 夜雨聆风
夜雨聆风





百度面试官问:长文档抽取漏字段和瞎编,2 类错怎么分开处理?

百度 文档智能落地面真题
文档智能题 · 业务场景精选
抽取最危险的不是抽错,而是它编了一个看着合理的值。
这一课继续业务场景:长文档抽取漏字段和瞎编,2 类错怎么分开处理?“给个 prompt 让模型输出 JSON”只能拿 40 分;能把漏抽和编造当两类错分开治、还能回指原文,才到 90 分。这题考的不是抽取准不准,是你分不分得清”漏”和”编”这两种错。
先认 3 个词
字段抽取:从文档里把”违约金、签署日期”这类结构化信息抠出来填成表
漏抽:值明明在文档里,却没被抽到
编造:文档里根本没有,模型却填了一个看着合理的值
一、面试现场
面试官提问
“长文档抽取漏字段和瞎编,2 类错怎么分开处理?”
百度文档智能落地面。团队做了个合同审查助手,从几十上百页合同里抽”违约金、签署日期、付款周期”。
上线后业务反馈:有的字段明明在合同里却没抽到,有的字段合同里根本没有,模型却填了一个看着很合理的数。面试官追问:”长文档抽取漏字段和瞎编,2 类错怎么分开处理?”
这题实际在考你能不能区分”漏抽”和”编造”——前者是没找到,后者是凭空补,治法完全相反。
直接回答:漏抽是召回问题,编造是约束问题,分开治。
二、大多数人怎么答的
典型翻车回答
“给它一个 prompt 要它直接按 JSON 输出,字段有 schema 就能补齐;我当时没要求把“没找到”和“我猜的”分开标。”
这答案能拿 40 分——短文档、字段明显时,模型直出 JSON 确实能用。问题是它把漏和编当成同一个”准确率”问题。
漏字段和瞎编,难点在两处。
一是schema 要求填满,模型就会为了合规去猜——你给了 8 个字段,合同里只有 6 个,它会硬凑出另外 2 个,越”听话”越危险。
二是漏和编混在一起,QA 根本没法验收——一份输出里既有没抽到的、又有编出来的,人工核对时分不清哪个该补、哪个该删。
抽取的反面不是抽错,是它编了一个看起来很合理的值——这种错比漏抽隐蔽得多。
三、深度解析(两类错分开治 + 一条铁律)
漏和编是两种病,用一种药治不好。先把它们拆开,各治各的,再加一条可溯源铁律兜底。
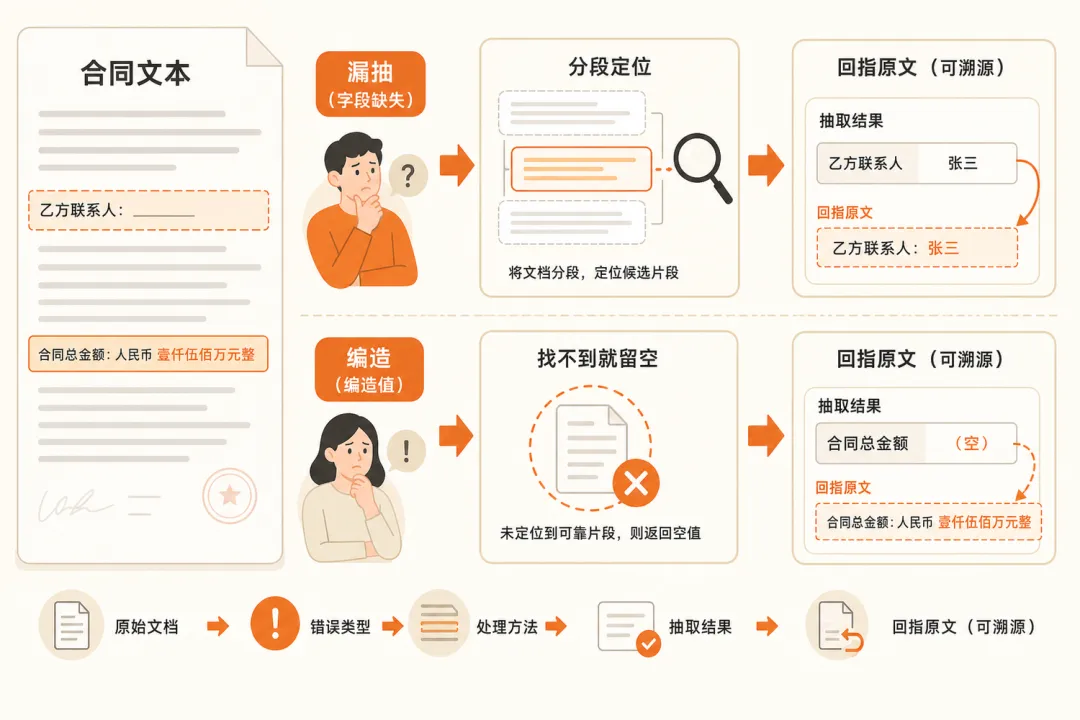
治漏抽 · 这是召回问题,靠定位
100 页、几万字的合同一次塞不进上下文,关键信息会被切段切丢。
先分段定位——对每个目标字段先找到候选段落,再按章节、按关键词两路抽取交叉。漏抽的根因是没定位到,不是模型不会读,所以药在召回,不在 prompt。
治编造 · 这是约束问题,靠禁猜
别让模型为了填满 JSON 去猜:字段级强约束,文档中没有就返回空 / 未提及。给模型一个合法的”不知道”出口,它才不会硬编。关键在于:宁可留空让人补,也不要让模型猜一个数字。
铁律 · 每个值都要能回指原文
不能回指原文的值,QA 没法验收。抽到的每个值都带上原文出处(页码 + 片段),QA 一眼能核对到合同那一句,而不是盲信一份 JSON。
不可溯源的抽取没法验收——你根本不知道这个值是抽来的还是编来的。
抽取系统的及格线不是准确率高,是”错了能被发现”;找不到 evidence 的字段不应该硬填。
顺序很清楚:先给模型留”未提及”出口防编造,再用分段定位补召回防漏抽,最后用可溯源让每个值都能核对。一个编出来、却没人能发现的违约金,比漏抽 3 个字段危险得多。
四、面试官追问链
追问 1
“怎么区分’文档里确实没有这个字段’和’模型没找到’?”
关键是让模型显式表态,而不是默默填一个值:
① 强制 found 标记——每个字段输出 {value, found, evidence},没找到 found=false
② no-evidence 即留空——给不出原文出处的值,一律当未找到
③ 定位兜底——再换一路分段定位扫一遍,确认是真没有
没有 evidence 的’有’,就当’没找到’——这是分开漏和编的关键。
追问 2
“抽取结果怎么做到可溯源,让 QA 能逐字段核对?”
每个值都挂上能跳回原文的坐标,三件事:
① 带 evidence——每个值附 {value, source_span, page},标清第几页哪一句
② 置信度分流——低置信字段进人工复核队列,不直接发
③ 原文高亮——核对时一键跳到合同那句,QA 不用全文翻
不能回指原文的抽取值,等于没法验收。
追问 3
“文档超出上下文长度时怎么分段,才不丢跨段的关键信息?”
按结构切、留重叠、关键字段多路兜底:
① 按章节结构切——顺着条款、章节边界切,别拦腰切断一个条款
② 段间留重叠——相邻段重叠一部分,防跨段的值正好被切在边界
③ 关键字段两路抽——按章节、按关键词各扫一遍,结果交叉
跨段信息丢失是漏抽的头号原因,切法比 prompt 更值得花时间。
五、落地案例:又漏又编的合同审查助手
回到开头那个合同审查助手,既漏字段又编数。把漏和编拆开各治,QA 终于能逐字段验收。
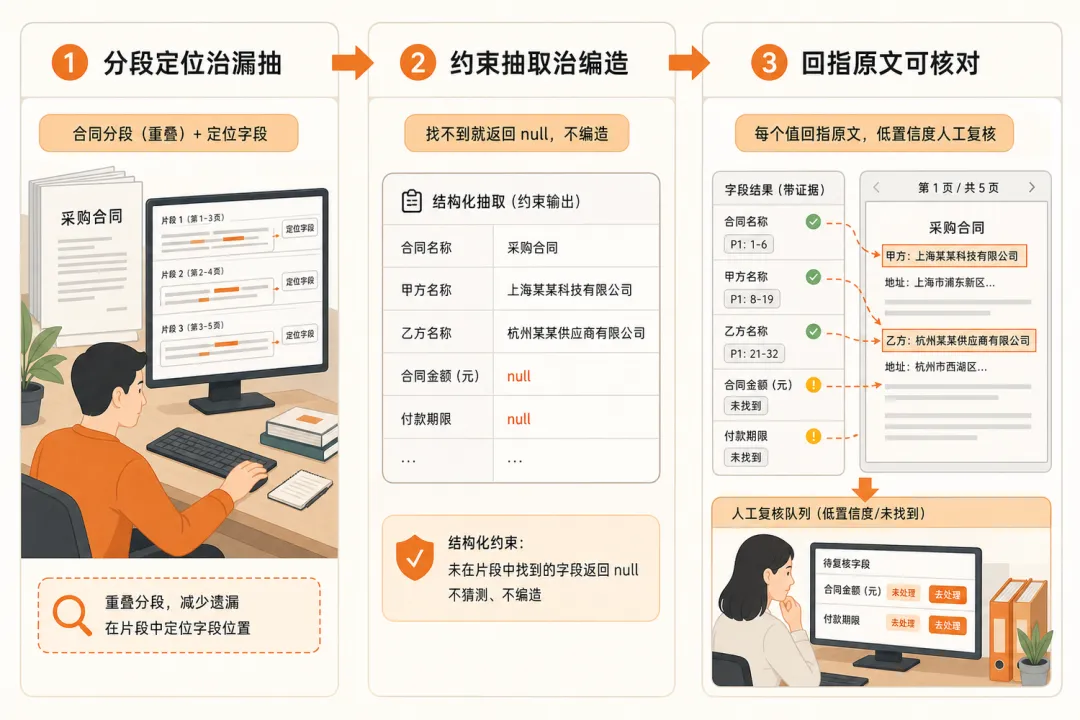
STEP 1 · 分段定位治漏抽
合同按条款结构切段、段间留重叠,每个字段先定位候选段,再按章节 + 关键词两路抽取。
↳ 结果:跨段被切断的违约金、付款周期,重新被定位到。
STEP 2 · 约束抽取治编造
字段级 prompt 强制”未提及则返回 null + 置信度”,给模型合法的”不知道”出口。
↳ 结果:合同里没有的字段不再被硬编,留空等人补。
STEP 3 · 回指原文可核对
每个值输出 {value, found, evidence},带页码片段;低置信字段进人工复核队列。
↳ 结果:QA 逐字段一键跳原文核对,漏和编当场分得清。
↳ 复盘(匿名合同审查助手)
上线翻车不是模型读不懂合同,是漏和编被当成一个问题在调。
拆开后——分段定位补回漏掉的字段,禁猜约束让编造的值变成留空,每个值带 evidence 能回指原文,QA 第一次能逐字段验收。真正决定一个抽取系统能不能上的,不是抽得多准,而是错了能不能被人发现。
六、本课总结
一句话总结
漏抽和编造是两类错:漏抽是召回问题靠分段定位,编造是约束问题靠强制找不到就留空。每个值都要能回指原文,QA 才验收得了——宁可留空让人补,也别让模型猜一个看着合理的数。
面试锦囊
先反问:”是问怎么抽得准,还是问漏和编怎么分开治?”——点破漏抽和编造是两种病,不能一种药治。
再列两治一律:治漏抽(分段定位 + 多路抽取交叉)→ 治编造(字段级强制找不到返回 null)→ 可溯源铁律(每个值带 evidence 回指原文)。
最后补:”给模型合法的’未提及’出口,低置信进人工复核——宁可留空让人补,也不让它编一个看着合理的数。”
下一步建议先补 3 件事
① 每个字段都加 evidence:页码、段落 id、原文 span、置信度;没有 evidence 的值默认不进结果。
② 把错误分成两张表看:漏抽率看 recall,编造率看 unsupported value;两类错分开调,不混成一个准确率。
③ 先做字段级抽检:每批抽 30-50 份文档,逐字段核 evidence,低置信和空值优先给人工补。
下一课预告
下一课继续业务场景:AI 客服该交到哪一层、什么时候必须立刻转人工。
留个问题:你们的长文档抽取系统出错时,是把”漏字段”和”瞎编值”混在一个准确率里看,还是分成漏抽率 / unsupported value 两张表?每个字段能不能回指原文 evidence 给 QA 核对?