 夜雨聆风
夜雨聆风





AI SoC、AI处理器设计一网打尽
00
景芯AI SoC团队业务
(2)芯片定制服务:提供AI SoC、MCU的spec in设计验证及中后端服务,提供MIPI/ISP/NPU/GPU/CPU/VPU/USB/GMAC/SDIO/PSARM/DDR/PCIE/eMMC等IP的培训、集成服务,提供CIS传感器定制服务,介绍design servie业务(有丰厚提成),期待您的加入!
01
景芯SoC设计实战课汇总
-
实战课1:基础实战课(UART、I2C、QSPI/SPI)
-
实战课2:进阶实战课(AXI/AHB Fab、MIPI、ISP、NPU-lite)
-
实战课3:RISC-V AI处理器实战
-
实战课4:PCIE实战
-
实战课5:DDR/LPDDR实战
-
实战课6:安全算法实战(AES、HASH、HMAC)
-
实战课7:AXI PSRAM实战(及GMAC、USB、EMMC、SPI NAND/NOR)
02
基础实战课+进阶实战课
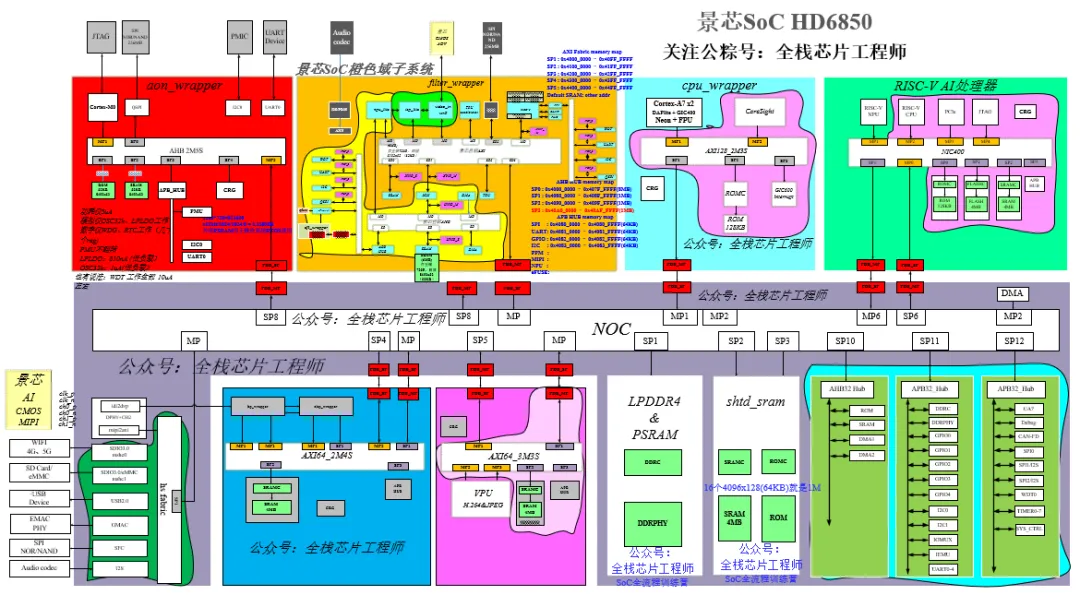
第一实战部分:橙色域子系统独立开发成一颗AI MCU芯片,采用低功耗RISC-V自研架构,全部自研实现了AXI总线矩阵、AHB总线矩阵、MIPI DPHY软核、ISP-Lite、NPU-lite、SRAM、DMA、UART、I2C、QSPI/SPI等常用IP,项目设计验证架构如下:
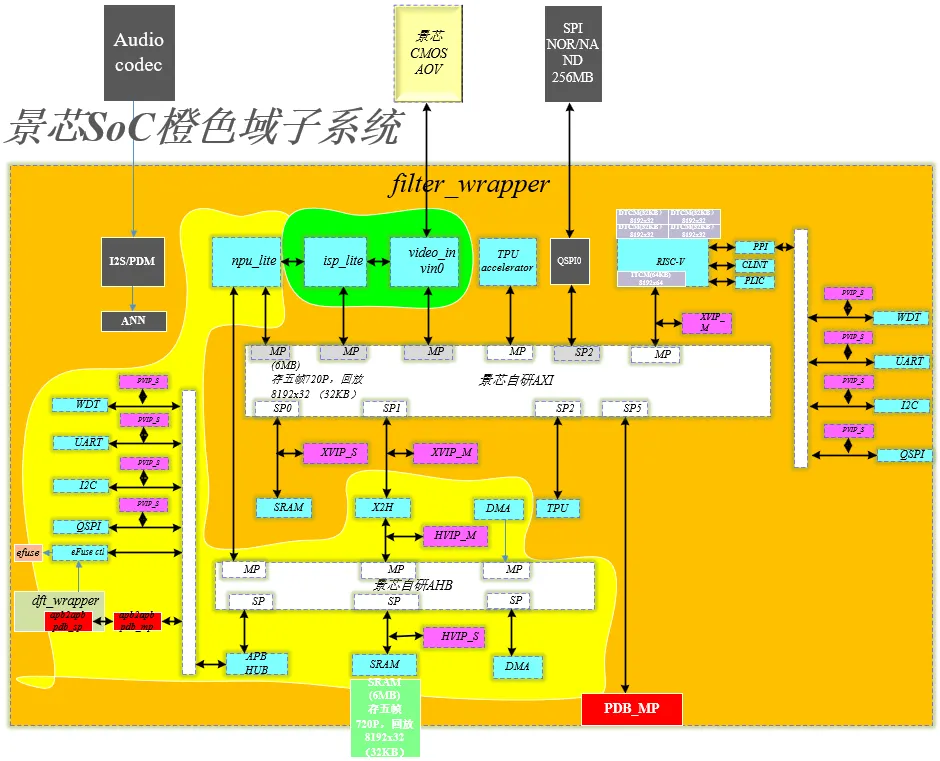
景芯橙色域子系统分为三个subchip子系统,包括media_wrapper、amba_wrapper、cpu_wrapper三个subchip,每个subchip的功能描述如下:
-
media wrapper(上图青色部分)负责MIPI图像输入、DPV图像输入、异步处理、ISP图像处理。
-
amba wrapper(浅黄色部分)负责接收media wrapper传递过来的经过ISP预处理过的图像,通过专用DMA搬运数据到amba wrapper系统主存SRAM,DMA搬运完成后,CPU配置NPU搬运系统主存SRAM的图像数据去做矩阵运算(卷积)。
-
cpu wrapper负责RISC-V CPU、TCM、自研AXI总线矩阵的译码、仲裁、AXI2AHB总线桥、中断系统、低功耗PMU管理等功能。NPU卷积完成后,RISC-V CPU执行WFI指令进入休眠模式。通过isolate信号和retain信号进行时钟门控、电源门控。
为了满足不同经验的学员需求,景芯开发了两套环境分别作为进阶课和基础课,带您一起手搓AXI总线矩阵、AHB总线矩阵、ISP-Lite、NPU-lite、MIPI DPHY软核、SRAM、DMA、UART、I2C、QSPI/SPI等常用IP,让您快速掌握架构、总线协议、接口协议、图像算法、软硬件协同验证等设计核心,让您快速超越同龄人!
Part.01
设计实战基础课
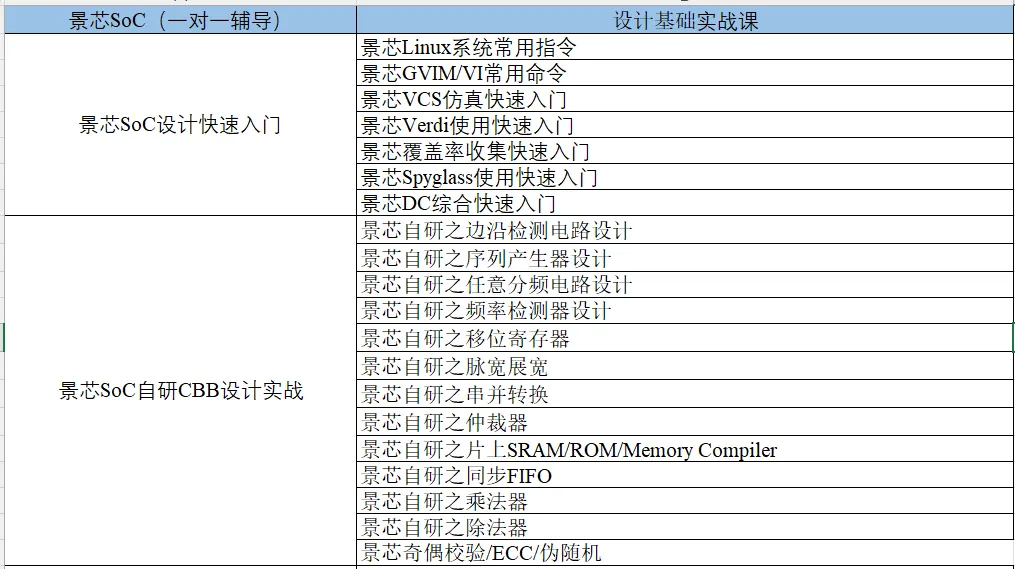
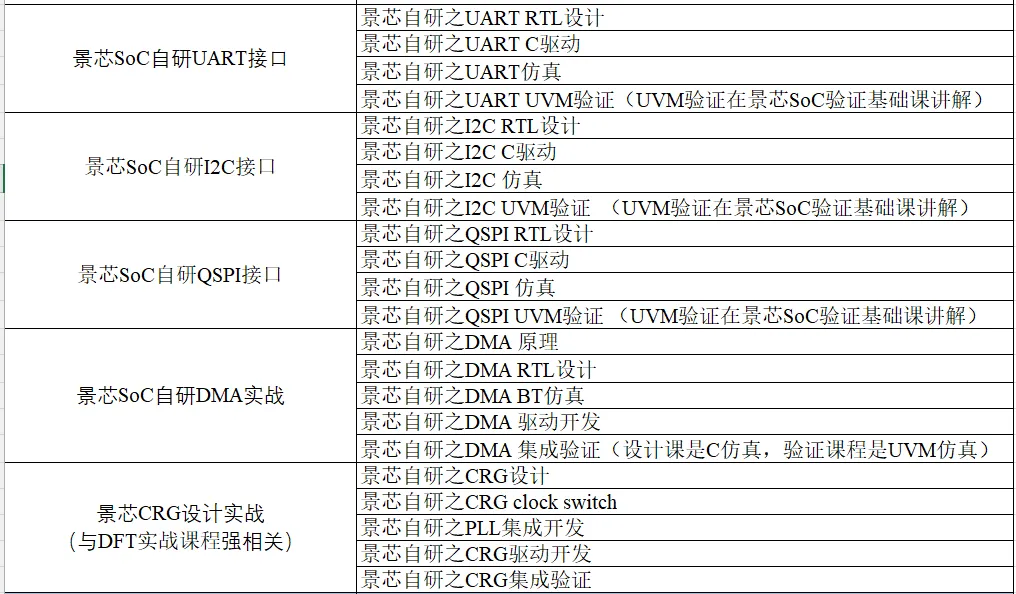
一对一辅导是景芯SoC全流程训练营的特色!景芯SoC设计实战基础课最新课表如下:

Part.02
设计实战进阶课
景芯SoC设计实战进阶课最新课表如下(买进阶课、送基础课):
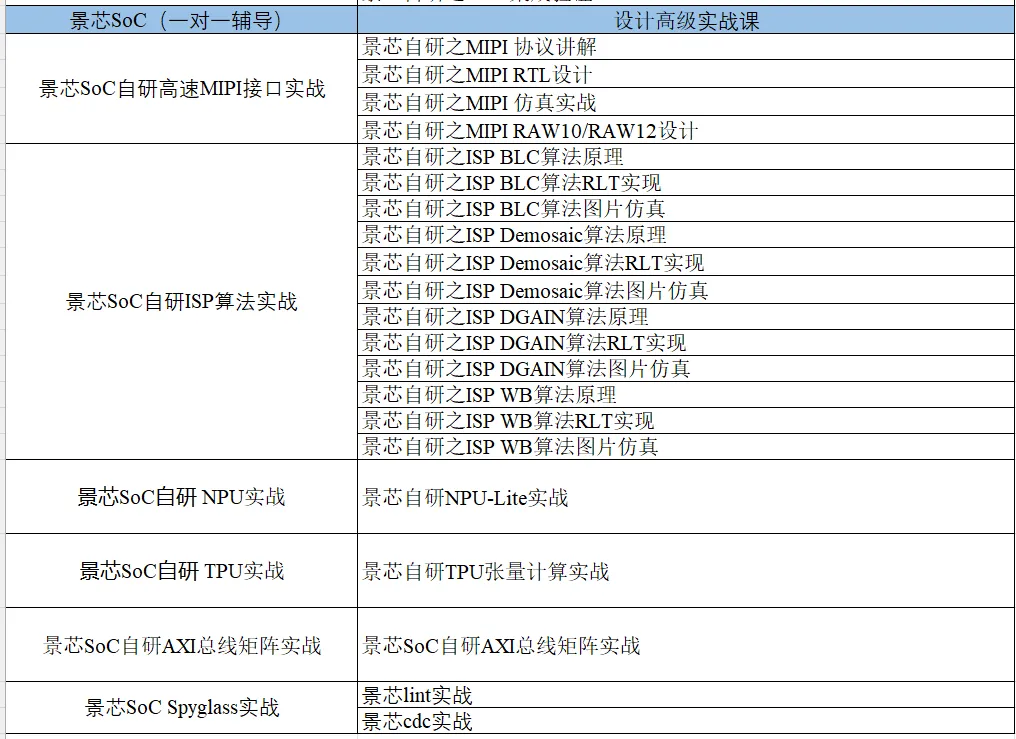
03
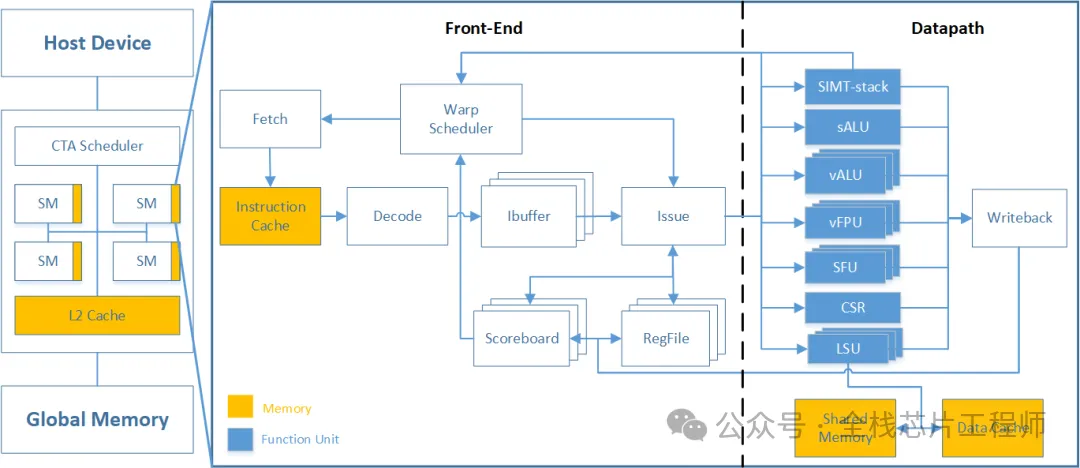
Part.01
AI处理器实战目录
景芯AI处理器项目,兼容RISC-V架构,向上可GPU、向下可NPU!
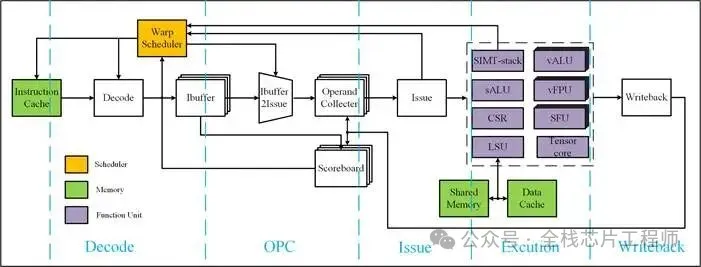
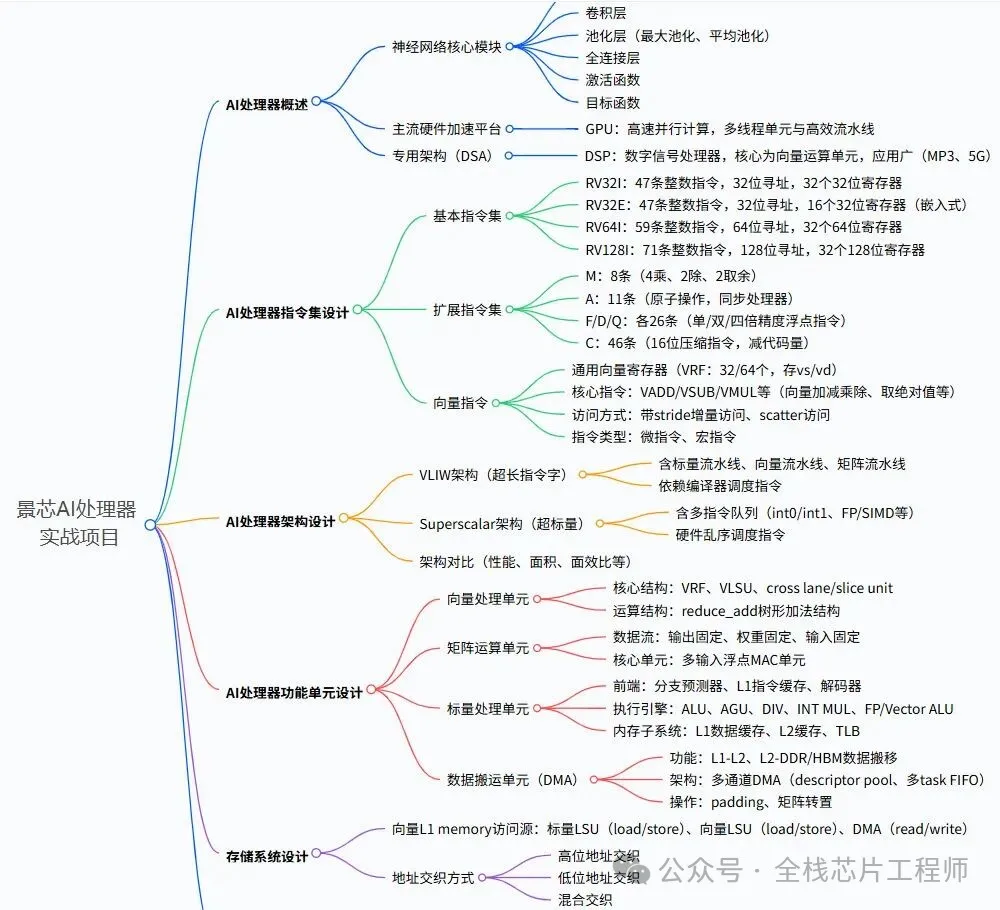
第一部分:AI处理器架构
1.1 AI计算芯片发展历程
-
从通用CPU到专用AI芯片的演进
-
不同AI工作负载对芯片架构的需求
-
云端与边缘AI处理器的差异
1.2 主流AI处理器架构对比
1.2.1 专用AI加速器(ASIC)
-
Google TPU架构深度解析
-
脉动阵列计算模式优势与局限
-
固定功能单元与可编程性平衡
1.2.2 可重构AI处理器(FPGA)
-
硬件可编程性在AI中的应用
-
动态重配置适应算法演进
-
能效与灵活性的折中设计
1.2.3 神经处理单元(NPU)
-
移动端AI加速器设计理念
-
功耗约束下的架构优化
-
端侧模型压缩与硬件协同
1.2.4 图形处理器(GPU)
-
从向量处理器到现代GPGPU的架构发展
-
GPU和GPGPU架构对比
-
GPGPU在AI和高性能计算中的应用场景
-
GPU同其他AI架构的对比及优势
1.2.5 图形处理器(GPU)架构选择
-
为什么选择GPGPU作为AI处理器基础
-
通用并行计算与AI工作负载的契合度
-
软件生态与开发生态优势
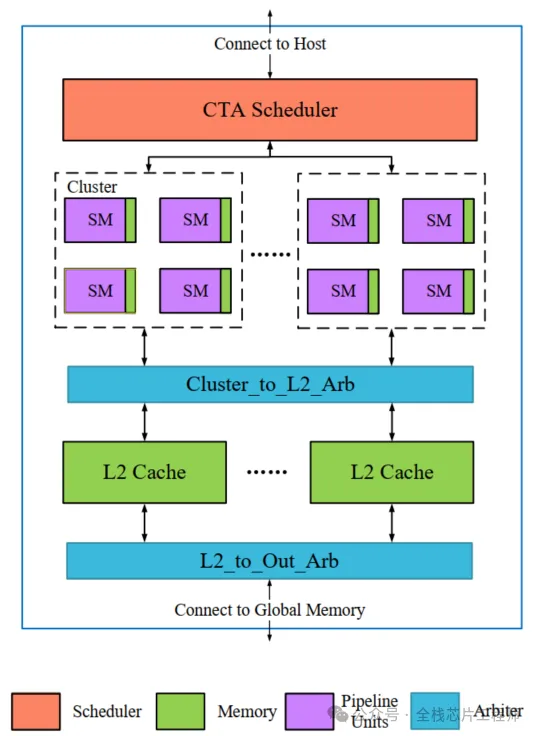
第二部分:GPGPU架构作为AI处理器的优势
2.1 AI工作负载特性与GPGPU架构匹配度
-
矩阵运算的并行化本质
-
神经网络层间的数据流并行性
-
训练与推理的差异化架构需求
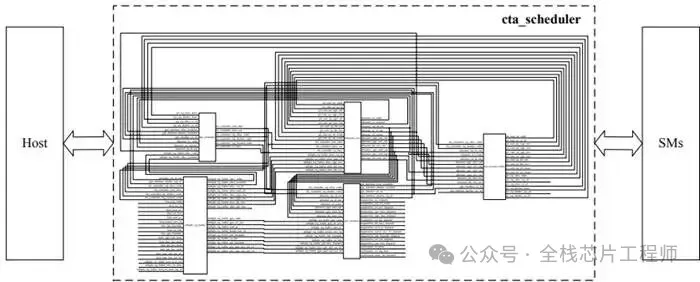
2.2 景芯定制化GPGPU核心架构解析
-
整体硬件架构框图与组件交互
-
流多处理器(SM)集群组织方式
-
多层次存储体系结构深度分析
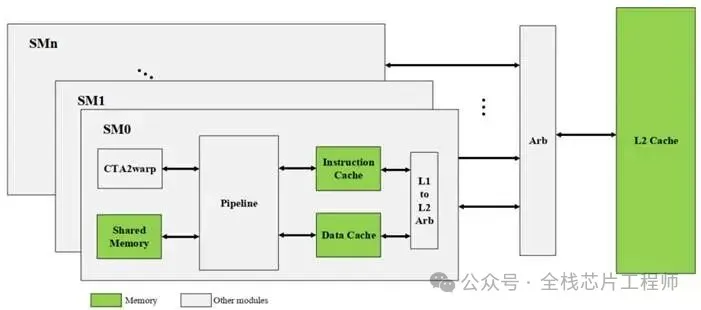
2.3 景芯定制化GPGPU特性
-
灵活的架构switch机制,可配置为NPU
-
混合精度计算硬件支持
-
张量核心专用运算单元
-
稀疏计算加速机制
第三部分:AI处理器微架构深度设计
3.1 并行计算架构优化
3.1.1 多层次并行度利用
-
数据并行与模型并行协同
-
指令级并行(ILP)优化技术
-
线程级并行(TLP)调度策略
3.1.2 AI专用执行单元设计
-
矩阵乘法单元优化实现
-
卷积计算专用数据通路
-
激活函数硬件加速
3.2 存储子系统AI优化
3.2.1 数据流优化架构
-
权重数据重用模式优化
-
特征图数据局部性利用
-
梯度计算存储访问模式
3.2.2 片上存储层次定制
-
共享内存AI工作负载优化
-
缓存替换算法AI特性适配
-
模型参数片上缓存策略
第四部分:AI专用指令集与编程模型
4.1 AI专用指令集扩展
-
张量运算指令设计
-
稀疏计算指令支持
-
量化运算指令实现
第五部分:芯片实现与验证
5.1 AI处理器RTL实现深度解析
5.1.1 AI处理器RTL架构介绍
5.1.2 关键AI计算模块1
-
Scheduler 模块
-
warp调度 -
寄存器堆 -
取指 -
译码 -
指令缓冲 -
发送、记分板 -
写回 -
L1 Cache -
L2 Cache
5.1.2 关键AI计算模块2
-
ALU
-
vALU
-
vFPU
-
MUL
-
LSU
-
CSR
-
SFU
-
warp控制
-
Tensors core
5.2 AI处理器专用验证方法
5.2.1 Simulation 仿真验证
-
仿真验证环境搭建
-
AI testcase开发
-
AI 性能精度体系验证
5.2.2 FPGA原型验证
-
FPGA选型
-
AI处理器RTL Porting
-
FPGA 仿真验证
-
性能功耗 profiling
04
景芯PCIe实战:从0到1搭建 PCIe子系统
在AI算力狂飙的时代,数据传输速度成为决定系统性能的关键瓶颈。PCIe(Peripheral Component Interconnect Express)总线技术,不仅是突破技术天花板的钥匙,更是跻身数字IC设计高手行列的终极杀手锏。
传统总线技术在如此海量数据面前捉襟见肘,而PCIe凭借8GT/s(Gen4)至16GT/s(Gen5)的超高传输速率,以及低延迟、高带宽、热插拔等特性,成为连接 CPU、GPU、AI加速卡的核心枢纽。在数据中心,PCIe构建的高速链路让多块GPU实现跨卡通信,大幅提升模型训练效率;在边缘计算设备中,它保障了传感器数据与AI芯片的实时交互。
景芯PCIe子系统设计的完整流程:
1.需求分析:确定传输带宽(需满足8GB/s持续读写)、延迟要求(小于10μs)。
2.架构设计:采用硬核PHY+软核协议栈方案,降低开发成本。
3.RTL实现:使用状态机实现TLP处理,通过AXI接口与AI计算单元对接。
4.验证与调试:通过眼图测试验证PHY性能,利用协议分析仪定位链路训练异常。
5.最终,该设计成功通过PCI-SIG合规性测试,在实测中性能超出预期15%。
如果你渴望成为数字IC设计领域的顶尖高手,PCIe子系统设计就是你必须征服的终极关卡!
本次IC设计课程,我们精心打磨了一套“理论+工具+项目”三位一体的PCIe教学体系,助你快速突破技术壁垒! 抢占数字IC领域的技术制高点,开启你的 PCIe技术进阶之旅,下一个数字IC高手,就是你!
Part.01
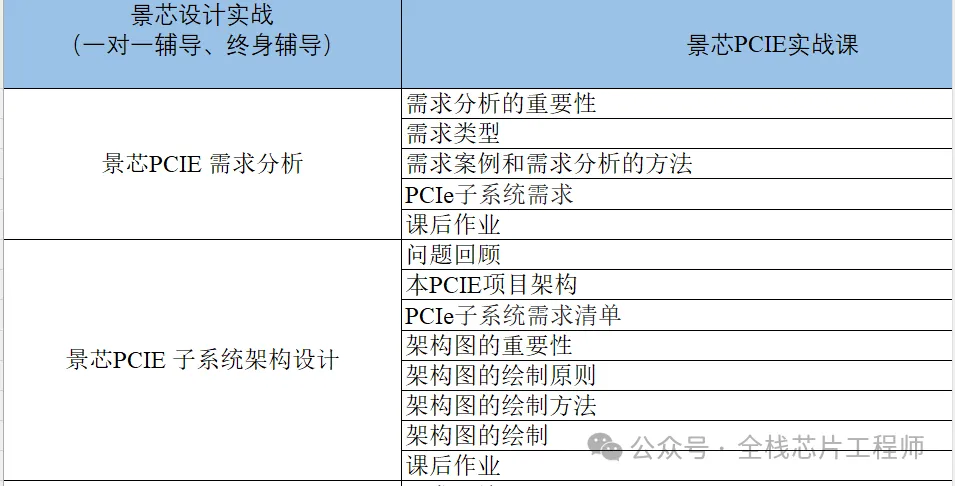
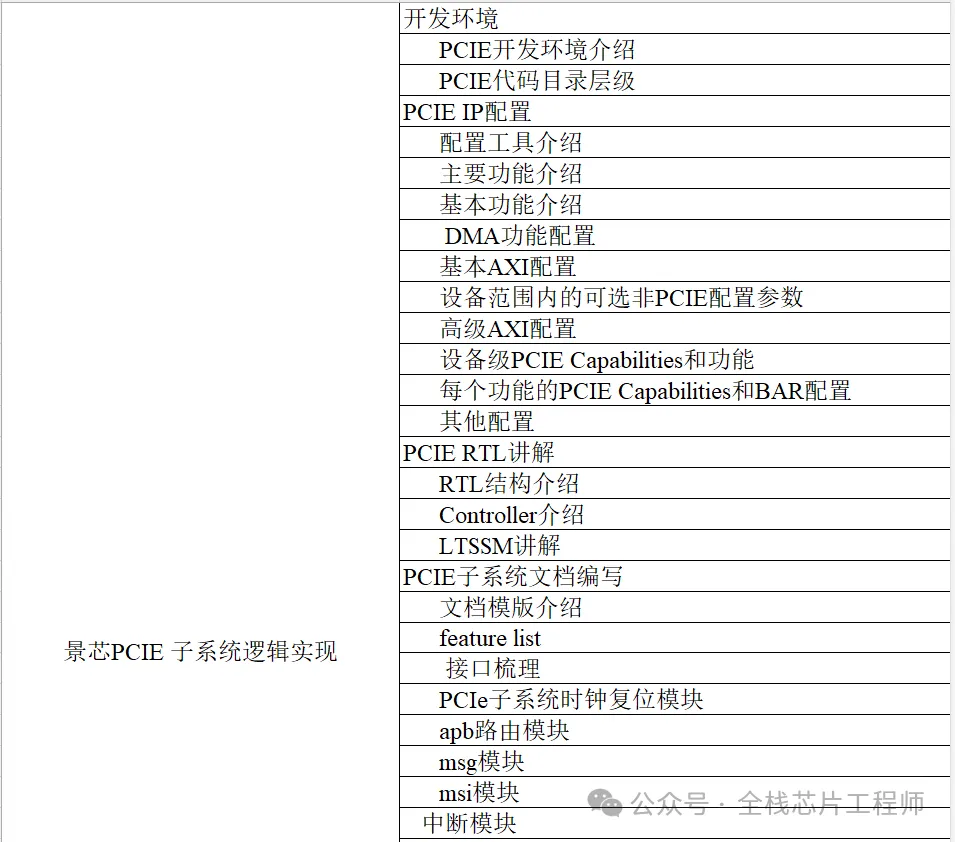
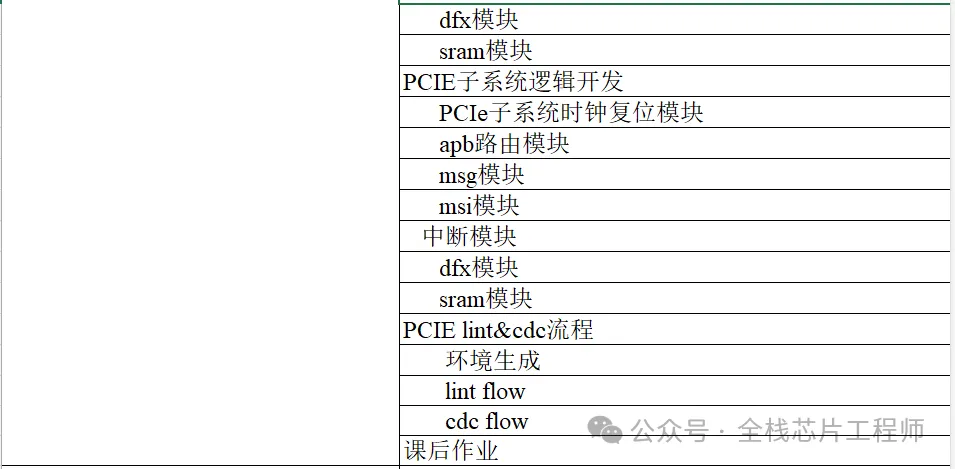
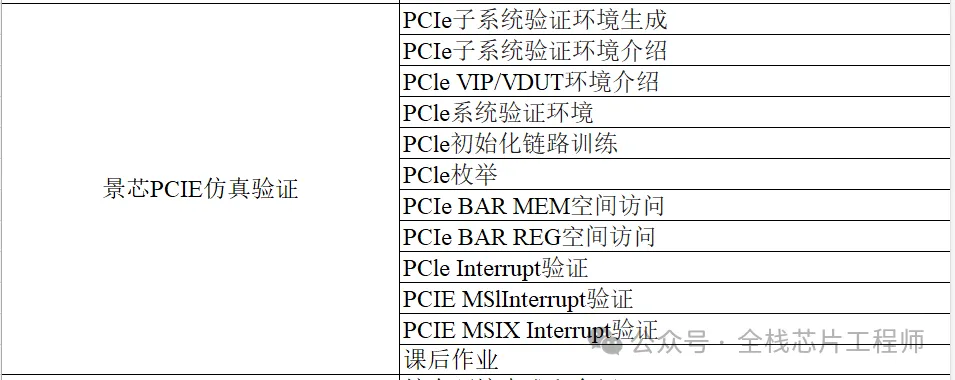
PCIE实战目录
景芯SoC设计实战之PCIE实战:

05
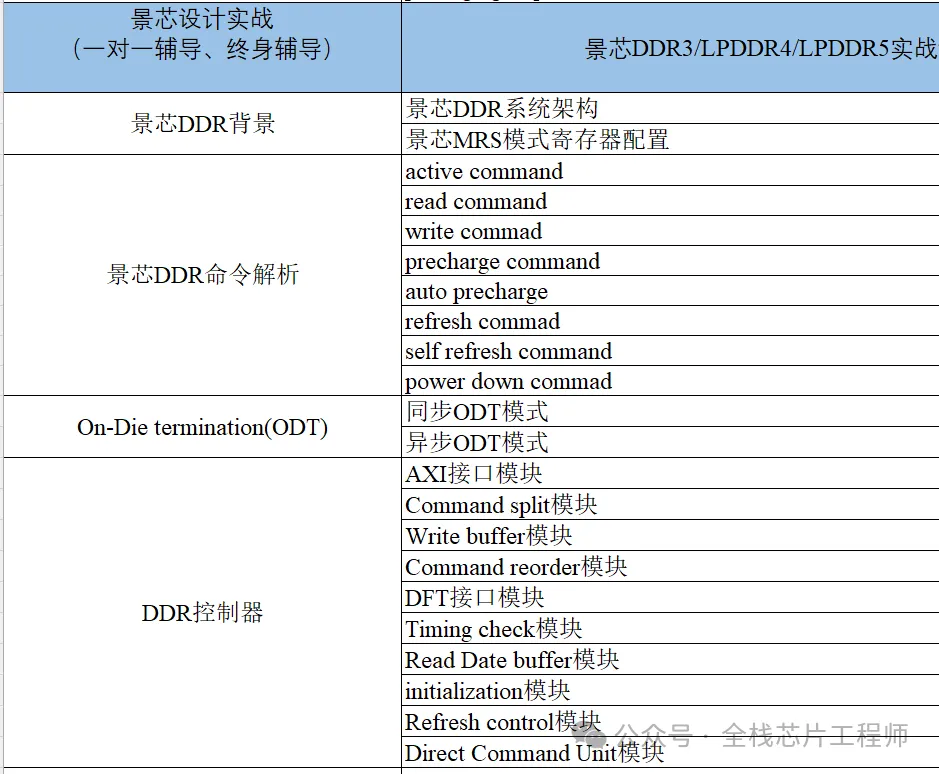
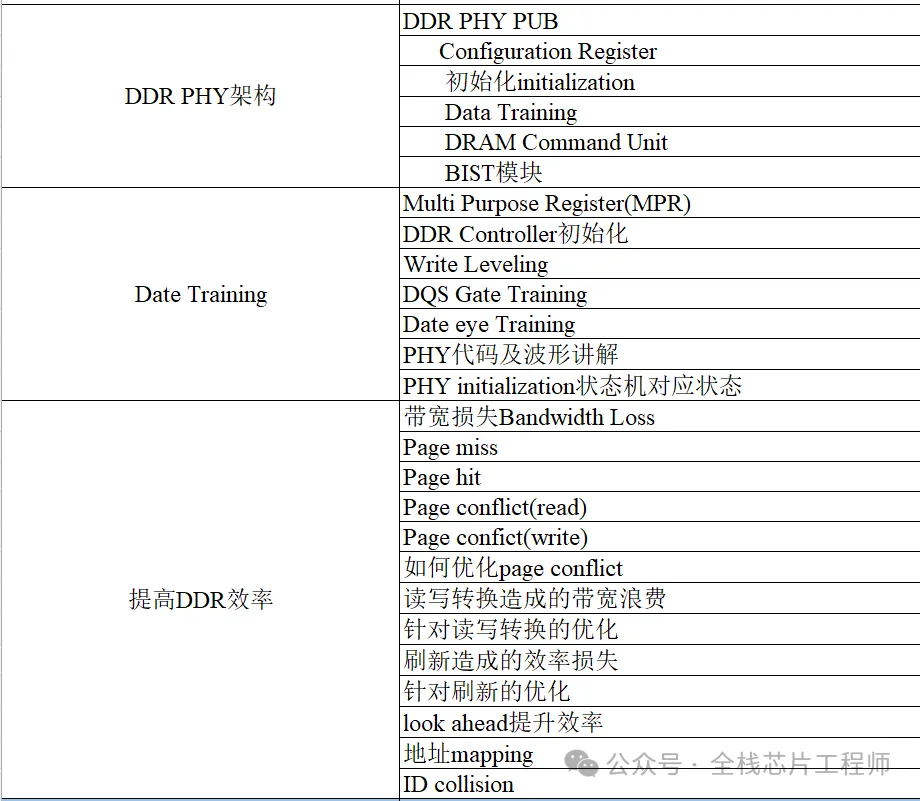
景芯DDR实战:从0到1搭建DDR子系统
Part.01
DDR/LPDDR实战目录
06
-
AES保障数据传输机密性,SHA/HMAC验证完整性与来源,RSA管理密钥交换与身份认证,形成端到端防护。
-
硬件加速趋势:通过全自研加密引擎)提升性能,同时优化功耗(动态电压调节)。
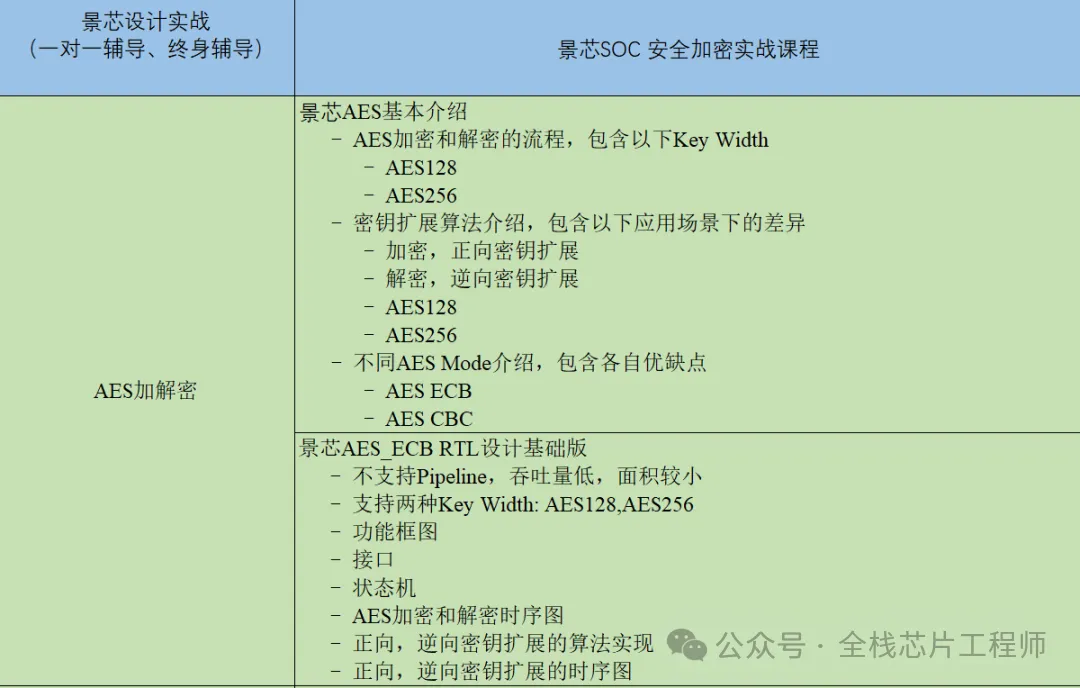




AES(高级加密标准)加密算法及其RTL实现
AES是一种对称加密算法,采用分组密码结构,将明文划分为固定长度的块(如128位、256位),通过多轮迭代的字节代换(SubBytes)、行移位(ShiftRows)、列混合(MixColumns)和轮密钥加(AddRoundKey)操作实现加密。其密钥长度支持128、192、256位,安全性高且计算效率优异。
-
数据机密性:对SoC芯片中的通信数据、存储内容进行加密,防止窃取或篡改。
-
低资源消耗:适合嵌入式系统,如物联网设备,通过硬件加速模块(如专用AES协处理器)提升性能并降低功耗。
SHA(安全哈希算法)算法及其RTL实现
SHA属于密码哈希函数,将任意长度输入转换为固定长度(如SHA-256为256位)的摘要。其核心为压缩函数迭代处理数据块,具备单向性和抗碰撞性,即无法通过摘要反推原文,且难以找到两个不同输入产生相同摘要。
-
数据完整性验证:用于固件签名、安全启动流程,确保代码未被篡改。
-
数字签名基础:与RSA/ECC结合生成签名,验证身份和消息来源。
-
安全启动链:在启动时逐级校验哈希值,防止恶意代码注入。
-
轻量化设计:采用SHA-256替代MD5或SHA-1,平衡安全性与计算开销(如SHA-256耗时473ms vs MD5的226ms)。
HMAC-SHA算法及其RTL实现
HMAC-SHA(基于哈希的消息认证码)是HMAC结合密钥与哈希函数(如SHA-256),生成固定长度的消息认证码(MAC)。其公式为:HMAC(K, M) = H((K ⊕ opad) || H((K ⊕ ipad) || M))通过两次哈希运算和密钥混淆,确保即使哈希函数存在漏洞,攻击者也无法伪造MAC。
-
消息认证:验证数据来源和完整性,防止中间人攻击。
-
会话保护:在通信协议(如TLS)中用于握手阶段的认证。
-
设备间安全通信:如车联网中ECU(电子控制单元)的指令认证,确保指令来自合法节点。
-
密钥派生:结合随机数生成会话密钥,增强临时通信的安全性。
07
AXI PSRAM实战(边缘设备的DDR)
AI眼镜彻底火了。小米、Meta、雷鸟轮番上新,智能手表更是卷到能跑端侧大模型。但有一个痛点始终没解决——续航。很多工程师把算力、屏幕、蓝牙的功耗抠到极致,最后发现DDR/LPDDR才是那个”电老虎”。自刷新电流动辄几毫安,深度睡眠唤醒还要重新训练PHY,一天两充是常态。
做低功耗AI SoC的工程师,谁没被DDR功耗和SRAM容量按头打过?智能眼镜、手表这类可穿戴设备,DDR功耗拉胯、传统SRAM容量不够,别慌!今天给大家带来一门直接解决行业痛点的硬核实战课 ——《AXI pSRAM 设计及 SoC 集成验证》,带你啃下 pSRAM 这块低功耗存储的硬骨头!
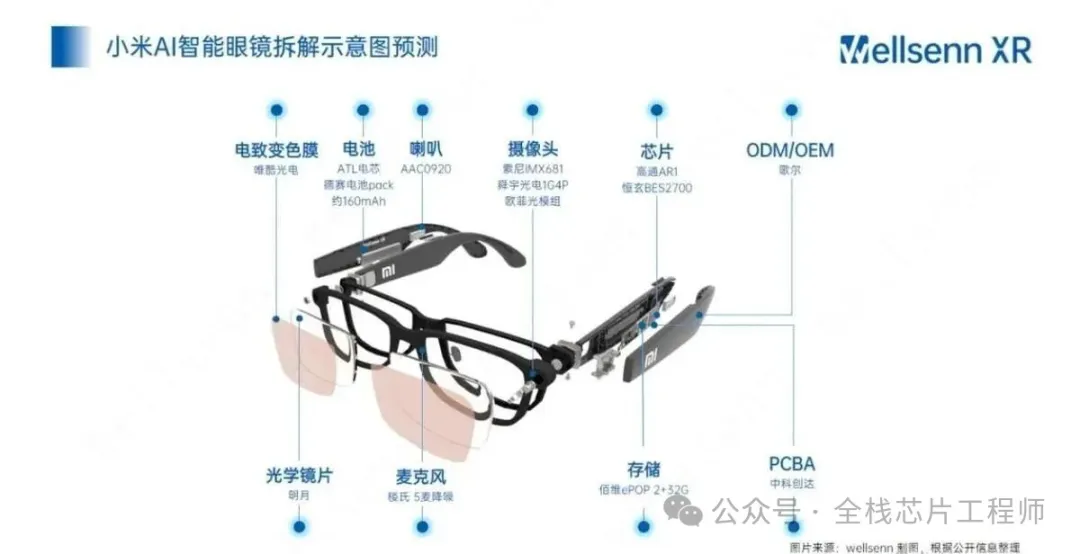
💡 为什么说 pSRAM 是低功耗 AI SoC 的必修课?
先给没接触过的小伙伴划个重点:
pSRAM(Pseudo SRAM)是专为低功耗场景而生的存储方案,兼具 SRAM 的简单接口和 DRAM 的大容量优势,功耗比传统 DDR 低一个量级,是智能手表、TWS 耳机、AR/VR 设备、边缘 AI 芯片的 “标配存储”。
pSRAM待机功耗能做到1.8μA,比传统DRAM低近90%。景芯在给AR眼镜做方案时,干脆用PSRAM替代DDR,把芯片面积缩小一半,整机功耗压到50毫瓦以下。炬芯的ATS3085C直接访问高速OPI PSRAM,驱动466×466分辨率60Hz刷新,BR+BLE双连接功耗还不到150μA。思澈科技给手表、AI眼镜做的SF32LB系列,也是内置SRAM合封PSRAM,蓝牙1秒间隔连接平均功耗不到10μA。
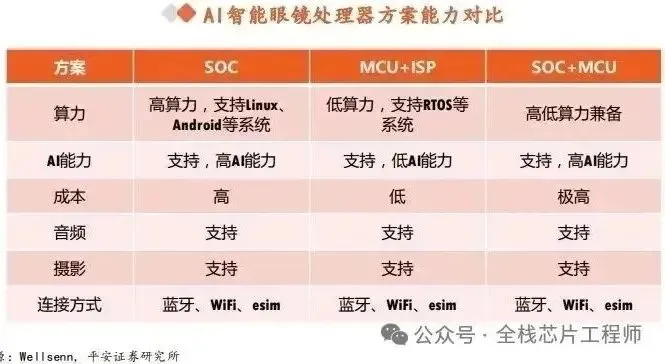
说白了,想在智能穿戴、AIoT、低功耗边缘设备里做SoC,不懂pSRAM设计根本玩不转。但pSRAM不是简单挂个总线就行——AXI接口怎么接?HyperBus时序怎么控?读写Transaction怎么Arbitrate?True Continuous Read怎么实现?Loopback、Split Write、Variable Latency这些特性在Controller里怎么落地?再到SoC集成时的AXI总线连接、Padring、ClockGen与DelayLine,每一步都是坑。
-
接口协议复杂,HyperBus/Octal SPI 时序坑多
-
AXI 接口适配、跨时钟域处理容易踩雷
-
低功耗模式、连续读 / 写优化,性能调优全是细节
-
SoC 集成时,和 AXI 总线、时钟复位的联调更是噩梦
所以我们做了这门课:
从pSRAM协议底层讲起,把接口信号、传输事务、时序要求掰开了揉碎了讲。然后进入Controller四大模块的实战设计:
AXI Interface Controller做多级sync/async FIFO、读写Transaction Arbiter;Main Controller里把AXI Queue管理、HyperBus接口控制、Transaction Flow状态机、Emulated Wrap、True Continuous Read全过一遍;Memory Interface Controller写透Write/Read Operation、Address Map、RXFIFO;最后Register Controller把配置接口和状态寄存器补齐。
验证环节也不含糊。从寄存器通路、AXI Memory通路到Basic Function,Basic Write&Read、Error Response、Outstanding Transaction、Split Write/Read with MAXLEN、Emulated Wrap、True Continuous Read、Device Variable Latency,全部覆盖。最后Device Model集成进SoC,跑通AXI总线连接、Padring、ClockGen与DelayLine,完整走一遍从RTL到集成的全流程。
市面上要么是纯理论的协议科普,要么是零散的代码片段,想系统学懂 pSRAM Controller 从设计到验证再到集成全流程?这门课直接给你安排得明明白白!
Part.02
PSRSAM设计实战进阶课
📚 课程大纲全曝光,从入门到 SoC 集成一步到位
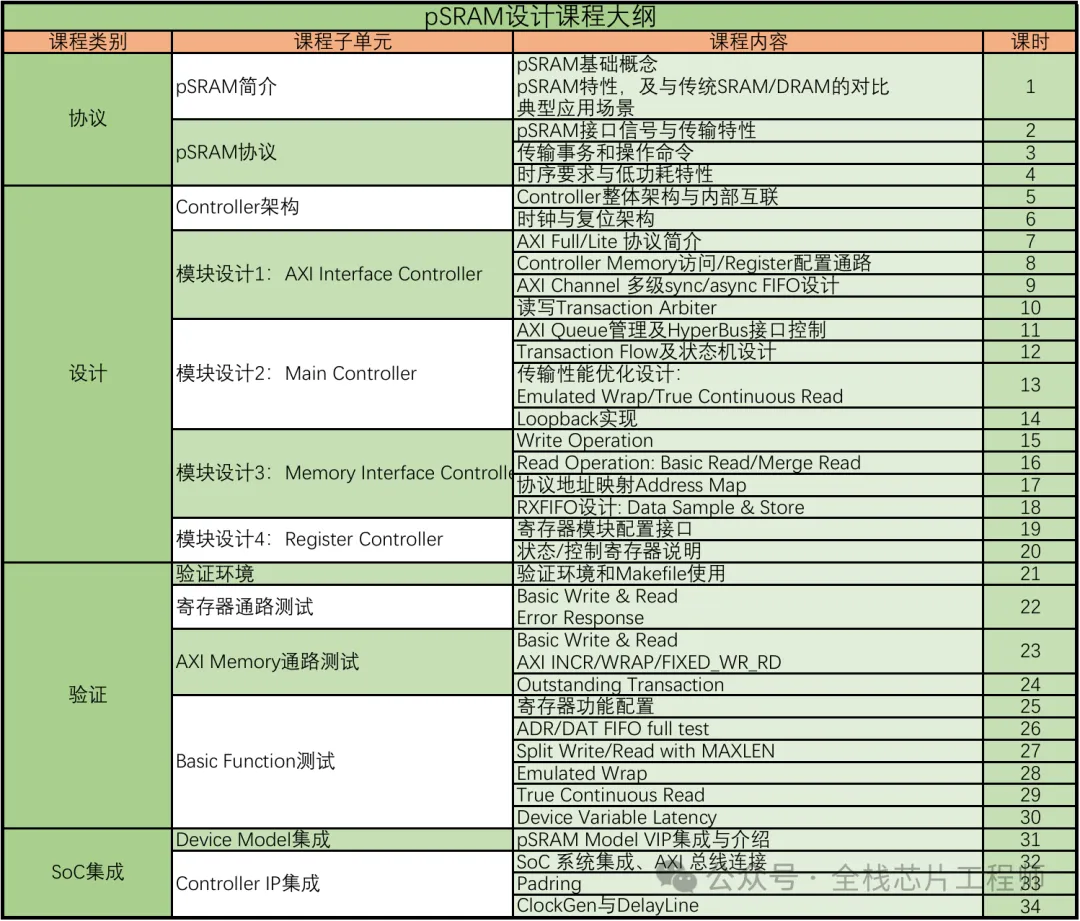
这门课不玩虚的,直接对标企业真实项目流程,34 课时带你走完完整链路:
🔹 协议基础篇:吃透 pSRAM 底层逻辑
从 pSRAM 和传统 SRAM/DDR 的差异讲起,把接口信号、传输特性、时序要求、低功耗模式拆解得明明白白,让你从根源理解 “为什么 pSRAM 能做到低功耗”。
🔹 模块设计篇:手把手搭 pSRAM Controller
四大核心模块,带你从零写 Verilog 代码:
-
AXI Interface Controller:搞定 AXI Full/Lite 协议适配、多级同步 / 异步 FIFO、仲裁器设计
-
Main Controller:HyperBus 接口控制、传输状态机、性能优化(连续读 / 写、Loopback 实现)
-
Memory Interface Controller:读写操作实现、地址映射、数据采样存储
-
Register Controller:寄存器配置接口、状态 / 控制寄存器设计
🔹 验证实战篇:打造可复用验证平台
从验证环境搭建、寄存器通路测试,到 AXI Memory 通路、基础功能全场景覆盖,把 pSRAM 的关键特性(AXI INCR/WRAP、Outstanding Transaction、Split Write、Emulated Wrap 等)全测一遍,让你学会写工业级测试用例。
🔹 SoC 集成篇:从 IP 到系统的最后一公里
Device Model VIP 集成、AXI 总线连接、时钟复位适配、Padring 设计,教你把 pSRAM IP 真正集成到 SoC 系统里,解决真实项目中的集成痛点。

🚀 这门课能给你带来什么?
✅ 一套可复用的 AXI pSRAM Controller RTL 代码
✅ 完整的验证平台和测试用例,直接适配项目需求
✅ 低功耗 AI SoC 存储方案选型与调优经验
✅ 搞定可穿戴设备、边缘 AI 芯片的存储设计面试题
✅ 完整的项目经验,简历直接加分!
🔥 早鸟优惠倒计时,错过拍大腿!
新课上线专属福利,早鸟价五折!
优惠名额有限,手慢无!
最后说句掏心窝子的:现在低功耗、边缘 AI 是行业大趋势,pSRAM 作为核心存储方案,懂设计、会验证、能集成的工程师,真的太吃香了!别再停留在只会用 IP 的阶段,搞懂底层逻辑,下次面试直接拿捏面试官,项目里遇到问题也能从容解决~
Part.06
课程报名微信,扫描咨询我们吧

想报名的同学可以发小红书、朋友圈拼课,5人成团后,每人可优惠500元!
景芯SoC芯片全流程实战附属【知识星球】,一个包括设计、验证、DFT、后端全流程技术的交流平台,也是景芯学员的答疑平台!若您和我一样渴求技术,那欢迎扫下面二维码加入星球,共同进步!

08
景芯团队Design Service提供哪些服务?
景芯主营业务是design service+一对一芯片辅导培训!景芯团队将持续打磨芯片全流程技术,边缘AI时代,景芯团队一定成!景芯团队提供的芯片Design Service设计服务包括:
-
提供SoC、MCU、ISP、CIS等芯片设计、验证、DFT、后端服务
-
提供DDR/PCIE/MIPI/ISP/NPU/VPU/CAN/USB/ETH等复杂IP设计
-
提供7nm、12nm、28nm、40nm、55nm、65nm、90nm等后端设计
-
提供高校、企业定制化芯片设计服务、设计培训业务
-
景芯团队为客户定制了数款A55、A7系列SoC芯片,皆一版成功!
-
景芯团队为客户定制了数款M7、M3/4、M0系列MCU芯片!
-
景芯团队为客户定制了数款RISC-V系列MCU芯片!
-
景芯团队为客户定制了数款CIS芯片以及ISP模块化设计!
景芯合伙人招聘:
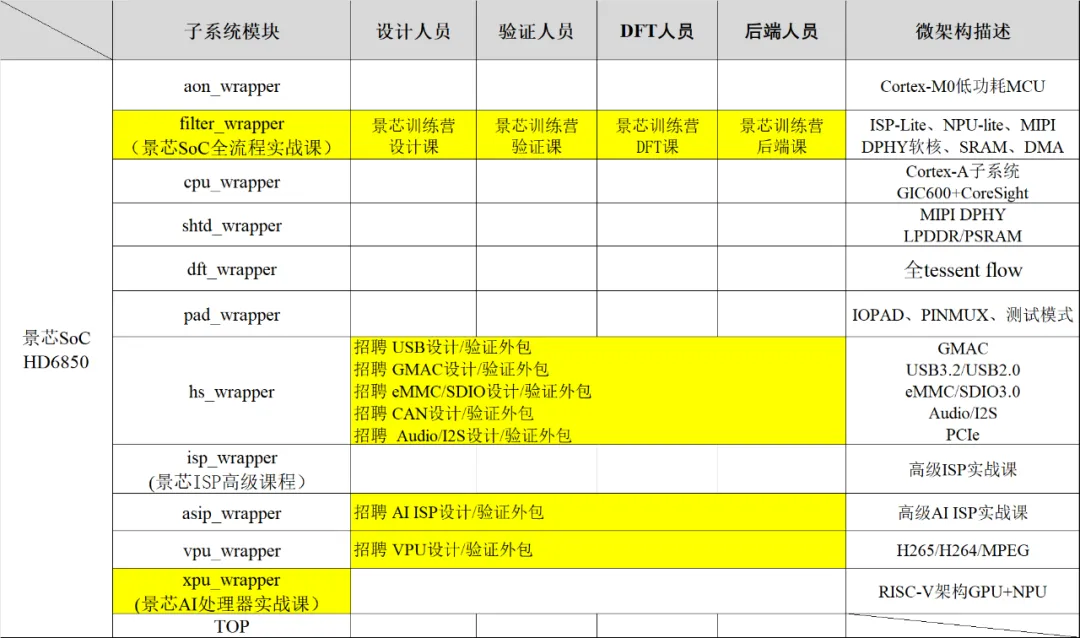
04
景芯SoC训练营项目有什么亮点?
亮点1:景芯SoC自研MIPI解码
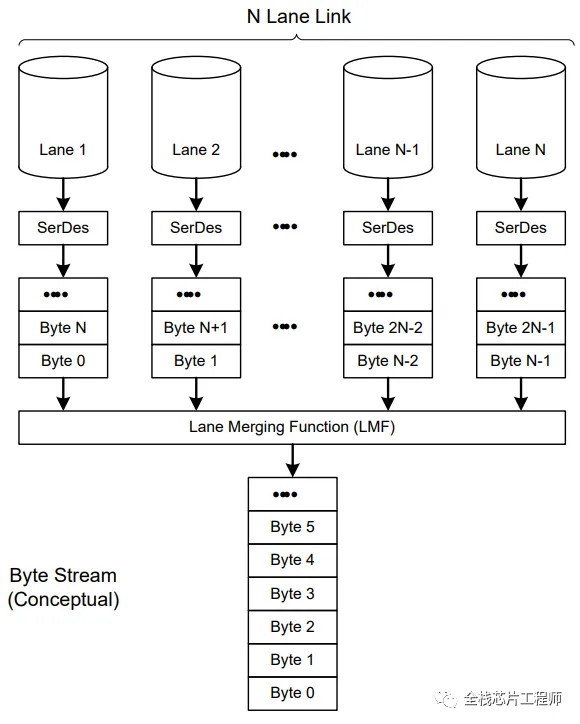
数字电路中经典设计:多条通信数据Lane Merging设计实现
数字电路中经典设计:多条通信数据Lane Distribution实现
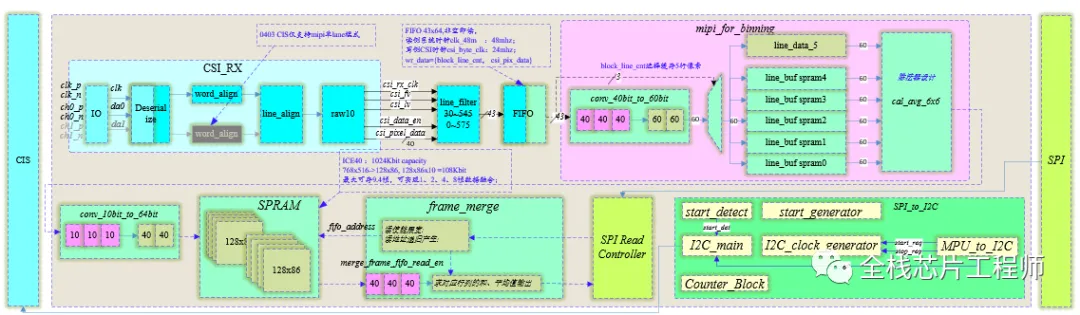
亮点2: 景芯SoC自研ISP图像处理
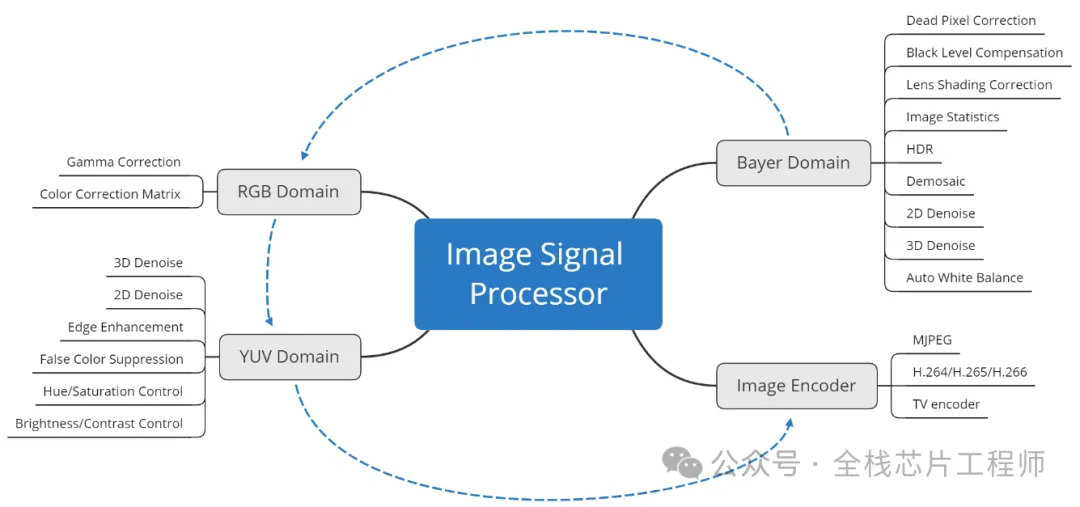
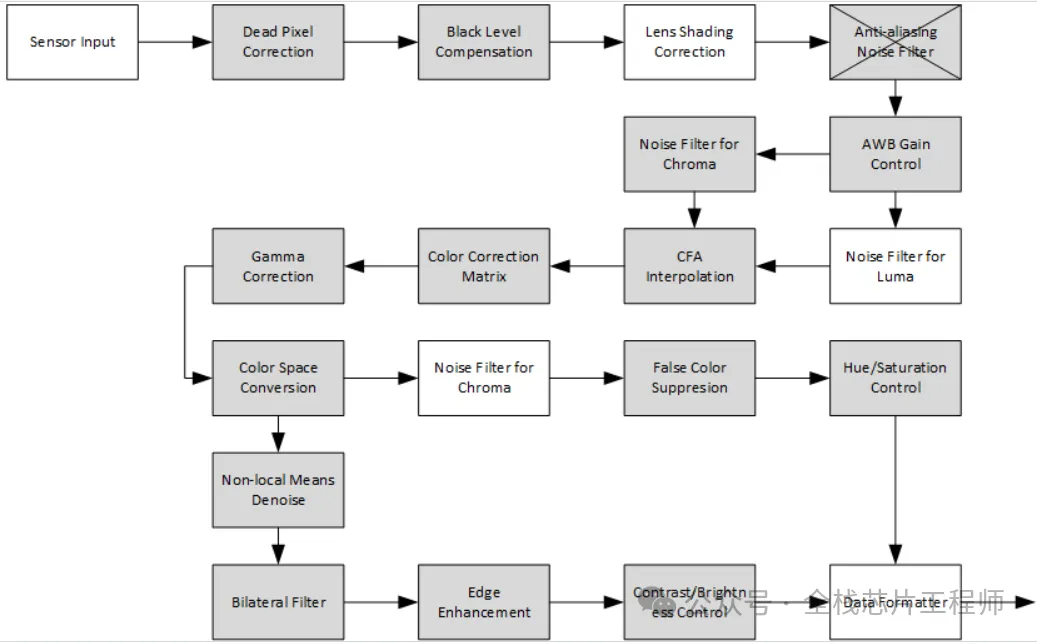
✅dpc – 坏点校正

✅blc – 黑电平校正
 ✅bnr – 拜耳降噪
✅bnr – 拜耳降噪
✅dgain – 数字增益

✅demosaic – 去马赛克

✅wb – 白平衡增益
✅ccm – 色彩校正矩阵
✅csc – 色彩空间转换 (基于整数优化的RGB2YUV转换公式)
✅gamma – Gamma校正 (对亮度基于查表的Gamma校正)
✅ee – 边缘增强

✅stat_ae – 自动曝光统计
✅stat_awb – 自动白平衡统计
【景芯SoC学员ISP算法实现的作品】:

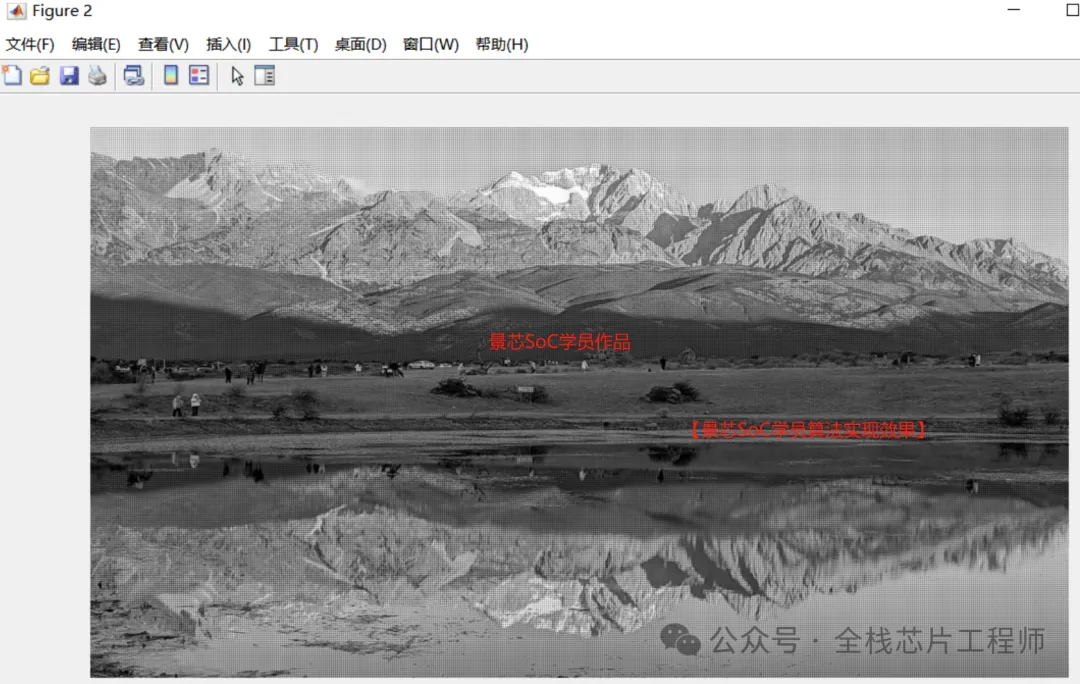
亮点3:景芯SoC自研NPU
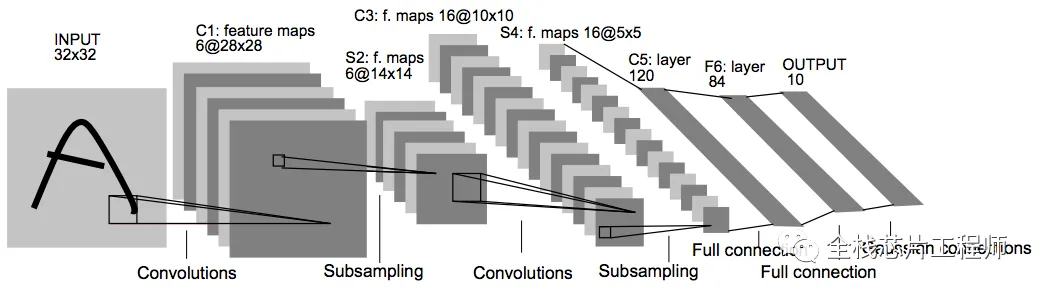
支持手写数字的AI识别:

仿真结果:仿真识别上图7、2、1、0、4、1、4、9

亮点4:景芯SoC UPF低功耗设计
全芯片UPF低功耗设计(含DFT设计)
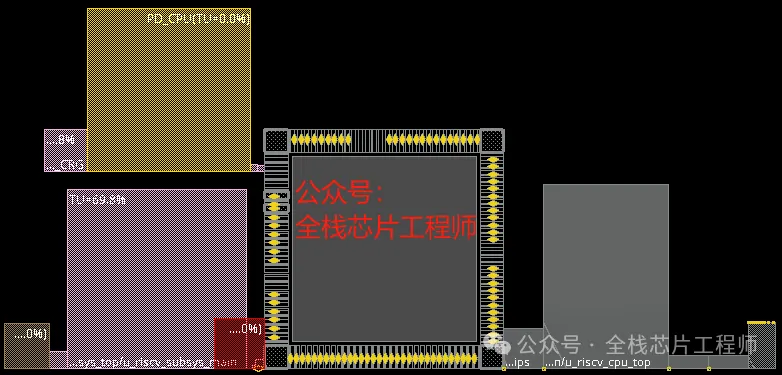
景芯SoC训练营培训项目,低功耗设计前,功耗为27.9mW。

低功耗设计后,功耗为0.285mW,功耗降低98.9%!

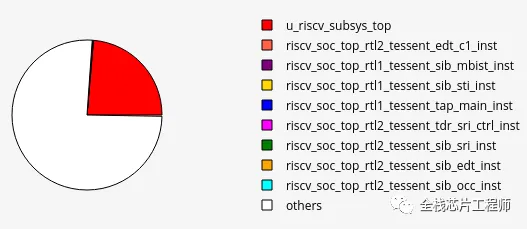
电压降检查:
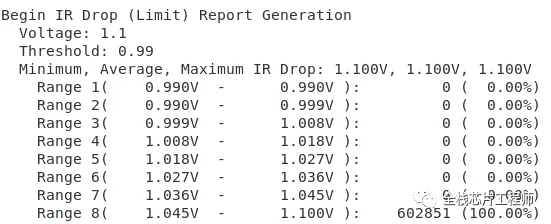
低功耗检查:
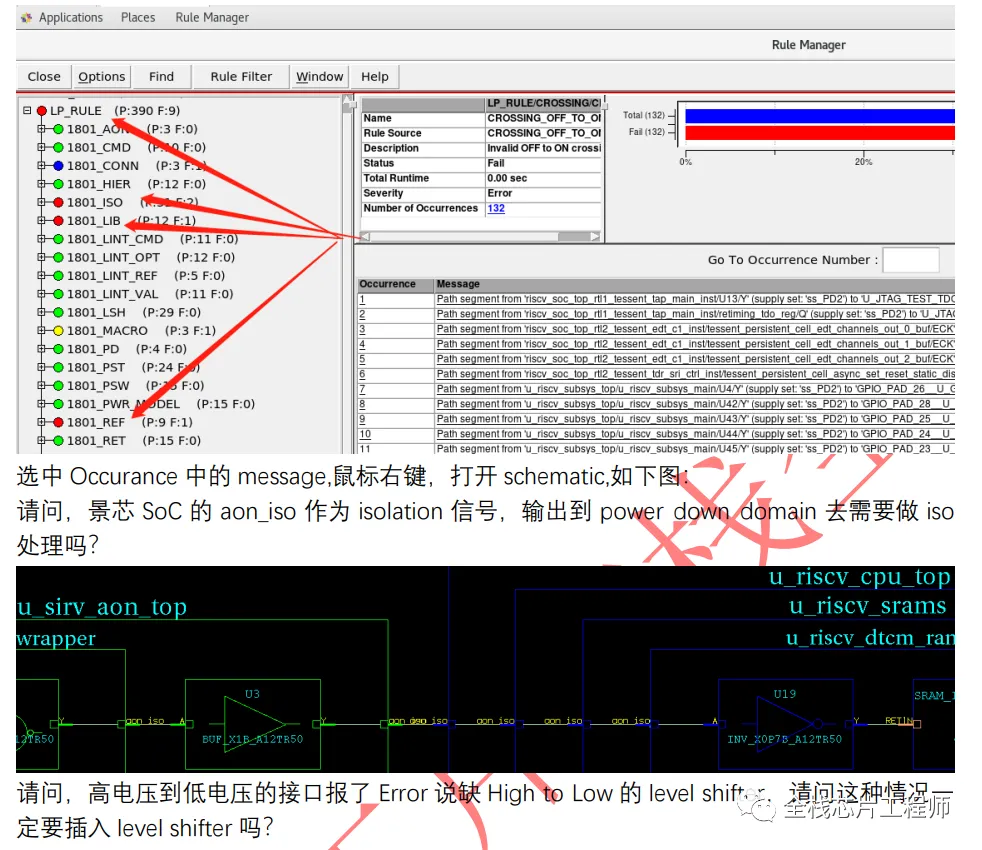
低功耗设计的DRC/LVS,芯片顶层的LVS实践价值极高,具有挑战性!业界独一无二的经验分享。

05
景芯SoC训练营好评如潮
十分感谢景芯学员们对景芯的信任和支持,景芯团队一定更努力精心打磨景芯SoC实战课,让大家无论资深还是资浅都能从景芯训练营获得成长!




最近学员纷纷咨询小编offer选择的问题,看到大家通过景芯培训提升后拿到心仪的offer了,非常开心,祝贺大家都拿到心仪offer了!
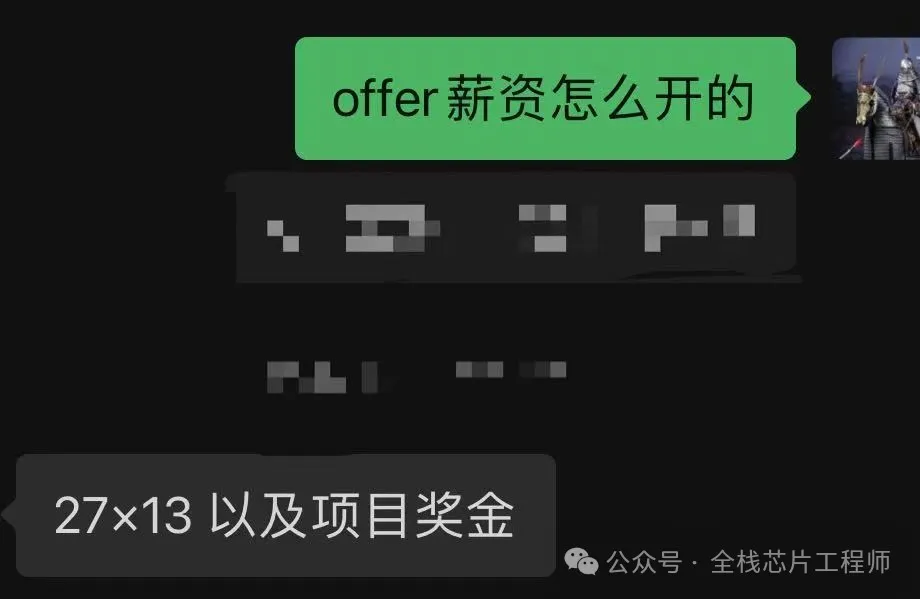
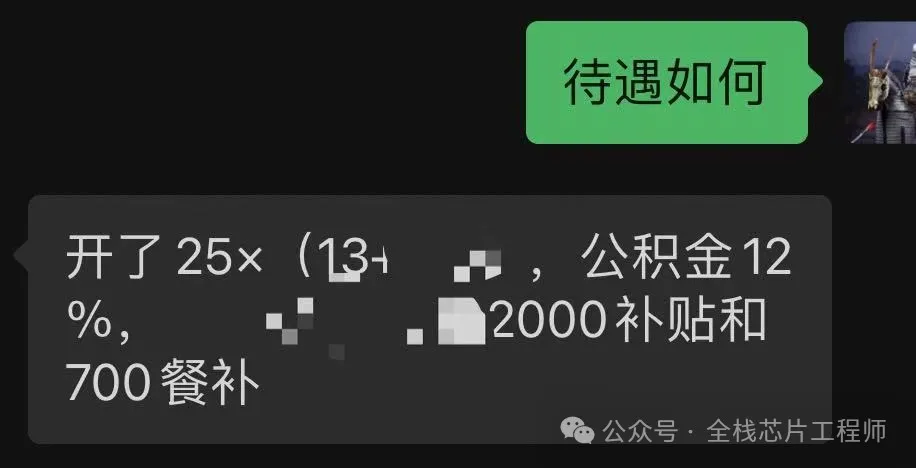
另外,小编的一个景芯VIP学员,成都某985,硕士7年经验,之前通过景芯培训提升后拿到心仪的offer了,这3个offer我看了都眼红!上次发起了投票,今天公布下结果。先来看下三个offer情况:
1、 某GPU公司,月薪5.8w,年终4个月合计23.2万,年薪92.8万,岗位是SoC前端设计,公积金12%;
2、多媒体SOC厂商JC,月薪6.5w,年终奖2个月合计13万,年薪91万,岗位是SoC芯片设计工程师,公积金12%;
3、 国企X微电子,月薪5.5W,年终奖4个月合计22万,年薪88万,担任数字ic设计工程师,主要从事SOC芯片设计,公积金10%
这里补充发布上次大家的投票结果公布:

从结果可以看出,市场行情不好,大家都看好国企军工的稳定性了,GPU仍然是技术首选,虽然GPU公司都在厮杀,但是仍有前景,但是IPC SOC反而得票最低,内卷同时没有太大增量市场。
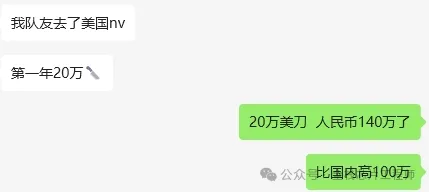
另外,景芯资深老学员告诉我,留学X国的硕士去外企某芯片巨头薪资是20万+美金!折合RMB超过140万,才25岁左右的小伙子!薪资超140万!努力学习技术吧 骚年。
课程报名微信:

06
招聘:景芯SoC学员供不应求
职位:SoC 数字前端设计工程师
岗位职责:
1、根据设计需求,完成 SoC 芯片中子模块的设计、集成、仿真等工作;
2、根据设计需求,完成第三方 IP 的配置、集成、仿真等工作;
3、完成 sdc、upf 的编写和检查,完成综合与 formal check 等工作;
4、完成性能、功耗分析;
5、支持 FPGA 和 emulator 原型验证;
6、支持中后端工作,协助完成时序收敛;
7、支持芯片 bringup,支持软件驱动开发及应用方案开发。
任职要求:
1、微电子、电子工程等相关专业硕士及以上学历,三年以上工作经验;
2、精通 Verilog/SystemVerilog 硬件描述语言,具备规范化代码设计能力。
3、深入理解 SoC 设计流程,熟练使用 VCS, Verdi, Spyglass, DesignCompiler 等 EDA 工具;
4、参与/掌握以下一项或者多项技术:
1) CPU, NoC, DDR, MIPI CSI, MIPI DSI, USB, 外设等 IP 的设计或集成;
2)AMBA 总线协议;
3)低功耗设计;
4)带宽评估与优化;
5)Python/Tcl 脚本开发,实现自动化流程。
5、具有良好的表达沟通能力及团队合作精神,具有较强的独立工作能力和动手能力;
6、良好的英文阅读、文档编写能力。
职位:数字前端设计工程师(ISP方向)
任职要求:
1、熟练掌握 Verilog HDL,能够使用 RTL 描述复杂数字电路;
2、熟悉 VCS/Verdi 等常见 debug 工具,能够对大规模数字电路进行仿真及 debug;
3、能够采用 Design compiler(或 Quartus/Vivado/Synplify 等 FPGA 工具)对 RTL 设计进行综合并分析时序、 面积;
4、熟悉 DDR 读写原理,熟悉常见片上总线规范(例如 AMBA AXI);
5、熟悉数字图像信号处理(ISP)、图像降噪、图像画质增强等相关方向。
岗位关键字:
数字前端设计,ASIC 前端设计,RTL 设计、ISP,图像降噪、图像画质增强。
职位:数字前端设计工程师(视频处理方向)
任职要求:
1、熟练掌握 Verilog HDL,能够使用 RTL 描述复杂数字电路;
2、熟悉 VCS/Verdi 等常见 debug 工具,能够对大规模数字电路进行仿真及 debug;
3、能够采用 Design compiler(或 Quartus/Vivado/Synplify 等 FPGA 工具)对 RTL 设计进行综合并分析时序、 面积;
4、熟悉 DDR 读写原理、熟悉常见片上总线规范(例如 AMBA AXI);
5、对视频编解码、GPU、GE2D、Display Engine 等机器视觉相关方向有强烈的学习意愿。
岗位关键字:
数字前端设计,ASIC 前端设计,RTL 设计、视频编解码(H.264/H.265/HEVC),GPU,GE2D、Display Engine。
职位:数字前端设计工程师(AI 人工智能方向)
任职要求:
1、熟练掌握 Verilog HDL,能够使用 RTL 描述复杂数字电路;
2、熟悉 VCS/Verdi 等常见 debug 工具,能够对大规模电路进行仿真 debug;
3、能够采用 Design compiler(或 Quartus/Vivado/Synplify 等 FPGA 工具)对 RTL 设计进行综合并分析时序、 面积;
4、熟悉 DDR 读写原理、熟悉常见片上总线规范(例如 AMBA AXI);
5、对 CNN,大语言模型(LLM)等常见 AI 算法及硬件实现方法有强烈的学习意愿。
岗位关键字:
数字前端设计,ASIC 前端设计,RTL 设计、AI/人工智能,深度学习、CNN、大语言模型 LLM。
职位:FPGA 原型验证工程师
岗位职责:
1、负责 FPGA 原型验证平台的设计、调试和维护;
2、完成从 SoC 到 FPGA 的 verilog 代码转换、集成和仿真验证;
3、支持 FPGA 系统调试;
4、跟进 FPGA 原型验证方法学的演进,完善 FPGA 验证流程。
任职要求:
1、电子、计算机、自动化等相关专业,本科及以上学历,三年以上工作经验;
2、精通 Verilog/SystemVerilog 硬件描述语言,有扎实的数字电路基础;
3、熟练掌握 Xilinx/Intel FPGA 芯片的设计、验证流程,熟练掌握 EDA 工具使用;
4、具有以下一项或者多项能力:
1)熟悉 AMBA 总线协议;
2)具有 IP 集成/验证经验,或系统集成/验证经验;
3)熟悉 ARM 等嵌入式处理器体系结构;
4)熟悉常见外设协议,具有相关调试经验;
5)具有脚本编写能力,能够将工作流程脚本化。
5、具有良好的表达沟通能力及团队合作精神,具有较强的独立工作能力和动手能力;
6、良好的英文阅读、文档编写能力。