合通信等场景中,常采用双缓冲(Double-Buffering)技术,直接向预先确定的备用缓冲区写入;
传输完成确认(后同步):发送方完成所有数据写入后,会向接收方发送一个完成标志(Flag),表明当前传输数据已全部到达RecvBuffer。
免同步的低时延通信:传统的通信流程依赖显式的同步操作来协调数据的生产与消费。而通过“以数据为信号”(Data-as-Flag)技术,可以将这种阻塞式的交互转变为基于异步数据信号更新的轻量级协作。在A2上,借助RDMA的网络保序性与NOC事务的首报文保序能力,可以利用细粒度的TokenFlag来判定Token数据是否到达。然而,在昇腾超节点架构中,MTE内存语义本身乱序。为了实现相同Flag校验功能,发送方必须主动插入Barrier,以强制保证Flag之前的所有数据都已可靠到达。事实上,尽管MTE操作乱序,但网络和总线能保证在单个数据包级别的一致性。以512B DataBlock为例,同一Block内的所有数据会被原子性地写入GM。这催生了一种巧妙的细粒度DataAsFlag实现方案:将有效数据(Data)和标志(Flag)合并封装在同一个512B的DataBlock。这样,一旦监测到Block内8B-Flag数据有效,即可原子性地确认504B的有效数据也已经就绪。
从系统优化的角度看,DataAsFlag本质上是一种通过增加预处理、后处理以及Flag传输开销,换取通信延迟降低的典型系统trade-off策略。以7KB Token传输为例:每个NPU通过7个网络平面将数据按地址散列发往对端NPU,每个平面传输1KB数据原本仅需2个DataBlock;采用DataAsFlag编码后,需增至3个DataBlock,同时接收端还需从RecvBuffer中提取原始Token数据,带来额外的处理开销。
向量化并行的DataFlag:超节点架构中,基于内存语义的DataAsFlag本质上是一种更细粒度的Flag校验机制。以BlockFlag消除后同步通信的向量化并行为例,MTE内存语义数据传输路径:发送侧GM—> AICore的UnifiedBuffer —>接收侧GM(详细代码参考原型):
发送侧预处理:AICore首先使用Flag初始化SendBuffer(位于UnifiedBuffer中),按专家维度并行逐个加载Token数据至UB,并为每个数据块预留32B空间用于存放初始化Flag;
接受侧后处理:AICore将RecvBuffer中的32B Flag拷贝至UB,通过Gather操作提取每32B中的int32类型Flag,并借助CompareScalar与ScalarGetSFFvalue等向量指令统计已到达的Block数量,进而推算出实际到达的Token数;
乱序重排:为规避慢卡或慢专家引起的瓶颈,接收侧AICore动态轮询所有发送方数据,依据Token实际到达时间,按FIFO策略动态调度执行对应专家的Token重排。由于关键路径上的输出累加和(cumSum)已预先计算完成,一旦某专家的Token到达,即可立即重排至OutputBuffer,实现高效流水线处理。
性能收益
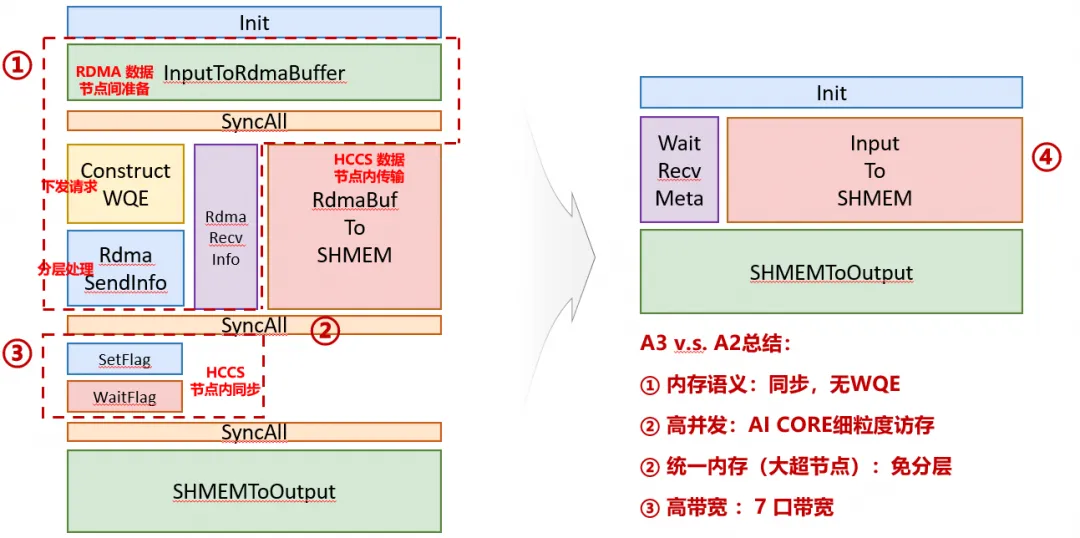
如图所示,得益于超节点计算系统提供的细粒度并行能力:免WQE消息处理的内存语义、AICore高并发的细粒度访存、超节点范围免分层的统一内存和高带宽域。通过识别程序整体流程的关键路径,打破BSP范式中子过程的串行依赖,实现AICore级的细粒度并行,我们最终设计和实践了一系列并行优化:提前计算与发送TokenCount、消除AICore间的全核同步(Sync_ALL)及NPU间的通信后同步、接收侧Token的乱序处理,以及向量化批处理等。
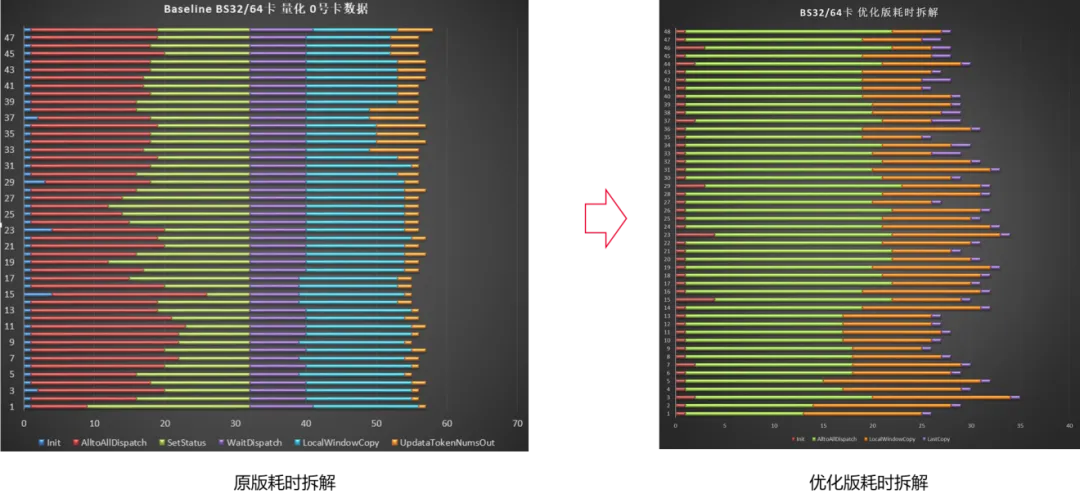
算子耗时的详细拆解(64卡、BS32、开启量化、目标专家均匀分布场景下,基于算子内打点计时)对比中:优化版本的同步等待相关耗时显著降低;同时,最后一个Token到达后的尾处理耗时极短(右图尾部紫色部分),接收侧的大部分后处理耗时被数据传输过程所掩盖,整体性能实现约57%的提升。
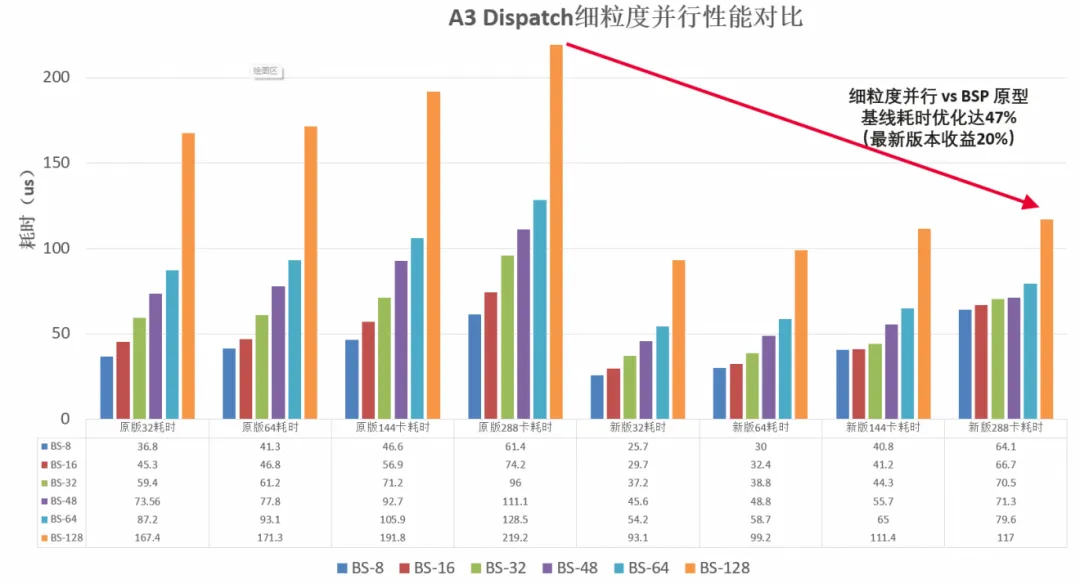
更进一步,288卡大规模场景下的整体性能对比测试结果如下(Dispatch单算子测试,开启量化,目的专家排布为均匀分布):128BS配置中,耗时从219us降至117us,缩短47%,性能接近翻倍。此外,得益于免同步能力对各阶段子任务充分并行的支撑,程序整体可扩展性显著提升:当BS从8扩大至128时,基线版本耗时从61us增至219us,而优化后耗时仅提升至117us,数据量增加带来的性能损失大幅降低(预处理、数据传输、后处理各阶段耗时更好掩盖)。
AICore细粒度性能分析
在算子性能分析与优化过程中,准确识别性能瓶颈是基础且至关重要的一环。在昇腾上,要高效组织众多AICore实现细粒度协同计算,性能分析更是核心前提。在规模化集群层面,昇腾调优工具MindStudio支持模型级与算子级调优,可显著提升性能分析效率。然而,当分析粒度细化至内核函数在具体AICore之间的负载均衡时,仅依靠外部打点工具有点力不从心了。单纯通过性能剖析工具采集算子运行时的Profiling数据,不仅会干扰算子本身的执行性能,也难以捕捉其内部各阶段的耗时分布。这就要求开发者必须在算子内部插入计时打点,并根据程序逻辑将打点数据整理成可视化的性能分解图。同时,打点计时操作本身依赖于GetSysTimeCycle等性能采集指令,该类指令也要按硬件调度要求执行,必须通过Pipe_Barrier主动控制内核函数的指令流水,才能确保计时点的准确性与一致性。
我们引入了AICore细粒度性能分析,打开算子整体性能的“黑盒”,实现细粒度性能数据采集。如图所示,每条横线代表一个AIV核心,以Dispatch算子为例,共48个AIV核心参与计算,各核心在不同阶段的耗时通过色块区分显示。通过观察同一阶段所有核心的色块是否同时结束,可直观判断是否存在核间负载不均的情况。在此简要说明在算子内部抓取各阶段耗时的基本思路:首先解析算子主体逻辑,在相应AICore核函数中插入时间戳采集点;随后统计各核函数耗时信息,并借助UB与GM输出耗时数据;最终汇总生成可视化的累计耗时图谱。注意打点过程中保持UB和GM的数据对齐,同时确保”PipeBarrier<PIPE_ALL>”的同步操作。
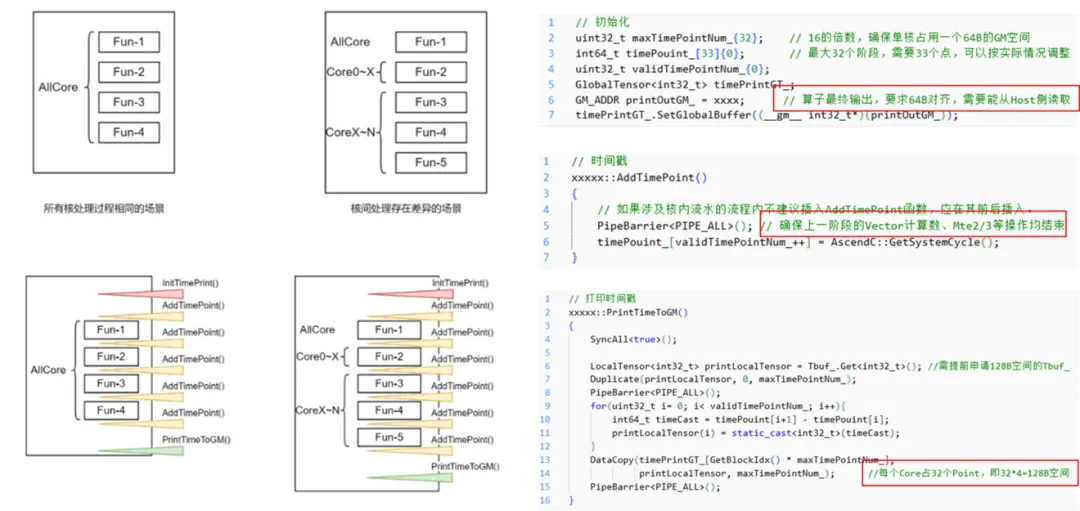
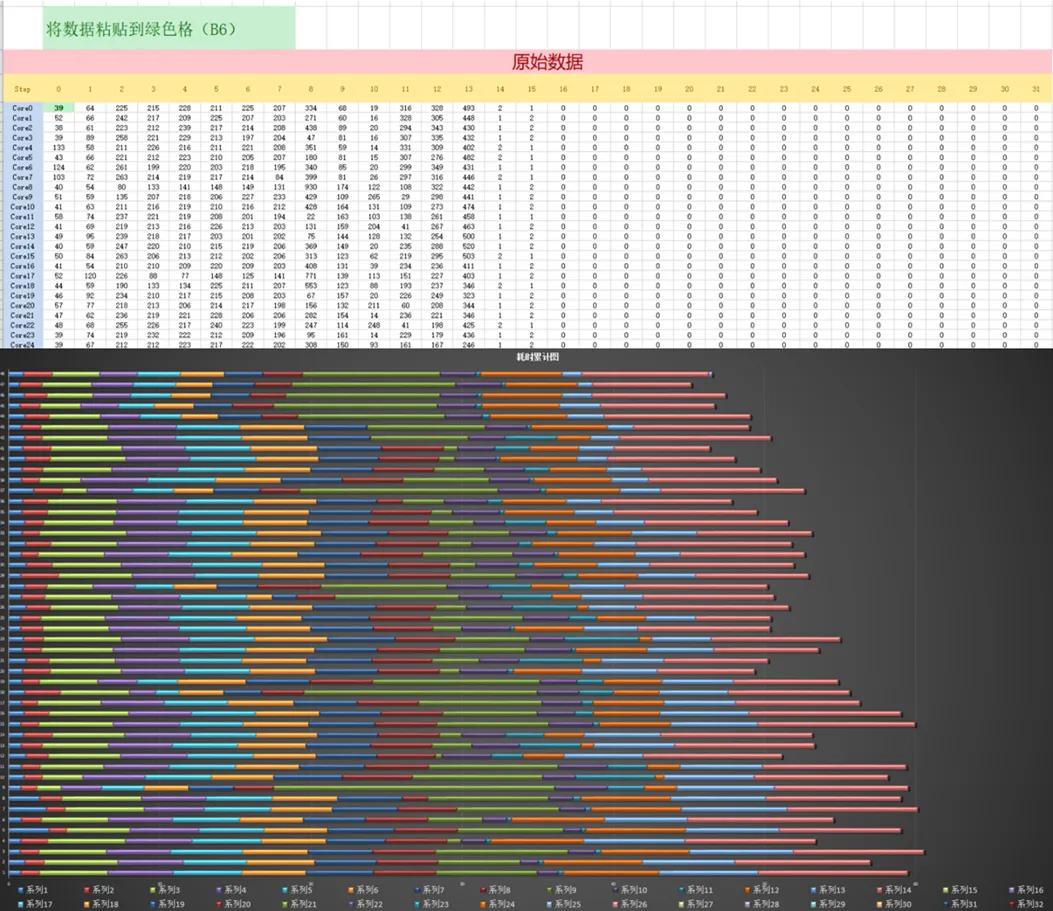
在重新执行带有时间戳的算子后,通过打印输出结果(具体为图中printOutGM_对应地址处的数据,注意使用maxTimePointNum_换行以区分不同AIV核心),即可获得算子性能分析所需的原始数据。输出结果中,每一行对应一个核心的时间戳记录。为便于分析,我们已同步准备好对应的可视化模板表格,用户只需将打点数据粘贴至模板,即可自动生成如下的耗时累计图。
总结
以突破BSP范式中子过程串行依赖为主线,从低开销核间同步与精确数据依赖出发,系统介绍了流水、乱序、向量化等优化方法,并实践于AICore细粒度并行场景的性能瓶颈分析与算法设计,为DeepSeek命题作文交出了一份阶段性答卷。不可否认,从支持一个新算子特性,到特定用例中充分发挥硬件能力,再到通用场景下实现极致性能,对软硬协同优化的确是不同层次的挑战。尽管实现细节纷繁复杂,但性能优化的底层逻辑万变不离其宗:识别整体流程的关键路径、掌握每个AICore的实际负载、支持核间细粒度同步、充分适配向量化硬件级并行特性。性能优化,无限征程。
昇腾A3系列产品粗粒度并行基线
https://gitcode.com/cann/ops-transformer/blob/master/mc2/moe_distribute_dispatch/op_kernel/moe_distribute_dispatch.h
昇腾A3系列产品细粒度分核并行代码
https://gitcode.com/cann/ops-transformer/blob/master/mc2/moe_distribute_dispatch_v2/op_kernel/moe_distribute_dispatch_v2_full_mesh.h
CANN Ascend C矢量接口
https://www.hiascend.com/document/detail/zh/canncommercial/82RC1/API/ascendcopapi/atlasascendc_api_07_0068.html
MindStudio Insight
https://www.hiascend.com/document/detail/zh/mindstudio/70RC3/msinsightug/msascendinsightug/Insight_userguide_0002.html