 夜雨聆风
夜雨聆风





基于书生大模型的全流程智能软件测试体系丨与书生共创

随着书生大模型开源生态的不断壮大,越来越多的产品和平台纷纷接入书生大模型。科研人员依托书生大模型持续探索创新,取得了丰富的研究成果;社区用户也不断创造出令人耳目一新的项目。“与书生共创”将推出一系列文章,聚焦这些合作与创新案例。欢迎订阅并踊跃投稿,一起分享经验与成果,共同推动大模型技术的应用与发展。
本项目为兴智杯“基础大模型智能体应用创新挑战赛”优秀获奖作品,由中国联通软件研究院打造。团队以书生大模型为核心引擎,创新构建覆盖“智能需求解析→用例生成→智能评审→用例转化→智能执行”的全流程智能化测试体系,系统性突破传统软件测试在效率与覆盖度上的核心瓶颈,全链路推进测试智能化升级。项目已在中国联通软件研究院成功落地,累计生成测试用例 13.6万+ 条、完成智能评审 20万+ 次,整体测试效率提升 25%,召回率和准确率对标国内头部互联网企业达到业界领先水平。
书生大模型在线体验链接:
https://chat.intern-ai.org.cn/
团队联系方式:
mengjn6@chinaunicom.cn
项目简介
在 AI 技术全面爆发的背景下,企业数字化转型加速,传统软件测试面临高度依赖人工经验、重复操作繁重、用例覆盖不全等核心瓶颈,难以满足敏捷开发与高质量交付的双重需求。
为应对上述挑战,中国联通软件研究院以书生大模型 InternLM3-8B-Instruct 为核心引擎,创新构建覆盖“智能需求解析→用例生成→智能评审→用例转化→智能执行”的全流程智能化测试,系统性突破传统软件测试在效率与覆盖度上的核心瓶颈,全链路推进测试智能化升级。
项目深度融合书生大模型的自然语言处理能力,并结合业务知识图谱和页面智能遍历算法,自动生成高覆盖率测试用例,用例生成效率提升 63%。利用 ReAct 推理框架+RAG 知识库实现用例智能评审,准确率达 89.45%。同时,通过自然语言驱动自动生成 Playwright 脚本,集成 MCP 工具链,叠加缓存机制,实现从需求到可执行脚本的分钟级转化。大幅降低缩短测试周期,回归测试效率提升 50%。
目前,该项目已在中国联通软件研究院成功落地,累计生成测试用例 13.6万+条、完成智能评审 20万+次,整体测试效率提升25%,召回率和准确率对标国内头部互联网企业达到业界领先水平。在经济效益上,以一个中等规模测试团队为测算基准,年节省人力成本约 525万元,而算力投入仅 25万元,投资回报率(ROI)高达 20倍。此外,项目荣获多项行业创新奖项,具备在金融、通信、政务等高复杂度、高可靠性要求的软件系统中广泛复制与推广的潜力,为国产大模型在垂直领域的深度应用提供标杆范例。
项目创新
项目创新主要有以下四点:
智能用例生成
首创“知识驱动+智能遍历”融合的用例生成方案。融合书生大模型,整合需求文档、业务知识图谱(OpenSPG)与页面遍历(DFS+Playwright),用例生成准确率达 87%,召回率达 76%,效率提升 63%。
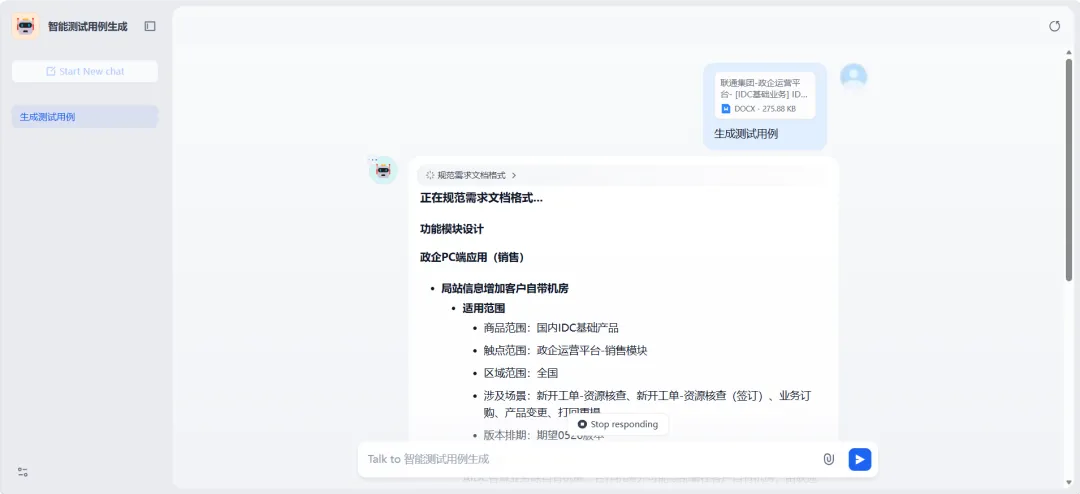
智能用例生成示例
智能用例评审
构建“思维链增强评审机制”,实现智能用例评审。结合ReAct推理与RAG知识库,实现逻辑分析与规则匹配,评审准确率达89%,用例质量提升34%,评审效率提升70%。
智能用例转化
实现“自然语言→可执行脚本”的智能转化与执行。基于NLP与知识图谱,10–20分钟内将自然语言用例转为可执行“AI语言”,打通设计到执行的快速通道。
智能执行
构建“大模型解析—脚本生成—一键执行”链路。自动生成 Playwright 脚本并通过 MCP 调度,执行效率提升 50% ,支持脚本复用与回放。
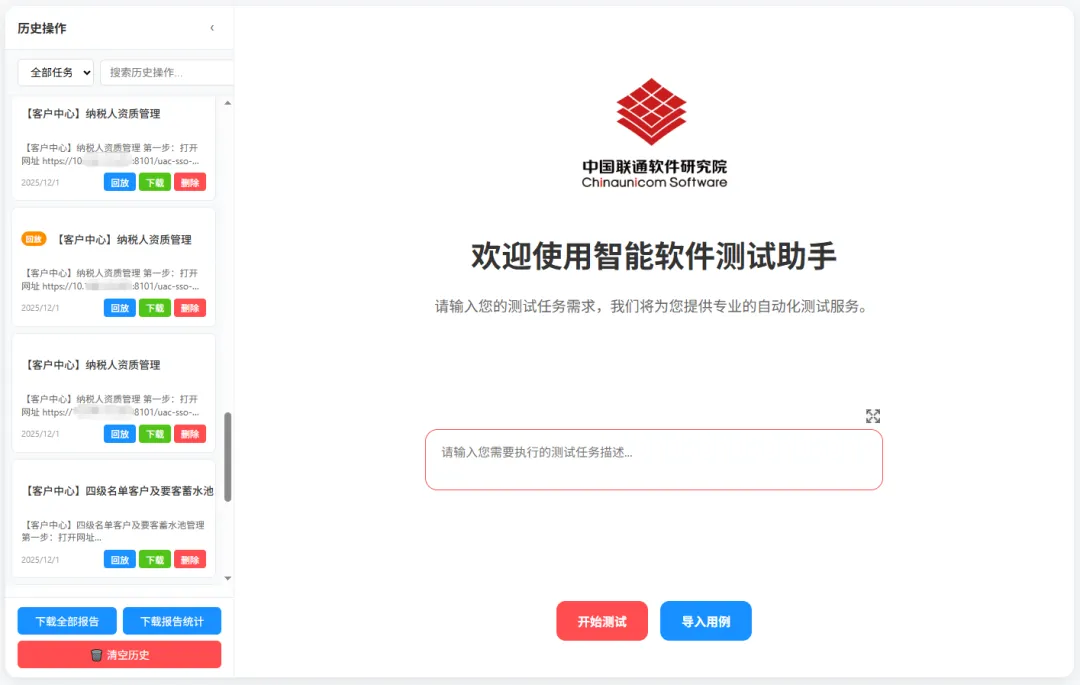
智能执行示例
技术方案
本方案以书生大模型 InternLM3-8B-Instruct 为核心基座,承担需求理解、测试用例生成、执行逻辑判断与决策调度等关键任务;在图文、界面识别等多模态场景中,使用 InternVL3.5-241B-A28B 模型,提升界面理解、元素定位与复杂业务场景解析能力。
整体架构分为四层:
数据知识层:汇聚需求文档、历史用例、评审规则、操作手册及页面遍历数据,依托 OpenSPG 构建测试领域知识图谱,实现知识结构化与高效关联。
智能决策层:融合 GraphRAG+RAG 检索增强、规则引擎与多智能体协同,完成需求拆解、用例智能生成、缺陷预判及自动化评审。
执行编排层:通过 MCP 统一调度 Playwright 自动化引擎与分布式执行节点,实现自然语言用例到自动化脚本的一键转换与批量执行。
应用输出层:输出标准测试用例、评审报告、执行日志与回归结论,形成需求 — 用例 — 评审 — 执行 — 回归的端到端智能测试闭环,全面提升测试效率与质量稳定性。
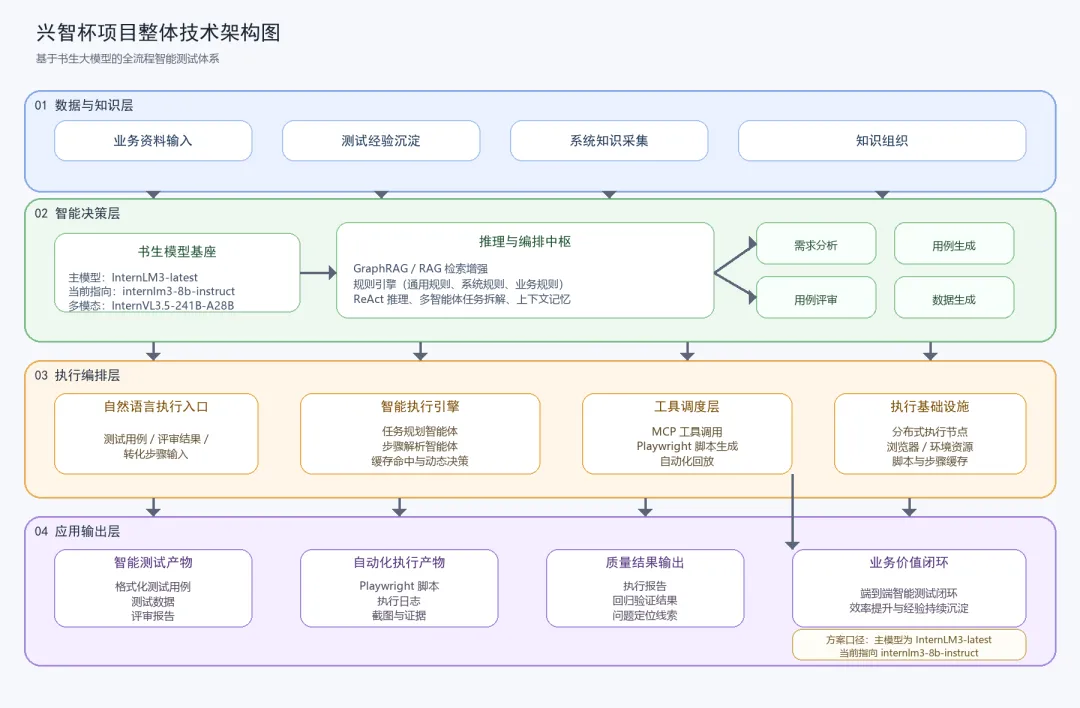
全流程智能测试体系整体技术架构
总结
基于 AI 智能测试平台现有落地成果,后续将围绕书生大模型能力深化与开源工具链融合,持续推进四大模块迭代升级:
用例生成模块:迭代 OpenSPG 知识图谱与图大模型融合能力,接入书生多模态模型 IntenrVL-U,强化 DFS+PlayWright 页面智能遍历与知识补全,提升复杂及优化类需求用例召回率与准确率,目标平均召回率超 85%。
用例评审模块:升级 ReAct 推理框架,扩充 RAG 漏测经验知识库,结合书生大模型优化规则引擎,将评审准确率提升至 93%,实现评审耗时压缩至分钟级。
用例转化模块:深化存量页面打标与系统知识图谱建设,优化自然语言转自动化脚本流程,将优化类需求用例转化效率提升至 1 分钟 / 用例,降低脚本维护成本。
智能执行模块:强化书生大模型自动生成 PlayWright 脚本能力,完善 MCP 一键执行与缓存回放机制,将执行效率提升至 85% 以上,减少人工干预。
通过持续适配书生大模型、打通全链路开源工具链,平台将构建用例生成、评审、转化、执行一体化智能测试闭环,实现测试质量与效率双提升,助力软件高质量交付。
https://chat.intern-ai.org.cn/
点击下方卡片,关注我们,获取书生大模型最新相关资讯。
欢迎投递技术稿件:加微信 breezy0101