 夜雨聆风
夜雨聆风





AI-Native 软件工程(12):Collaboration Layer——多 Agent 协作真正的难题不是消息总线
上篇拆了知识层——半年就馊的那一层。知识被蒸馏出来之后,最终是要在某些 Agent 之间流动的。这一篇是这个系列的最后一篇,我想把过去 11 层都不太肯触碰的那个问题摊开讲——多个 Agent 在一个系统里同时干活时,到底在协作什么?什么是协作,什么只是并行?
剧透一下结论:大多数所谓的”多 Agent 协作”系统,其实是几个 Agent 各自为政——它们不是在协作,是在抢方向盘。
两个月前我帮一个团队评审他们做了三个月的 Agent 编排系统。架构图画得很漂亮:Planner Agent 拆任务、Coder Agent 写代码、Reviewer Agent 审查、Tester Agent 测试。中间一根粗管子写着”Message Bus”,旁边一行小字”统一上下文共享”。讲架构的工程师很自信——”我们做的是真正的多 Agent 协作”。
我看了一下 trace。
第一个发现:Reviewer Agent 在大多数任务上会推翻 Coder Agent 的设计,让 Coder 重写。重写之后 Reviewer 再来一遍,又找出新问题。一个简单任务在两个 Agent 之间能来回打八次,最后还得人介入。
第二个发现:Planner Agent 切完任务给 Coder,Coder 在实际写的时候发现 Planner 的拆解不对,自己又重新切了一遍。但 Coder 切完之后没把新的拆解结果回写给 Planner——Planner 在监控面板上看到的还是它自己最初的那版任务清单。两个 Agent 各自维护一份”事实”,互不相通。
第三个发现:Tester Agent 跑完测试有失败,它把失败结果写进了 trace,但没有任何机制决定谁该接锅。结果是 Coder 不知道要修,Planner 不知道要重新规划,Reviewer 不知道之前的审查需要复盘。失败就这么挂在那。直到一个真正的人类工程师上来手动指派”这个去找 Coder 修”,这条任务才动起来。
复盘的时候我跟那个团队说:你们做的不是协作。你们做的是把一个本来一个 Agent 串行能搞定的任务,强行切成四份让四个 Agent 串行,并且在每两个 Agent 之间还要走一道高昂的”对齐成本”。这套系统里每一次 handoff 都在重新拉一遍上下文,每一次审查都在用一个不确定的 Agent 去判另一个不确定 Agent 的产出,每一次失败都没有一个明确的人或角色出来兜底。看起来分工很细,实际上责任完全摊薄了。
他们立刻反问:那真正的多 Agent 协作应该长什么样?
这个问题我答不上来——我想了几个月,越想越觉得,问题本身被问错了。真正该问的不是”协作应该长什么样”,而是”什么时候不该协作”。先把不该协作的工作筛干净,剩下真的非协作不可的那一小撮,再去琢磨怎么协作。这个顺序如果搞反了,整个系统从第一天起就在错的赛道上加速。
协作不是并行,也不是分工
我先把”协作”这个词拆开。日常语境里它被严重过度使用,跟”并行”、”分工”、”流水线”经常被混着说。
并行是同一类工作被切成 N 份,各干各的,最后聚合。MapReduce 是并行的极致形态。并行不需要 Agent 之间交流——每个 worker 只需要知道自己那份。两个 Agent 同时审查同一段代码的两个不同部分,这是并行,不是协作。
分工是不同类工作被分到不同角色,各自负责自己擅长的那一段。流水线是分工的典型。分工要求每个角色的输入输出契约清晰——上游产出符合契约的东西丢给下游,下游不需要回头追问。Planner 写好规划交给 Coder 执行,如果规划完全够用、Coder 完全不用反过来跟 Planner 商量,这就是纯分工。
协作是真正”无法事先把责任切干净”的那一类工作。两个 Agent 必须在过程中持续交换信息、相互调整、共同收敛到一个结果。协作有一个并行和分工都没有的特性——中间状态是涌现的,不是预设的。你不知道下一个动作该谁来做,只能根据当前共同上下文动态决定。
这三件事在工程上的代价差着数量级。并行最便宜,只要切得均匀就行。分工次之,关键在于契约设计。协作最贵——它要求两个 Agent 共享一份不断变化的上下文、要求决策权能够动态转移、要求冲突时有一个收敛规则。
很多团队的”多 Agent 协作”系统,其实把 80% 的本可以走分工的任务,硬塞进了协作管道。结果就是花着协作的成本,做着分工的事,效果还不如一个 Agent 串起来跑。
我现在判断一个多 Agent 系统是不是设计合理,第一道关就是:你这里面有多少是真正必须协作的部分,有多少是被你强行放进协作管道的分工部分?
绝大多数答案是:90% 以上都是分工伪装成协作。把这 90% 还原成分工,系统会立刻变快、变稳、变便宜。
信任边界:协作系统真正的设计核心
真正必须协作的那 10%,问题也不在消息怎么传。消息总线、A2A 协议、blackboard——这些都是技术细节。协作系统的设计核心是另一个问题:什么决策可以让另一个 Agent 替你做?
这个问题是信任边界问题。
我们做了几十年的微服务架构,信任边界问题其实早就有成熟解法——API 契约、服务等级协议、调用方鉴权、流量隔离。一个服务调用另一个服务,调用方信任的不是被调用方本身,而是契约——”你声明了这个接口在 P99 100ms 返回 JSON,我就照这个用”。出了问题归契约约束方负责。
多 Agent 协作里这套不太成立。原因有三。
第一,Agent 的输出不是确定性的。同样的输入,今天给出方案 A,明天给出方案 B,两个都不算违反契约——LLM 本来就是概率模型。微服务时代的契约假设”接口稳定”——稳定到测试通过就能上线。Agent 的”接口”是输出某个判断,而判断本身就有分布。
第二,协作中的决策权是动态的。微服务调用关系是单向的——A 调 B,B 不会反过来给 A 下决策。Agent 之间不是。Reviewer Agent 给 Coder Agent 提建议,Coder 可能接受可能反驳,反驳之后 Reviewer 可能升级到更强的论据,也可能让步。决策权在协作过程中来回切换,没有固定的”调用方/被调用方”。
第三,协作的失败模式不可观测。微服务调用失败有明确信号——超时、500、契约校验失败。两个 Agent 协作出错的典型形态是”它们达成了一致,但这个一致是错的”——两个 Agent 都没有警觉地接受了对方的判断,谁也没去 challenge,最后输出一个共同认可的、错误的结果。这种”双向共谋”在没有人盯着的情况下,可能跑很久才被发现。
所以多 Agent 协作里需要的不是更强的消息总线,是更明确的信任边界。我自己在用的几条规则:
第一条:写操作权限的不对称。同一个共享上下文,谁能写、谁只能读,必须显式声明。两个 Agent 都能写同一份共享上下文是 90% 协作灾难的源头——它们会互相覆盖对方的中间结论,谁也搞不清”现在事实是什么”。
第二条:怀疑权限的对等。任何一个 Agent 都可以质疑另一个 Agent 的输出,这条权利不能被层级关系压住。Reviewer 当然可以质疑 Coder,但反过来 Coder 必须能质疑 Reviewer——因为 Reviewer 的判断也是概率分布。如果质疑权不对等,协作系统就会退化成单向霸权,被霸权 Agent 的偏差会主导整个系统的产出。
第三条:决策权的兜底归属。每一类决策必须有一个明确的”最终负责人”——可以是某个 Agent,也可以是人,但不能是”集体决议”。集体决议在 Agent 之间几乎一定会陷入无限循环——A 提议、B 反对、A 修改、B 又反对。必须有一个角色对某类决策有终止权——”到我这里,结论定了,下面执行”。
这三条规则一拼出来你会发现,它们跟好的人类团队管理几乎是同构的——清晰的写权限、人人可以挑刺、关键决策有最终决策人。区别是 Agent 之间需要把这些规则显式编码,因为 Agent 没有职场常识可以补全这些隐性规则。

共享上下文:协作中最贵的资源
协作的物质基础是共享上下文。两个 Agent 必须能看见同一份”事实”才有协作可言。但共享上下文的工程代价,比大多数团队预估的高得多。
我见过几种典型的失败设计。
第一种是”全量共享”。所有 Agent 共用一个大 context,谁都能读全部历史。看起来民主、透明、信息无衰减。实际跑起来,每个 Agent 决策时都要在几万 token 的共享上下文里翻找——成本爆炸不说,相关性还差。每个 Agent 真正需要看的只是其中 5% 的部分,剩下 95% 是干扰。
第二种是”视图分离 + 后期合并”。每个 Agent 维护自己的局部上下文,定期”同步合并”。听起来更经济,但同步点的设计是个坑——同步太频繁等于没有分离,同步太稀疏会导致漂移。两个 Agent 在两次同步之间各自基于过期信息做了决策,等同步时已经互相不兼容了。
第三种是”事件溯源式”。所有 Agent 的动作以事件流形式追加到一个日志里,任何 Agent 需要重建上下文时回放这条日志。这套设计在分布式系统里有成熟先例,理论上很优雅。但它假设 LLM 能像传统系统一样从事件流中重建出准确的当前状态——这个假设在长事件流上不太成立,LLM 在重建过程中会丢失或扭曲一部分事件的语义。
我现在的做法是更朴素的”任务级共享 + 角色级私有 + 显式 handoff“。
任务级共享池里只放跟当前任务直接相关的事实——目标、约束、当前状态、已尝试过的方案。这个池子刻意保持小,所有 Agent 都能读,但只有”任务负责人”(可能是 Planner 角色)能写。
角色级私有上下文是每个 Agent 自己的工作记忆——它的思考过程、调试痕迹、对中间结果的怀疑。这部分不共享。这件事很反直觉——很多人觉得”思考过程也应该可见才透明”,但事实是把所有 Agent 的内心戏混在一起,比任何外部噪声都更严重地污染决策。
显式 handoff 是协作中的关键动作——一个 Agent 主动把”接力棒”交给另一个 Agent。Handoff 不只是消息传递,它有四个必填字段:当前状态摘要、本次贡献了什么、未解决的问题、建议下一步谁来做。没有这个结构的 handoff 等于没交接,接手的 Agent 还得自己从一堆原始 trace 里复盘。
这套设计的代价是 handoff 时刻必须显式建模——你不能让 Agent “自然地”流转,因为它们没有职场默契。但好处是协作过程的可观测性极高,出问题能精准定位到某次 handoff 的某个字段缺失。
协作的五种失败模式
把信任边界和共享上下文都设计对了,协作系统还有一类特殊故障——它们不是某个 Agent 出错,是 Agent 之间的交互模式本身病了。我大致归了五种。
第一种是相互等待。Agent A 等 Agent B 给出方案,Agent B 在等 Agent A 给出约束。两个都在被动状态,谁都不主动出招。这种死锁在 LLM 系统里特别隐蔽——它不像传统线程死锁有进程卡住的明显信号,Agent 还在”思考”,只是思考的内容是空转。应对方式是给每个 Agent 加一个”必须主动产出”的下限——超过 N 轮没有具体推进就强制对话升级。
第二种是责任弥散。任务交给一个 Agent 群,最后没有任何一个 Agent 认为自己该完整地交付。每个 Agent 都做了”自己那部分”,缝隙处没人补。这是典型的多人协作病在多 Agent 上重演。解法跟人类团队一样——指派明确的 owner,owner 对全局结果负责,可以拉别人来帮忙但不能甩锅。
第三种是级联回退。Agent A 给的方案过不了 Reviewer Agent,A 退一步换新方案;新方案过不了 Tester Agent,A 再退一步;再退又过不了别的 Agent……Agent A 最后被反复打回到一个谁都接受但功能性最弱的”最低公约数”方案。整体协作系统输出了一个垃圾结果,而每一步都”通过了审查”。这种故障的根源是各个审查 Agent 之间彼此不可见——Reviewer 不知道 Tester 之前提了什么意见、不知道 Coder 已经退到第几版了。应对手段是审查类 Agent 之间也要共享”审查历史”,避免 Coder 被推到死胡同。
第四种是上下文漂移。两个 Agent 协作过程中,对”我们在解决什么问题”的理解逐步偏离。一开始都同意”修一个登录 bug”,几轮交互之后一个 Agent 觉得在”重写认证模块”,另一个还以为是”打个补丁”。两个 Agent 的输出都符合各自的理解,但加起来不构成一个连贯的产出。应对方式是周期性的”目标对齐”——每隔 N 步强制两个 Agent 重新确认当前任务目标的一致性,发现分歧立即升级。
第五种是上下文污染。一个 Agent 的局部错误经由共享上下文传染给所有协作方。Agent A 错误地把”用户已登录”写进了任务状态,所有依赖这个状态的 Agent 都基于错误前提做决策。这种故障最难修——错误已经成了”共同事实”,被多个 Agent 一遍遍引用强化。应对手段是给共享状态打可信度标签——谁写的、什么时候写的、基于什么证据写的。后续 Agent 引用时如果发现支撑证据已经过期或被反例覆盖,能主动质疑而不是无条件接受。
这五种故障,没有一个能用”加更好的消息总线”解决。它们都是协作语义层面的问题——你需要建立一套关于”谁负责什么、谁可以质疑谁、什么时候必须重对齐”的规则,并且把这些规则编码到系统里。这件事的工作量,在我看来不比写另一个 Agent 小。
我自己踩过的教训是:协作系统上线的前三个月,绝对不会暴露这五种故障中的任何一种——因为系统还小、任务还简单、并发还低。真正的问题集中爆发在第四到第六个月——任务量上来了、并发任务多了、Agent 角色多了,五种故障开始两两叠加、三三叠加。等你发现的时候,trace 已经乱到没法回溯,只能整体重构。所以协作系统的设计必须从第一天就把这五种故障的应对机制做进去,而不是等出问题再补——补不上的。
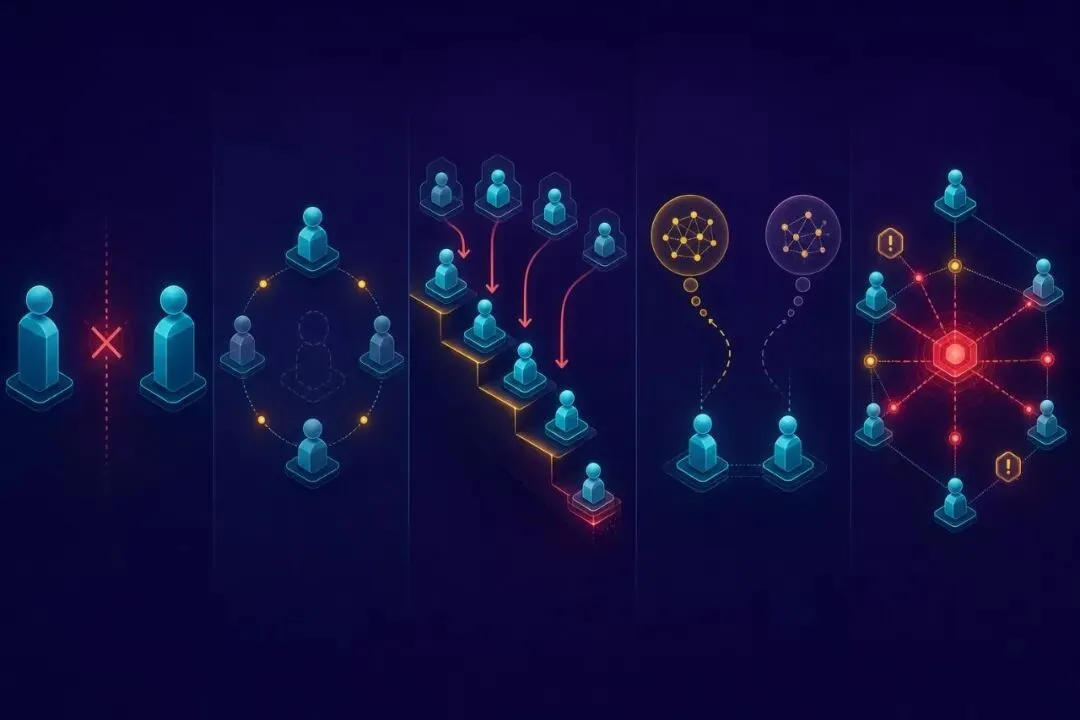
人和 Agent 同时操作时
到现在为止讲的都是 Agent 之间的协作。但 AI-Native SE 里真正难的,是人和 Agent 同时操作一个系统——这件事比纯多 Agent 协作还要复杂一层。
人和 Agent 协作有几个独特的特性。
人的速度比 Agent 慢两到三个数量级,但人的判断质量在某些维度上高一个数量级。这意味着不能让人去做”批量审查”——人审 50 条会越审越敷衍。应该把人放在少数几个真正高风险的决策点上,让人深度参与那几个点,其他全交给 Agent。
人的上下文跟 Agent 完全不在一个频道。人脑里有大量没法写进 prompt 的隐性知识——”上周开会决定了那个不能动”、”那个客户最近不好惹”、”那段代码是某某写的他下周休假”。Agent 不知道这些,但人不会主动把这些都说出来。结果是人接管时常常凭直觉做了一个决定,Agent 接下来按字面继承这个决定,但根本不知道决定背后的真正原因。
最棘手的是所有权交接。人在一个任务里干了一半交给 Agent,或者反过来 Agent 干了一半交给人——这个交接点需要被显式处理。完全不交接(默认所有权停留)会导致互相等待。完全公开交接(所有上下文倾倒)会让接手方淹没在信息里。
我现在的做法跟前面讲的 Agent 之间的 handoff 类似——人和 Agent 之间的 handoff 也要显式建模,但增加一个额外字段:“人需要知道但 Agent 不需要知道的事” 和 “Agent 知道但人懒得看的事”。前者放进交给人的接力棒里,后者帮 Agent 压缩成摘要。
还有一件事容易被忽略——人在协作循环里的位置不该是固定的。早期任务、风险高的任务、判断密集的任务,人靠前;流程化任务、低风险任务、可逆操作,人靠后甚至彻底不参与。让人灵活进出协作循环,而不是钉死在某一步——这是人机协作设计上的核心自由度。
协作的”契约”长什么样
最后回到那个开头被反问的问题——真正的多 Agent 协作应该长什么样?
经过这一年多的折腾,我现在的判断是:多 Agent 协作的核心产物,不是更聪明的 Agent,而是一份”协作契约”。这份契约定义了系统里每个角色的写权限、读权限、质疑权、决策权、handoff 协议、冲突收敛规则、人介入的触发条件。
写人类微服务时我们有 OpenAPI、有 gRPC proto。这些工具描述”接口的形状”。多 Agent 协作需要的契约比这层更厚——它还得描述”角色的边界”、”决策的归属”、”分歧的收敛路径”。这套语言现在还在演化中——A2A 协议、AgentFile 规范、MCP 都是这个方向的一部分尝试,但还没有任何一个达到”OpenAPI 之于微服务”那种地位的成熟度。
我现在做协作系统的实际产出物,是一份显式的协作契约文档——比代码还重要。每个 Agent 启动时把这份契约塞进 system prompt 的开头几行,让它先理解”我在这个协作系统里是什么角色、能做什么、不能做什么”。这件事看似简单,效果不可思议——同样的几个 Agent,加这份契约前后,协作质量差距比换模型还大。
协作契约不是为了让 Agent 互相礼貌,是为了把那 90% 不必要的”准协作”压回分工管道,把真正需要协作的 10% 圈进一个受控的小区域。这是协作层最重要的一件事——用契约把协作的边界画清楚,让大部分工作都不需要协作。
十二层走完了,回头看一遍
到这里,AI-Native SE 这个系列覆盖的 12 层就拼齐了。我用一段话回顾一遍这条主线。
Intent Layer(#6)说明了为什么起点是意图而不是代码——AI-Native 系统的第一公民是结构化的意图,而不是字符。Planner Layer(#7)讲规划能力为什么是必须的——任务从意图到执行之间需要一道显式的分解。Verify Layer(#8)说为什么生成的东西必须先被验证——LLM 的输出是概率分布,没验证等于没产出。Execute Layer(#9)讲代码在哪跑、怎么跑安全——隔离不是开关是光谱。Feedback Layer(#10)讲反馈不是采集,是认知——信号和噪声必须区分。Knowledge Layer(#11)讲知识不是文档——它有半衰期,会腐烂,需要持续修剪。Collaboration Layer(#12,本篇)讲多 Agent 协作的核心是信任边界——不是消息总线。
这十二层加在一起,是一套关于”AI 如何成为软件工程基础设施”的工程视角。它的反面,是把 AI 当成”另一个调用 API 的中间件”——这种视角不会错,但拿不到 AI-Native 真正的杠杆。
把这十二层都拼起来之后,下一步该往哪走?我不准备给标准答案——每个团队的现实约束都不一样。但有几个方向值得继续往深里挖:把这十二层用同一个具体业务场景跑一遍端到端、在生产环境观察这套架构的真实瓶颈在哪、把组织里的隐性知识系统性地灌进知识层、把协作契约从”文档”演化成”可执行的规则系统”。这些都是接下来一两年值得花力气的方向。
这个系列写完,不代表 AI-Native SE 这个赛道讲完了——恰恰相反,把这十二层拼齐才是起点。地基有了,上面盖什么楼,是更难、更值得做的题。后续会换一个角度继续——可能是某一层的深度复盘,可能是某个具体场景的端到端拆解,也可能是把这套体系跟传统软件工程做一次正面的对比。
但今天就到这里。一个体系的完整呈现需要在某个点停下来,让读者有机会把它当成一张完整的地图看一眼,而不是一直被新章节追着跑。
知识层不让 Agent 复制旧的错误。反馈层不让 Agent 在噪声里变蠢。协作层不让多个 Agent 互相消耗。三句话放在一起,差不多就是这个系列想留下的东西。