 夜雨聆风
夜雨聆风





AI 合同审查测评:ChatGPT、Claude、豆包、DeepSeek,哪个好?


武泽钰
iCourt 法律 AI 研究员
越来越多的律师、法务以及法学生开始尝试借助大模型辅助合同审查。从实际使用情况来看,这些模型在基础能力层面已经能够提供较为稳定的支持,尤其是在风险识别和文本分析方面,整体表现已经具备一定实用价值。
但在进一步使用过程中,不同模型之间的差异也逐渐显现:有的更侧重全面覆盖与细节展开,有的更强调结构与重点把握,也有的在条款修改和法律分析上更具优势。
不同模型在识别和分析方面存在差别,直接影响了其在具体审查场景中的使用体验。
这与合同审查本身的工作特性密切相关。合同审查并非单一维度的任务,而是围绕交易背景、双方谈判地位、责任分配、风险控制以及委托方立场所展开的综合判断过程。
这一过程既要求对法律和商业规则的准确理解,也依赖对具体业务场景的把握。因此,不同能力侧重的模型,在这一过程中自然会呈现出不同的适配程度。
基于此,本文不再从技术原理出发讨论模型能力,而是聚焦一个更实际、更贴近律师工作的问题:在同一份合同、同一套提示词之下,哪款 AI 审查合同的水平,更接近人类律师?
我们选择了 ChatGPT、Claude、豆包、DeepSeek 四款模型,做了一次详细的测评。

测评规则一览
本次选取四款具有代表性、且在法律从业者中讨论度较高的大模型进行对比测试,分别为:
– Claude-4-6
– ChatGPT-5.4
– Doubao-Seed-2.0-pro
– DeepSeek-V3.2-think
上述模型在当前法律 AI 应用场景中均有一定使用基础,具有可比性。之后我们也会增加 DeepSeek-V4 的测评,请各位持续关注。
测试材料部分,我们选取了两份不同类型的合同作为样本,以覆盖基础商业合同与强监管法律场景下的审查需求。
测试合同一:采购合同,约 1800 字
审查视角:乙方(卖方)
合同概述:该合同对乙方(卖方)存在多处不利约定,例如:争议解决方式设置不利、付款期限不明、双方违约责任明显失衡,尤其是缺少甲方违约责任条款,而对乙方逾期交货的违约责任规定过高;同时验收机制也不明确。
测试目的:主要考察模型的基础风险识别能力,看其能否抓住合同中的核心商业和法律风险。
测试合同二:劳动合同,约 3000 字
审查视角:甲方(用人单位)
合同概述:合同中特意在试用期、加班管理、病假工资、劳动者违约责任等条款中「挖坑」,多处约定明显违反相关法律规定。相较于采购合同,该合同对审查的法律规范的准确适用与合规判断要求更高。
测试目的:本合同以用人单位视角进行审查,重点考察模型在劳动法语境下的合法性识别能力与规范适用能力。
为保证测试结果的可比性,本次测评对四款模型均采用同一套提示词,通过控制输入变量,尽可能将差异限定在模型本身的能力表现上。
提示词内容如下:
# 角色
你是一位拥有 20 年执业经验的资深律师,擅长合同审查。你能够精准捕捉合同中潜藏的合规风险、商业陷阱及逻辑漏洞。
# 人物
请站在你客户的立场对合同进行全面的审查,你需要坚定地维护客户利益。
# 执行逻辑
请阅读全篇合同,识别合同类型及核心法律按照以下审查维度逐项审查:
1. **合法合规性审查**:确保合同内容符合《民法典》及相关法律法规。
2. **核心条款审查**:结合合同的性质及内容分别从以下方面进行审查:
– **标的条款**:描述是否准确、清晰。
– **权利义务**:双方权利义务是否明确,是否存在「霸王条款」或责任缺失。
– **合同价款**:支付方式、期限、发票开具及税费承担是否明确。
– **履行条款**:履行期限、地点、标准及验收流程是否约定明细且具备可操作性。
– **违约责任**:违约金计算标准是否明确,是否足以覆盖我方潜在损失,是否存在对我方不利的违约责任。
3. **程序性条款审查**:
– **争议解决**:仲裁或诉讼管辖约定是否有效、是否对我方有利。
– **生效条款**:签署要求、生效条件及期限。
– **通知与送达**:联系方式及送达效力的约定。
4. **形式审查**:合同错别字、序号、前后表述的一致性。
# 输出
请在前面用一段话概括该合同的核心风险点,如存在不合法不合规的约定或是核心条款的风险点;再分别呈现审查点格式如下:
风险点 1:xxx;修改原因:xxx:修改建议:xxx/n
风险点 2…
# 要求
– 请使用规范的法律术语。
– 你给的建议需要具备针对性,不要只给宽泛的建议,要针对合同具体内容进行分析。
– 只需要输出审查建议,不需要给出建议或其他内容。
为尽可能还原律师在实际合同审查中的工作逻辑,本次测评从以下五个维度对模型表现进行综合评价:
1、风险识别与重点把握能力:考察模型是否能够从整体交易结构出发,识别合同中的核心风险点,并对关键条款进行优先提示,而非停留在零散或表层问题。
2、风险分析的专业性:考察模型是否能够说明风险产生的法律原因,并结合现行法律规定或司法实践,对潜在法律后果进行明确分析,而非泛泛而谈。
3、修改建议的可操作性考察:模型是否能够提出具体、可执行的修改方案,包括条款重写、数值补充或机制设计,而非停留在原则性建议层面。
4、立场意识:考察模型是否能够在审查过程中始终坚持特定当事人立场(如乙方或用人单位),对不利条款进行针对性识别与调整,而非保持「形式中立」。
5、场景适配与基础文本审校能力:考察模型输出是否符合实际场景,并具备基础文本审校能力,包括识别明显错别字、序号错误等形式问题或表述瑕疵。

实测对比:四款模型,差别到底在哪里?
我们先看第一份合同审查结果的评分。
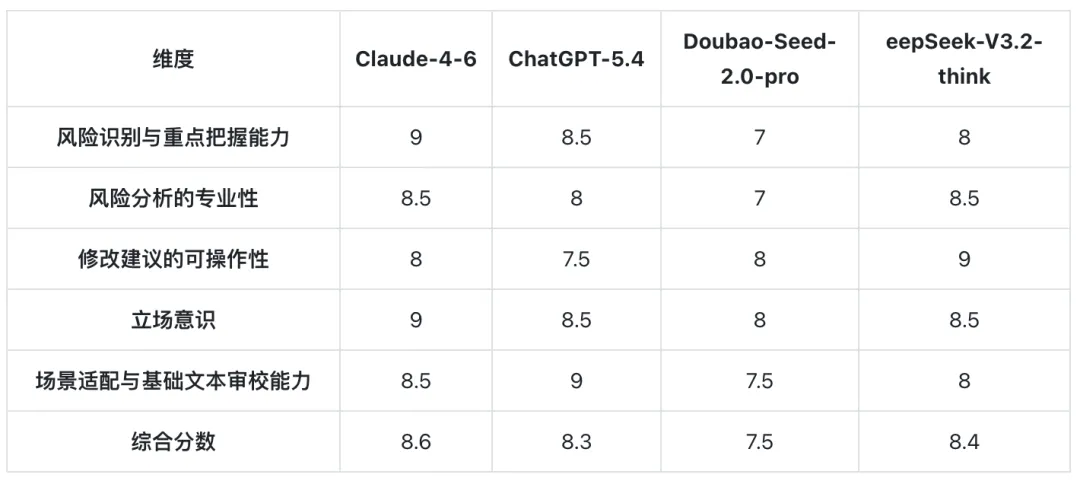
Claude-4-6
优点:风险识别较全面(15 个风险点),立场意识强烈,每个风险点均明确说明对乙方的不利后果。特别擅长识别隐蔽风险(如间接赔偿责任无上限、知识产权条款范围过宽),修改建议具体且可操作。
问题:个别修改建议略显冗长,部分条款(如质保期、保密条款)属于锦上添花而非核心风险。
ChatGPT-5.4
优点:风险点数量最多(50 个风险点),覆盖面极广,文本审查尤其是细节把控能力突出(发现「NY0T」错误、开户许可证过时等细节问题),场景适配性强。
问题:风险点过于分散,部分风险重复或重要性不高(如包装物责任、计量方式等),导致重点不够突出,可能让客户抓不住核心矛盾。
Doubao-Seed-2.0-pro
优点:抓住了核心的风险条款(争议解决条款无效、权利义务失衡),修改建议简洁明了,适合快速决策场景。
问题:遗漏了多个重要风险,如发票条款、知识产权条款对己方不利、安全责任的间接损失等,专业深度不足。
DeepSeek-V3.2-think
优点:法律分析最专业(引用《民法典》具体条文、司法解释),修改建议最具可操作性(提供具体数值示例如 20%、15 日等),律师工作流规范。
问题:风险点数量较少(8 个),对部分次要风险(如发票、保密等条款)关注不够。
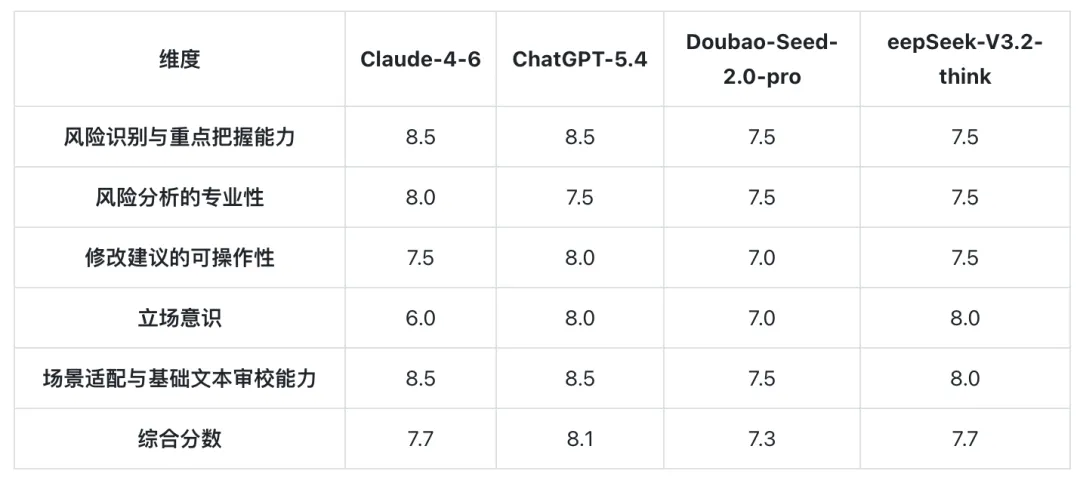
Claude-4-6
优点:识别了 15 个风险点且分析较为专业,其中对试用期、加班工资等核心风险点均有提示,尤其是关于试用期延长的规定切中要点且修改的也很完美。
问题:存在明显的立场偏差问题,即忽视了己方用人单位的立场完全站在劳动者立场审查。
ChatGPT-5.4
优点:识别出 45 个风险点,既抓住核心违法条款,又关注程序性、操作性细节。特别是从甲方用人单位立场出发,系统性地指出了举证困难、制度衔接不足、送达机制缺失等实务痛点。文本审校细致,发现了多处编号错误和表述瑕疵。
问题:在审查建议中有细节错误,如提到「固定期限 3 年的劳动合同,试用期最长只能约定 2 个月」是错误的。
Doubao-Seed-2.0-pro
优点:表现中规中矩。识别了 12 个风险点,覆盖主要违法条款,法律分析基本准确,但修改建议相对原则化,部分条款的可操作性不足。
问题:立场意识不够突出,缺少从己方用人单位视角下对考核标准、录用条件等条款进行明确。
DeepSeek-V3.2-think
优点:只识别 7 个风险点,但每个都切中核心条款,分析深度到位,修改建议具体可落地,提供了完整的修改后文本。立场把握准确,从甲方角度充分考虑了法律风险和举证责任。
问题:风险覆盖面不够,部分条款的修改不够好(如审查建议中提到了法律规定试用期只有一次,但是在修改内容中仍然提出可以延长试用期)。

从整体测评结果来看,四款模型在合同审查这一场景下,基础能力已经较为接近。在两份合同中,各模型基本都能够识别出主要风险点,这说明在「发现问题」这一层面,大模型已经可以提供较为稳定的支持。
如果用更直观的方式来理解,可以把不同模型的表现类比为不同类型的律师:
ChatGPT-5.4 与 Claude-4-6 整体更偏「高完成度」风格,审查更细致、覆盖更全面。
其中,ChatGPT-5.4 在细节把控和覆盖范围上表现突出,但有时也会因为展开过多,导致重点不够集中;Claude 则在结构和立场表达上更鲜明,部分审查意见和修改建议会相对「主动」和「有判断」,呈现出更强的个人风格,当然也会存在一些修改建议比较「大胆」和「有想法」的情况。
DeepSeek-V3.2-think与 Doubao-Seed-2.0-pro 整体风格则相对稳健和基础。两者都能够完成核心审查任务,风险识别也较为准确,但在表达风格和分析展开上相对克制,没有特别突出的「个性」,更接近于按规范完成工作的状态。其中,DeepSeek 在专业分析和条款执行方面的表现仍然较为亮眼。
综合来看,如果从专业性与完成度角度评价,ChatGPT-5.4 与 Claude的表现更为突出;DeepSeek 在关键问题上的处理同样具备较强水准;而豆包则更偏向于提供一个稳定、基础的审查结果。
需要强调的是,这种差异更接近于「执业风格的不同」,而不是简单的优劣划分。不同模型的输出方式,对应的是不同的使用场景和偏好。
2、律师可以选择不同的模型,解决不同的审查需求。
基于上述差异,模型的使用方式,实际上更接近于一种「工具选择与组合」的问题,而不是单一依赖。
在实际工作中,可以做一些相对明确的区分:
在需要尽可能覆盖风险、避免遗漏的场景下,可以优先使用审查更细致、展开更充分的模型,比如 ChatGPT-5.4;
在需要对外输出意见或快速抓住核心问题时,更适合选择结构更清晰、重点更突出的模型,比如 Claude;
在涉及条款修改或具体落地时,则应优先考虑文本生成能力更强、表达更具体的模型,比如豆包或 DeepSeek。
换句话说,模型的选择更应基于具体的审查目标和使用需求,而不是用同一个模型覆盖全部工作。

更简单的用法:选择专业法律 AI
从产品视角来看, iCourt AIGC 法律研究员的日常工作,很重要的一部分就是持续测评不同模型在各类法律场景中的表现,并将其能力与具体业务模块进行匹配。
换言之,通过对模型能力的理解,在产品层面完成「选择与分配」,从而让用户在使用过程中无需反复判断。
因此,法律 AI 产品的价值之一,并不只是接入某一个模型,而在于在不同法律场景下,优先调用更合适的能力。
这是将「模型选择」这一原本需要用户自行完成的过程,转化为产品的一部分,从而提升整体使用效率与稳定性。
目前,我们团队参与开发的 AlphaGPT 就通过内部流程调试实现了一点,进而提升了合同审查的整体效果、效率和稳定性。
在产品体验上,AlphaGPT 的合同审查板块,有四个大功能:智能审查、模板审查、补充协议审查和规章制度审查。
1、智能审查
即上传合同 AI 自动进行审查,审查完成后会进入修订页面,可以非常方便地对合同文档进行审阅、修订:
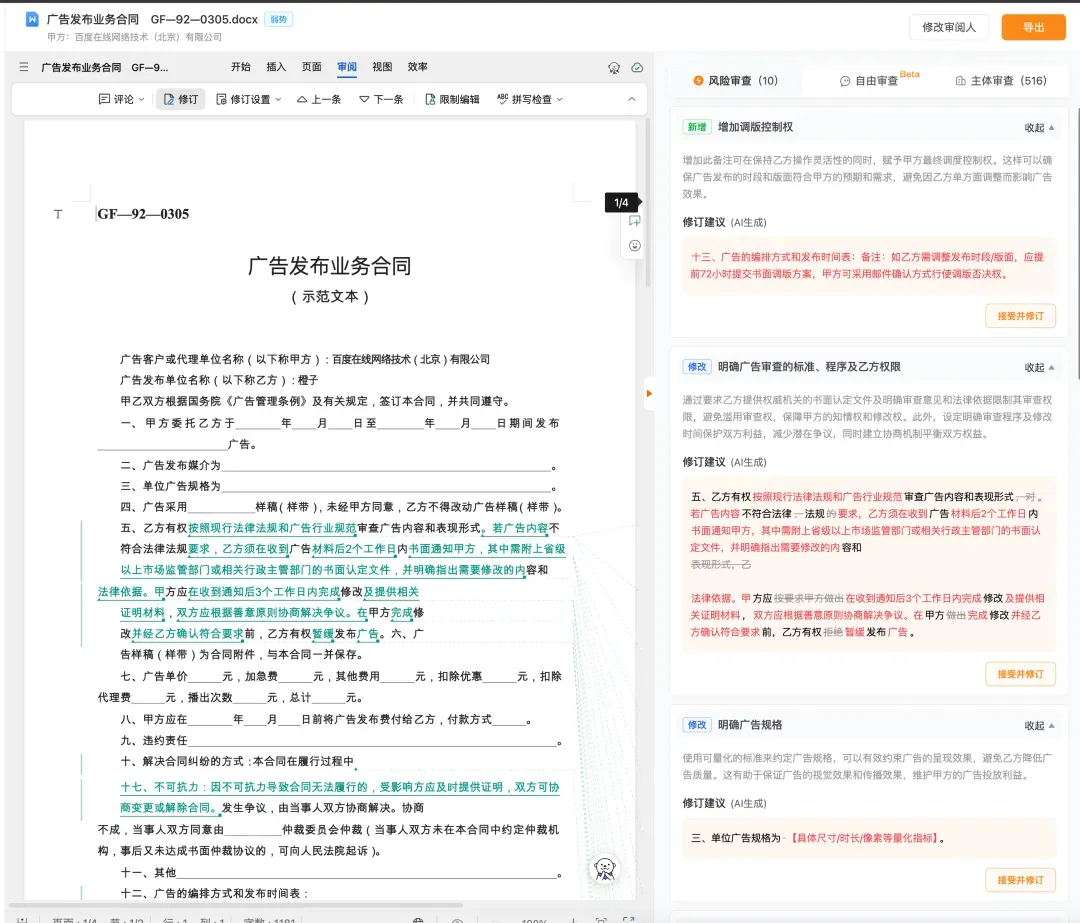
自由审查板块,还可以用提问的方式,让 AI 更细致地审核对应细节:
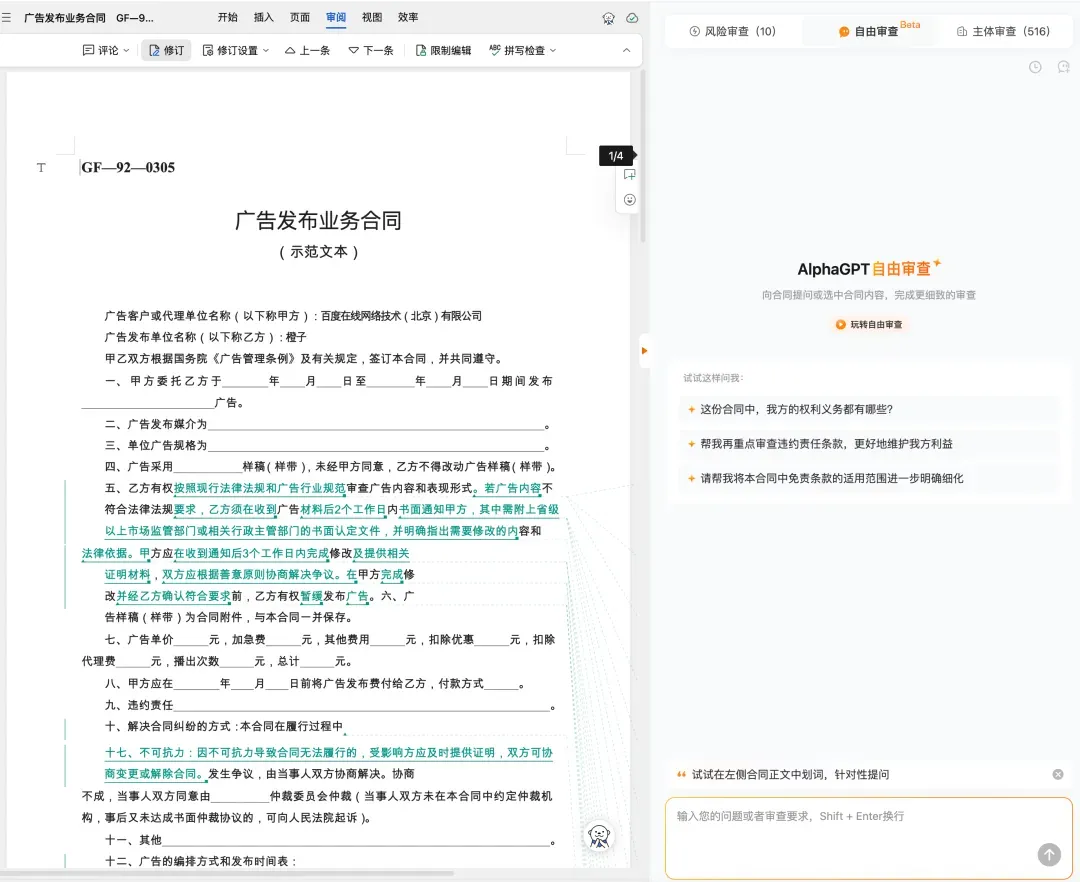
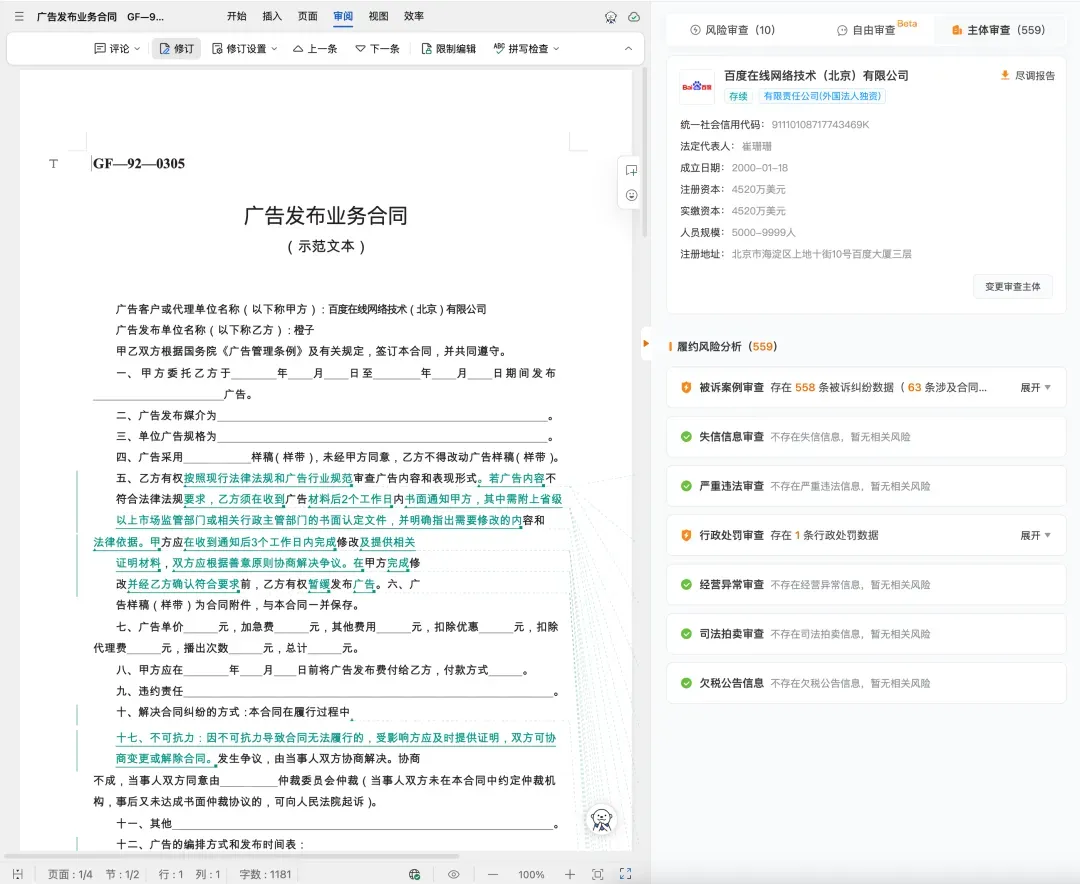
如果合同涉及相关主体,主体审查模块则可以审查主体的履约风险分析,并一键下载尽调报告。
2、模板审查
模版合同经常被作为审查合同的重要参照,像常见的风险点、某些行业的固有合同惯例、合同中强势方的「合理性依据」等,通常都会固化在模版中。
如果 AI 能够参考固定的模板合同进行新合同的审查,能很大程度上避免律师重复修改、审核。
目前 AlphaGPT 便提供了模版审查的功能。在 AlphaGPT 合同审查页面的左侧上传待审合同,右侧上传模板合同,就能以模板为基准,快速定位待审合同中存在的遗漏、修改或新增风险点。
该功能可以有效保障合同批量化处理时的质量、效率及一致性。
3、补充协议审查
实务中,补充协议极为常见。原合同条款变化、部分条款单独协定、给历史合同「打补丁」等,都需要增加补充协议。
但审查补充协议有它的难点。律师需要参考主合同,重点关注被修改的条款、被“间接影响”的条款,以及补充协议是否造成逻辑冲突或责任失衡。
虽然补充协议篇幅不长,却可能对原合同的权利义务结构产生实质性、甚至颠覆性的影响。审核补充协议,一点不比审核原合同简单。
AlphaGPT 的补充协议审查功能,便是针对这一场景开发。通过同时上传原始协议与补充协议,AI 会首先理解主合同的权责框架与关键约定,在此基础上审视补充协议,识别出补充协议可能引发的解释冲突或对主合同关键条款的实质性修改,帮助规避因协议间割裂而产生的履约风险。
相比人工翻查、反复对照文本,该功能显著提升审查效率,尤其适用于「一主合同多补充协议」「历史合同反复打补丁」等复杂场景。同时,AI 以结构化方式呈现风险点和修改建议,有助于律师快速对补充协议的调整做出判断。
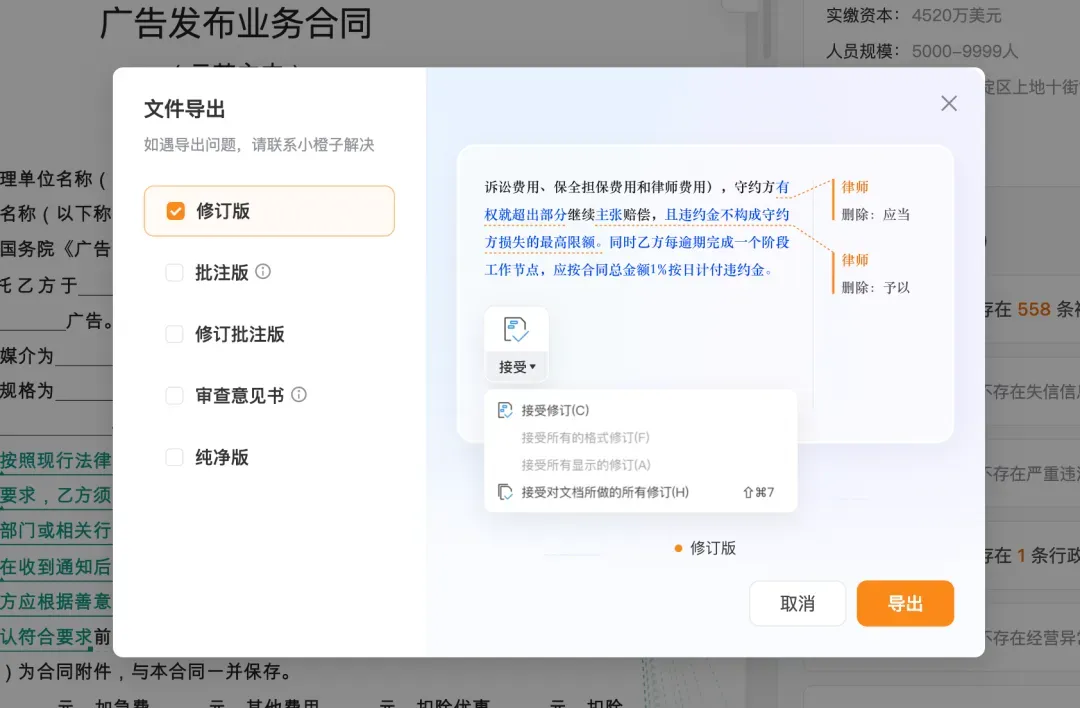
审查完成后,还有多种版本文件可选择导出:
4、规章制度审查
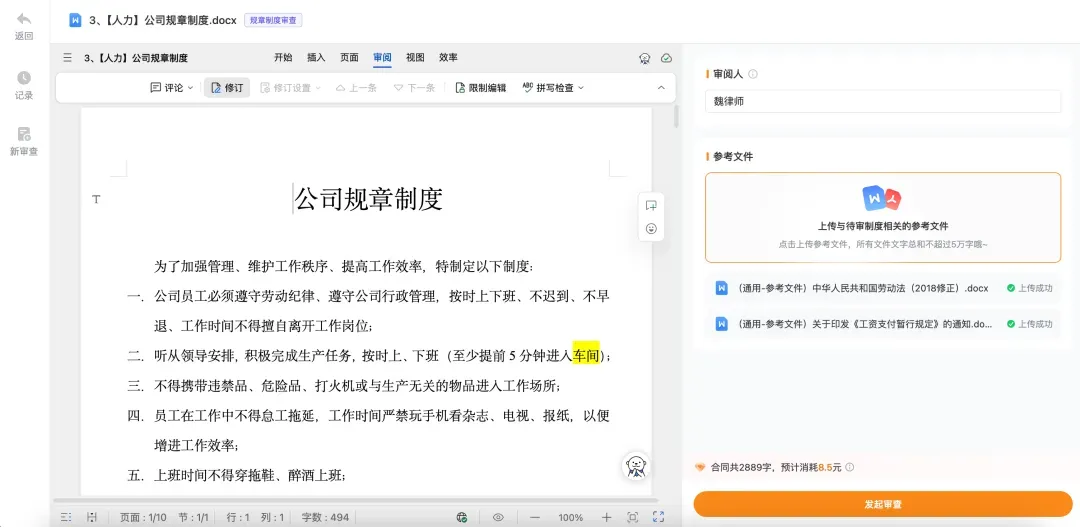
这是 AlphaGPT 新增的功能。只需在审查前上传相关的参考文件(如企业过往制度、行业规范、内部管理指引等),AlphaGPT 便会深度学习这些文档再开始审核,让审查结果更贴合企业的实际情况,输出真正可落地的修改建议,精准度大幅提升。
除合同审查外,AlphaGPT 还涵盖类案检索、法律咨询、文书写作、证据阅卷等多个功能板块,能大幅减少律师的重复性工作,将原本需要数小时的基础任务缩短至几分钟。
目前已有数万名律师在使用 Alpha AI,每一项功能都收获了众多好评。
扫描下方二维码,即可领取免费试用。

撰文:武泽钰 编辑:魏新峰