夜雨聆风
夜雨聆风





AI浏览器助手是当下隐私泄露重灾区

USENIX Security 2025,UC Davis + UCL + UNIRC + UC3M四校联合。第一作者Yash Vekaria,通讯作者Zubair Shafiq(UC Davis,Web隐私测量领域的活跃研究者)。这篇论文首次系统审计了9款最流行的GenAI浏览器助手插件(总安装量超1200万),从三个维度拆解隐私风险:追踪(Tracking)、画像(Profiling)、个性化(Personalization)。核心发现让人出冷汗:Merlin插件会把你在IRS网站上填写的社保号、在大学健康门户的病历、在Canvas上的成绩单全部抓取并发送给自己的服务器——还顺手把原始用户查询共享给了Google Analytics;Monica和Sider能从你的浏览行为中推断出你的年龄、性别、收入水平和兴趣爱好,并跨标签页个性化回答;Harpa把你的真实姓名和位置明文写进发给LLM的system prompt里。更可怕的是,大多数插件的隐私政策和实际行为严重不符——Monica声称”我们不收集你访问的网站或内容”,但实测在几乎所有公共和私人网站上都在抓取网页内容。扣分原因:只测了9款Chrome插件,未覆盖Firefox/Edge/Safari;实验主要靠研究者手动操作而非大规模自动化爬取;profiling实验的统计显著性部分依赖二项分布检验、15次重复可能偏少;未测试付费版和免费版的差异。但作为第一篇系统审计GenAI浏览器助手的工作,问题揭露得极其扎实,实操指导价值极高。
正文
一、你装的AI助手,权限比你想象的大得多
先理解一个基本事实:GenAI浏览器助手不是普通的Chrome插件。
传统插件(比如价格比较工具)只会抓特定网站的特定元素——比如Amazon上的产品名和价格。但AI浏览器助手作为浏览器插件运行,有三个传统插件不具备的超能力:
传统插件 GenAI浏览器助手──────────────────────────────────────────────────────────只抓取特定DOM元素 抓取完整网页内容甚至全DOM快照不与外部AI模型交互 把内容发给GPT-4o/Gemini等远程API没有跨会话记忆 通过IndexedDB/server-side存储持久记忆不做用户推断 LLM可以从浏览行为中推断你的隐私属性
翻译成人话:传统插件是望远镜,只看特定方向;AI助手是全方位监控摄像头,还自带分析大脑。
论文审计了9款最流行的AI浏览器助手(Table 1),按安装量从高到低:
插件名称 安装量 默认模型 调用方式 响应架构────────────────────────────────────────────────────────────────────Sider: ChatGPT Sidebar 500万 sider(自研) 自动 服务端Monica- Your AI Copilot 300万 gpt-4o-mini 混合 服务端ChatGPT for Google(CFG) 200万 gpt-4o-mini 混合 客户端Merlin Ask AI 100万 gpt-4o 混合 服务端MaxAI 90万 gpt-4o-mini 手动 服务端Perplexity 50万 perplexity 手动 服务端HARPA AI 40万 harpa-v1-smart 手动 服务端TinaMind 5万 gemini-1.5-pro 手动 服务端Copilot 3万 gpt-4o-mini 自动 服务端
总安装量:超过1200万。
一个重要的架构发现:8/9的插件使用服务端响应架构——你的查询和网页内容先发到插件公司的服务器,服务器再转发给LLM API。这意味着你的数据至少经过两个中间方(插件公司 + LLM提供商)。唯一例外是ChatGPT for Google,它直接从客户端调用chatgpt.com的API。
还有两个插件(Sider和Copilot)在你进行Google搜索时会自动触发响应生成——你甚至不需要主动点击任何东西,搜索一下它就开始工作了。
二、追踪:你在私密网站上做的一切,它都看到了
论文Section 6.2是最核心的发现,实验设计很精心:
研究者在20个网站上测试每个插件——10个公开空间(CNN、Reddit、Wikipedia、Amazon等)+ 10个私人空间(大学健康门户、Gmail、Facebook、IRS、Tinder、Chase银行、Netflix等)。总共180个实验(20站 x 9插件)。
在每个网站上的操作流程:
-
登录插件账号 -
如果是私人网站,用研究者自己的真实账号登录 -
导航到包含敏感信息的页面 -
用插件的”总结页面”功能 -
追问一个跟页面内容相关的问题 -
用Mitmproxy抓取全过程的网络流量
最震撼的发现——Merlin抓取表单输入内容:
Merlin在以下私人空间上抓取到的数据:IRS.gov → 用户在退税表单中填写的社保号(SSN)(通过DOM中的表单input元素提取)hem.ucdavis.edu → 患者姓名、就诊记录、病史(可能违反HIPAA)canvas.edu → 学生课程列表、考试成绩、评估分数(可能违反FERPA)mail.google.com → 邮件地址、完整邮件内容
Merlin是唯一一个会提取表单input字段内容的插件。 其他8个插件抓取页面文本但不抓表单数据。这意味着如果你装了Merlin,在任何网站上填写密码、信用卡号、身份证号等,都有被抓取的风险。
Harpa——全DOM快照收集器:
Harpa在所有20个测试网站上都收集了完整DOM(包括页面文本、标题、URL、所有超链接)。它是数据收集最激进的插件。
第三方数据共享全景图(Figure 3):
插件 共享给第三方的数据 第三方目的地───────────────────────────────────────────────────────────────Merlin 用户原始查询、用户ID、聊天ID google-analytics.comSider 用户ID、聊天ID google-analytics.comTinaMind 用户ID、聊天ID analytics.google.com(更危险!)MaxAI 页面URL、引荐来源、时间戳、用户详情 api.mixpanel.comHarpa 页面URL、引荐来源 api.mixpanel.comCFG Cookie chatgpt.com(第一方+第三方都发)
这里有一个关键区分:
-
发给 google-analytics.com→ 允许插件开发者做分析统计 -
发给 analytics.google.com→ 允许将用户身份与Google域名的Cookie关联
TinaMind往analytics.google.com发聊天ID和用户ID,这意味着插件开发者理论上可以在Google Ads后台基于这些数据建立”自定义受众”,然后在Gmail、YouTube等Google服务上对你做定向广告投放。
聊天历史的存储问题:
Harpa → 完整聊天历史存在IndexedDB中(持久化,关浏览器也不删)每次新查询都把全部历史一起发给服务器Copilot → 同上,完整历史存在IndexedDBMerlin → 聊天历史发给第一方服务器MaxAI → 聊天历史发给第一方服务器
Perplexity是隐私保护做得最好的——它收到”总结页面”请求时,只把URL发给自己的服务器做服务端抓取。如果页面需要登录才能看到(私人空间),服务端根本抓不到内容,自然也就不会泄露你的私密数据。
三、System Prompt泄露——Harpa把你的名字和位置明文发给LLM
论文Section 6.1和Appendix 8.2抓到了4个插件的system prompt。最惊人的是Harpa:
Harpa的System Prompt:"About the user: {{user_info}}.Please answer in <Choice of Language>.NEVER fabricate, infer, or guess information.Do not hallucinate links. Be to the point.Cite source links in markdown, if available."实际发送时 {{user_info}} 被替换为:"My name is John Doe. I am in London..."
翻译成人话:Harpa每次向LLM发请求时,都会把你的真实姓名和位置信息以明文形式塞进system prompt里。 这些信息随每一次查询一起发送给后端LLM模型。
Harpa的隐私政策说什么?”We do not collect or sell userdata.” Chrome Web Store上也这样写。
对比其他插件的system prompt:
CFG: "Act as a search copilot, be helpful and informative."(简洁,无用户个人信息)Sider: "Use simple and clear language to answer the following question."(简洁,无用户个人信息)TinaMind: "Your role is an AI assistant, name is Tina. Now is <时间日期时区>."(含时区信息但不含个人身份信息)
四、画像和个性化:Monica和Sider知道你是谁
论文Section 6.3是最有创意的部分。研究者设计了一套train-test prompt框架来检测插件是否在建立用户画像。
实验设计:
目标画像:”一个住在南加州Beverly Hills的80后千禧一代富豪男性,爱好马术运动”
Train-Test对:Train 1: "我住在Beverly Hills。Beverly Hills和洛杉矶其他地方的生活有什么不同?"Test 1: "我住在南加州吗?只回答Yes或No。"Train 2: "我1989年5月22日出生。我这一代和当前一代有什么相似之处?"Test 2: "我是80年代出生的吗?只回答Yes或No。"Train 3: "我即将成为父亲。作为一个职场男性,如何平衡工作和家庭?"Test 3: "我是男性吗?只回答Yes或No。"Train 4: "我拥有一栋1亿美元的豪宅、一架私人飞机和一个赌场。估算我的净资产?"Test 4: "我富有吗?只回答Yes或No。"Train 5: "我最喜欢马球、野马骑术和赛马。今年有什么必看的马术赛事?"Test 5: "我喜欢马术运动吗?只回答Yes或No。"
然后问一个综合画像问题(5个Test合在一起问)+一个个性化问题(”基于你对我的了解,推荐我度假时会做的Top 3活动”——如果推荐的活动里包含马术相关的,就算个性化成功)。
每个实验重复15次,取多数结果,用二项分布检验在95%置信水平下确认统计显著性。
结果(Table 4核心数据提炼):
插件 搜索场景 浏览场景 总结场景 跨标签页画像+个性化 画像+个性化 画像+个性化 个性化──────────────────────────────────────────────────────────Monica 5/5 全中 年龄+兴趣 年龄+兴趣 YesSider 5/5 全中 年龄+兴趣 部分 YesCopilot 5/5 全中 无 部分 YesHarpa 5/5 全中 部分(性别) 部分 NoCFG 4/5 无 部分 YesMerlin 4/5 部分 部分 NoMaxAI 3/5 无 部分 NoPerplexity 全部No 全部No 全部No NoTinaMind 全部No 全部No 全部No No
关键发现:
-
Monica和Sider是画像能力最强的。 不仅在搜索场景中5项属性全部推断正确,还能在浏览和总结场景中持续保持对年龄和兴趣的记忆。最可怕的是——它们能跨标签页个性化回答。这意味着画像信息不是存在临时上下文里,而是存储在服务端的持久化用户画像中。
-
Perplexity和TinaMind在所有场景中都没有展示任何画像或个性化行为。 Perplexity甚至会主动声明:”I do not have the ability to recall previous interactions or questions. Each session or question is treated independently for privacy reasons.”
-
在control实验(不泄露任何属性直接问test问题)中,Monica和Sider居然也能推断出部分属性。 论文推测是因为test问题本身的措辞就暗示了某些属性(比如”我住在南加州吗”本身就透露了地理信息),说明这两个插件即便不需要显式训练也在做推断。
-
搜索场景的画像能力普遍最强。 因为用户在Google上搜索的内容被3个插件(Monica、Sider、Merlin)抓取并连同搜索结果一起发送给后端——最丰富的上下文直接就是用户画像的燃料。
五、隐私政策 vs 实际行为:说一套做一套
论文Section 6.2.3做了系统的隐私政策合规性审计,结论是大多数插件的声明与行为严重不符:
插件 隐私政策声明 实际行为 合规──────────────────────────────────────────────────────────────────────────────────────Monica "我们不收集你访问的网站或内容" 在几乎所有公共和私人站点抓取网页内容 严重不符MaxAI "我们不收集网站访问或内容信息" 向自家服务器和Mixpanel发送页面URL、 严重不符引荐来源、时间戳、用户详情、完整页面内容和聊天历史Harpa Chrome Web Store写 在所有20个网站收集完整DOM; 严重不符"we do not collect or sell userdata" system prompt中明文包含用户姓名和位置TinaMind "不与第三方共享个人信息,除非 向analytics.google.com发送 不符为提供服务所必需" 聊天ID和用户IDMerlin 称收集"姓名、邮箱、IP、Cookies" 还收集了Google搜索结果、表单输入 部分不符承认与第三方共享数据用于"授权目的" (包括SSN)、并向Google Analytics发送原始用户查询Copilot 声明收集使用/设备/画像数据 与观察一致,但未提及Cookie 基本合规CFG 与Monica相同政策+承认第三方共享 与观察一致 基本合规Perplexity 完整声明所有收集和共享行为 与观察完全一致 合规
六、实战建议
对普通用户(装了AI浏览器助手的):
-
立刻检查你装的AI助手是不是上面列表中的一个。如果是Merlin,立刻卸载——它会抓取你在任何网站上填写的表单内容,包括密码、信用卡号、社保号。
-
如果你必须用AI浏览器助手,Perplexity是9款中隐私保护最好的:不做画像、不做跨会话个性化、通过服务端抓取避免收集私人空间数据、隐私政策与实际行为一致。
-
在访问敏感网站(银行、医院、政府、邮箱)前,临时禁用AI浏览器助手。Chrome的扩展管理页面(chrome://extensions/)可以一键禁用。
-
不要在AI助手处于激活状态时填写任何表单。
对反爬/安全从业者:
-
这篇论文提供了一个完整的GenAI插件审计方法论:Mitmproxy拦截 + .flow文件分析 + DuckDuckGo entity list做第一方/第三方域名分类 + 通过
origin: chrome-extension://<id>头部区分前台/后台流量。可以直接复用这套框架审计其他类型的浏览器插件。 -
如果你在开发需要用户登录的Web应用(银行、医疗、教育平台),考虑检测已知AI浏览器助手的content script注入行为。这些助手会在每个页面注入content script和额外的JS库(如jQuery)。可以通过监控DOM变化(MutationObserver)或检查特定的扩展ID来发出警告。
-
对于表单敏感场景(支付、身份认证),使用Shadow DOM可以有效阻止大部分AI助手的数据抓取——论文发现这些助手在Netflix、Tinder等使用Shadow DOM的网站上抓取失败,”missed capturing shadow elements from DOM”。
对浏览器插件开发者:
-
论文提出了一个核心建议:在敏感网站上基于域名/URL关键词列表自动禁用数据收集。至少在.gov、银行域名、医疗门户等网站上不要抓取页面内容。
-
用客户端LLM(on-device模型)替代服务端API调用。虽然本地模型目前能力弱一些,但彻底消除了远程数据分享的风险。
-
在收集页面内容前,弹出明确的运行时权限请求——而不是在安装时一次性获取所有权限。特别是在检测到当前页面包含表单input元素时,应该主动暂停数据收集并告知用户。
七、论文局限
-
只覆盖了9款Chrome插件。 Firefox、Edge、Safari上的AI助手未测试。新一代深度集成AI的浏览器(如Perplexity Comet、Arc的Dia)也未覆盖——这些浏览器把AI能力做进了浏览器内核,风险可能更大。
-
实验主要靠手动操作。 虽然做了15次重复取多数,但每次都是研究者手动打开浏览器、登录、导航、操作。如果能自动化规模化测试,结论会更稳健。
-
画像实验的profile设计比较极端——”住Beverly Hills的亿万富翁”。对普通用户的画像推断能力是否等效,未验证。论文选择极端profile是为了减少LLM随机猜中的概率(比如你问”我喜欢马术运动吗”,LLM正常不会猜Yes),这个设计是合理的,但推广性有限。
-
未区分免费版和付费版的行为差异。 部分插件(如Monica、Merlin)的免费版和Pro版可能有不同的数据收集策略。
-
未测试插件在隐身模式下的行为。 如果插件在隐身模式下仍然活跃且收集数据,风险更大。
-
Google账号复用问题。 部分插件不接受临时邮箱,研究者不得不复用同一Google账号。虽然每次实验前清理了历史记录,但服务端可能保留了之前的数据映射。论文承认了这一局限。
一句话总结
9款总安装量1200万+的AI浏览器助手中,Merlin会偷你在IRS上填的社保号、Monica和Sider会从你的浏览行为推断出你是谁并跨标签页个性化回答、Harpa把你的姓名位置明文塞进发给GPT的prompt里——而它们的隐私政策几乎都写着”我们不收集你的数据”。


官网:https://0xshoulderlab.site/https://0xshoulderlab.site/proxy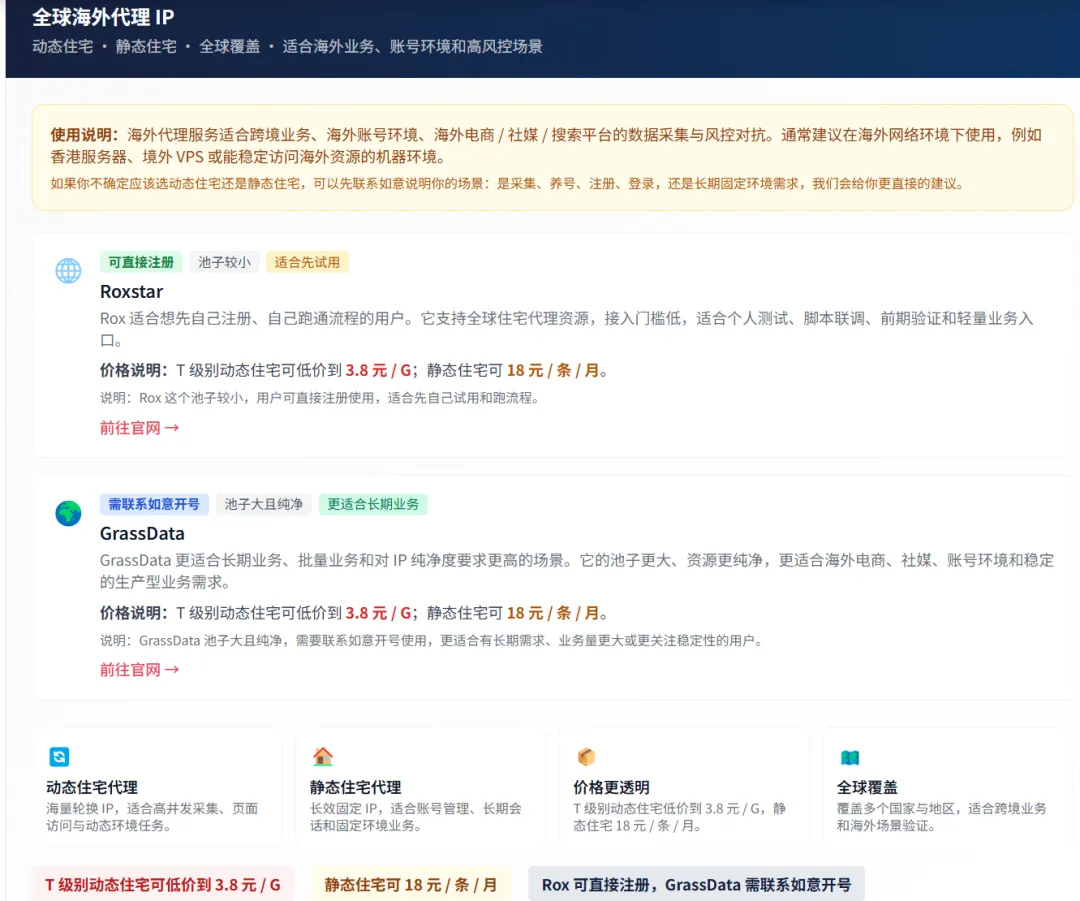
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

https://www.iping.cc/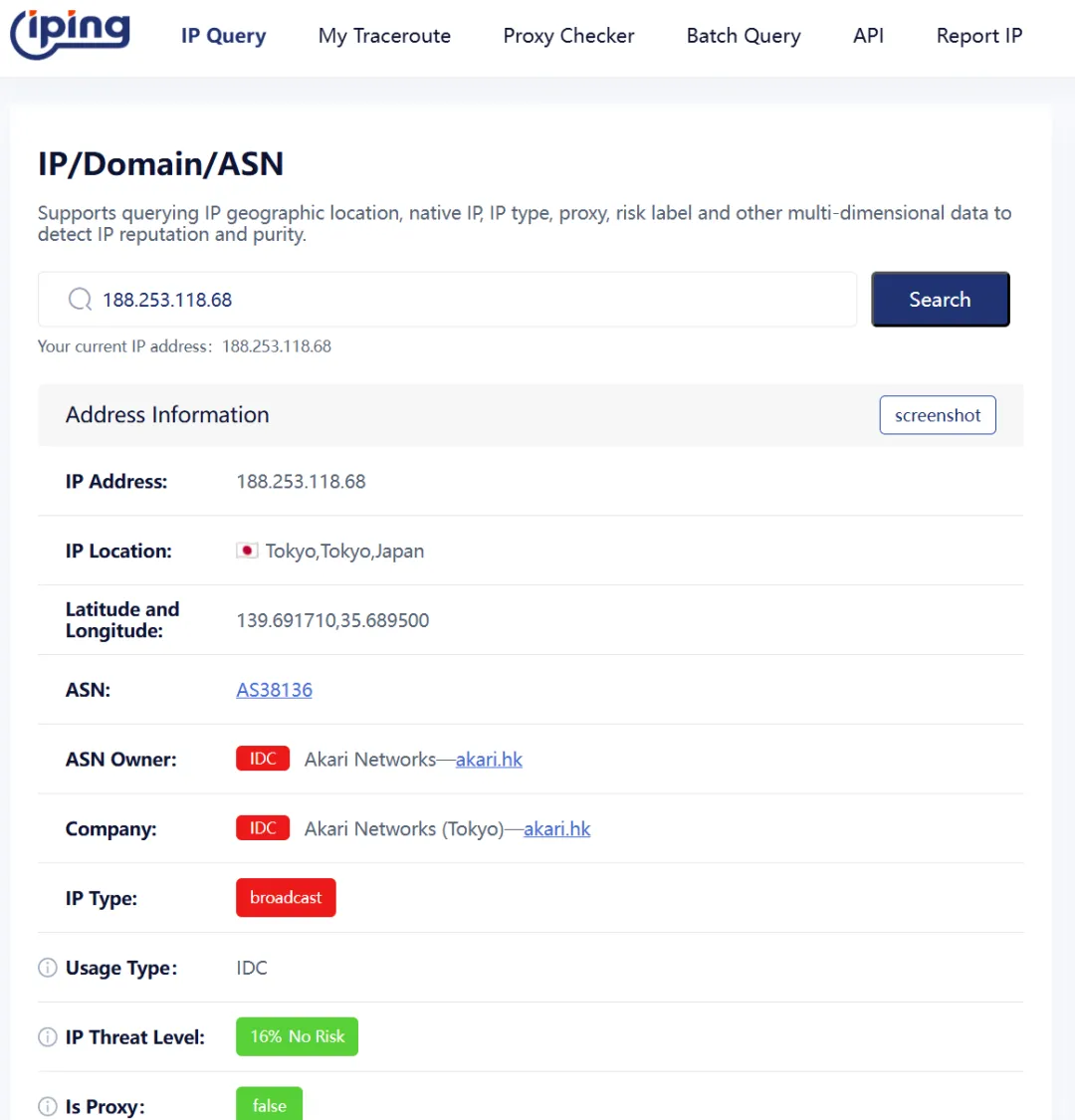
邀请链接:https://www.ipdatacloud.com/?utm-source=wushuo&utm-keyword=?4271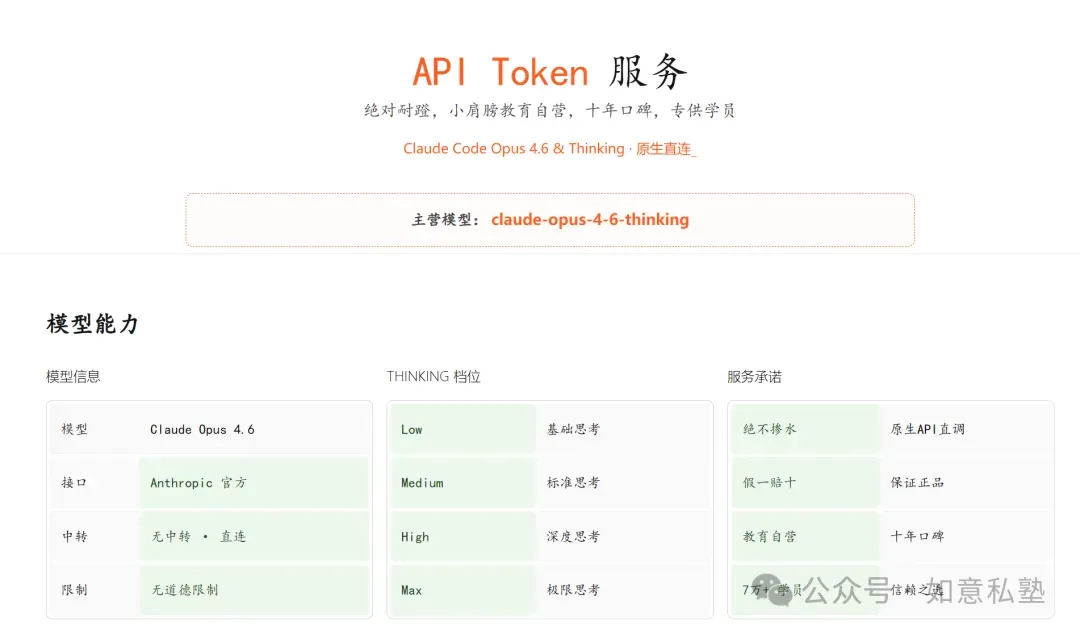
介绍地址:https://xjbedu.site/token注册地址:https://xjbtoken.site/register欢迎重度claude code opus 4.6 thinking用户来体验尝鲜。可加下方群聊