 夜雨聆风
夜雨聆风





AI Agent 的记忆系统:从认知科学到工程实践
引言:为什么 Agent 需要记忆?
和 ChatGPT 聊了一个小时,关掉窗口再打开,它什么都不记得了。
这不是 bug,是 LLM 的本质特性:它是无状态的。每次推理都是独立的,上下文窗口就是它全部的工作空间。对话一旦超出窗口限制,之前的内容就彻底消失了。
对一个简单的问答工具来说,这没什么问题。但当我们期望 AI 成为一个能长期协作的 agent 时,没有记忆就成了致命缺陷。一个不记得你上周说过什么的助手,每次都要从头解释背景,和一个新来的实习生没有区别。
记忆是 agent 从工具变成助手的关键跨越。有了记忆,agent 才能:
-
在长对话中保持上下文连贯 -
从过去的经验中学习,越用越好 -
理解你的偏好和工作习惯 -
处理远超上下文窗口的复杂任务
如何让一个本质上健忘的 LLM 具备记忆能力?这个问题的答案,藏在认知科学对人类记忆的研究里。

认知科学的启示:人类记忆模型
上世纪 60 年代,认知心理学家 Atkinson 和 Shiffrin 提出了经典的多重存储模型,将人类记忆分为三个层次。这个模型虽然简单,却为后来的 AI agent 记忆设计提供了核心蓝图。
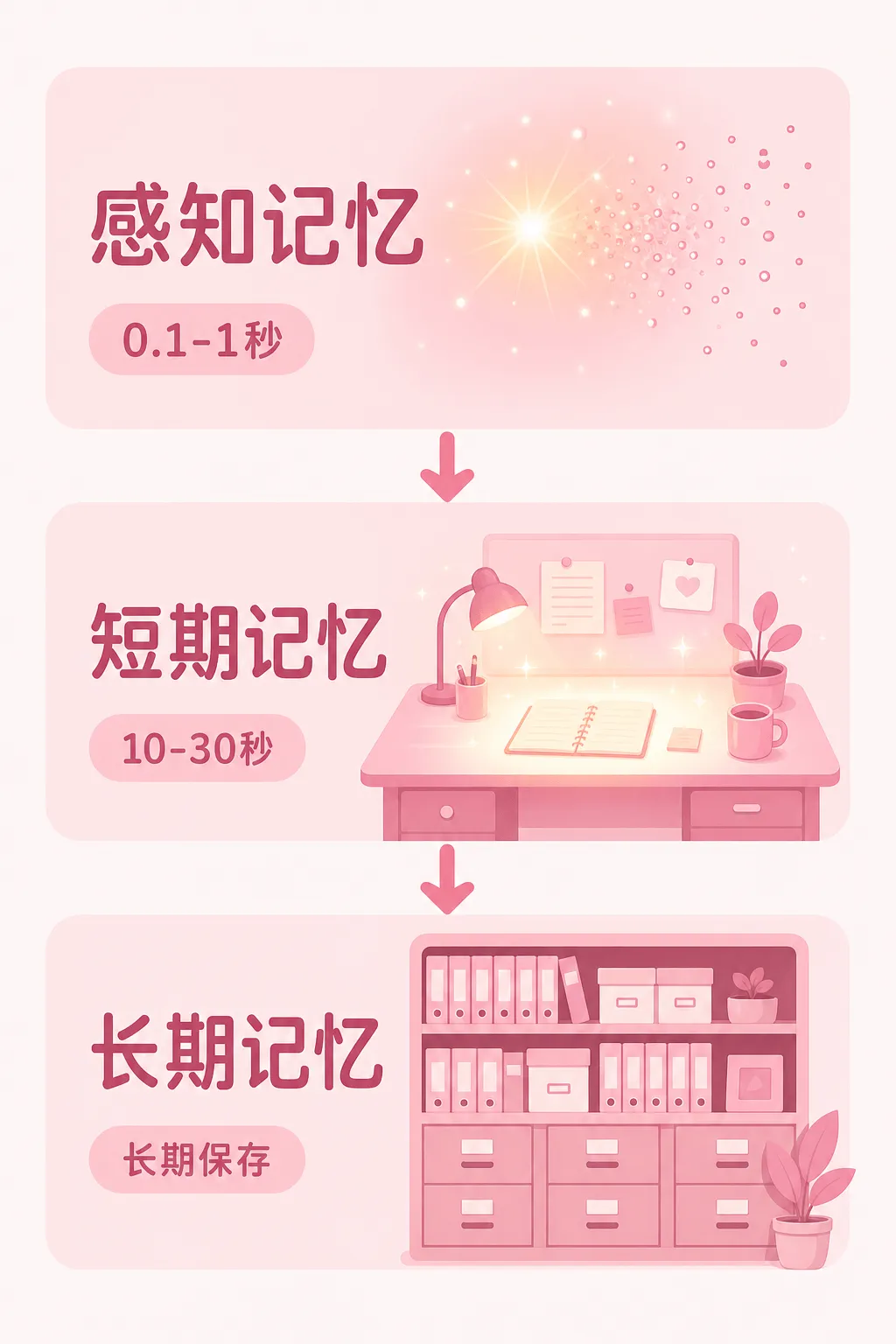
三层记忆模型
感知记忆是最外层的缓冲区。你看到的每一帧画面、听到的每一个声音,都会短暂地停留在感知记忆中。大部分信息在毫秒级的时间内就被丢弃了——你不会记住路上擦肩而过的每个人的脸。
短期记忆,也叫工作记忆,是你此刻正在处理的信息。它的容量很有限——心理学家米勒说”7±2″,大约能同时记住 5 到 9 个信息块。你正在读的这句话、正在思考的问题,都存在于短期记忆中。
长期记忆是真正的持久存储。理论上容量无限,信息可以保存数年甚至一辈子。但长期记忆不是铁板一块,它内部有更精细的分工:
-
情景记忆:对特定经历的记忆。”上周三下午和产品经理开了个会”,”昨天调试了一个诡异的 bug”。 -
语义记忆:对抽象知识和概念的记忆。”TypeScript 是 JavaScript 的超集”,”React 使用虚拟 DOM”。 -
程序记忆:对操作方法的记忆。”怎么用 git rebase”,”这个项目的部署流程是什么”。
映射到 Agent 设计
这个认知模型几乎可以直接映射到 AI agent 的记忆架构设计:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
当前主流的 agent 记忆系统,设计上几乎都在回应同一个问题:如何在有限的上下文窗口内,高效地管理不同类型、不同时间尺度的记忆?
Agent 记忆的核心架构模式
工程界发展出了几种主流架构模式,每种都在尝试解决记忆系统的某个核心挑战。
短期记忆:上下文窗口就是工作台
最简单的记忆方案就是直接利用 LLM 的上下文窗口。窗口内的一切,模型都能”记住”;窗口外的,一律不知道。
LangChain 将这种模式包装为 ConversationBufferMemory,把每一次对话的原始内容都塞进上下文。实现简单,效果在短对话中也不错。但问题显而易见:token 消耗线性增长。对话进行到第 20 轮,token 数可能就已经逼近上下文窗口上限了。
为了解决这个问题,LangChain 衍生出几种变体:
-
ConversationSummaryMemory:用 LLM 逐步总结对话,token 增长从线性变为亚线性 -
ConversationBufferWindowMemory:只保留最近 k 轮对话,像一个滑动窗口 -
ConversationSummaryBufferMemory:混合方案——远处的对话用总结,最近的保留原文
这些方案的本质是在信息完整性和 token 预算之间做权衡。
但无论怎么优化,短期记忆都有一个根本局限:它只能看到当下。当任务需要回顾三天前的讨论、一个月前的决策时,上下文窗口就无能为力了。
记忆流架构:用时间线记录一切
2023 年,斯坦福大学的 Joon Sung Park 团队发表了 Generative Agents 论文。他们构建了 25 个 AI agent,在一个名为 Smallville 的虚拟小镇中自主生活。这些 agent 能做饭、社交、传播消息、形成观点,展现出丰富的社会行为。
支撑这一切的核心是 Memory Stream,即记忆流。
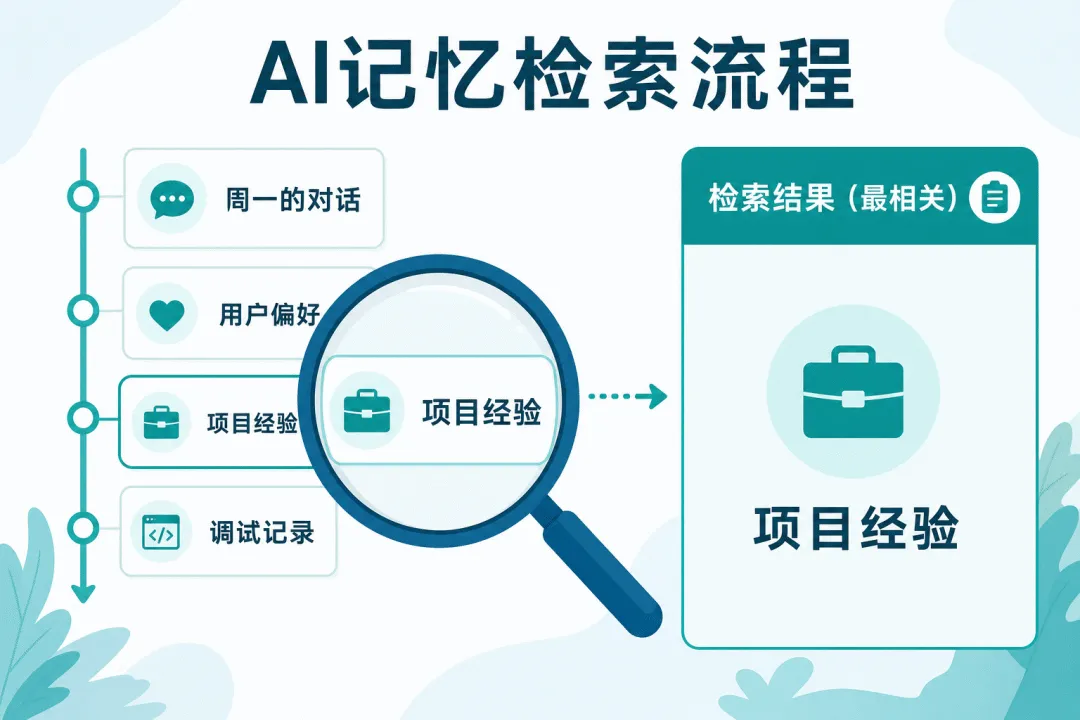
记忆流是一个按时间顺序存储所有观察的列表。每条记录就是一个自然语言描述加上时间戳:”Klaus Mueller 正在图书馆阅读一本关于殖民主义的书”,”Agent A 在下午 3 点和 Agent B 聊了天”。
当 agent 需要做决策时,它不是把所有记忆都塞进上下文——那会立刻撑爆窗口。相反,它通过一个检索函数从记忆流中挑选最相关的几条。这个检索函数结合了三个因子:
新近性(Recency):越近的记忆权重越高,使用指数衰减函数。昨天发生的事比上个月的重要。
重要性(Importance):由 LLM 对每条记忆打分,0 到 10。”Klaus 读了一本书”可能只有 2 分,但”Klaus 和 Maria 吵架了”可能有 8 分。
相关性(Relevance):当前查询与记忆之间的语义相似度,通过 embedding 计算。
三个因子相乘,得到每条记忆的综合得分,取 Top-K 条注入上下文。
这个设计模拟了人类联想记忆的工作方式——我们不会回忆起所有事,而是被当前情境触发,想起最相关、最近、最重要的那些。
分层记忆架构:给 LLM 装一个操作系统
记忆流解决了”存什么”和”怎么找”的问题,但还有一个更根本的挑战:上下文窗口本身就那么大,怎么装下远超窗口容量的信息?
MemGPT(现已更名为 Letta)给出了一个思路:借鉴操作系统的虚拟内存管理。
在传统操作系统中,CPU 有快速但昂贵的缓存,内存容量适中且速度快,磁盘容量大但速度慢。操作系统通过在这些层级之间智能地移动数据,让程序感觉自己在使用一个无限大的内存空间——这就是虚拟内存。
MemGPT 把这个思路搬到了 LLM 上:
-
快速层:LLM 的上下文窗口,相当于 RAM。模型可以即时访问,但容量有限。 -
慢速层:外部存储,比如向量数据库和文件系统,相当于磁盘。容量几乎无限,但需要主动检索。
关键的创新在于让 LLM 自己决定何时在层之间移动数据。当上下文窗口快满时,模型可以主动将不重要的信息换出到慢速层;当需要旧信息时,再把它换入回上下文。
MemGPT 还借鉴了 OS 的中断机制来管理控制流。系统可以暂停当前对话,去处理记忆管理任务,比如整理和归档,然后恢复对话——就像操作系统的上下文切换一样。
LLM 即 CPU,MemGPT 即 OS——把记忆管理从一个被动的检索问题,变成了一个主动的调度问题。
树结构记忆:大文档的导航式阅读
另一种处理大文档记忆的思路来自 MemWalker。它不是把文档塞进上下文,也不是简单地检索片段,而是让 agent 像人一样翻阅文档。
具体做法是:先将长文档处理成一棵摘要节点树。树的根节点是文档的全局摘要,子节点是各章节的摘要,叶节点是原始文本段落。
agent 从根节点开始,根据当前需求决定往哪个分支深入。它不需要通读全文,只需要沿着树结构导航,逐步聚焦到相关部分。
这种设计有两个额外好处。一是可解释性——agent 的导航路径本身就是推理过程的可视化,你可以看到它是从哪个章节的哪一段得出结论的。二是效率——相比于把整个文档塞进上下文或做全量检索,树结构导航在 token 消耗上更加可控。
反思与记忆整合:从经验中提炼规律
前面讨论的都是”怎么记住”。但人类记忆的一个关键特性是:我们不仅记住事实,还会从事实中提炼规律。
Generative Agents 中的 Reflection 机制就是对这种能力的模拟。agent 会定期对最近的观察进行高层综合,生成更抽象、更概括的反思。比如:
-
原始观察:”Klaus 今天去图书馆了”,”Klaus 昨天也去了图书馆”,”Klaus 前天在咖啡店读论文” -
反思产出:”Klaus 是一个勤奋的学者,经常在安静的环境中工作”
反思结果会被反馈到记忆流中,和原始观察一起参与后续的检索。agent 的记忆不只是事件的堆砌,还包含了对事件的理解和归纳。
MemoryBank 进一步引入了艾宾浩斯遗忘曲线的思路:记忆的强度会随时间衰减,但如果被反复调用或被标记为重要,就会被强化。这解决了一个实际问题——不是所有记忆都值得永远保留。三个月前的调试细节可能已经没用了,但”这个项目使用 monorepo 架构”这个事实应该长期保留。
RAG:检索即记忆
最后一种架构模式,是很多开发者最熟悉的:检索增强生成(RAG)。
从记忆系统的视角来看,RAG 的本质就是把外部知识库作为可更新的长期记忆,检索操作作为记忆的读取机制。
用户提问 → 从知识库中检索相关文档 → 将检索结果注入上下文 → LLM 基于上下文生成回答。
这和人类遇到问题时去翻资料几乎一模一样。
RAG 作为记忆架构的优势在于:知识可以随时更新,无需重新训练模型。今天加了一篇新文档,明天 agent 就能用上。这比微调模型来更新知识要灵活得多。
但 RAG 也有局限:它更擅长存储事实,也就是语义记忆,不太擅长存储经历和方法。这也是为什么 RAG 通常需要和上述其他架构模式配合使用。
三大 AI 编程助手的记忆系统对比
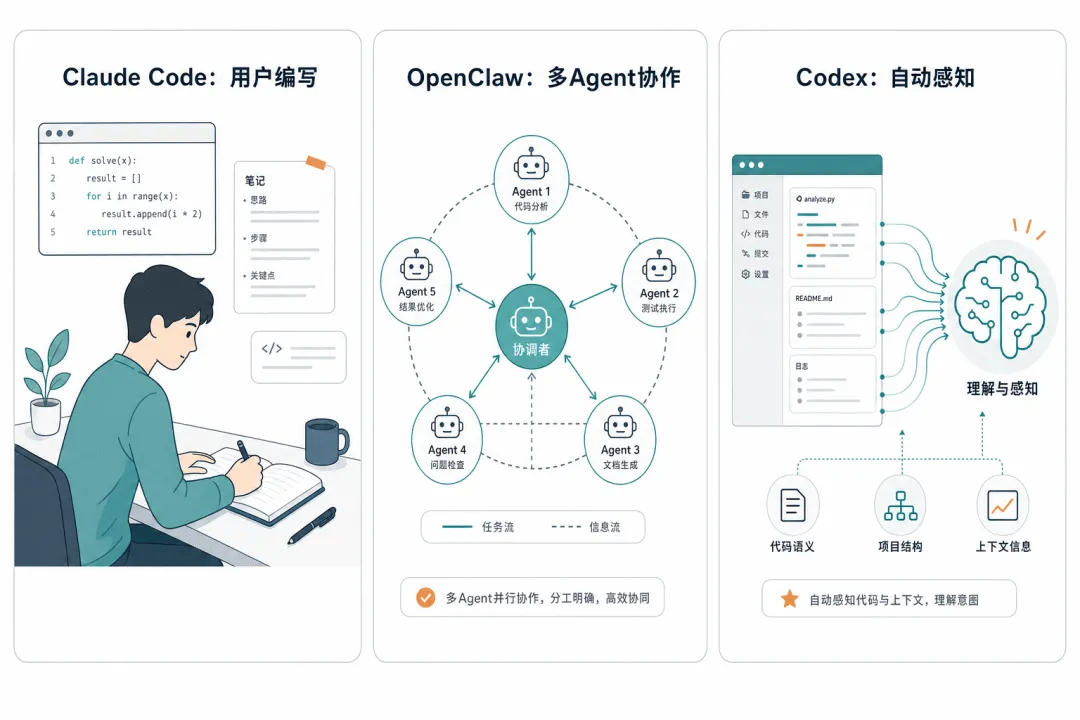
前面是理论,这一节看实际产品怎么做。我们选了三个有代表性的 AI 编程助手——Claude Code、OpenClaw 和 Codex——分析它们的记忆系统设计。
Claude Code:双重记忆 + 分层作用域
Claude Code 采用了双系统设计:一个由用户编写,一个由 AI 自动积累。
CLAUDE.md 是用户编写的指令文件,类似于给新同事的一份入职手册。你可以在里面写项目架构、编码规范、构建命令、团队约定——任何 Claude 在每个会话中都应该知道的事情。它通过 @path 语法可以导入其他文件,支持在项目根目录、用户目录、甚至组织级别放置,形成一个四级作用域:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
更精细的是,Claude Code 支持 .claude/rules/ 目录下的路径特定规则。比如你可以写一条规则”只在编辑 src/api/ 下的文件时才加载 API 设计规范”,这样规则不会在无关场景下浪费上下文窗口。
Auto Memory 是 AI 自动积累的记忆。Claude 在工作过程中会自己判断什么值得记住——构建命令、调试经验、代码风格偏好——然后写入 ~/.claude/projects/<project>/memory/ 目录。MEMORY.md 作为索引文件,前 200 行会在每个会话开始时加载;详细的主题笔记,比如 debugging.md,则按需读取。
这种设计的哲学是规则由人控制,经验由 AI 积累。CLAUDE.md 保证了关键指令的确定性,Auto Memory 让 agent 能从交互中持续学习。
OpenClaw:多 Agent 记忆隔离与共享
OpenClaw 面向的是一个不同的场景:多个 agent 协作。
它的记忆体系建立在一组 Bootstrap 文件之上:
-
AGENTS.md:操作指令 + 长期记忆,相当于 agent 的工作手册 -
SOUL.md:定义 agent 的人格、边界、语气 -
USER.md:用户画像和偏好 -
TOOLS.md:工具使用说明和约定
每次新会话开始时,这些文件的内容会被注入系统提示词的 Project Context 中,实现跨会话记忆传递。空白文件会被跳过,过大的文件会被截断。
OpenClaw 的独特之处在于它的多 Agent 架构。每个 agent 都有完全隔离的 workspace、session store 和 auth profile。你可以让一个 agent 负责前端开发,另一个负责后端,它们各自维护独立的记忆,互不干扰。
但在某些场景下,agent 之间又需要共享信息。OpenClaw 通过 QMD 跨 agent 记忆搜索来实现——一个 agent 可以通过 extraCollections 配置搜索另一个 agent 的会话记录。记忆的隔离和共享变成了一个可配置的连续谱,而不是非此即彼的选择。
对于多通道场景,OpenClaw 的设计也有参考价值:无论用户通过 Discord、Telegram 还是 WhatsApp 和 agent 交互,都会路由到同一个 agent 的同一个 session,记忆是统一的。
Codex:记忆即 Markdown + 屏幕感知
Codex 的记忆系统走了一条更激进的路线:全自动记忆生成,甚至包括屏幕感知。
Codex 的 Memories 系统默认关闭,开启后会在后台自动从历史对话中提炼记忆。它会分析已完成的会话,提取偏好、工作流、技术栈、已知陷阱等信息,写入本地 markdown 文件(存在 ~/.codex/memories/ 下)。
这个自动生成过程有几个设计决策值得留意:
-
跳过活跃会话:等待线程空闲足够久再处理,避免总结还没完成的工作 -
敏感信息脱敏:自动从记忆内容中移除密钥等敏感数据 -
按线程控制:每个线程可以独立决定是否使用记忆、是否允许从该线程生成新记忆 -
速率限制保护:如果 API 额度不足,会跳过记忆生成
Codex 最具创新性的功能是 Chronicle——一个屏幕感知记忆系统。它会定期截取屏幕截图,通过 OCR 提取文字,然后用后台 agent 生成记忆摘要。Codex 不仅能记住你和它说过什么,还能看到你在做什么。
比如你正在 VS Code 中修改一个 React 组件,Chronicle 能感知到这一点,下次你和 Codex 对话时,它就知道你最近在处理前端工作,不需要你重新解释上下文。
Chronicle 也带来了隐私和安全的挑战。Codex 文档明确警告:屏幕内容可能包含恶意指令,存在提示注入攻击的风险,而且截图目录中的敏感数据可能被其他程序访问。
对比总结
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
三个产品展示了三条不同的记忆设计路径:Claude Code 偏向用户控制,OpenClaw 偏向多 agent 协作,Codex 偏向自动化感知。选择取决于你的使用场景和对控制权的偏好。
开放问题
记忆系统已经取得了不少进展,但几个核心问题仍然没有答案。
准确性 vs 效率的权衡
更多记忆并不意味着更好表现。当检索到的记忆过多时,LLM 反而会被噪声干扰,产生错误的回答。如何设计好的记忆选择和遗忘机制——知道什么时候该记、什么时候该忘——仍然是一个开放问题。
MemoryBank 引入的艾宾浩斯遗忘曲线是一个方向,但如何确定重要性阈值、如何平衡新旧记忆的权重,还没有通用的解决方案。
灾难性遗忘
当 agent 长期运行并不断积累新记忆时,它可能会忘记早期学到的重要知识。这和神经网络中的灾难性遗忘是同一个问题:新知识覆盖了旧知识的存储空间。
在记忆系统的语境下,这意味着:当记忆库满了,新的记忆写入时,应该淘汰哪些旧记忆?简单的 LRU 策略可能不够好,因为一条很久没用但很重要的记忆不应该被淘汰。
多 Agent 的记忆共享与隐私
随着多 agent 系统的普及,记忆的共享和隔离变得越来越重要。OpenClaw 的可配置共享是一个开始,但更深层的问题是:当多个 agent 共享记忆时,如何保证信息的一致性和权限控制?一个 agent 的机密信息不应该被另一个 agent 读取。
Codex Chronicle 带来的隐私挑战也值得关注——屏幕感知记忆意味着 agent 能看到你在做什么,这在提升效率的同时,也引入了新的攻击面。
记忆的评估
如何衡量一个记忆系统的好坏?现有的 agent benchmark 很少专门评估记忆能力。几个值得探索的评估维度:
-
召回准确性:需要某条记忆时,能否准确找到? -
遗忘合理性:不重要的记忆是否被适时清理? -
跨会话一致性:agent 在不同会话中是否保持一致的行为和知识? -
token 效率:在有限的上下文预算内,记忆系统能提供多少有用信息?
总结

AI Agent 的记忆系统,本质上是在有限的上下文窗口内,模拟人类记忆的分层结构和动态管理能力。
从认知科学的三层记忆模型出发,工程界发展出了记忆流、分层记忆、树结构导航、反思整合、RAG 等多种架构模式。Claude Code、OpenClaw、Codex 三大产品的实践则展示了理论落地时的不同设计路径。
记忆是 agent 能力的倍增器。更好的记忆系统,通向更智能的 agent。
参考文献
-
Park et al., “Generative Agents: Interactive Simulacra of Human Behavior”, arXiv:2304.03442, 2023 -
Packer et al., “MemGPT: Towards LLMs as Operating Systems”, arXiv:2310.08560, 2023 -
Zhang et al., “A Survey on the Memory Mechanism of LLM-based Agents”, arXiv:2404.13501, 2024 -
Sumers et al., “Cognitive Architectures for Language Agents”, arXiv:2309.02427, 2023 -
Zhong et al., “MemoryBank: Enhancing Large Language Models with Long-Term Memory”, arXiv:2305.10250, 2023 -
Chen et al., “Walking Down the Memory Maze”, arXiv:2310.05029, 2023 -
Zhao et al., “Retrieval-Augmented Generation for AI-Generated Content: A Survey”, arXiv:2402.19473, 2024 -
LangChain Documentation: Conversational Memory -
Anthropic: Claude Code Memory Documentation -
OpenClaw Documentation -
OpenAI Codex Documentation