 夜雨聆风
夜雨聆风





多模态文档解析开源新进展:Unlimited OCR技术方案
这次介绍的技术方案架构是站在前期《多模态文档解析开源新进展-DeepSeek-OCR2.0架构、数据、训练方法》所介绍的DeepSeek-OCR的改进,主要引入了【R-SWA(Reference Sliding Window Attention,参考滑动窗口注意力)】。下面来具体看看。

思想来源(故事背景)
先抛开技术,想一个生活场景:让你抄一本书。
你会怎么做?你不会每抄一个字,就把前面已经抄过的几百页从头到尾重读一遍。你的注意力其实只停在三个地方——原书(看着抄什么)、刚写下的几个字(确认抄到哪了),以及马上要写的下一个字。前面抄完的内容,你会自然地”淡忘”,不再占用脑力。正因如此,你抄第 100 页和抄第 1 页一样轻松,速度不会越来越慢。
但今天的 OCR 大模型做不到这一点。
以 DeepSeek OCR 这类”端到端”模型为代表,它们用大语言模型(LLM)当解码器,确实带来了语言先验、识别更准。可代价是:输出越长,模型越慢、越吃显存。原因在于标准注意力机制——每生成一个新字符,模型都要回看此前生成的全部内容,这些历史以 KV cache 的形式堆积在显存里,随输出长度线性膨胀。
结果就是:现有模型一次前向根本读不完十页文档。它们只能”逐页处理”——一页一页地 for 循环,每翻一页就把记忆清空重来。论文一针见血地指出,这种做法”能用,但只是工程上的权宜之计,而非迈向通用智能的一步”。它把一个本应连贯的长程任务,硬生生切碎成一堆孤立的短任务,再交给外部调度器拼接。
Unlimited OCR 的目标,就是让模型摆脱这个 for 循环,真正像人一样,一口气连续读完几十页。
抄书时的注意力,长什么样?
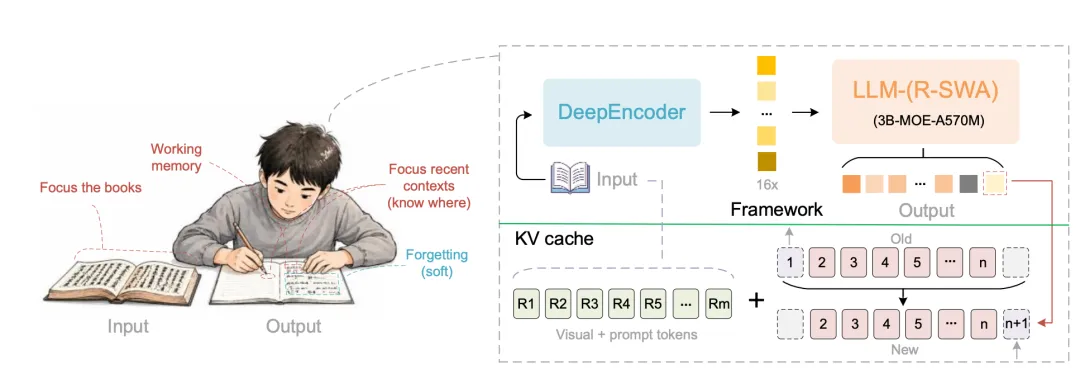
画了张图:

人抄书时的那种注意力模式,和现有模型里任何一种注意力都不一样。
-
它不是标准全注意力——因为你从不把已写的全部历史完整重读一遍; -
它也不是线性注意力——因为原书(视觉信息)始终清晰地摆在那里,不会被反复”压缩进某个隐状态”而逐渐模糊。
这两点否定非常重要,它们直接框定了新机制必须满足的两个约束:
-
原文必须始终清晰可见——视觉特征不能因为反复迭代而退化(这会直接拉低识别准确率); -
历史输出可以”软遗忘”——只保留最近一小段就够追踪进度,不必全部留存。
R-SWA:一半全局看图,一半滑窗看进度
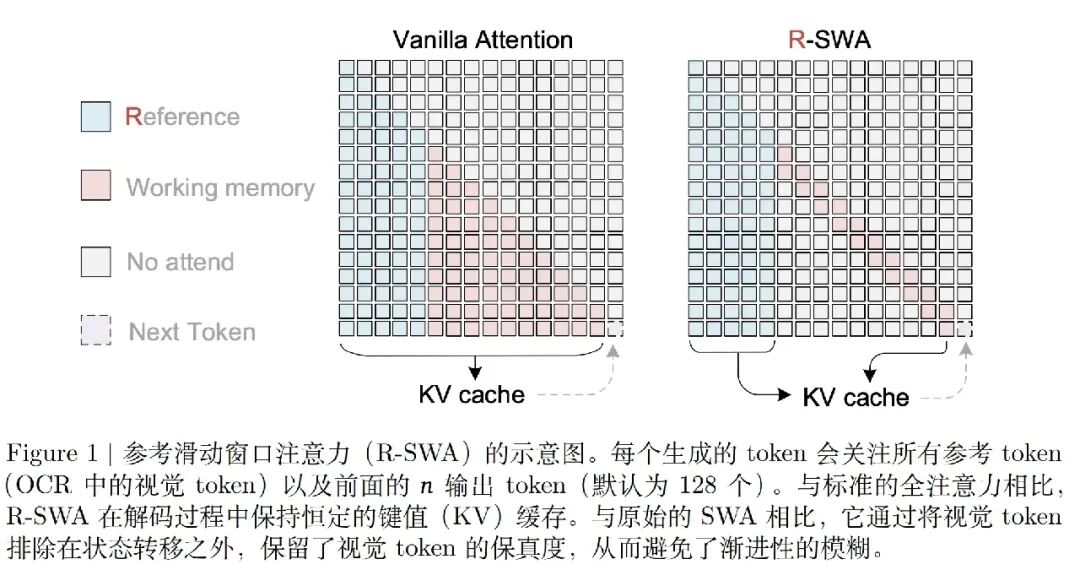
R-SWA 的设计可以用一句话概括:每个待生成的 token,永远能看到全部”参考内容”,但对”已生成内容”只看最近的一小段。
这里的”参考内容”,对应抄书时的原书,在 OCR 里就是图像编码后的视觉 token,外加任务提示词(prompt)。”已生成内容”则是模型此前吐出的文字 token。
注意力被限制在一个由两段拼成的窗口里,宽度为 m + n:
-
前缀段 m(参考窗口):包含全部视觉 token 和提示词。它对后面所有 token 全局可见。它的大小只取决于文档有多少页、分辨率多高,在整个解码过程中固定不变,不随你生成了多少字而增长。 -
解码段 n(滑动窗口):只覆盖最近生成的n个文字 token(默认n = 128)。它以因果(causal)的方式向前滑动——每生成一个新字,窗口就往前挪一格。
于是每个新 token 的”视野”就是:全部前缀 + 最近 n 个输出。前缀提供”我在读什么”的完整图像信息,滑窗提供”我抄到哪了”的进度追踪。更早的输出则被排除在视野之外,对应人脑的”软遗忘”。
这个设计有一个巧妙的细节:视觉 token 只在最开始被编码一次,之后就静态地待在那里,永远不参与状态更新。 这正好规避了线性注意力的通病——如果让视觉特征跟着输出一起反复迭代,它们会像反复复印的纸张一样越来越模糊,识别精度随之崩坏。R-SWA 把”参考”和”进度”彻底解耦:原文永远清晰,进度靠滑窗追踪。
为什么它能”无限”读下去?关键在 KV cache 恒定
R-SWA 带来的最直接、也最重要的好处,是 KV cache 的大小被锁死成一个常数。
对比一下两种机制在生成了 T 个 token 之后,需要保留多大的 KV cache(L_m 表示前缀长度):
-
标准注意力(DeepSeek OCR):缓存 = L_m + T。也就是说,输出越长,缓存越大,没有上限。 -
R-SWA(Unlimited OCR):缓存 = L_m + min(n, T),永远 **不超过L_m + n**。
差别非常本质:标准注意力的缓存随输出无限线性增长,而 R-SWA 的解码侧缓存被一个固定窗口锁住。当输出足够长(T 远大于 n)时,两者缓存的比值会趋近于零——意味着输出越长,R-SWA 省下的显存就越夸张。
工程实现上,论文把这个 KV cache 做成一个容量固定为 m + n 的队列。每生成一个新 token,就把队首那个最老的输出 token 的 KV 踢出去(论文里描述为驱逐第 m+1 个位置的 KV)。这样队列长度恒定,显存占用和计算开销都不会随生成过程递增。
模型架构
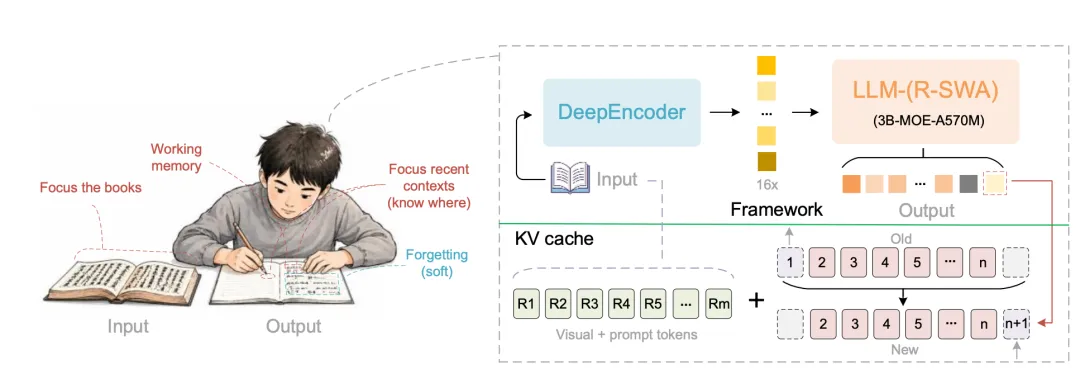
Unlimited OCR 并非从零搭建,而是直接以 DeepSeek OCR 为基线【《多模态文档解析开源新进展-DeepSeek-OCR2.0架构、数据、训练方法》】,做了一处替换。
整个模型是一个统一的端到端结构,由两部分组成:
第一部分:DeepEncoder(视觉编码器,原样保留)
这是 DeepSeek OCR 里就有的高压缩编码器,它把 SAM-ViT 和 CLIP-ViT 级联起来,在两者衔接处做 16 倍的 token 压缩。前半段用窗口注意力处理原始高分辨率图像,后半段才用全局注意力处理已压缩的少量 token——这样处理高清图时激活值很低,省显存。它能把一张 1024×1024 的 PDF 图像压成区区 256 个视觉 token。
这个高压缩比对”无限 OCR”至关重要:因为视觉 token 是要全程驻留在前缀里的”参考”,压得越狠,前缀 L_m 就越短,能塞进去的页数就越多。
第二部分:MoE-LLM 解码器(注意力全换成 R-SWA)
解码器沿用 DeepSeek OCR 的混合专家(MoE)架构——总参数 3B,但推理时只激活 0.5B,效率极高。Unlimited OCR 做的唯一、也是核心的改动,就是:把解码器里所有的标准多头注意力(MHA),全部替换成 R-SWA。
训练方法:只练解码器,冻住编码器
冻结 DeepEncoder,只训练 LLM 的参数。因为编码器在 DeepSeek OCR 里已经被充分优化过了,没必要再动。模型真正要学的,是如何在 R-SWA 这种”只能看一小段历史”的新注意力模式下,把有用的进度信息持续地传递进滑窗。
-
数据:构造约 200 万条文档 OCR 样本,单页与多页按 9:1 混合。单页数据用 PaddleOCR 标注,把每个版面块的坐标和内容拼成”端到端检测 + 解析”的标签,坐标归一化到 0–1000。多页数据则由单页拼接合成——随机生成约 20 万条、每条 2 到 50 页的样本,页与页之间用 <page>分隔。所有数据打包成 32K 长度的序列。 -
起点与时长:从 DeepSeek OCR 的 checkpoint 继续训练,仅 4000 步,全局 batch size 256,最大序列长度 32K,在 8×16 张 A800 上完成。
实验
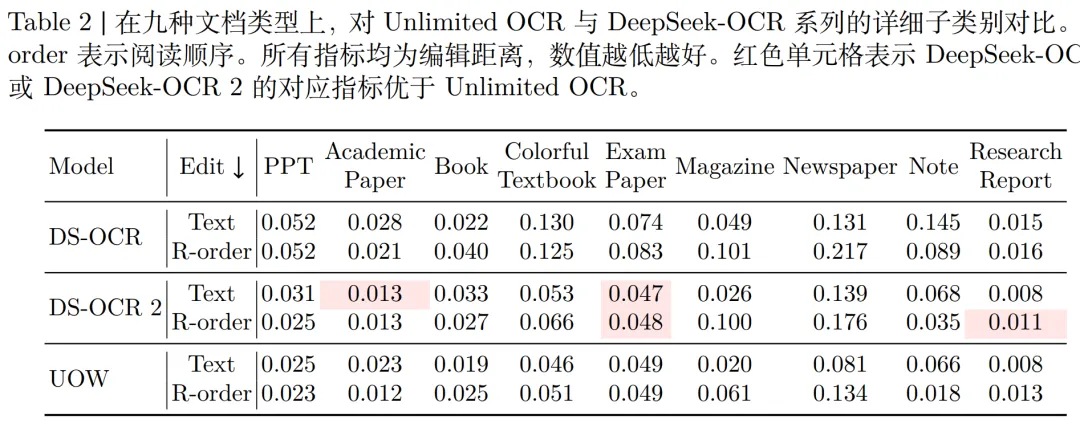
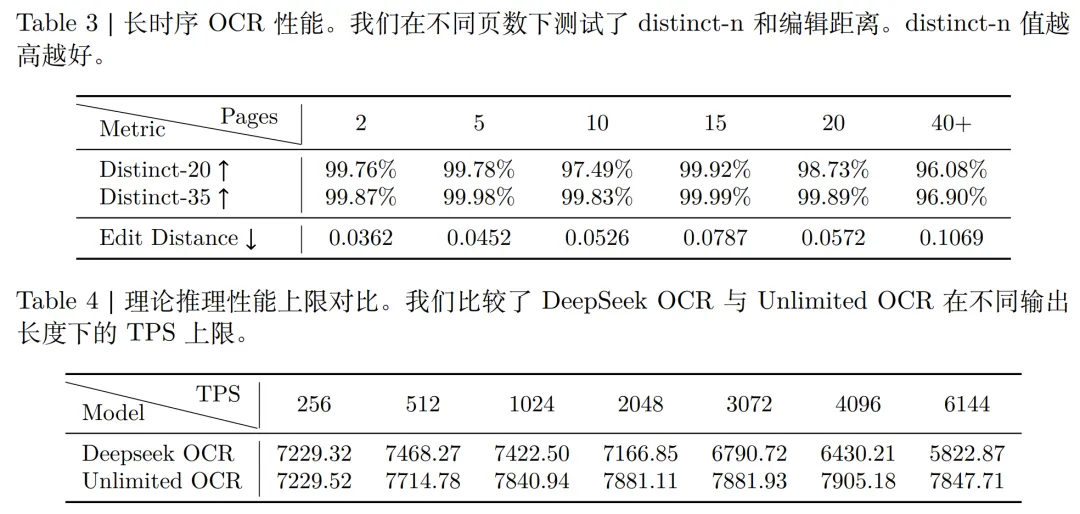
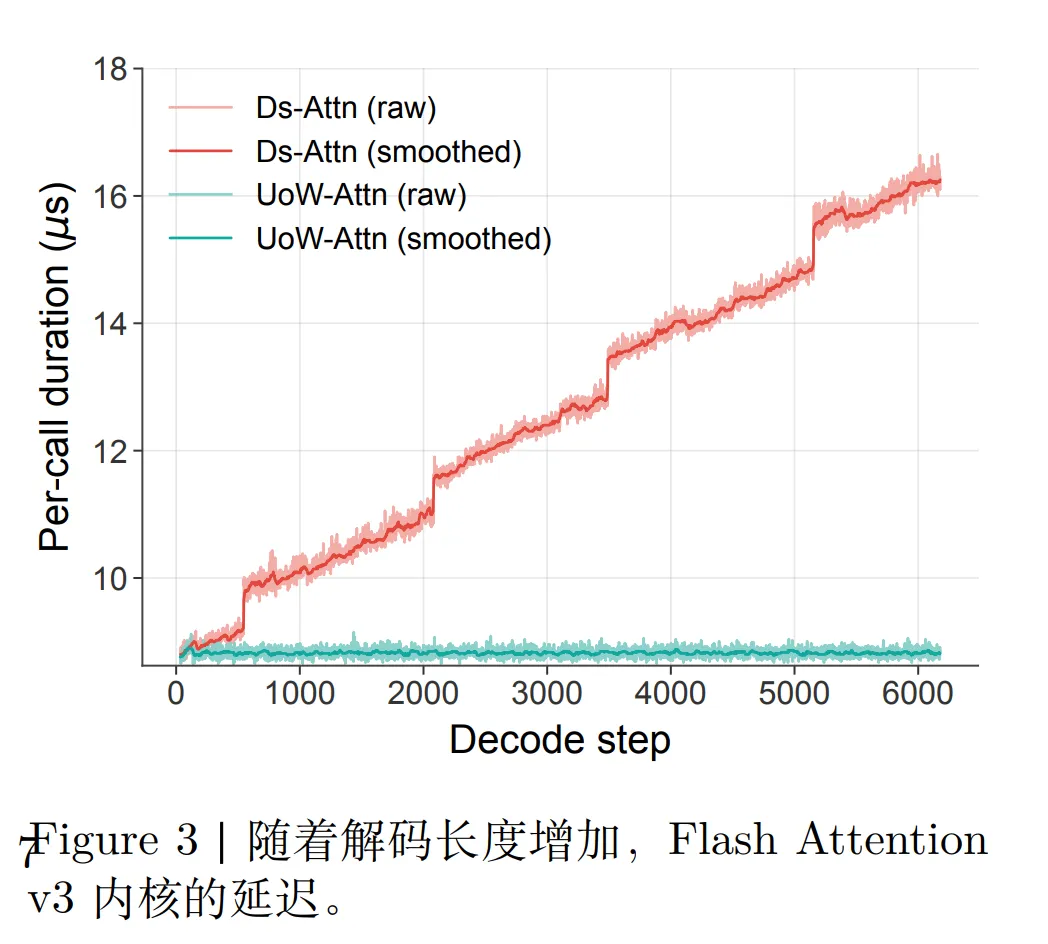
往期相关
多模态文档解析的开源项目模型技术方案都在《文档智能专栏》,如:
…
参考文献
-
Unlimited OCR Works: Welcome the Era of One-shot Long-horizon Parsing,https://arxiv.org/abs/2606.23050 -
https://github.com/baidu/Unlimited-OCR