 夜雨聆风
夜雨聆风





没文档、没注释、前人跑路,老代码终于有地图了

刚接手一个老项目的时候,最难的地方,往往不是写代码。
是你根本不知道从哪里开始看。
比如说,一个二十多万行的项目丢到你面前,目录很多,模块很多,函数名看起来都像有道理,但就是没有一条线能把它们串起来。
文档没有。
注释很少。
前面的人也不在了。
组长只说了一句,下周开始接需求。
这个时候,大家心里大概都会有点发虚。不是说我们不会写代码,而是说,项目的上下文全断了。你不知道入口在哪里,不知道哪些模块是核心,不知道某个函数被谁调用,也不知道改一处地方会不会影响另外十几个地方。
所以今天想聊的这个工具,重点不是它有多酷,而是它解决了一个很具体的问题。
它叫 Understand-Anything。
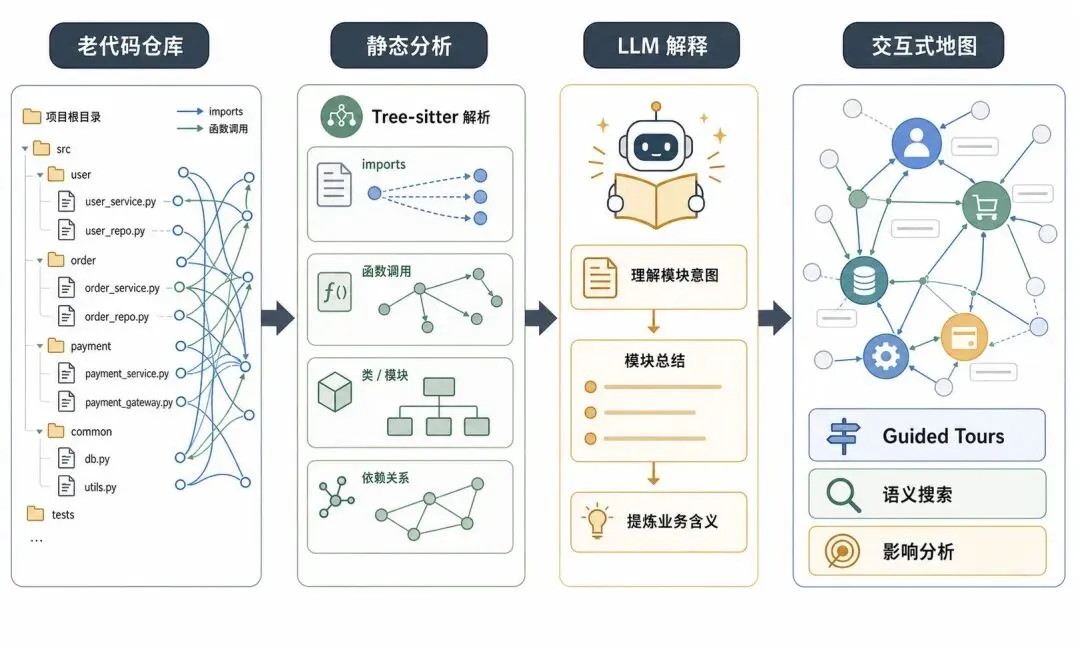
简单讲,它就是帮你把一个代码库整理成一张可以交互的地图。
为什么老项目这么难接
我们先把问题说清楚。
新项目难,通常难在设计。你要想清楚架构,想清楚边界,想清楚怎么把需求做出来。
老项目难,很多时候难在理解。
代码已经在那里了,业务也已经跑了很多年。它不是没有逻辑,而是逻辑散在各个地方。一个订单状态,可能牵着支付、库存、消息通知、权限校验。你看其中一个文件,好像懂了。再往下一追,发现后面还有一串。
这个地方最痛苦的是,你很难判断自己到底看到了全貌,还是只看到了局部。
很多人会用全局搜索。
比如搜 auth,搜 payment,搜 order。
当然了,这个方法肯定有用。但问题是,结果太多以后,你还是要靠自己一个一个点进去判断。
你看得越久,越容易进入一种状态,眼睛在读代码,脑子已经开始糊了。
所以更好的方式,不是只给你更多搜索结果,而是给你一个结构。
就是说,我们需要的不是一堆零散线索,而是一张能看出关系的图。
Understand-Anything 在做什么
Understand-Anything 做的事情,可以分成两层来看。
第一层,是把代码里的硬关系抓出来。
比如文件之间怎么 import,函数之间怎么调用,类和类之间有没有继承,模块之间有没有依赖。
这些东西不适合让大模型瞎猜。它需要比较确定的解析方式。所以这个项目用了 Tree-sitter 这一类静态分析工具,先把语法结构扒出来。
大家可以把它理解成,先把房子的梁、柱子、墙的位置画出来。
这一步很重要。
因为如果底层结构不准,后面所有解释都会飘。
第二层,是让大模型去补那些更像人话的理解。
比如这个模块大概负责什么,这一组文件可能属于哪个业务区域,某条调用链背后对应什么功能。
静态分析能告诉你 A 调用了 B,但它不一定能告诉你,这一段代码其实是在处理用户登录后的权限判断。
这个地方,大模型就有用。
所以它不是单纯画图,也不是单纯让 AI 读代码。它是把静态分析和 LLM 放在一起用。
一个负责骨架,一个负责解释。
这张地图能怎么用
好,我们来看实际使用场景。
最直接的一个,是 Guided Tours。
这个名字听起来有点像景区导览,其实放在代码库里还挺贴切。
刚进一个项目,你最缺的就是有人告诉你,先看哪里,后看哪里。哪些模块是底座,哪些模块是上层业务,哪些文件只是辅助工具。
Guided Tours 大概就是做这件事。
它会根据依赖关系,给你排一条理解路线。你跟着这条路线走一遍,至少能先把项目骨架摸出来。
这个地方特别适合新人。
因为新人最怕的不是慢,而是乱。
只要知道从哪里开始,后面很多事情就能一点点接上。
再一个,是语义搜索。
普通搜索要求你先知道关键词。
比如你要找鉴权逻辑,你得知道代码里叫 auth,还是 permission,还是 access control。
但实际项目里,命名经常不统一。尤其是老项目,前后几批人写的风格都不一样。
语义搜索的好处是,你可以用更接近自然语言的方式去问。
比如,哪块代码在处理支付流水和权限校验。
它不是只返回一堆文本匹配结果,而是把相关节点和关系一起给你看。这样你看的是一片区域,不是一个孤零零的函数。
这个体验差别很大。
还有一个很实用的点,是 Impact Analysis。
也就是改代码之前,先看影响范围。
老项目最怕的就是这里。
你以为自己只是改了一个小函数,结果它下面连着好几条业务链。测试没覆盖到,上线之后才发现另一个地方行为变了。
如果图谱能提前把相关依赖和可能受影响的模块标出来,就能帮你做一次预判。
它当然不能替你承担责任,也不能保证百分百不出问题。
但至少它会提醒你,这个地方不是孤立的。
它适合放在哪些工作流里
我觉得它最适合三个场景。
第一个场景,是新人入组。
新人最需要的不是一上来就改需求,而是先建立地图感。这个项目有哪些主要模块,数据怎么流,核心调用链在哪里。
如果团队能提前把图谱生成出来,新人看项目会快很多。
第二个场景,是接手没人维护的老项目。
这种项目通常不是完全不能碰,而是大家都怕碰。
怕的原因也很简单,没人知道哪里是雷区。
这个时候,先用工具把依赖和调用关系扫出来,比直接硬改要稳很多。
第三个场景,是提 PR 之前做自查。
我们平时写完代码,习惯看 diff,跑测试。
这个当然要做。
但如果能再多一步,看一下这次改动在图谱里牵动了哪些节点,很多隐藏风险会更早暴露出来。
好,这个就很像体检。
不是说体检能解决所有问题,但它能让你少一点盲区。
这个工具的价值在哪里
我觉得 Understand-Anything 最有价值的地方,不是它用了多少 agent,也不是图谱做得多漂亮。
真正有价值的是,它把代码理解这件事,从靠个人经验硬扛,变成了一个可以沉淀的流程。
以前一个老员工懂项目,是因为他在里面待了很多年。
他知道哪个模块不能乱动,知道某个函数为什么写得很怪,知道一次改动会影响哪里。
但这些知识大部分都在脑子里。
人一走,知识就跟着走。
现在如果能把这些结构、关系、导览路径沉淀成图谱,哪怕它还不完美,也比什么都没有强很多。
更关键的是,这个图谱可以跟着项目一起保存。
也就是说,团队理解代码的过程,可以慢慢变成资产,而不是每个新人都从零开始撞墙。
最后说一下我的看法
这类工具不会让你一夜之间看懂所有代码。
大家不要对它有这种期待。
它更像是给你一张地图。
地图不会替你走路,但没有地图的时候,你会绕很多远路。
尤其是接手老项目的时候,真正消耗人的不是某个语法点,而是长期的不确定感。
这个函数能不能改。
这个模块谁在用。
这条调用链后面还有没有别的分支。
这些问题如果都靠人肉去追,效率很低,而且很累。
所以我觉得,Understand-Anything 这类工具真正代表的方向,是把 AI 放进工程理解环节里,而不是只让 AI 帮我们写代码。
写代码只是其中一部分。
看懂代码,评估影响,交接上下文,这些其实更重要。
下次再接手一个没文档、没注释、前人跑路的老项目,别急着硬啃。
先把地图开出来。
好,这一步做完,后面的需求才有地方落脚。
参考来源:
-
Understand-Anything GitHub 仓库:<https://github.com/Lum1104/Understand-Anything>
🔥 精选文章推荐
awesome-design-skills:让 AI 写前端时终于有一点设计品味
别再乱喂 Agent 了:Superpowers 把 coding agent 的开发流程做成了一套方法论