 夜雨聆风
夜雨聆风





大模型不只有网页上的:还有能下载到本地跑的
失踪人口回归啦!!!!这几天工作比较忙,文章断了几天。
本来想继续写 AI 编程工具,但想了一下,前面聊了不少 ChatGPT、DeepSeek、Claude Code、AI Agent,好像还有一个更基础的问题没讲清楚:
我们平时说的“大模型”,是不是只能打开网页才能用?
比如打开 ChatGPT,打开 DeepSeek,打开 Kimi,打开豆包,然后在聊天框里输入问题。
其实不是。
网页上的 AI 只是最常见的一种使用方式。
大模型除了“在线使用”,还有另一类很重要的形态:
有些模型是开放出来的,可以下载,可以部署,甚至可以放到自己的电脑上跑。
这篇就先不讲复杂论文,也不讲训练原理,用普通人的话,把几个概念说清楚:
什么是闭源模型?
什么是开源模型?
什么是开权重模型?
为什么有人要把大模型部署到本地?
一、我们平时用的,大多是云端模型
大部分人第一次接触 AI,都是从网页或者 App 开始的。
比如你打开一个 AI 聊天页面,输入一句话:
“帮我写一段文案。”
“帮我解释一下这段代码。”
“帮我总结一下这篇文章。”
它很快就返回答案。
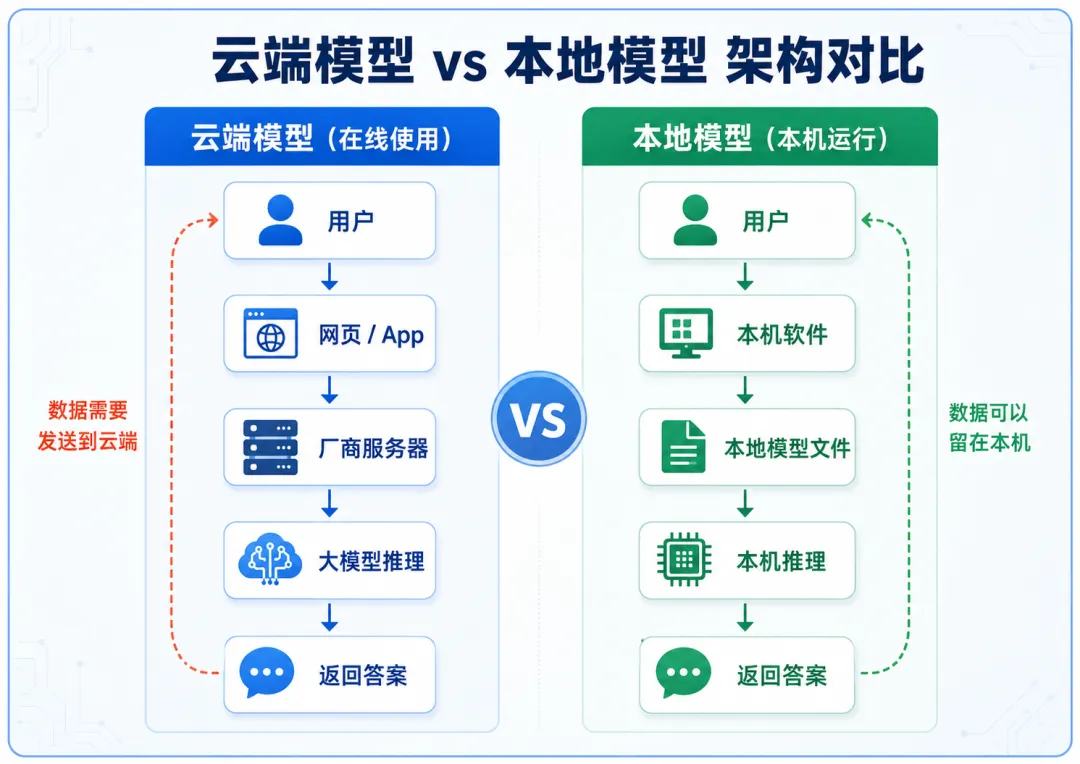
这个过程看起来像是在你的手机或电脑上完成的,但实际上,大部分计算并不在你的设备上。
更常见的流程是:
你输入问题
↓
问题发送到厂商服务器
↓
服务器上的大模型进行推理
↓
结果再返回到网页或 App
这就是我们平时最熟悉的“云端模型”。
它的优点很明显。
第一,方便。
不用安装环境,不用下载模型,不用关心显卡,不用关心内存。
打开网页就能用。
第二,效果通常比较强。
很多最强模型都在云端,背后有大厂的算力、工程优化和产品能力。
第三,功能完整。
现在很多云端 AI 不只是聊天,还能联网搜索、识别图片、分析文件、生成图片、写代码,甚至调用工具。
所以对普通人来说,云端模型是最省心的。
但它也有一个绕不开的问题:
你输入的内容,需要发到服务商那里处理。
问公开问题没什么。
比如:
“HTTP 是什么?”
“帮我写一段周报模板。”
“给我推荐几个学习英语的方法。”
这类内容发出去,一般问题不大。
但如果你把公司代码、合同、客户名单、数据库结构、接口密钥、内部文档直接丢进去,那就不是一个级别的问题了。
所以云端模型可以简单理解成一句话:
用起来最方便,但数据要出门。
二、什么是闭源模型?
闭源模型,简单说就是:
模型背后的核心东西不公开,你只能通过厂商提供的网页、App 或 API 来使用。
比如很多商业大模型,普通用户能用它的聊天能力,开发者能通过 API 调用它,但看不到完整模型权重,也不能把模型下载到自己电脑上运行。
这就像你去饭店吃饭。
你能点菜,也能评价好不好吃,但后厨配方、火候、原材料比例,你看不到。
闭源模型的优点是成熟、省心、能力强。
你不用管模型怎么部署,也不用管怎么优化。
厂商负责升级,厂商负责维护,厂商负责算力。
但它也有缺点。
你依赖平台。
价格怎么变,模型怎么升级,功能怎么调整,接口怎么限制,很多时候你说了不算。
今天这个模型好用,明天可能改版。
今天这个功能免费,明天可能收费。
今天接口能调,后面可能限流。
所以闭源模型更像是一种在线服务。
你可以使用它,但它不属于你。
三、什么是开源模型?
开源模型这个词,现在有点容易混。
很多人一听“开源”,就会以为它和普通开源软件一样:
代码公开,训练数据公开,训练方法公开,模型权重公开,大家都能自由修改。
但在大模型领域,情况没这么简单。
有些模型确实开放了很多东西。
有些模型只是开放了模型权重。
还有些模型开放了使用方式,但对商用、改造、再分发有限制。
所以更严谨一点,应该分成几类看。
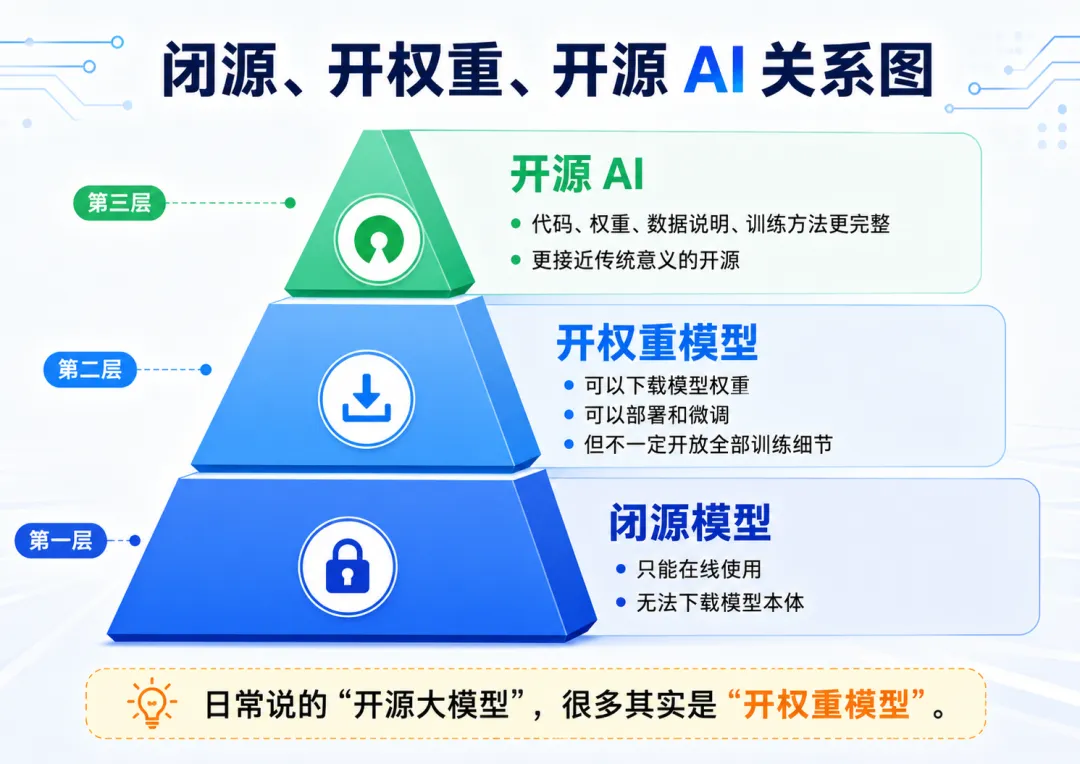
第一类:闭源模型。
你只能通过网页、App 或 API 用。
不能下载模型本体。
不能自己部署。
第二类:开权重模型。
模型权重开放出来了,你可以下载,可以部署,可以在本地或服务器上运行。
但它不一定公开完整训练数据,也不一定公开完整训练过程。
第三类:更完整意义上的开源 AI。
除了权重,还要尽可能提供代码、数据说明、训练方法,让别人真的能研究、修改、复现和再创造。
不过我们日常写科普,不用一上来讲得太学术。
你先记住一句话就够了:
很多大家口头说的“开源大模型”,其实更准确叫“开权重模型”。
也就是说,它至少把模型权重放出来了,别人可以下载和部署。
常见的开放模型包括:
Llama、Qwen、DeepSeek、Gemma、Mistral 等。
它们不一定都适合普通电脑完整运行,但很多都有小参数版本、量化版本、蒸馏版本,可以让普通用户体验本地运行。
四、开源模型和闭源模型到底差在哪?
我用一张表说清楚。
| 对比项 | 闭源模型 | 开源 / 开权重模型 |
|---|---|---|
| 使用方式 | 网页、App、API | 本地部署、服务器部署、私有化部署 |
| 能不能下载 | 通常不能 | 通常可以 |
| 使用门槛 | 低,打开就能用 | 中等,需要工具和配置 |
| 效果上限 | 通常更强、更稳定 | 看模型大小和硬件 |
| 数据隐私 | 数据要发到云端 | 可以不出本机 |
| 成本 | 会员费或 API 费用 | 本地不按次收费,但吃硬件 |
| 可控性 | 依赖平台 | 自己掌控更多 |
| 适合人群 | 普通用户、办公、创作 | 开发者、企业私有化、极客用户 |
这里不要走极端。
闭源模型不是不好。
开源模型也不是万能。
如果你只是日常问答、写文章、做 PPT、查资料,云端模型最省心。
但如果你在意数据隐私,想做本地知识库,想研究模型,想给公司做私有化部署,那开放模型就很有价值。
换句话说:
云端模型解决的是“我马上就要用”。
本地模型解决的是“我想自己掌控”。
五、为什么有人要把大模型放到本地跑?
很多人会问:
既然网页 AI 已经这么方便了,为什么还要折腾本地模型?
主要是三个原因。
第一个原因:隐私。
有些东西不适合发给云端 AI。
比如公司内部代码、客户资料、合同、财务数据、数据库结构、接口密钥、个人隐私文档。
如果模型能在本地运行,至少这些内容可以不离开自己的电脑。
这不是说本地模型就一定绝对安全,而是它给了你一个选择:
敏感资料,可以不出门。
第二个原因:成本。
如果你只是偶尔问几句,云端模型的成本不明显。
但如果你要批量处理很多内容,比如批量总结文档、分析日志、清洗数据、生成大量草稿,云端 API 成本就会慢慢上来。
本地模型运行起来后,不会每问一句都按 token 收费。
当然,它也不是完全免费。
它会占硬盘,会吃内存,会消耗电脑性能。
模型越大,对电脑配置要求越高。
所以本地模型不是没有成本,只是成本结构不一样。
第三个原因:可控。
云端模型是平台服务。
平台升级了,你跟着升级。
平台限制了,你跟着受限。
平台调整价格,你也只能接受。
本地模型更像自己装的软件。
用哪个模型,什么时候升级,数据放在哪里,接什么工具,都可以自己控制。
对普通用户来说,这可能没那么重要。
但对开发者、企业、极客用户来说,这一点很关键。
六、本地模型是不是一定比网页模型差?
不一定,但大多数情况下,强云端模型还是更稳。
尤其是复杂推理、长文写作、多模态理解、联网搜索、复杂代码工程,这些场景下,顶级闭源模型通常体验更好。
本地模型的优势不是“全面吊打”。
它的优势是:
隐私更可控。
成本更可控。
部署方式更灵活。
可以离线运行。
可以接自己的资料和工具。
所以你可以这样理解:
闭源云端模型像大厂提供的在线服务。
本地开放模型像你自己装在电脑里的工具。
一个追求省心和强能力。
一个追求隐私、控制和可折腾。
不是谁取代谁,而是使用场景不一样。
七、普通人到底该怎么选?
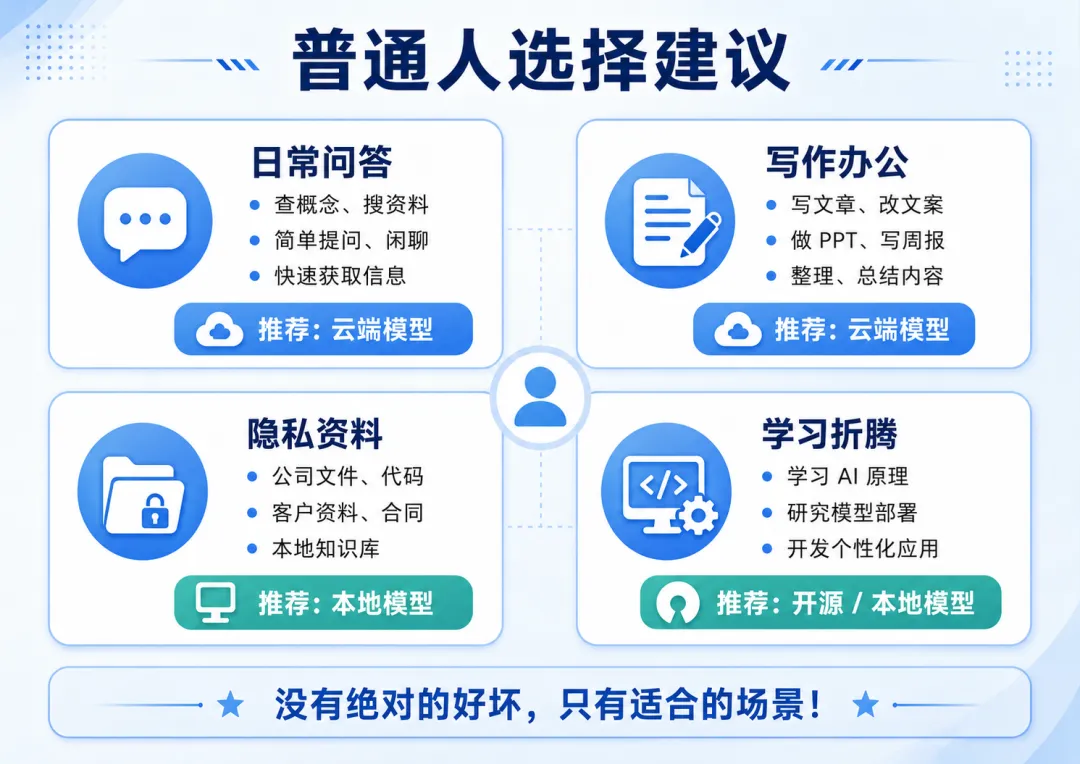
如果你只是日常使用 AI,我建议很简单:
写文章、改文案、查概念、做总结:
优先用云端模型,省心。
复杂推理、写代码、分析大文件:
优先用能力强的在线模型。
公司资料、隐私文档、本地知识库:
可以考虑本地模型。
想学习 AI、折腾工具、研究模型部署:
一定要了解开源模型和本地部署。
不要一上来就追求“全部本地化”。
很多人第一次听本地模型,很容易冲动下载一个几十 GB 的大模型,结果跑不动,电脑风扇狂转,体验很差。
正确路线应该是:
先理解概念。
再选轻量工具。
先跑小模型。
最后再考虑更复杂的部署。
下一篇我会直接写实操:
手把手教你在电脑上跑一个本地大模型。
不讲训练,不买服务器,不搞复杂环境。
就从普通人能用的工具开始,比如 LM Studio 和 Ollama。
八、最后总结一下
大模型不只有网页上的聊天框。
网页上的,是云端模型。
能下载部署的,是开放模型或开权重模型。
能在自己电脑上运行的,就是本地模型。
它们不是互相替代的关系,而是不同的使用方式。
云端模型适合省心使用。
本地模型适合隐私、可控和折腾。
普通人可以暂时不部署本地大模型,但至少要知道:
AI 不只有一种形态。
它可以在云端,也可以在本地。
可以是厂商服务,也可以是自己电脑里的模型文件。
知道这一点,再看后面的 AI 工具、本地知识库、企业私有化、AI Agent,就会清楚很多。