 夜雨聆风
夜雨聆风





AI 写代码越来越强之后,工程师真正要学的是 Harness Engineering
大家好,我是【虾米】
Harness Engineering 到底是什么?
这两年大家学 AI 编程,第一反应通常是学 Prompt。
比如:
这当然有用。
但如果你真的把 AI 智能体放进一个复杂项目里,很快就会发现:真正卡住它的,不是“不会写代码”,而是它不知道这个项目怎么运转。
它不知道架构边界在哪里。
不知道改完以后应该跑哪些检查。
不知道本地应用怎么启动,日志怎么看,CI 为什么失败。
甚至不知道某个业务规则是写在文档里,还是藏在团队某个同事的脑子里。
当然也可能会知道,但是需要它去读你的很多文件。
Harness Engineering 要解决的问题就是这个。
一句话:
Prompt Engineering 是教你怎么跟 AI 说话。Harness Engineering 是给 AI 搭一个能稳定干活的工程环境。
这里的 Harness 可以理解成“约束装置”“工作台”“测试夹具”。
它不是某一个神奇提示词,也不是某个单独工具,而是一整套工程系统:
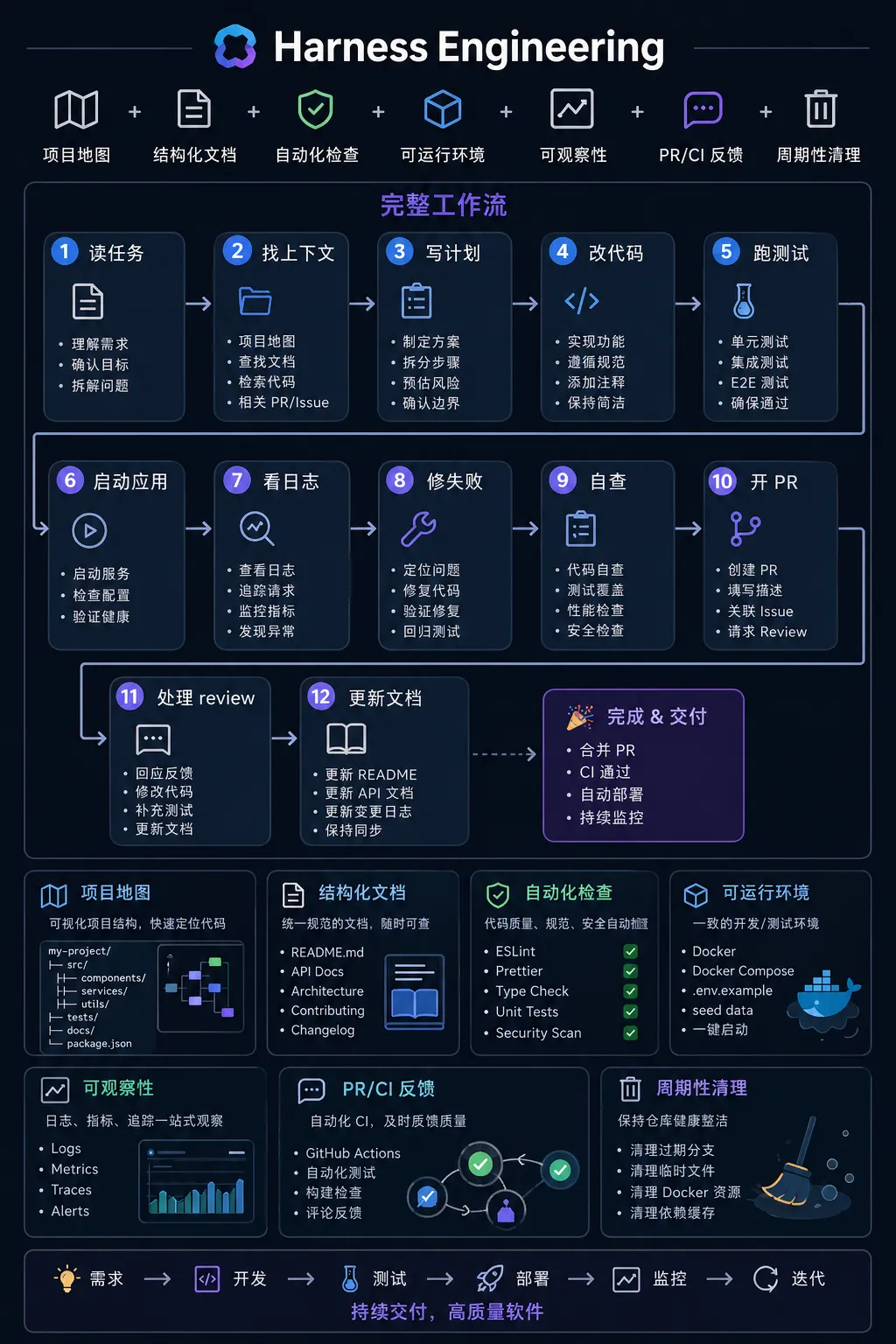
当这些东西齐了,AI 就不再只是一个代码生成器,而是可以进入一个完整工作流。
这才是 AI 编程真正进入工程化的样子。
为什么现在需要 Harness Engineering?
以前我们用 AI 写代码,很多时候是“局部增强”。
让它写一个函数,补一个测试,解释一段代码,生成一个页面。
这种场景下,Prompt 够用了。
但智能体越来越强以后,任务会变成这样:
这些任务靠一句 Prompt 是顶不住的。
因为复杂工程任务有三个特点:
-
上下文分散 -
验收标准复杂 -
失败反馈不只来自代码本身
人类工程师靠经验、会议、聊天记录、项目直觉,把这些信息拼起来。
AI 不行。
对 AI 来说,看不到的东西,就等于不存在。
所以你要做的不是“让 AI 更聪明”,而是把项目改造成 AI 能看懂、能执行、能验证的形态。
这就是 Harness Engineering 的核心价值。
一个成熟 Harness 工程长什么样?
咱们先看目标形态。
一个对 AI 友好的项目,大概应该长这样:

你看,它并不神秘。
它做的事情就几类:
AGENTS.md
:给 AI 的项目地图 ARCHITECTURE.md
:告诉 AI 架构边界 docs/product-specs/
:沉淀产品规则 docs/design-docs/
:记录重要技术决策 docs/exec-plans/
:让复杂任务先有计划 scripts/harness/
:把团队规则机械化 .github/workflows/
:让 CI 成为稳定反馈回路
说白了,就是把项目里原来靠人脑、口头约定、review 经验兜底的东西,尽量沉淀成 AI 能读取、能运行、能检查的东西。
先选一个试点任务
如何把自己现有的工程项目 AI 化呢?如何让自己开始实践 Harness Engineering?
这个坑我建议你一定要避开:不要一上来就说“我们要把整个项目 AI 化”。
太大了,容易虚。
更好的方式是选一个边界清楚的任务做试点。
比如:
-
给订单列表加 CSV 导出 -
给用户设置页补一个字段 -
修一个可复现的前端 bug -
给某个 service 补测试 -
把一个旧 API 迁到新路径
选任务有三个标准:
-
真实业务需要,不是 demo -
改动范围可控 -
有明确验收标准
你要用这个试点任务来检验你的 Harness 是否有效。
AI 卡在哪里,就补哪里的 Harness。

第 1 步:搭目录,把仓库变成 AI 的工作台
先在项目根目录创建上面讲的那些目录结构
第 2 步:写一个短小的 AGENTS.md
很多人做 AI 工程化,第一反应是写一本巨大的说明书。
这其实很危险。
AI 的上下文是宝贵资源,你一上来塞一大坨,它反而抓不住重点。
AGENTS.md 最好是一张地图,不是一本百科全书。
可以直接用这个模板:
这里真正关键的是“渐进式披露”。
不要把所有信息都塞进 AGENTS.md。
你只需要告诉 AI:入口在哪里、规则在哪里、检查怎么跑。
第 3 步:写 ARCHITECTURE.md,把边界讲清楚
AI 最喜欢清晰边界。
你给它一个混乱项目,它会复制混乱。
你给它一个边界清楚的项目,它会放大清晰。
ARCHITECTURE.md 不需要写得很文学,直接、可执行、可检查就好。
模板如下:
这里不是为了写漂亮文档。
而是为了让 AI 在改代码前知道:什么地方能改,什么地方不能乱碰。
第 4 步:把产品规则放进 product-specs
很多 AI 写错业务逻辑,不是模型差,是业务规则没给它。
比如订单导出功能,真正的规则可能是:
-
只有管理员能导出 -
最多导出 5000 条 -
导出字段要脱敏 -
取消订单也要出现 -
金额单位是分,不是元 -
时间按用户所在时区展示
如果这些规则只在产品经理脑子里,AI 必然会漏。
所以你要建产品规格文档。
比如:
这类文档越具体,AI 越稳。
不要写“注意权限和异常情况”这种空话。
要写到可以变成测试。
第 5 步:加一键检查命令,让 AI 改完能自证
Harness Engineering 的灵魂之一,是反馈回路。
AI 改完代码以后,必须能自己验证。
对 Node/TypeScript 项目,可以在 package.json 里加:
然后每个任务都要求:
这句话比“注意代码质量”有用多了。
因为“代码质量”是口号。
npm run harness:check 是约束。
第 6 步:把团队品味变成脚本
真正厉害的 Harness,不只是跑测试。
它会把团队经常在 review 里说的话,变成自动检查。
比如:
-
单文件不要太长 -
UI 层不要直接访问数据库 -
service 不要依赖 UI -
不要在业务代码里散落 magic string -
关键路径必须有结构化日志 -
API 入参必须做 schema 校验
先从简单的做起。
比如文件行数检查:
再比如 UI 层禁止直接访问数据库:
然后加到 package.json:
这就是很朴素但很有效的 Harness Engineering。
人类 review 里反复讲的问题,不要每次都靠嘴说。
能写成检查,就写成检查。
第 7 步:给 AI 固定任务模板
AI 做任务不稳,很多时候是因为任务描述太糊。
不要再这样派活:
这句话信息量太低了。
你应该给项目加一个任务模板,比如 docs/TASK_TEMPLATE.md:
以后你给 AI 的任务可以这么写:
这时候 AI 就不是在自由发挥。
它是在流程里干活。
第 8 步:复杂任务必须先写执行计划
小任务可以直接改。
复杂任务最好先让 AI 写执行计划,放到:
模板如下:
执行计划有两个价值。
对 AI 来说,它是导航。
对人来说,它是审查点。
你可以先看计划对不对,再让 AI 开始写代码。这样比写完一大坨再返工舒服很多。
第 9 步:让应用对 AI 可观察
只让 AI 写代码,不让它看运行结果,这事很危险。
就像让一个工程师写完代码但不准启动项目。
一个最小可用的可观察性配置,至少包括:
-
能启动本地服务 -
能跑单元测试 -
能跑集成测试或端到端测试 -
能看到结构化日志 -
能跑 smoke test
前端项目可以这样:
日志也要尽量结构化。
不要只写:
更适合 AI 和系统排查的是:
为什么?
因为结构化日志可以搜索、可以聚合、可以跟踪,也更容易让 AI 判断发生了什么。
Harness Engineering 不是让项目看起来高级。
它是让项目能被智能体观察和修复。
第 10 步:把 PR 和 CI 也放进反馈回路
AI 不应该只在本地工作。
它还要能理解 CI 和 PR review。
加一个 docs/REVIEW_CHECKLIST.md:
以后可以让 AI 自查:
再进一步,你还可以让另一个智能体 review 这个 PR。
一个负责实现。
一个负责挑问题。
人类工程师重点看方向、边界和关键决策。
这就是智能体协作开始进入工程流程的样子。
第 11 步:定期做工程垃圾回收
AI 会放大项目已有模式。
好模式会被放大。
坏模式也会被放大。
所以 Harness 工程必须有周期性清理。
可以每周让 AI 跑一次这样的任务:
docs/QUALITY_SCORE.md 可以这样写:
这件事越早做越好。
不要等项目变成一团,再让 AI 进去救火。
一次完整实战:让 AI 做“订单 CSV 导出”

我们把前面的东西串起来。
假设你要做一个功能:
不要直接丢一句“帮我做导出”。
你应该这样派活:
AI 接到任务以后,理想流程应该是:
如果它中途失败,不要急着骂模型。
你要问一个更工程化的问题:
它为什么失败?
常见原因大概是这些:
-
找不到业务规则:补 docs/product-specs/ -
不知道架构边界:补 ARCHITECTURE.md -
改完没验证:强化 harness:check -
测试太难跑:修测试环境 -
不知道错误原因:补结构化日志 -
老犯同一个错:写 lint 或 harness 脚本
这才是 Harness Engineering 的日常循环。
你看,这件事的重点不是“调教一次 AI”。
而是持续改造工程系统。
常见坑
坑 1:把 AGENTS.md 写成百科全书
AGENTS.md 不是知识库。
它是地图。
越短越好,重点是告诉 AI 去哪里找信息。
坑 2:只有文档,没有检查
文档能提醒,检查能拦住。
能机器化的规则,尽量机器化。
坑 3:只让 AI 写代码,不让它跑结果
这会让 AI 变成盲写。
最少也要有:
更好的情况是再加:
坑 4:文档过期没人管
过期文档对 AI 的伤害比对人更大。 人类看到文档不对,可能会怀疑一下。 AI 很可能认真执行错误信息。 所以文档也要进入 review 和周期性清理。
坑 5:把人的判断永远留在人脑里
每次 review 出现这种话:
都应该追问一句:
这能不能变成文档?
能不能变成测试?
能不能变成 lint?
能不能变成 harness 脚本?
工程能力就是这么沉淀出来的。
Harness Engineering 的真正转变
以前工程师最重要的产出,可能是自己写了多少代码。 但在智能体越来越强的时代,工程师更重要的产出会变成:
-
设计清晰架构 -
沉淀项目知识 -
建立反馈回路 -
把品味变成规则 -
把隐性经验变成系统能力 -
让 AI 智能体在系统里稳定交付
这不是工程师变弱了。
恰恰相反,这是工程能力被放大了。
未来真正稀缺的,可能不是“会不会让 AI 写一个函数”。
而是你能不能搭出一个环境,让一组 AI 智能体稳定地做需求、修 bug、跑验证、处理反馈、持续交付。
一句话收尾:
Harness Engineering 的核心,不是让 AI 更听话,而是让项目本身变得足够清晰、可验证、可观察、可维护,让 AI 可以在里面靠谱工作。
把 Prompt 写好,只是开始。
把工程系统搭好,才是真正的分水岭。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。