 夜雨聆风
夜雨聆风





百度开源了一个能一次读完40页文档的OCR模型参数只有3B
我花了时间读这篇论文。
说实话,一开始没抱什么期待——OCR 这个方向,这几年被大模型轮番轰炸过太多次了。 GPT-4o 说要做、 Gemini 说能做、各个国产大模型都说自己”文档理解很强”。但真拿去跑一个 20 页的 PDF ,结果基本都是那个样:前几页还行,到第 5 页开始丢字,第 10 页开始胡诌,第 15 页直接告诉你”抱歉,我上下文不够了”。
坦白说,挺令人失望的。 2026 年,参数已经干到上千亿,可连”读完一份合同”这件事都做不利索。每次看到那些所谓”长上下文”的 demo ,我的反应都是——拿一个真实的 50 页标书去跑跑看?跑完再说。
但这次不太一样。
6 月 22 号,百度悄悄在 GitHub 上丢了一个项目。名字很大气:Unlimited-OCR。宣传语也很大气——”Welcome the Era of One-shot Long-horizon Parsing”(欢迎来到单次长程解析时代)。总参数量 3B , MoE 架构,实际激活只有 500M 。

参数不大,口气不小。我心想,又一个大模型厂出来刷存在感了?
然后看到了数据。
93.92%,比 235B 的模型还高
在 OmniDocBench v1.6 上, Unlimited-OCR 综合得分 93.92%。排它后面的是谁呢? Qianfan-OCR ( 4B ) 93.90%, Logics-Parsing-v2 ( 4B ) 93.33%, FireRed-OCR ( 2B ) 93.26%。
而 DeepSeek-OCR 2——它基于的那个版本——才 90.25%。
这些数字单独看可能不太震撼。但你再看一行:Qwen3-VL , 235B 参数, 89.15%。被一个 3B 总参、 500M 激活的小模型按在地上摩擦。
也不是说 235B 的模型就水——问题出在标准注意力机制上。输出序列越长, KV Cache 就越大,显存越吃越多,速度越跑越慢。如果你用 GPT-4o 跑同样的测试,得分只有 75.02%。不是模型不聪明,是它”记不住”。
Unlimited-OCR 做了一个谁都没做过的事:一次性输入 20 页文档,编辑距离仅 0.057 。 40 页以上, 0.107 。 Distinct-35 (去重指标)仍然高达 96.9%。
也就是说,这本”书”它真的一口气读完了,而且没复读、没忘词。
怎么做到的?
这个问题才是整篇论文最值钱的地方。
R-SWA :把”抄书”的读法塞进了注意力机制
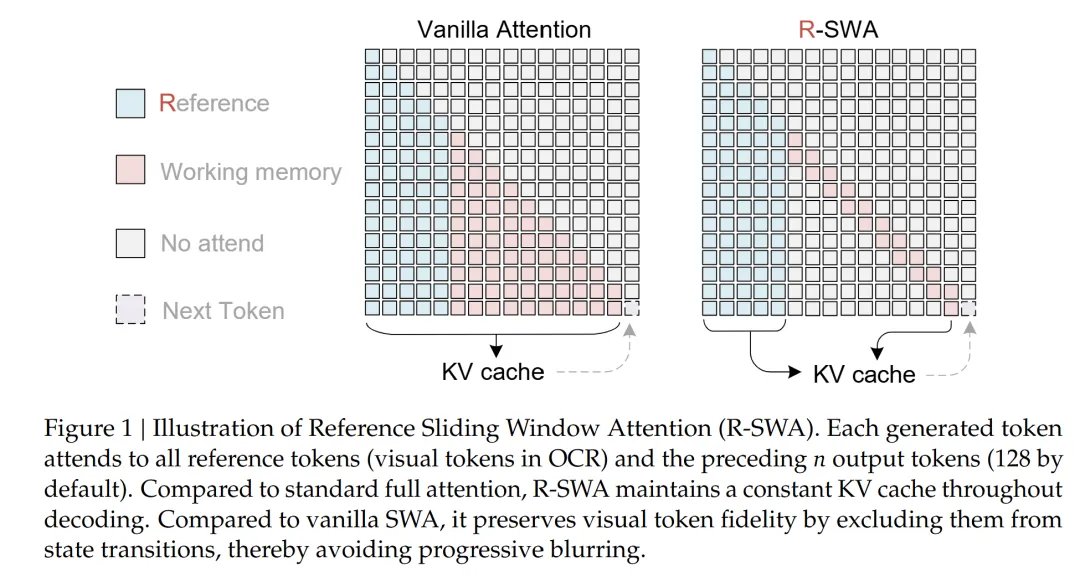
Unlimited-OCR 的核心创新叫 Reference Sliding Window Attention,简称 R-SWA 。中文名我试着翻了一下:参考滑动窗口注意力。
听起来像又一篇注意力机制改进的论文对吧?老实说,我翻到第三章时还在想——又是一个为了发论文硬造的”创新”。但看完实验数据,我收回这个判断。
先看它解决了什么问题。
标准的注意力机制( MHA )在处理长序列时有个致命问题: KV Cache 跟着输出 token 数线性增长。你输出 1000 个 token ,它就膨胀到 1000 那么多;输出 10000 个,膨胀到 10000 。显存吃不消,速度也直线下降。
这就导致了一个极其荒诞的现状:人类抄 10 页书,越抄越熟练;但 AI 读第 10 页时,比读第 1 页慢了将近 40%。你敢信吗——所谓的”最聪明”的模型,连线性抄写这件事都做不到匀速。
R-SWA 的思路很直接——模仿人抄书。
你把文档图像摊在桌上(这就是 Reference Token ),它始终在那里、始终可见。而你已经写出来的那些字呢?不需要全部盯着——只看最近写下的那几行就行。
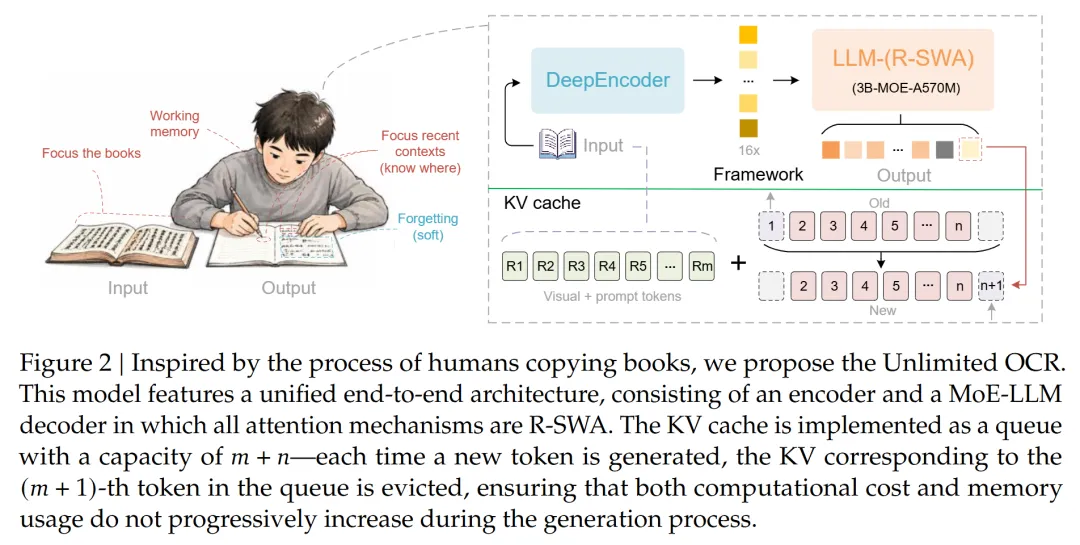
在这个机制下,每个解码 token 能看到两部分内容: 1. 所有 Reference Token(视觉 token + prompt )—— 相当于”摊在桌上的原书” 2. 最近 128 个输出 token(滑动窗口)—— 别忘了刚写下的字,再早的就自然”忘记”了
KV Cache 变成了一个固定大小的队列:新来的挤走最老的。不管你输出 1000 个 token 还是 10000 个,缓存占用的显存完全一样。
嗯。
就这么简单?
就这么简单。
效果呢?
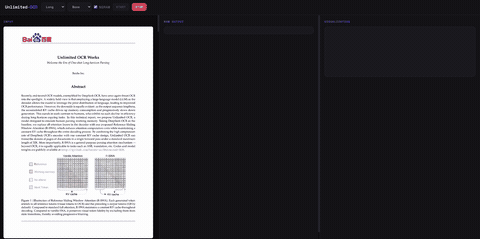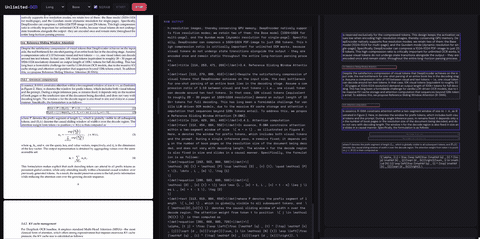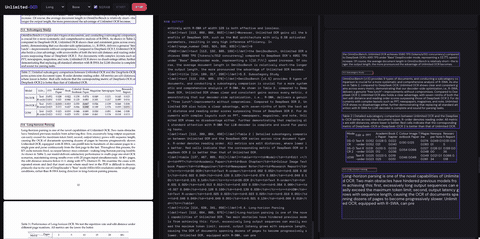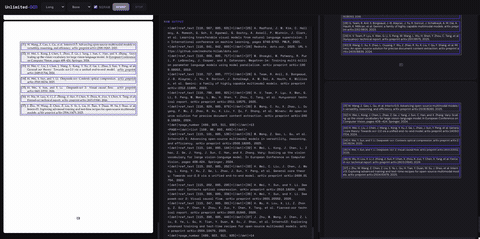
直接看 TPS (每秒处理 token 数)曲线。 DeepSeek OCR 的标准 MHA ,在 6144 个 token 的输出长度下, TPS 从 7400 掉到了 5800——掉了将近 22%。而 R-SWA 全程稳定在 7800~7900 ,几乎是一条直线。
差距有多大? 6144 token 时,快了 35%。
更关键的是, DeepEncoder 把 1024×1024 的一页 PDF 压缩成了仅 256 个视觉 token( 16 倍压缩率)。这些视觉 token 在 R-SWA 下不参与状态更新——不管你输出多长,文档的视觉信息始终保持清晰。说白了就是:原书摊开放在那里,你不会”看久了就看不清”。
配合标准的 32K 上下文长度,几十页文档一次推理就搞定。
而且有个细节让我很在意:论文说,这个模型是在 DeepSeek OCR 的基础上,只继续训练了 4000 步。数据量就 200 万页文档样本, 9:1 的单页多页混合。
4000 步。就改了个注意力机制,效果直接上天了。
多少团队砸了几个月的算力去训千亿参数模型,结果一个注意力机制的换法就解决了。说明之前根本不是数据和模型大小的问题,是路径依赖的问题。所有人都在堆参数堆上下文,没人停下来想一想”现有机制适不适用于这个任务”。
3B 碾压 235B ,这个信号值得注意
过去两年的 AI 叙事,核心是一个字:大。更大的模型、更多的数据、更长的上下文。 GPT-4 到 GPT-4o 到 GPT-5 ,一路往大走。 DeepSeek V3 到 V4 也是。大家都默认”大力出奇迹”是唯一的路径。
但 Unlimited-OCR 给出了一个完全不同的叙事。
不是说 Unlimited-OCR 不好,是说明过去两年我们被”大力出奇迹”的叙事忽悠瘸了。多少团队砸了几百张显卡去训千亿参数模型,结果呢?一个 3B 参数的小模型,靠一个注意力机制的改动,就把所有”巨无霸”按在地上摩擦。
3B 参数, 500M 激活——在 OmniDocBench 上追平甚至超过了 4B 的 Qianfan-OCR 。而这还不是它最离谱的地方。最离谱的是它在长文档场景下直接秒了所有大参数模型——因为那些模型在长输出场景下 KV Cache 膨胀到根本无法高效运行。
反过来说,如果 R-SWA 这条路走通了,那”大”就不是唯一的答案了。
论文里有一句很克制的话: R-SWA is a “general-purpose parsing attention mechanism”——可以适用于语音识别、机器翻译等需要长输出依赖的任务。
翻译一下就是:我们不只在做 OCR 。
百度手里有 PaddleOCR 的产业底座、有文心的模型能力,现在又多了一个 R-SWA 这样的通用注意力机制专利。如果它真能把这种 constant-memory 的解码范式推广到更多任务,那格局就不一样了。
结尾?
OCR 这个领域太老了,老到很多人觉得它已经被”解决”了。但 Unlimited-OCR 告诉我们的恰恰是相反的故事:一个真正好用的 OCR ,不是把识别率从 98% 提到 99%,而是让一个模型能像人一样、一次性看完一整本书。
论文的结尾抛出了下一步计划:训练 128K 上下文窗口,构建一个”预填池( Prefill Pool )”机制,让模型学会像人翻书一样按需调取历史信息。
如果能做到那一步——OCR 就不再是”识别一页文字”了。那是真正地在”阅读”。
参考链接:
论文地址:https://arxiv.org/pdf/2606.23050
Huggingface开源模型库地址:https://huggingface.co/baidu/Unlimited-OCR
开源github仓库地址:https://github.com/baidu/Unlimited-OCR