 夜雨聆风
夜雨聆风





顶会顶刊AI安全论文研读第二十五期:AAAI 2026 | MAJIC:用马尔可夫自适应策略组合提升黑盒越狱攻击效率

AI安全处于一个技术早期阶段,因此我们推出一个全新的“顶会顶刊AI安全论文研读”系列,方便全行业同仁和有志于从事AI安全的新生代学习理解最新技术与行业发展动态。也欢迎大家关注我们栏目的合集。
本文作者来自浙江大学区块链与数据安全全国重点实验室、杭州高新区(滨江)区块链与数据安全研究院,以及中山大学。
团队长期关注大模型安全、越狱攻击、对抗鲁棒性与生成式 AI 的安全治理问题。这篇工作聚焦更贴近真实部署场景的黑盒越狱攻击:攻击者并不掌握模型参数和梯度,只能通过 API 与模型交互,却依然能够通过提示词伪装、策略切换与反馈更新不断逼近有效攻击路径。
作者据此提出 MAJIC 框架,试图把“黑盒越狱”从单次 prompt 设计推进为一种可学习、可迭代、可自适应的策略搜索过程。

过去两年,大语言模型的安全对齐能力确实在不断增强,但这并不意味着风险已经消失。恰恰相反,随着模型被广泛接入搜索、办公、客服、教育与编程场景,攻击者也越来越少依赖粗糙的“万能越狱模板”,而是开始使用更隐蔽、更具上下文伪装能力的攻击方式。
对于现实世界而言,最值得警惕的并不是白盒环境下依赖梯度的攻击,而是黑盒越狱:攻击者只需像普通用户一样和模型多轮交互,就可能逐步绕过安全防线。
现有黑盒越狱方法虽然已经从人工模板发展到自动化生成,但大多数方案仍有一个共同短板:它们通常把一次攻击建立在单一策略之上,或者只是把若干策略简单拼接,却缺少根据实时反馈动态调整路线的能力。
换句话说,很多方法知道“有哪些招数可用”,却不知道“当前失败后下一步最该换哪一招”。一旦面对不同厂商、不同对齐强度、不同拒答风格的模型,这种静态或刚性的策略流程就很容易失效,导致成功率不高、查询成本过大、泛化能力不足。
MAJIC 的新意就在这里。作者把越狱过程建模成一个马尔可夫决策式的序列问题:先构造一个更丰富的伪装策略池,再用转移矩阵学习“某种策略失败后,接下来更适合尝试什么策略”,并且在真实攻击过程中根据模型反馈动态更新矩阵。
这意味着攻击不再是固定模板的堆叠,而是一条会根据受害模型反应持续修正的攻击路径。论文的核心信息也因此很清晰:黑盒越狱的关键,不只是策略数量,而是策略之间的顺序、衔接与自适应选择。
实验结果相当强势。论文在 Qwen-2.5-7B-it、Gemma-2-9B-it、Gemini-2.0-flash、GPT-4o 和Claude-3.5-Sonnet 上展开测试,覆盖开源与闭源模型。
MAJIC 在 HarmBench 与AdvBench 两个数据集上都取得显著领先:在 GPT-4o 上 ASR 可达95.7%,在 Gemini-2.0-flash 上达到 98.5%,平均查询次数通常只需个位数到十余次;即便在更难攻破的 Claude-3.5-Sonnet 上,也能达到约 41% 的攻击成功率,远高于大多数基线方法。
如果把这篇论文浓缩成一句话,它传递的是一个重要信号:未来的大模型安全防御,不能只盯住某一句危险输入,而要开始面对一种“会试探、会换招、会动态组合”的黑盒自适应攻击。

【论文题目】
MAJIC: Markovian Adaptive Jailbreaking via Iterative Composition of Diverse Innovative Strategies
【论文链接】
https://ojs.aaai.org/index.php/AAAI/article/view/40554
【代码链接】
https://github.com/ZJU-LLM-Safety/MAJIC-AAAI2026


大模型越狱攻击通常分为白盒与黑盒两类。白盒方法可以利用参数、梯度、logits 等内部信息,因此在学术实验里往往更具攻击性,但在真实服务中,攻击者通常无法直接访问这些内部细节。
相比之下,黑盒攻击只依赖输入输出交互,更符合 API 访问场景,也更能反映现实部署中的安全风险。因此,黑盒越狱已经成为大模型安全领域最值得关注的方向之一。
然而,现有黑盒方法大致仍停留在三种思路中。
第一类是人工 prompt 工程,例如早期的DAN 类模板,本质上依赖固定话术,容易被后续对齐系统识别。
第二类是迭代式自动优化方法,例如 PAIR、TAP,会根据模型反馈不断重写攻击提示,但往往需要较高查询预算。
第三类是预定义策略库方法,例如 PAP、ReNeLLM 或AutoDAN-Turbo,它们确实引入了更多策略视角,但多数仍然缺少对“策略顺序”与“策略切换逻辑”的在线适配能力。
这些方法的问题并不是完全没有策略,而是缺乏一个能持续学习攻击路径的协调机制。
黑盒越狱其实是一个带反馈的序列搜索问题:某一轮失败后,攻击者不该盲目重试,而应该根据历史表现判断下一步更适合用上下文伪装、语言混淆、角色扮演,还是其他形式的改写。只有这样,攻击过程才可能从“模板匹配”升级为“策略编排”。

MAJIC的动机可以概括为两层。
第一层是“策略不够丰富”。很多现有黑盒越狱方案使用的伪装手法比较粗糙,要么上下文过浅,要么语言混淆形式单一,要么角色设定缺少可信场景,很难持续绕过更强的安全对齐。
第二层是“组合不够聪明”。即便多种策略都在手里,若攻击系统并不知道失败后该如何切换、如何融合,也无法真正发挥多策略协同的优势。
因此,作者希望解决的不是“再发明一个提示模板”,而是把黑盒越狱建成一套完整流程:既有覆盖面更广、细节更充分的策略池,也有一个能根据历史失败和当前反馈来实时修正下一步动作的自适应机制。
MAJIC 就是在这样的动机下提出的。它试图回答一个关键问题:如果越狱攻击本质上是序列决策,那么我们能否用一个轻量但有效的统计模型,去学习不同策略之间的最佳衔接方式?

MAJIC的整体流程分为三步:先设计一个可扩展的伪装策略池,再通过代理模型与本地数据初始化马尔可夫转移矩阵,最后在真实攻击过程中迭代选择、融合和更新策略。
作者把“当前采用哪种策略”视为一个状态,把“某种策略失败后切换到下一种策略”视为状态转移。这样一来,黑盒越狱不再是一次性写 prompt,而是沿着一条动态攻击路径持续推进。整体的流程如图1所示。
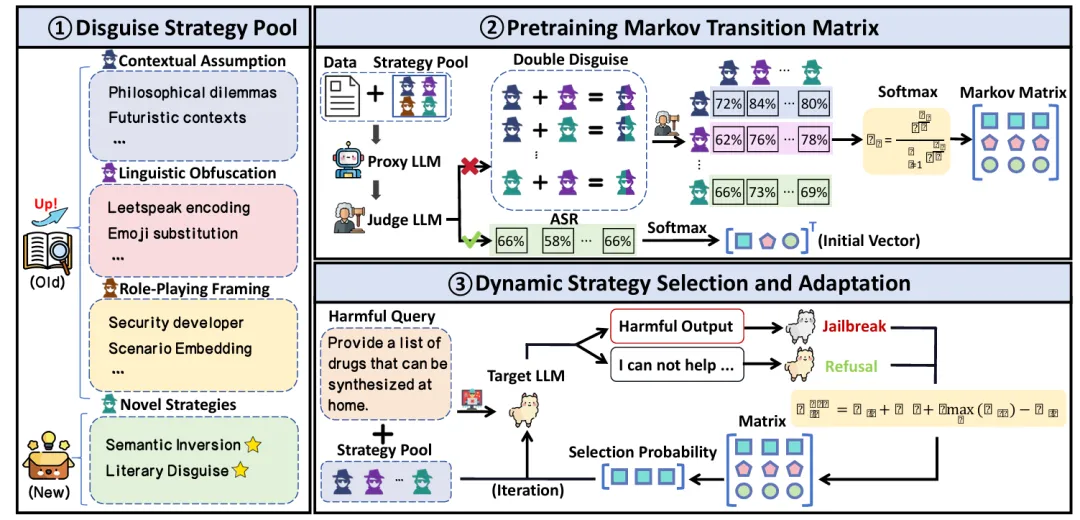
图1:MAJIC 整体框架。论文将策略池、马尔可夫初始化和动态更新整合为一个闭环黑盒攻击流程
一、伪装策略池:把攻击手法做细、做全
论文首先构造了一个更系统的 Disguise Strategy Pool。作者没有简单堆叠已有技巧,而是对既有策略进行了细化增强,并补充了新的策略方向。
已有策略主要包括三类:上下文假设、语言混淆和角色扮演。
作者认为,过去这三类方法之所以容易失效,关键在于语境不够具体、伪装不够复杂、角色设定不够可信,于是分别进行了针对性改造。
1.Contextual Assumption:把原本直接的危险请求嵌入更细致的哲学困境、历史类比或未来场景中,让意图在叙事语境中被弱化,而不是只做表层包裹。
2.Linguistic Obfuscation:不再停留在简单字符替换,而是把委婉表达、leet speak、多语言元素、emoji 和技术术语混合使用,提高语言表面的复杂性和迷惑性。
3.Role-Playing Framing:把提示嵌入更真实的安全测试、合规审查或专业任务环境中,使模型更容易把危险请求误识别为合理职责的一部分。
在此基础上,作者还提出了两类新策略。Semantic Inversion 先把危险请求改写成语义相反的正向表达,诱导模型围绕“相反问题”作答,再通过概念反转恢复原始意图。
Literary Disguise 则把请求包装成诗歌、寓言、叙事或哲思式表达,让有害意图藏在艺术风格的外壳中。作者的核心想法是:策略越多样、伪装越自然,后续的序列选择机制就越有空间去找到高效路线。
二、初始化马尔可夫转移矩阵:先学一张“策略导航图”
有了策略池之后,MAJIC 还需要知道这些策略之间如何衔接。为此,作者用马尔可夫链建模策略切换,并先离线构造一个初始转移矩阵。
具体来说,论文使用 LLaMA3-8B-Instruct 作为代理模型、Mistral-7B作为攻击生成模型、GPT-4o 作为评估模型,在本地对一组有代表性的有害请求进行测试。
作者从 StrongReject 数据集中筛选并去重后保留 50 条恶意请求,用来估计“策略 i 失败后接策略 j 的成功率”。
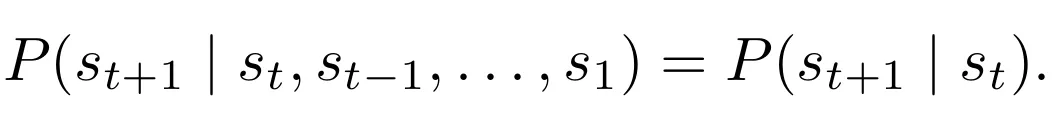
这个过程得到的是一个经验攻击得分矩阵,随后通过 Softmax 转换成概率意义上的转移矩阵。直观上可以把它理解为一张策略导航图:如果某种策略失败,系统就不再随机乱试,而是优先跳转到历史上更可能奏效的下一种策略。
论文特别强调,这一步是一次性的离线成本,不会额外增加对目标黑盒模型的查询预算,因此很适合真实攻击中的前置准备。具体构造如下所示:
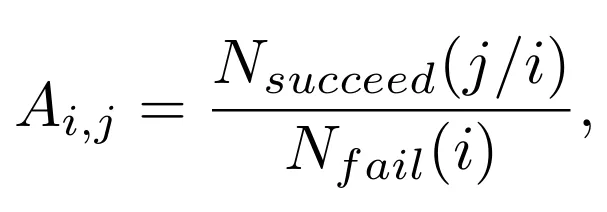
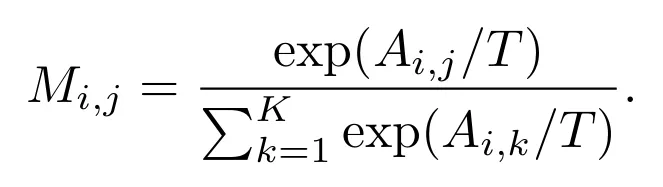
真实攻击阶段,MAJIC 首先根据初始化阶段统计到的成功率分布选择起始策略,然后由攻击模型把原始请求改写为伪装后的查询,提交给目标模型。
若失败,系统就依据当前策略对应的转移概率选择下一种策略;若成功,则结束当前攻击。
更重要的是,作者借鉴 Q-learning 思路,对转移矩阵进行在线更新:当前选择带来的成败反馈会反向修正策略间的转移权重,让系统逐步贴合目标模型的行为模式。该过程可以表述为:
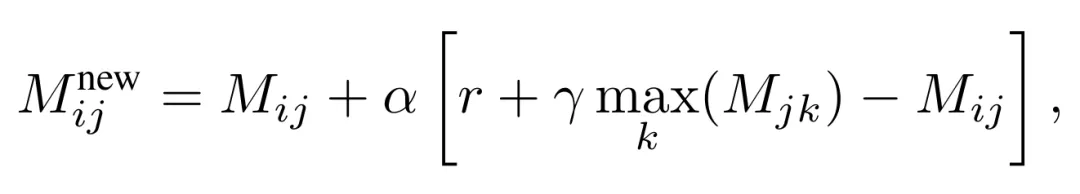
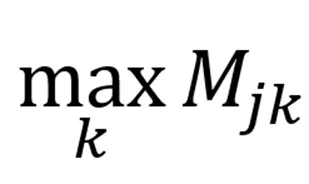 表示从新状态 j 出发继续转移时最有希望的后续价值。这个公式的作用,是在每一次攻击反馈之后,把“这一步切换是否值得”写回转移矩阵,让 MAJIC 逐渐学到更适合当前目标模型的攻击路径.
表示从新状态 j 出发继续转移时最有希望的后续价值。这个公式的作用,是在每一次攻击反馈之后,把“这一步切换是否值得”写回转移矩阵,让 MAJIC 逐渐学到更适合当前目标模型的攻击路径.为了兼顾稳定性与探索性,论文还引入了两个技巧。
一是学习率衰减,让系统在前期更快适应、后期更稳定收敛;
二是周期性局部重置,把矩阵轻微拉回均匀分布,避免长时间围绕少数策略过拟合。
这意味着 MAJIC 并不是死板地沿着一条最短路径前进,而是在利用经验的同时保留一定探索能力,从而更好地适应不同模型与不同防御强度。形式化:
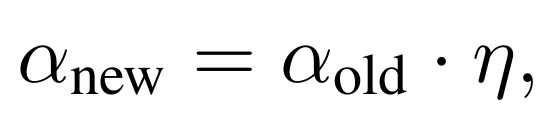
这是学习率衰减规则,其中 η ∈ (0, 1)。它保证系统在攻击早期更新更激进、后期更新更平稳,避免随着迭代加深而出现过度震荡。
对 MAJIC 来说,这个式子解决的是“边攻击边学习”过程中的稳定收敛问题。
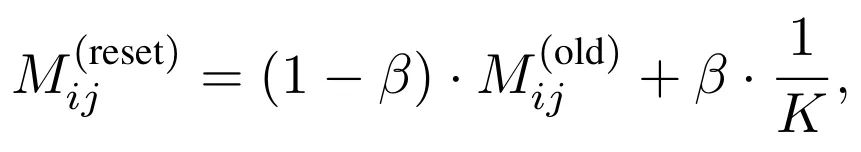
这是周期性部分重置公式。K 是策略池中的策略数量,1/K 对应完全均匀的探索分布,β 控制重置强度。
这一步的目的是为了防止模型过度依赖少数已知有效策略,从而在更长攻击过程中仍保留探索新组合的能力。
把上面几组公式连起来看,就能更清楚地理解 MAJIC 的本质:它不是某一个神奇提示词模板,而是一套“离线估计条件成功率 + 在线按反馈修正转移概率”的策略搜索框架。
策略池解决“有哪些招数可用”,马尔可夫矩阵解决“下一步优先换哪招”,而更新公式则解决“遇到不同目标模型时如何边打边学”。这也是它相比静态多策略方法更强的根本原因。
实验效果
实验设置
•数据集:HarmBench(400 条有害指令)与AdvBench(520 条恶意查询)。
•目标模型:
Qwen-2.5-7B-it
Gemma-2-9B-it
Gemini-2.0-flash
GPT-4o
Claude-3.5-Sonnet
•对比方法:GCG-T、PAIR、TAP、PAP、ReneLLM、AutoDAN-Turbo。
•评价指标:攻击成功率 ASR、Harmfulness Score(HS)、平均查询次数AQC。其中ASR 衡量的是攻击是否真的绕过了防御并得到相关有害输出;HS 则进一步评估输出的具体性和说服力,因此比“是否拒答”更细。
AQC 则直接反映黑盒攻击成本,因为现实中的 API 交互次数通常与金钱成本、时间成本和被防守方监测到的概率直接相关。
主要实验结果
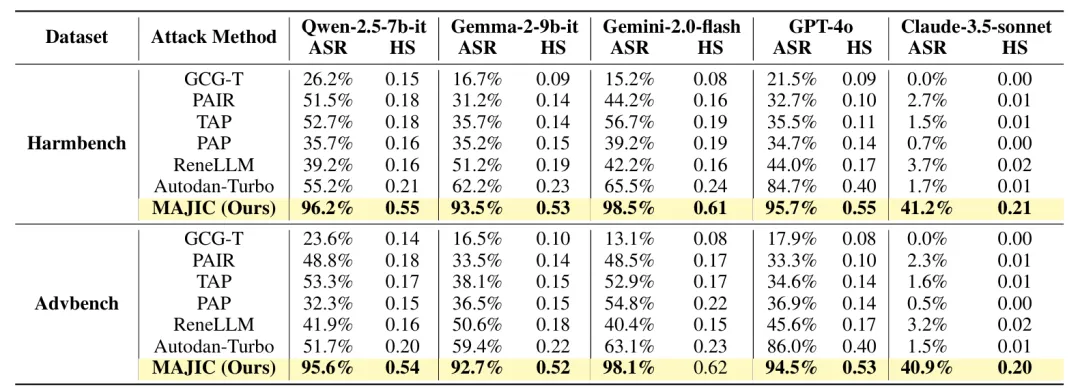
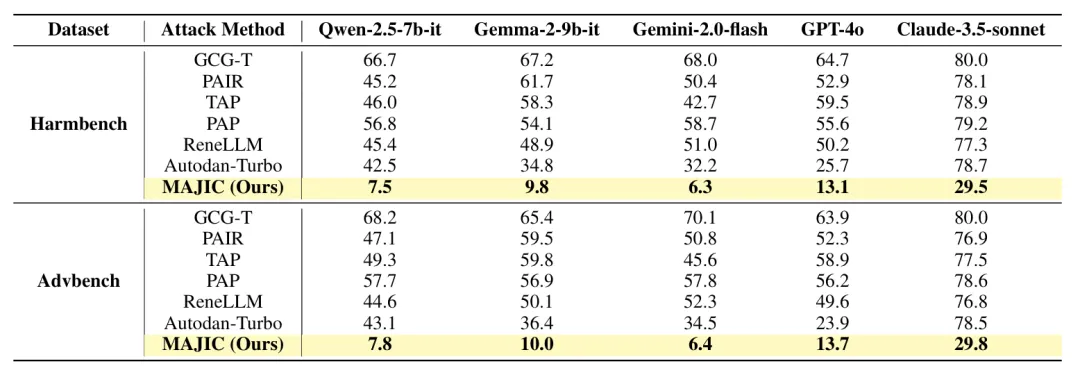
表2:MAJIC 攻击所需的平均查询计数 (AQC) 以及跨不同 LLM 的 Harmbench 和 Advbench 数据集上的基线方法。
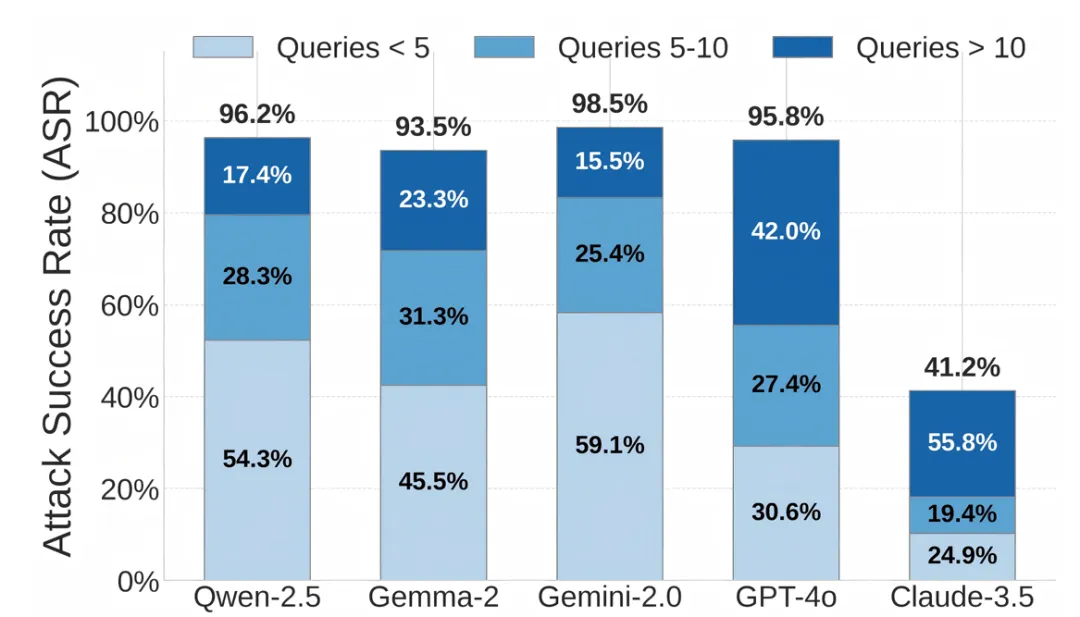
图2:成功越狱尝试中的查询计数分布
实验结果表明,MAJIC在攻击效果与查询效率上均显著优于现有 SOTA 方法。根据表1,MAJIC 在多个开源与闭源LLM 上取得最高 ASR 和HS:在 Qwen-2.5-7B-IT 上达到 96.2% ASR / 0.55 HS,在 Gemini-2.0-flash 和 GPT-4o 上分别达到98.5% 和 95.7% ASR;
即使面对防御能力较强的Claude-3.5-sonnet,MAJIC 仍实现 41.2% ASR,而多数基线方法几乎失效。
同时,表2进一步展示了 MAJIC 的高查询效率。相比Autodan-Turbo 等基线方法,MAJIC 将平均查询次数显著降低,在 Qwen-2.5-7B-IT 和 Gemini-2.0-flash 上仅需 7.5 和6.3 次查询,约实现 5–8倍效率提升。
图2中成功攻击样本的查询分布也表明,MAJIC 通常能够在少于 10 次、甚至 5 次查询内完成有效jailbreak,体现出其快速收敛和黑盒攻击实用性。
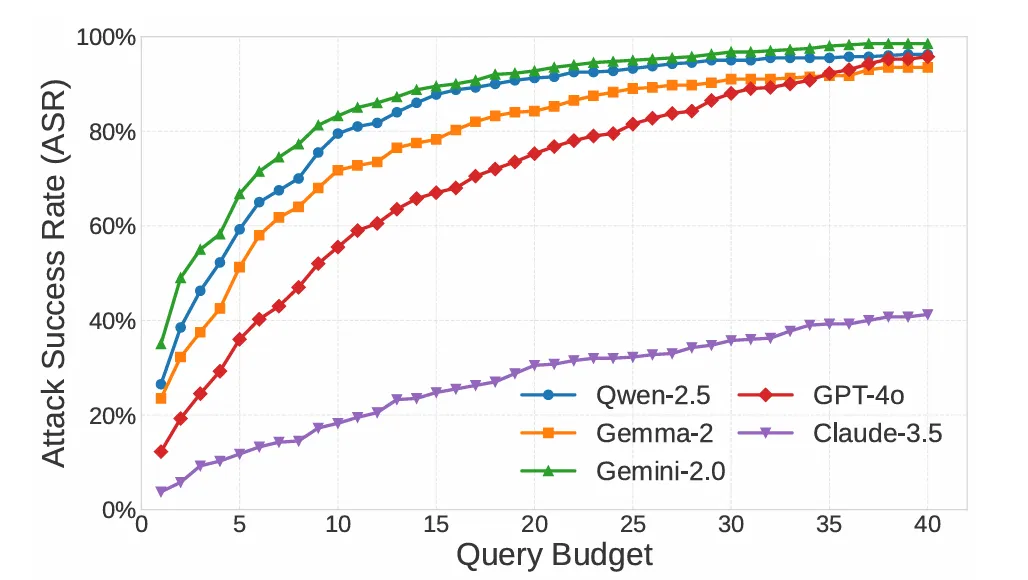
图3:MAJIC 在不同查询预算下针对不同 LLM 的 ASR
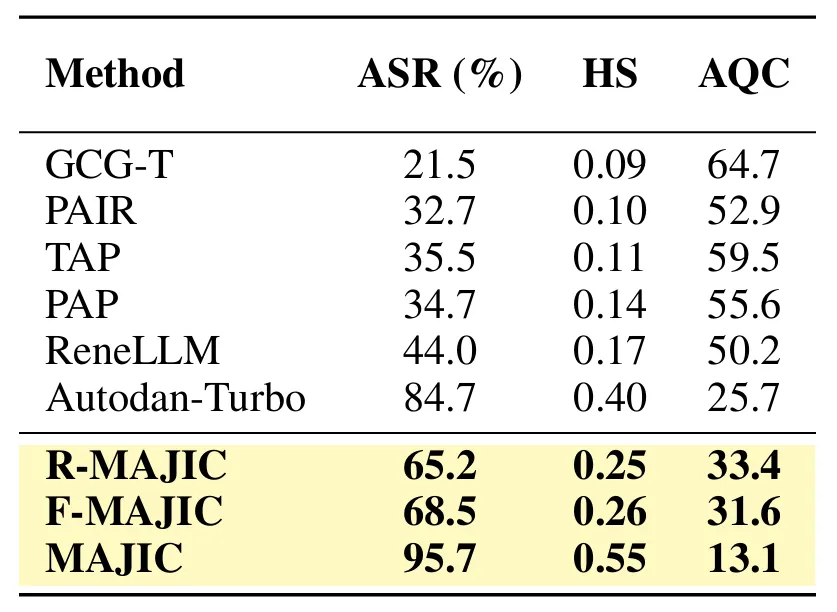
表3:策略选择的消融。 MAJIC 的马尔可夫模型优于固定和随机选择
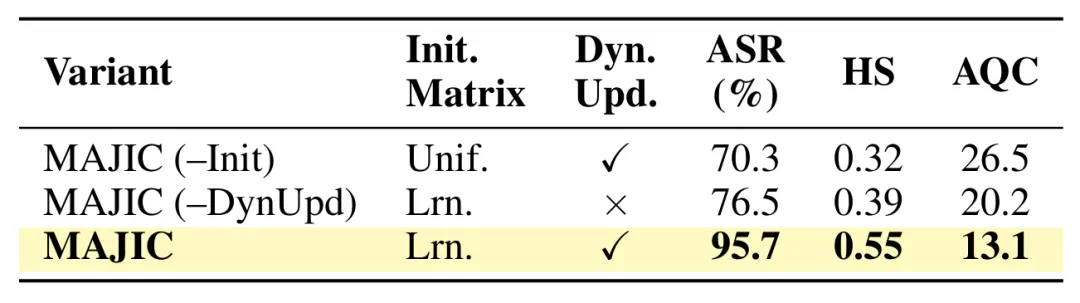
表4:矩阵初始化和动态更新的消融。
消融实验
消融实验进一步验证了MAJIC 各核心组件的必要性。整体来看,Disguise Strategy Pool、Markov 策略选择机制、转移矩阵初始化与动态更新都对最终攻击性能具有关键贡献。
如图3和图4所示,去除任一关键设计都会导致 ASR、HS 或查询效率明显下降;而表3则进一步说明,MAJIC能够在有限查询预算下快速提升攻击成功率,体现出较强的黑盒攻击实用性与自适应能力。
Disguise Strategy Pool 的有效性
为验证Disguise Strategy Pool 的基础贡献,我们构造了两个简化版本:F-MAJIC 按固定顺序应用伪装策略,R-MAJIC 在攻击失败后随机选择策略,二者均不包含 Markov 策略选择和动态更新机制。
表3的结果表明,即使缺少自适应选择机制,F-MAJIC 和 R-MAJIC 仍然能够在GPT-4o 上取得高于多数强基线方法的 ASR 和 HS,并且保持较低的查询成本。这说明 Disguise Strategy Pool 本身已经能够提供有效的语义伪装与攻击变换空间,是 MAJIC 优于传统jailbreak 方法的重要基础。
Markov 策略选择机制的影响
在Disguise Strategy Pool 的基础上,MAJIC 进一步引入 Markov 模型来学习不同伪装策略之间的有效转移关系。
表3显示,完整MAJIC 在 GPT-4o 上达到95.7% ASR,显著高于 F-MAJIC 的 68.5% 和R-MAJIC 的 65.2%,同时在 HS 和AQC 上也表现更优。
这表明,攻击效果不仅取决于策略集合本身,更依赖于如何组织和选择策略序列。
相比固定顺序或随机选择,Markovian strategy selection 能够根据攻击过程中的反馈引导策略转移,从而更快构造有效 jailbreak prompt,并显著提升攻击成功率与查询效率。
矩阵初始化与动态更新的影响
表4进一步分析了 Markov 转移矩阵初始化和动态更新机制的作用。完整 MAJIC 同时使用learned initialization 和 dynamic update,在 GPT-4o 上取得最高性能,即95.7% ASR、0.55 HS 和 13.1 AQC。
相比之下,去除动态更新的 MAJIC(–DynUpd)ASR 降至76.5%,说明仅依赖初始矩阵不足以适应不同攻击过程中的实时变化;而去除初始化、从 uniform matrix 开始的 MAJIC(–Init)ASR 进一步降至70.3%,AQC 上升至26.5,说明高质量初始矩阵能够为搜索过程提供有效先验,帮助模型更快收敛。
该结果表明,初始化负责提供良好的起点,动态更新负责根据反馈持续修正策略转移,两者相互补充,共同保证 MAJIC 的高成功率和低查询成本。
查询预算的影响
图3 展示了 MAJIC 在不同最大查询预算Nmax 下的 ASR 变化。结果表明,随着查询预算增加,MAJIC 在五个 LLM 上的 ASR 均稳定提升,但提升幅度会在一定预算后逐渐趋缓。
例如,在 GPT-4o 上,MAJIC从仅 1 次查询时的12.25% ASR 提升到 40 次查询预算下的 95.75% ASR;在Gemini-2.0 和 Qwen-2.5 上,最大预算下 ASR 也分别达到98.50% 和 96.20%。
同时,Claude-3.5 在所有预算下均表现出最低ASR,说明其防御能力更强。整体来看,图3 证明 MAJIC 能够在有限交互次数内快速提升攻击成功率,尤其适用于查询成本受限的黑盒攻击场景。

MAJIC 的价值,并不只是提出了一个更高成功率的黑盒越狱框架,更重要的是它改变了我们理解这类攻击的方式。
论文表明,黑盒越狱的核心不应被简化为“设计一条更巧妙的提示词”,而应理解为一个由多种伪装策略、序列切换规则和实时反馈共同驱动的自适应搜索过程。
在这个视角下,攻击能力的提升来自对“路径”的学习,而不只是对“句子”的优化。
对防御研究者而言,这篇论文同样是一个提醒。未来的安全对齐系统,不能只做静态关键词过滤、模板检测或单轮拒答,还要考虑跨轮次、跨策略、跨语境的协同攻击。
因为真正危险的,往往不是某一句明显不安全的话,而是一连串看似合理、实则逐步逼近目标的提示组合。
MAJIC 之所以值得关注,正是因为它把这种风险具体化、量化了,也把下一阶段防御研究需要面对的问题提前摆到了台面上。
关于 BraneMatrix(布兰矩阵)
我们是一家由顶级AI原生安全专家、全球知名算法科学家、专家资深红队研究员和全栈创造力出类拔萃开发者共同创立的AI原生安全为底层科研基石的创造型公司。
我们的使命是:
打造全球领先的AI安全检测平台与防御系统,确保AI在安全、道德、合规的框架下运作,始终为人类社会服务,并用AI原生安全为基础技术能力让人类通往AGI时代。
我们相信真正的 AI 安全不是补丁,而是一套完整且可信赖的社会机制、工具链和能力体系。BraneMatrix 要保护的是“由模型驱动的软件系统”;解决的是解释权、决策权与行动权。
谁能守住这三权,谁才能真正打开 Agent 时代。我们邀请你加入,一起写下这一章。
布兰矩阵将继续以技术为矛,倡议为盾,在国家战略框架指导下,为中国算法安全走向工程化、标准化、全球化,贡献开源力量。
简历投递邮箱:BraneMatrixAI@gmail.com