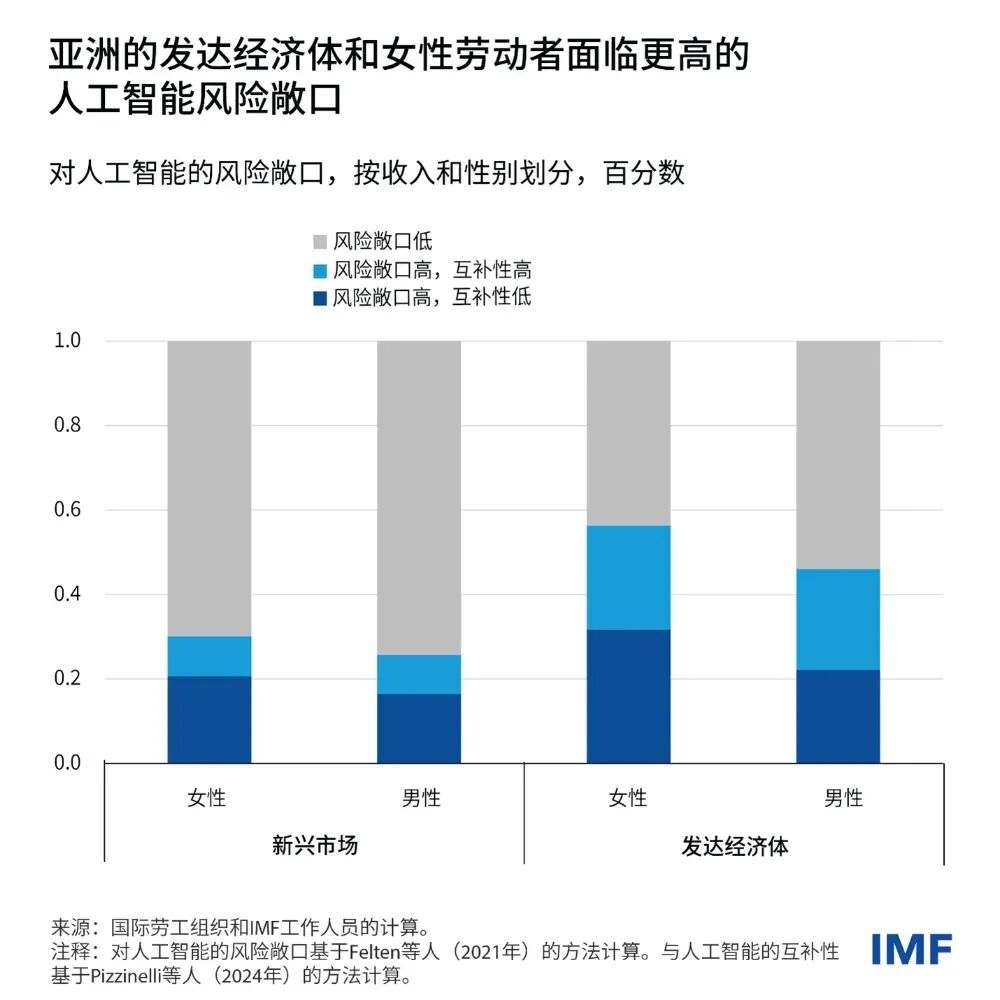
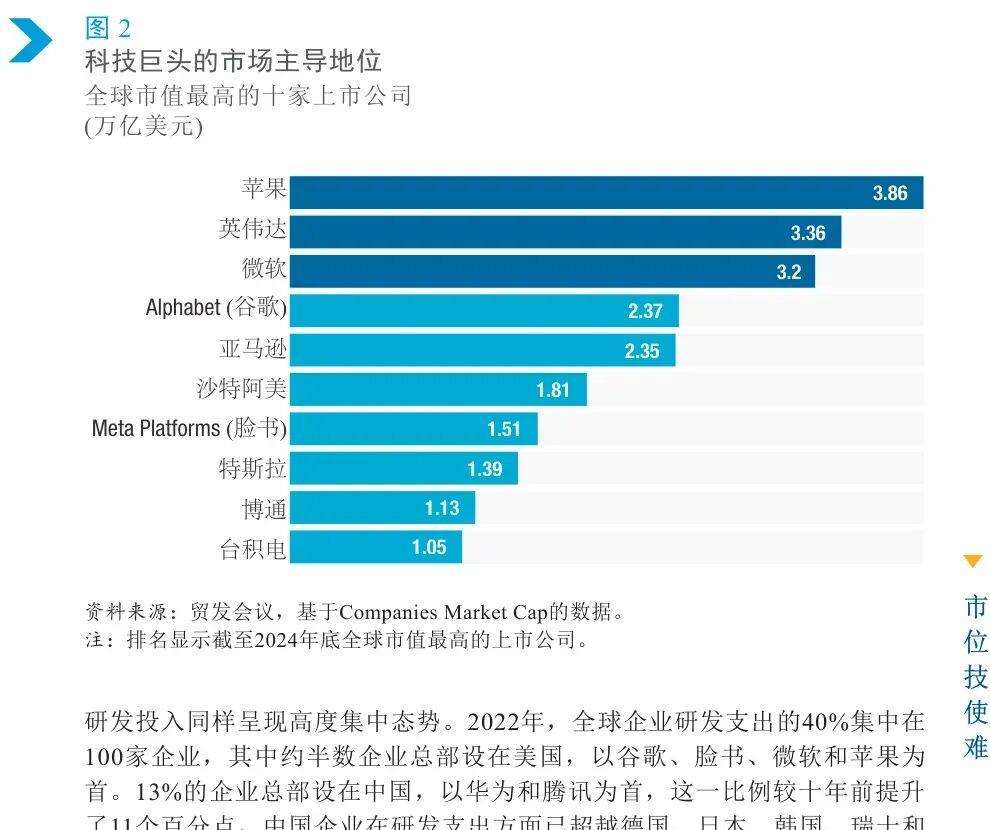
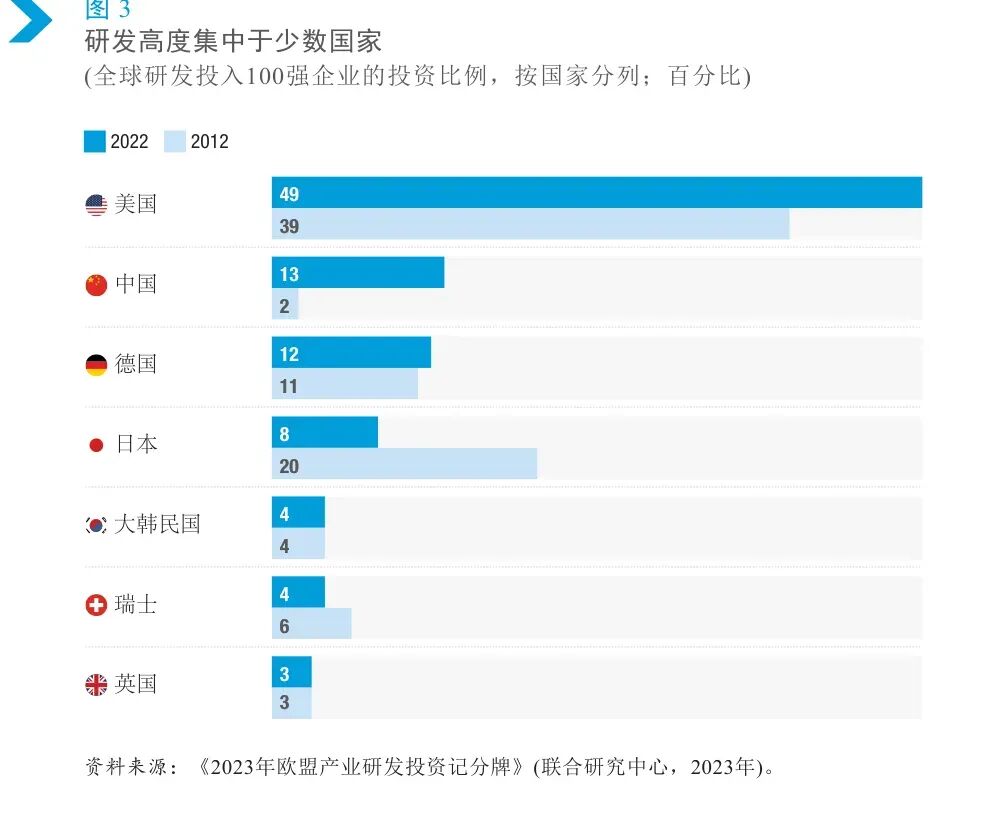
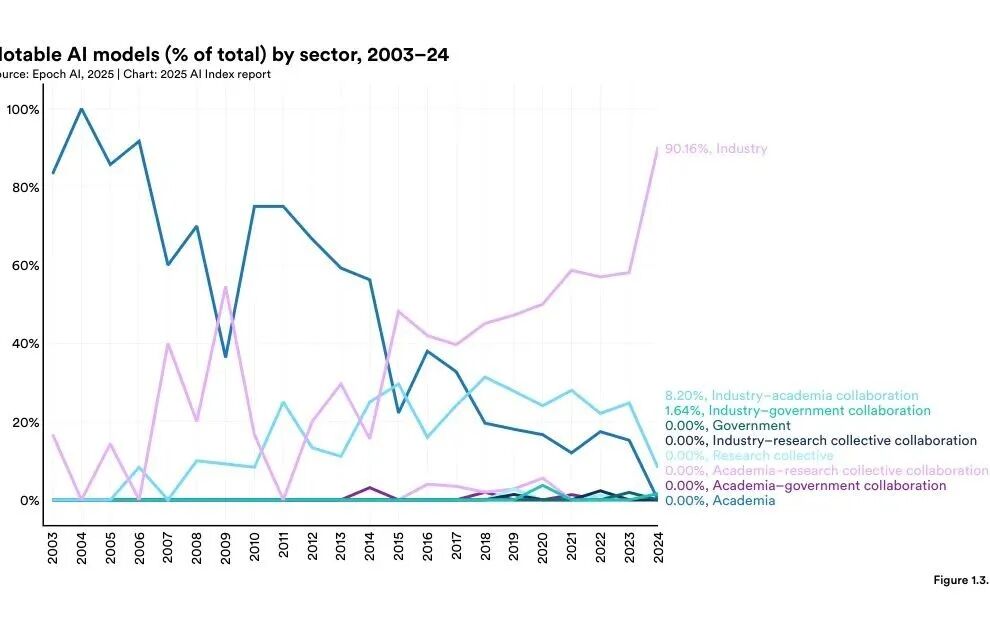
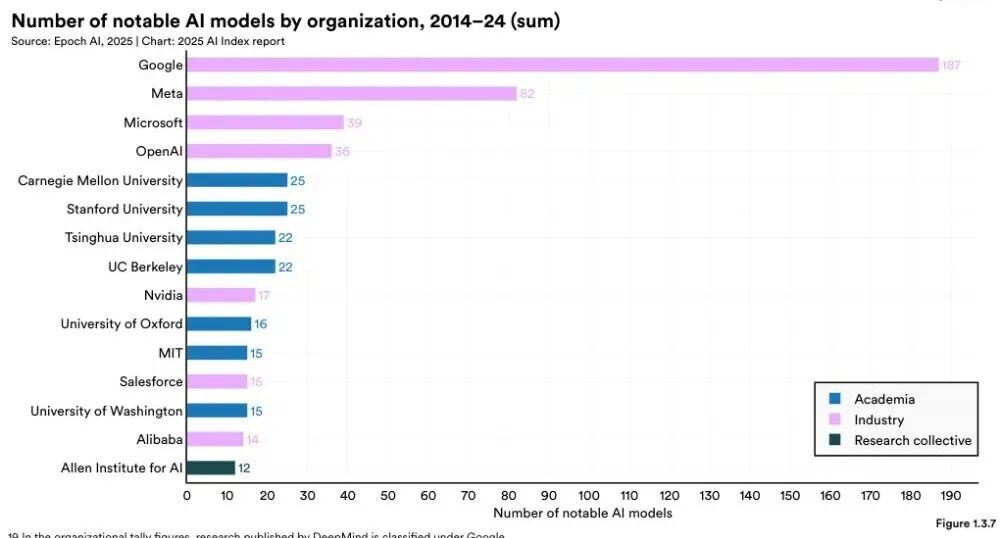
一、先从课堂里说起我相信很多人一开始会跟我有一样的相法:每个人都能几乎免费使用AI,使用它也不需要什么门槛,AI通过技术平权,缩小所有人的差距。但最近,我愈发觉得,在现实中,AI并没有带来技术平权,更没有导致能力平权。相反,它拉大了人们的差距。就在最近,在《Python的金融应用》这门课上,我给同学布置了一个作业:使用代码实现并分析给定的一个投资策略,再写一份完整的策略报告。而且我明确鼓励大家使用 AI。我原本以为,AI 会让结果更平均一些。毕竟它能帮大家查资料、改代码、写报告,理论上应该能把一些知识和能力差距抹平。但作业交上来之后,我看到的不是差距缩小,而是差距被拉得更开。有些同学借助 AI,做出了明显更完整更优秀的作品。但还有一些同学,表面上也用了 AI,结果却比不用还差。他们做的事情很简单:把老师的作业要求一股脑丢给 AI,然后等着 AI 直接吐答案。最后交上来的东西,哪怕堆砌了不少文字,但一细看,漏洞百出。这件事让我意识到,AI 并没有天然带来所谓的技术平权。它当然降低了一部分门槛。但它降低的是“开口问一句”的门槛,不是“把事情做好”的门槛。二、为什么很多人会误以为 AI 在平权很多人会下意识反驳:不对啊,AI 明明让更多人能写代码、做图、写报告了,这不就是平权吗。这个判断只看到了表面的一层。如果把“技术平权”理解成“以前做不了的人,现在能勉强做点东西了”,那 AI 当然算是在降门槛。但如果把“平权”理解成“不同背景的人,最后能获得更接近的结果、机会和收益”,那现实常常不是这样。因为 AI 不是把所有人的能力一起抬高。它更像是把人与人之间本来就存在的差异,换了一种方式重新放大。以前的差距,表现在写作能力、搜索能力、代码能力、表达能力里。现在的差距,开始转移到提问能力、判断能力、任务拆解能力、workflow(工作流)设计能力、以及对结果的校验能力里。也就是说,门槛并没有消失。所以,AI 最容易制造的一种幻觉,就是让人以为“人人都能用,所以差距会变小”。可真正决定差距的,从来不是“有没有资格打开工具”,而是“你能不能把工具变成你的生产力”。这一点,在课堂上很明显,在职场里会更明显。所以我更愿意把 AI 理解成一种重新分配优势的技术。它不是自动平权器,它是一台分化器。三、再来看看专业观点如果这还只是我个人课堂上的感受,那它最多算经验判断。我去找了下现有研究和新闻报道,看看其他学者或大拿是如何看待这件事。国际货币基金组织(IMF)在 2025 年 1 月的中文博客里写道:人工智能可能会扩大不平等。在亚洲发达经济体里,更多岗位既暴露在 AI 面前,又能被 AI 补强。而在新兴市场和发展中经济体,这类“能被补强”的岗位比例更低。图1 IMF:亚洲的发达经济体和女性劳动者面临更高的人工智能风险敞口换句话说,同样是一波 AI 浪潮,有些地方更容易把它变成生产率,有些地方更可能先承受冲击。这不是平权,这是分化。联合国贸发会议(UNCTAD)在《2025 年技术和创新报告》明确提醒,AI 的开发、资本、研发和基础设施,已经高度集中在少数国家和少数企业手里。当底层资源都集中时,后来者当然更难追上。图2 UNCTAD:科技巨头的市场主导地位图3 UNCTAD:研发高度集中于少数国家诺奖经济学奖得主达龙·阿西莫格鲁(Daron Acemoglu)也公开表达过类似担忧。他在 Nobel Prize 官网访谈里说,如果 AI 用错了方向,它会进一步加剧不平等,甚至推动一种“两层社会”的出现。还有一些论文,结论也并不乐观。IMF 的 2025 年工作论文《AI Adoption and Inequality》讨论了一个关键问题:即便 AI 在某些岗位上降低了技能溢价,只要企业之间的采用能力差异很大,财富不平等仍可能上升。一篇基于中国县域数据的实证研究则更直接,AI 发展会恶化收入差距,尤其会扩大城乡和区域差距。这和我们在现实中看到的现象其实很一致。谁先有基础设施,谁先有人才,谁先有钱,谁就先把 AI 变成新的优势。而没有这些条件的人,并不会因为会打开 AI就自动追平差距。AI 并不是天然走向平等的技术。它更像一种会沿着既有优势继续流动的技术。资源强的地方,吸收得更快。组织强的人,学得更快。判断强的人,产出更快。四、AI 真正拉大的,不是一种差距,而是五层差距那 AI 到底把哪些差距拉大了?我觉得至少有五层,而且是一层套着一层。第一层,是接入差距。很多人以为现在一个网页、一个 App 就算接入了 AI。但真正的接入,不只是能不能用,还包括模型质量、算力资源、付费能力、是否有更好的工具链、是否能接 API(应用程序接口)和自动化流程。表面上大家都在同一个聊天框里。实际上,背后的工具环境可能完全不一样。图4 Stanford AI Index:2024 年近 90% 的 notable AI models(重要模型)来自产业界图5 Stanford AI Index:过去十年,重要 AI 模型主要集中在少数头部机构第二层,是提问差距。这个就涉及到Prompt(提示词)能力,它能决定AI输出的质量。如何更好地向AI提问?我翻了几乎所有提示词手册后,写下这份提示词工程指南!context engineering(上下文工程)详细指南!第三层,是判断差距。AI 最大的问题不是不会说,而是太会说。所以它不仅会给你答案,但同时也会给你很多错误答案。一项重要的关键能力在于你是否具有鉴赏力,能不能识别它什么时候说的好,什么时候在胡说。当人人都会用AI,人与人的差距到底还在哪?第四层,是工作流差距。有的人只会打开网页或app和ai进行对话。这件事其实现在很多老年人都会做。有的人已经学会把 AI 用在选题、搜索、整理、草稿、修改、核对、复盘这一整套链条里。这时候差距就不是一句 prompt(提示词)的差距了,而是一整条 workflow(工作流)的差距。第五层,是组织差距。一个会用 AI 的个人很强。但一个会把 AI 嵌进制度、流程、分工和数据里的组织,会更强。也就是说,AI 最终放大的,往往不是单点技能,而是整个系统的组织能力。AI只是把差距从过去那种肉眼可见的“谁会不会写、谁懂不懂技术”,转移成了更隐蔽、也更难追赶的结构差距。五、为什么同样是用 AI,有人越用越强,有人越用越差回到学生和普通职场人的处境里,最值得警惕的是“你以为自己在使用 AI,其实只是把任务外包给了 AI”。真正越来越强的人,通常是能把 AI 放在一个正确位置上的人。他知道什么该交给 AI,什么一定要自己把关。他知道什么时候让 AI 出初稿,什么时候只让它做搜索,什么时候只让它帮忙挑刺。他不是把脑子交出去,而是把重复劳动交出去。反过来看,越容易被拉开的那一类人,往往也有几个共同点。第一,急着要答案,不急着搞清楚问题。第二,把 AI 输出当成结果,而不是当成待检查的中间件。第三,没有复核习惯,尤其不愿意回到原始材料里核对。第四,只会单轮提问,不会追问、重问、重构问题。第五,把“会用 AI”理解成“会让 AI 代劳”。这也是为什么很多人在 AI 时代,反而会掉进一种新的低水平勤奋。他看起来省了很多力气。可实际上,只是把原本需要自己慢慢消化的部分,用一段顺滑的话临时盖住了。这样的人,短期会觉得自己效率很高。但越到需要独立判断、独立负责、独立交付的时候,短板越明显。六、既然 AI 在拉大差距,我们就更该学会怎么不被甩开如果我们已经承认 AI 在拉大差距,那下一个问题就不是感叹,而是怎么办。我觉得对学生、老师和普通职场人来说,真正该学会的,是几项很具体的能力。第一,学任务拆解能力。不要一上来就问 AI:“帮我做完这个。”先学会把问题拆开:策略思路是什么,数据范围是什么,评价标准是什么,最后要交付什么。第二,学核验能力。AI 不是计算结果就一定真,也不是语句流畅就一定对。学会回到原始数据、原始文献、原始表格里做交叉验证,这是最核心的能力之一。第三,学表达能力。很多人以为自己不会用 AI,是因为不会技术。其实更常见的原因,是不会把自己的目标讲清楚。第四,学最基本的工具能力。学生至少要学会表格、文档、检索、版本管理、基础代码运行这些东西。因为没有这些基本技能,AI 给你的东西再多,你也不知道是否准确,是否能用。第五,学复盘能力。每次用完 AI,都问自己一句:这一步为什么有用,哪一步是我自己判断的,哪一步如果离开 AI 我就不会了。说到底,真正的应对办法是把 AI放在一个合适的位置。它应该是放大器,不是你的替身。它应该是助理,不是你的脑子。它应该帮你把时间省下来,用在判断、理解和创造上。参考资料来源1. 国际货币基金组织(IMF)博客:《人工智能将如何影响亚洲经济体》,2025年1月6日,https://www.imf.org/zh/Blogs/Articles/2025/01/05/how-artificial-intelligence-will-affect-asias-economies2. Rockall, Emma J.; Tavares, Marina Mendes; Pizzinelli, Carlo. AI Adoption and Inequality. IMF Working Paper 2025/068, 2025年4月4日,https://www.imf.org/en/publications/wp/issues/2025/04/04/ai-adoption-and-inequality-5657293. 联合国贸发会议(UNCTAD):《2025年技术和创新报告:包容性人工智能促进发展(概述)》,2025年4月7日,https://unctad.org/publication/technology-and-innovation-report-20254. 联合国日内瓦办事处:AI’s $4.8 trillion future: UN warns of widening digital divide without urgent action,2025年4月,https://www.ungeneva.org/en/news-media/news/2025/04/105032/ais-48-trillion-future-un-warns-widening-digital-divide-without5. Stanford HAI:The 2025 AI Index Report,2025年,https://hai.stanford.edu/ai-index/2025-ai-index-report6. Daron Acemoglu – Interview. NobelPrize.org,访谈录于2024年12月录制,网页更新于2026年,https://www.nobelprize.org/prizes/economic-sciences/2024/acemoglu/interview/7. Acemoglu, Daron; Johnson, Simon. Rebalancing AI. Finance & Development, IMF, 2023年12月,https://www.imf.org/en/publications/fandd/issues/2023/12/rebalancing-ai-acemoglu-johnson8. Kang, Chen; Li, Daiyue; Cheng, Mingwang. 人工智能、城乡收入差距与共同富裕,《系统工程理论与实践》,2025,45(10): 3168-3185,https://sysengi.cjoe.ac.cn/CN/10.12011/SETP2024-01019. Inequality in the digital economy: The impact of artificial intelligence on income gap – an empirical analysis based on county-level data from China. Cities, 2025,https://www.sciencedirect.com/science/article/pii/S026427512500581510. When AI Levels the Playing Field: Skill Homogenization, Asset Concentration, and Two Regimes of Inequality. arXiv:2603.05565,2026,https://arxiv.org/abs/2603.0556511. Generative Artificial Intelligence and the Knowledge Gap: Toward a New Form of Informational Inequality. arXiv:2603.24335,2026,https://arxiv.org/abs/2603.24335
 夜雨聆风
夜雨聆风