 夜雨聆风
夜雨聆风





零成本部署 AI 助手!24小时在线,Qwen3.6 + Hermes 太绝了
如果你一直在为 AI 订阅费头疼,如果你想要一个真正属于自己的 AI 助手——今天这篇文章,帮你彻底解决这个问题。
我把零成本部署 Qwen3.6 + Hermes Agent 的完整流程整理出来了。只要有一张还算过得去的显卡,照着做,24 小时在线的私人 AI 助手就是你的。

Token 自由,零月费,数据隐私安全——完全掌握在自己手里。
为什么你的 AI 账单越来越贵?
你有没有认真算过,每个月在 AI 上花多少钱?
GPT-4 的订阅费、Claude 的用量费、各平台 API 调用成本……很多人每个月大几百块的 AI 支出,轻轻松松就没了。更让人焦虑的是,这些钱是「不得不花」的——你离不开它,但它也在悄悄吃空你的钱包。
而且还有一个更关键的问题:数据隐私。你的聊天记录、你的工作内容、你的各种 Prompt——这些数据都在云端,你根本不知道它们会被怎么用。
这就是为什么我一直在关注本地部署方案。本地跑 AI,数据不出自己的电脑,完全离线可控,再也不用担心隐私问题。
很多人觉得本地部署门槛高,要懂 Linux、要会调参数。但实际上,这个门槛已经被大幅降低了。今天我要推荐的这套组合——Qwen3.6 + Hermes Agent——小白也能跑起来。
Qwen3.6 + Hermes Agent:为什么是这个组合?
先说说为什么选这两个。

Qwen3.6 是阿里巴巴开源的大语言模型,27B 参数规模,接近 17GB 的模型文件。这个尺寸的模型在开源社区里算是性能比较能打的,中文理解、逻辑推理、代码生成这些任务都能 cover 住。
Hermes Agent 是一个开源的 AI Agent 框架,负责把模型包装成真正可用的助手。它支持多轮对话、工具调用、任务自动化——换句话说,没有它,模型只是个语言模型;有了它,才能变成干活的 AI 助手。
这两个组合在一起,就是一套完整的、免费的、可本地运行的 AI Agent 方案。
还有一个关键点:Llama-cpp 方案。很多本地部署方案用起来容易爆显存,录个屏都卡得不行。Llama-cpp 走的是量化路线,虽然不是专门优化过的版本,但它稳定,不会动不动就显存不足。
速度实测 40 token/s——注意,这是在录屏占用的状态下跑出来的数据,空载只会更快。这个速度已经足够使用了,日常对话、代码生成、自动化任务,都不在话下。
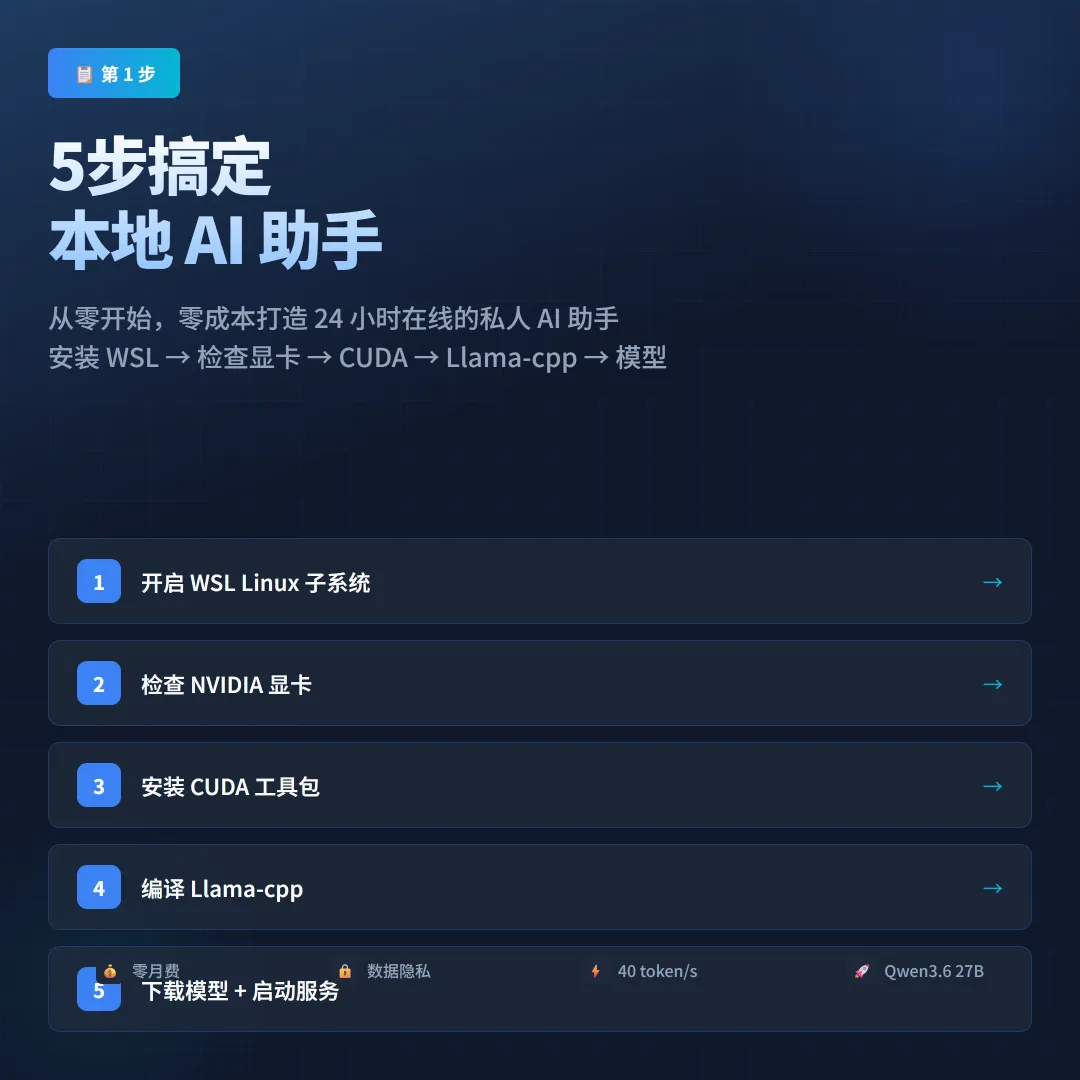
5步搞定本地 AI 助手
说干就干,整个流程分 5 步。
第 1 步:开启 WSL
WSL 是 Windows Subsystem for Linux,在 Windows 里跑 Linux 环境的神器。管理员权限打开 PowerShell,运行:
 wsl --install
wsl --install装完重启一下,Ubuntu 自动配置好,直接用。
第 2 步:检查显卡
NVIDIA 显卡是必须的,显存大小决定你能跑多大的模型。4GB 勉强能跑,8GB 比较舒服,16GB 可以跑满血版。检查命令:
nvidia-smi如果看到显卡信息,说明驱动没问题。
第 3 步:装 CUDA
CUDA 是 NVIDIA 的计算平台,没有它显卡跑不了模型。去 NVIDIA 官网下载 CUDA toolkit,建议选 12.x 版本,安装过程直接 next 到底。
第 4 步:编译 Llama-cpp
这是最关键的一步。Llama-cpp 是一个高效的模型推理引擎,支持量化,跑大模型更稳定。
git clone https://github.com/ggerganov/llama.cpp cd llama.cpp mkdir build && cd build cmake .. cmake --build . --config Release编译过程大概 5-10 分钟,耐心等着就行。这里需要注意,如果 CMake 报错,大概率是 CUDA 环境变量没配好,检查一下 PATH 里有没有加 CUDA 的 bin 目录。
第 5 步:下载模型 + 启动
Qwen3.6 的模型文件大概 17GB,建议用磁力链接下载,速度快而且不占用服务器带宽。下载完放到指定目录,然后启动服务:
./llama-server -m qwen3.6-27b.gguf -c 4096 -np 8服务跑起来之后,默认端口是 8080,打开浏览器 http://localhost:8080 就能看到界面。
完全可控,本地离线使用,再也不用去购买 Token。
Telegram 远程控制:这个功能太实用了
很多人可能觉得,本地部署就意味着只能在家里电脑前用。错。
Hermes Agent 支持对接 Telegram 机器人——意思是,你人在外面,手机上发条消息,家里的 AI 助手就能收到并回复。
这个功能解决了一个真实痛点:有时候不在电脑旁边,但还是想调用 AI 助手。接上 Telegram 之后,24 小时在线,随时响应。
配置过程也不复杂,在 Hermes 的配置文件里填入 Telegram Bot Token 和 Chat ID,就能建立连接。具体的配置教程视频下方有详细说明,照着做就行。
和收费模型对比:真的够用吗?
很多人会问:本地模型和 GPT-4、Claude 这些收费模型比,差距有多大?
说实话,论综合能力,开源模型和最顶级的闭源模型确实有差距。但问题在于——你需要那个差距吗?
普通人很多的任务,都不需要用收费模型,本地模型已经足够使用了。
只有一种情况你确实需要收费模型:你要做极其复杂的推理任务,或者对输出质量有极高要求,而且时间成本远大于金钱成本。
但对于绝大多数人来说,本地部署的 AI 助手已经「足够使用」了。这个结论不是我拍的,是大量用户实际使用后的真实反馈。
写在最后
这就是今天要分享的全部内容。
零成本、24 小时在线、数据隐私安全、还能远程控制——本地部署 Qwen3.6 + Hermes Agent,可能是目前最适合普通人的 AI 助手方案。
如果你手里有显卡,真的建议试试。从长远看,AI 这东西用得越多越划算,能省下的订阅费不是一星半点。
看完这篇,你就知道怎么开始了。
觉得有用的话,点个「在看」让更多人看到。有问题评论区见,下一篇聊什么你们来定。