当前时间: 2026-05-04 13:36:10
更新时间: 2026-05-04
分类:软件教程
评论(0)
月薪3千与3万的AI从业者,差距只在一张表
你以为提示词就是给AI写几句话让它干活?如果你还这么想,可能正在用最贵的算力做着最无效的工作。真正懂行的人早就明白,提示词不是聊天话术,而是整个AI产品的心脏。而心脏跳得好不好,靠的不是灵感,是一套科学到骨子里的评分体系。
一、认知觉醒:提示词是你唯一能和AI对话的方式
朋友阿杰去年花三个月搭了一个智能客服,上线第一天就崩了。用户问”我的快递到哪了”,AI回复了一段关于宇宙起源的长文。他跑来问我:”模型是不是不行?”
他愣住:”测试?我就是自己试了几十条,感觉还行就上线了。”
这就是大多数AI从业者的真实状态。他们把提示词当成即兴创作,把上线当成碰运气。但真相是,提示词是你唯一能和大模型打交道的方式。模型没有手,不会自己打开文件,不会主动联网查资料,它只会读你塞给它的那段文字,然后基于这段文字生成下一个字。
所以RAG也好,Agent也好,知识库也好,所有酷炫的技术设计,最终目的只有一个:在对的时间点,把对的内容塞进提示词里。你让AI分析财报,就得把财报数据塞进去。你让AI写代码,就得把代码规范塞进去。你让AI做竞品分析,就得把竞品信息塞进去。
但提示词有字数限制。小模型可能只有几千到几万字,大模型能到几十万甚至上百万字。塞得越多,模型越容易”注意力不集中”,表现反而下降。这就倒逼你在应用层做大量设计,本质上都是在解决一个问题:怎么在有限的提示词空间里,塞入最有价值的信息。
二、系统提示词与用户提示词:看不见的战场
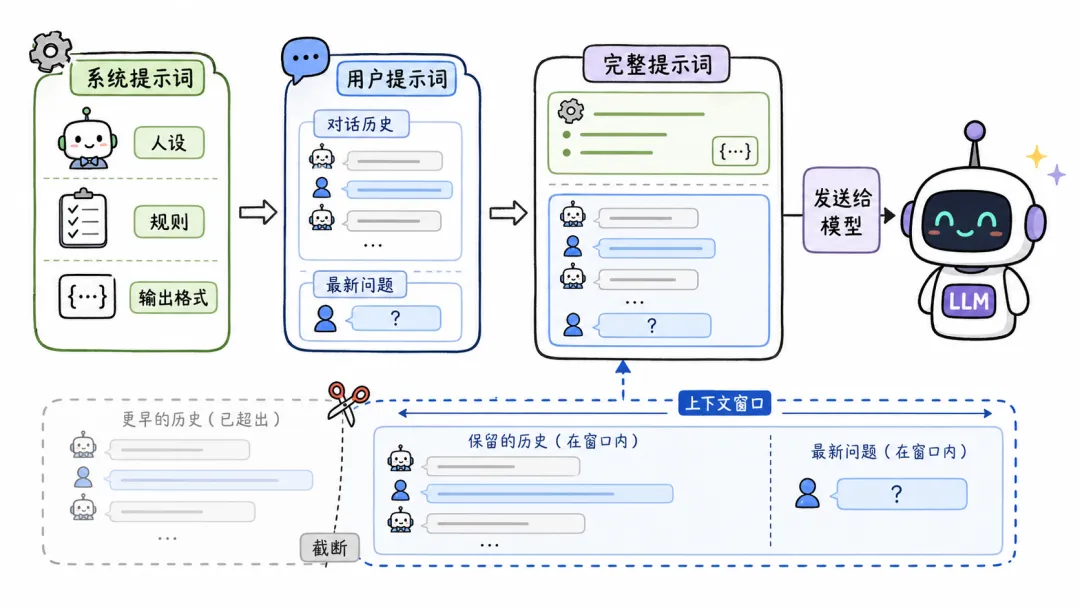
很多人不知道,你在对话框里输入的内容只是用户提示词。背后还有一层系统提示词,你根本看不到。
系统提示词写的是全局规则,比如你的人设、你的任务边界、你的输出格式。用户提示词写的是当下这一次对话的具体内容。产品界面会把两者拼接成一整段文字发给模型。模型本身并不知道什么叫系统提示词,什么叫用户提示词,它只收到一段完整的文字。
这里有个坑。你在同一个对话框里连续对话,模型看起来有记忆,其实它根本没有记忆。它只是把你之前所有的问答记录,连同你最新提的问题,全部塞进用户提示词里。聊得越多,用户提示词越长。一旦超出模型的上下文窗口限制,大多数模型会优先保留系统提示词完整,截掉最早的对话历史。
所以当你发现AI突然”失忆”了,不是它变傻了,是你的对话历史太长,前面的内容被截掉了。
三、参考资料与样例:让AI学会你的业务语言
塞参考资料叫做In-Context Learning,也就是基于上下文的学习。注意,这不是训练模型。模型的参数不会因为你的提示词发生任何变化。你就算跟AI聊一万轮,教它再多新知识,它下次重启后还是原来的它。In-Context Learning只是借助提示词里的信息,让模型在当前这次回答中表现得更好。
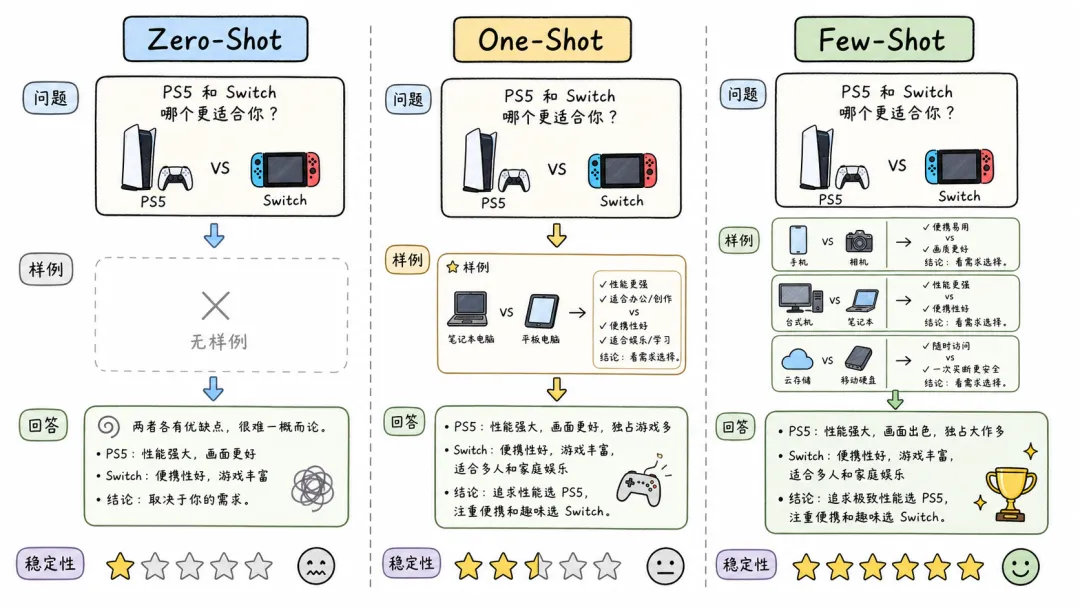
塞样例更直接。你不给样例,叫Zero-Shot。给一条样例,叫One-Shot。给多条样例,叫Few-Shot。
举个例子。你让AI扮演索尼门店店员,回答”PS5和Switch哪个性价比高”。如果不给样例,AI可能会泛泛而谈,说PS5性能强、有独占游戏。但如果你给了一条优秀店员的回答样例,AI就会学会:先区分定位,再分析Switch的可替代性,最后强调PS5的客厅体验。方向完全不一样了。
而且样例数量直接影响稳定性。只给一条样例,AI十次回答里可能有一两次跑偏。给三条样例,稳定性大幅提升。这就是概率模型的本质,它永远在猜下一个最可能的字,你给它的上下文越丰富,它猜得越准。
四、那张表:AI产品管理的核武器
今天这篇文章最重要的内容,是一张表。这张表决定了你的AI产品能不能科学迭代、能不能上线、能不能向老板交差。
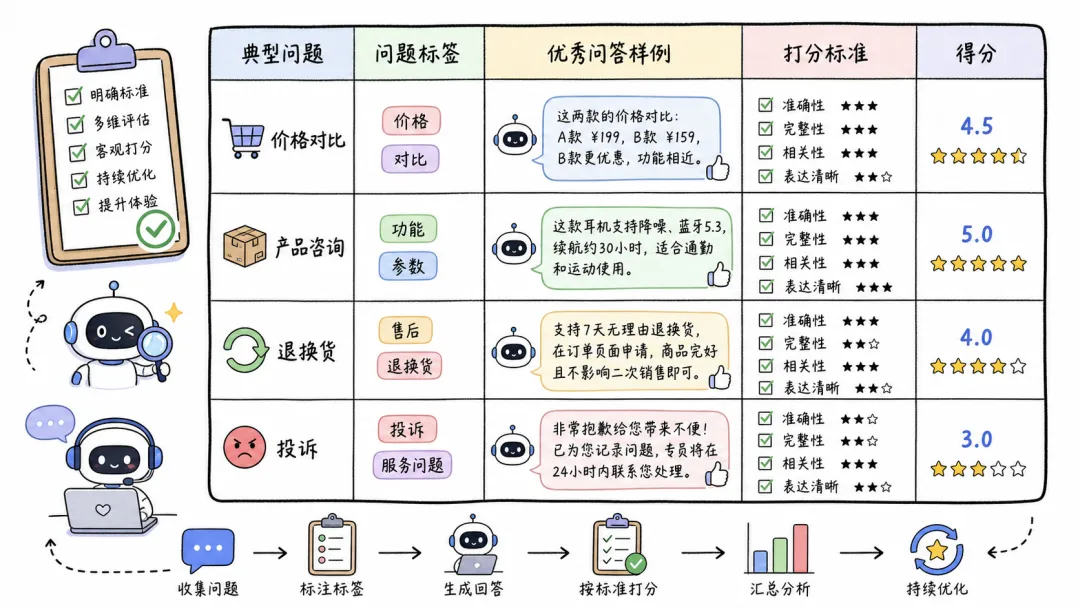
表的列是这样的:典型问题、问题标签、优秀问答样例、打分标准。
第一步,梳理典型问题。假设你是做门店智能客服的,你要把用户可能问的所有问题都列出来。产品咨询、价格比对、退换货、投诉,每个大类下面再细分。比如价格比对下面,比对对象是Switch还是Xbox,是台式机还是笔记本。最终你可能梳理出300条甚至1000条典型问题。
第二步,给每个问题打标签。一级标签是问题类型,二级标签是具体场景,三级标签是比对对象。这样你就能知道,你的AI在哪些子场景上表现好,哪些子场景上表现差。
第三步,为每个典型问题写优秀问答样例和打分标准。优秀问答样例就是你希望AI回答成什么样。打分标准就是评判维度,比如是否提到定位差异、是否攻击竞品可替代性、是否强调核心优势。每条标准配多少分,跟高考作文评分一个道理。
五、模型选型:别再看榜单了,看这张表
很多人做AI产品的第一步是选模型,看哪个榜单排名高就用哪个。这是错的。
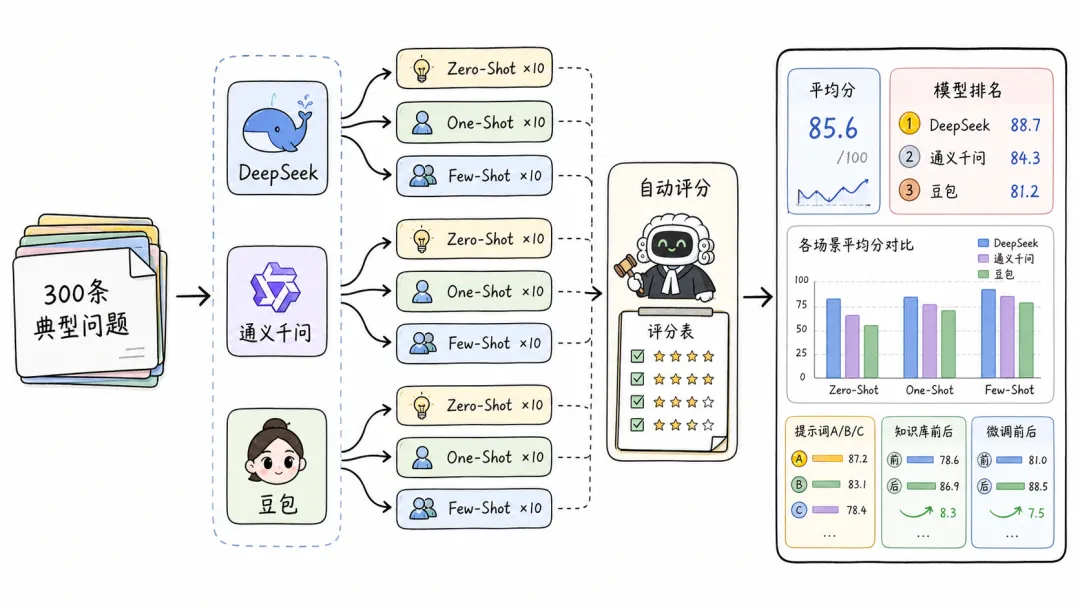
榜单上的通用分数不能直接代表它在你的垂直业务场景中的表现。某个模型在通用评测上击败了GPT,不代表它在你门店客服的场景里表现更好。你唯一需要关心的,是这个模型在你的300条典型问题上能得多少分。
具体怎么做?拿DeepSeek跑一遍,拿通义千问跑一遍,拿豆包跑一遍。每个模型,每个问题,Zero-Shot问十遍,One-Shot问十遍,Few-Shot问十遍。300个问题乘以30遍,就是9000次调用。每次调用都用另一个模型按照打分标准自动评分,最后算平均分。
整个过程自动化,工程师写个脚本,跑完大概一小时。一小时后,你就知道DeepSeek在你的场景里平均多少分,通义千问多少分,豆包多少分。这才是科学的模型选型。
你做了三套提示词版本,A版B版C版,哪套更好?用这张表跑一遍,算平均分,一目了然。
你更新了一版知识库,性能有没有提升?用这张表跑一遍,跟旧版知识库对比平均分,用数字说话。
你微调了模型,花了半个月训练,效果怎么样?还是用这张表跑一遍,看平均分涨了多少。
老板问你这个月干了什么,产品能不能上线?你打开这张表,指着数字说:整体平均分从72涨到了85,价格比对场景从68涨到了90,但退换货场景从75跌到了60。所以我们还需要两周优化退换货场景,整体达标后再上线。
这就是科学管理。不是凭感觉,不是拍脑袋,是用数字驱动每一个决策。
六、成本与投产比:这张表值多少钱
梳理1000条典型问题,每条配一个优秀问答样例和一个打分标准,一个熟练的业务专家加AI专家,一天大概能梳理20到30条。1000条大概需要33个工作日,一个人一个半月左右,两个人配合的话一个月就能完成。
成本大概几万块钱。对于一个AI产品来说,这笔投入的投产比极高。但大多数企业没有这个意识,他们宁愿花几十万做开发,也不愿意花几万做测试用例梳理。
为什么?因为测试用例不性感,不能写进PPT,不能向领导展示”我们又做了一个新功能”。但正是这些不性感的工作,决定了你的AI产品能不能真正落地。
七、解析任务:AI在后台默默做的那些事
很多人以为AI应用就是问答,用户问一个问题,AI给一个回答。其实大量AI任务根本不面向终端用户。
比如零售门店的录音解析。现在越来越多的门店配备了录音工牌,顾客和店员的对话全程录音,音频转文字后交给AI解析。解析什么?顾客的年龄段、是否有小孩、咨询了什么产品、有什么担忧、是否消费、支付方式、消费金额、有没有提到竞品、怎么描述竞品的、有没有投诉或不满。
这些字段在行业里叫”槽位”,把对话内容填充到这些槽位里的过程叫”填槽”。填完槽的数据存入数据库,管理层就能实时看到各个门店的运营情况。
以前区域经理想知道某家门店出了什么问题,得层层汇报,信息失真严重,半个月后才能拿到反馈。现在打开AI面板,几秒钟就能看到数据。
这个技术难吗?音频转文字是成熟技术,文字解析用大模型做填槽任务,跟腾讯会议自动生成会议纪要没有本质区别。但商业价值巨大。国内循环智能的智能工牌、美国Nuance(已被微软收购)的医疗录音助手,都是年营收数亿美元的产品。
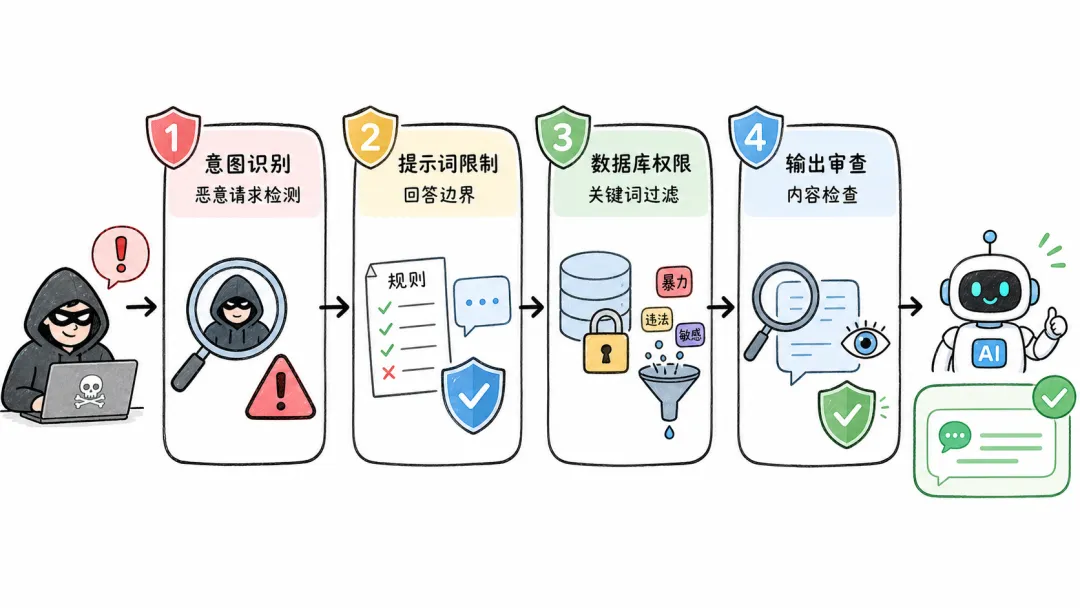
八、安全防护:提示词里的暗战
最基础的风险是信息泄露。用户可能通过精心设计的提问,把你系统提示词里的内容套出来。网上经常能看到有人晒出”我破解了某某AI的系统提示词”,这就是提示词注入攻击。
更危险的是,如果你的Agent有权限访问数据库,用户可能通过对话诱导AI查询敏感数据。比如让你提供某个医生的电话号码,或者批量导出订单信息。
所以真正的AI产品至少要做三到四层防护。第一层,用大模型解析用户意图,识别是否有批量拖取数据的恶意请求。第二层,在回答阶段用提示词限定AI能说什么不能说什么。第三层,在调用数据库的代码层面做关键词过滤和权限控制。第四层,最终输出给用户之前,再用另一个模型做内容审查,确保没有泄露内部信息。
九、写在最后
当你觉得AI很蠢的时候,大概率不是它蠢,是你不会用。
提示词工程的核心心法,就是把AI当成一个智商极高但毫无工作经验的实习生。它有脑子,但你交代任务必须事无巨细。给身份、给背景、给目标、给输入输出样例、给限制条件、给参考资料。少一样,它就可能跑偏。
2026年,AI应用层的竞争已经从”有没有”进入”好不好”的阶段。你的提示词写得好不好,你的测试体系健不健全,你的评分标准科不科学,直接决定了你的产品能不能在真实场景中活下来。
 夜雨聆风
夜雨聆风