 夜雨聆风
夜雨聆风AI资讯要点
【要闻筛选】
- Meta 发布 Muse Spark:原生多模态模型,迈向个人超级智能,部分指标超GPT-5.4
- Anthropic 发布 Claude Managed Agents:一套托管完成Agent构建
其他AI资讯
【AI 3D】
- SP‑6M :人脸扫描数据集,通过一张照片快速进行3D人像重建
【AI 创作】
- Runway: 支持自定义AI角色语音
- HeyGen 发布 Avatar V:15 秒视频打造数字分身
- Black Forest Labs 发布 FLUX.2 Small Decoder:更轻、更快的高质量图像生成
【AI 应用/模型】
- 腾讯云:发布 AI 浏览器QBotClaw
- 字节跳动发布 Seeduplex:全双工语音大模型,交互更自然
- Liquid AI 发布 LFM2.5-VL-450M:专为边缘设备设计的轻量级视觉语言模型,能够在极低算力下实现复杂的场景理解。
👇进群,不错过每日最新AI资讯噢~


💡主要内容
Meta 发布 Muse Spark:原生多模态模型,迈向个人超级智能
Meta 推出原生多模态模型 Muse Spark,这是 Muse 系列的首款模型。
Muse Spark 在视觉、语音等多模态上进行原生融合,支持内置工具调用、视觉思维链和多智能体编排。
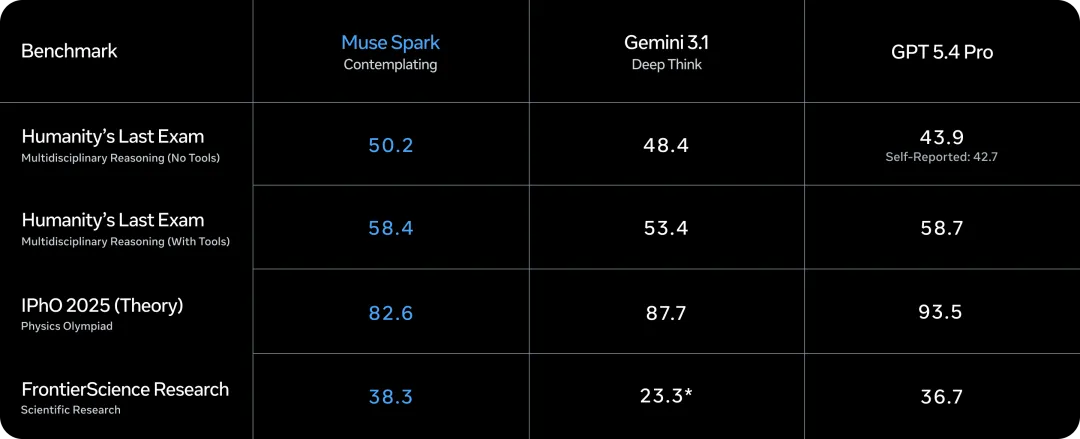
其新推出的“沉思(Contemplating)”模式允许模型并行调度多个代理进行深度推理,在复杂任务上明显提升推理能力。
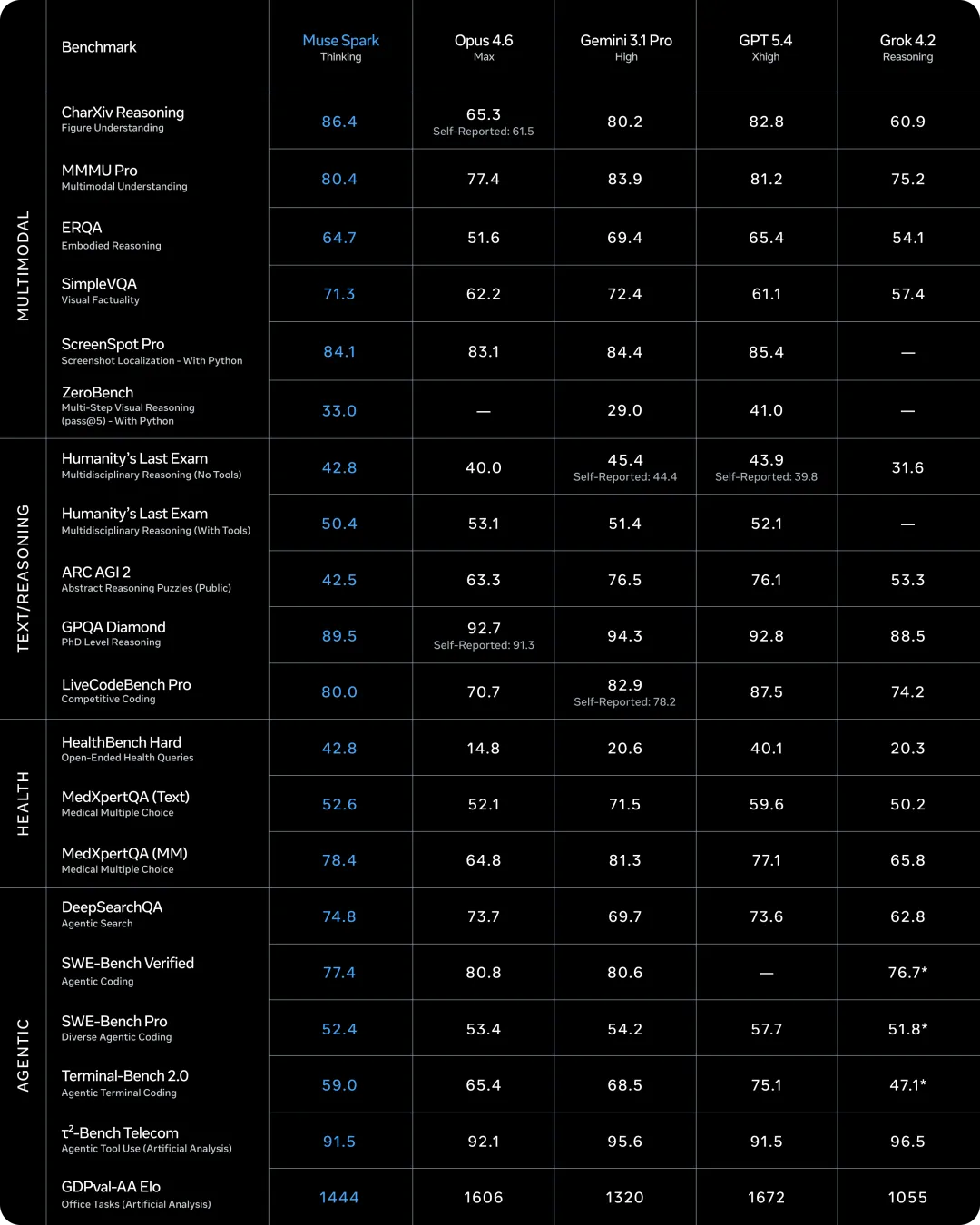
- 原生多模态推理: Muse Spark 将视觉、文本和代码理解统一在一个模型中,并支持通过工具调用执行外部程序或生成代码。这种原生融合使模型能够在视觉 STEM 问题、实体识别和定位等任务上取得较好表现
- 视觉思维链: 模型可以在回答前进行多步图像‑文字推理,生成可解释的中间步骤和视觉标注,从而改善复杂问题的解决能力
- “沉思”模式 (Contemplating): 支持多智能体编排,通过增加测试时计算量,让多个并行 Agent 协作推理,在保持低延迟的同时大幅提升性能。官方称该模式在 Humanity’s Last Exam 和 FrontierScience Research 等基准上分别达到58%和38%的分数,可与现有顶尖模型媲美!
- 高效扩展: 相比前代模型 Llama 4 Maverick,Muse Spark 达到同等能力所需的计算量降低了一个数量级以上,训练效率极高。
Muse Spark 正在向部分开发者开放 API 预览,并计划将 Contemplating 模式逐步推送至 meta.ai 应用。
⭐使用地址:
https://meta.ai/https://ai.meta.com/blog/introducing-muse-spark-msl/Anthropic 发布 Claude Managed Agents:一站式 Agent 构建平台
Anthropic 宣布开放 Claude Managed Agents 的公测。为使用 Claude 构建自主代理提供托管基础设施,开发者只需定义代理的任务、使用的工具和安全规则,托管环境会负责沙箱隔离、状态管理和权限控制等运行细节。
简单来说,你可以把它理解成一个“官方托管版 AI 智能体工作台”:以前如果开发者想让 Claude 执行长任务,往往得自己搭很多复杂的底层系统;而 Managed Agents 就是 Anthropic 直接把这套基础设施做好,开发者只需要告诉它任务、工具和规则,Claude 就能在一个有状态的会话里持续工作,带着持久事件记录、安全沙箱和内置工具去完成更长链条的任务。通俗点说,它像是把“只会一问一答的 AI”升级成了“有人给它配好工作环境、工具箱和安全护栏的数字员工”,所以开发者不用从零搭脚手架,就能更快做出会自己行动的 AI 应用。

- 托管代理架构: 与直接调用模型的 Messages API 不同,Managed Agents 提供一个预先配置好的“代理框架”,包括模型、系统提示、工具库、MCP服务器和技能管理等。
- 自动环境管理: 开发者可以创建定制化环境,配置容器的软件包和网络权限;启动会话后,代理会在云端持续运行,并根据用户事件异步执行任务。
- 内置工具支持: 托管代理内置 Bash 命令、文件读写、网页搜索和抓取等工具,未来还将接入代码执行、内存管理等更多工具。
官方定位为适合长时间运行、多次调用工具的任务,例如代码评审、文档生成或复杂数据分析;所有会话状态保存在云端,可随时查看或中断。
备注:Claude Managed Agents 目前处于测试阶段。
🌟阅读更多:
https://platform.claude.com/docs/en/managed-agents/overview🤖️AI 3D
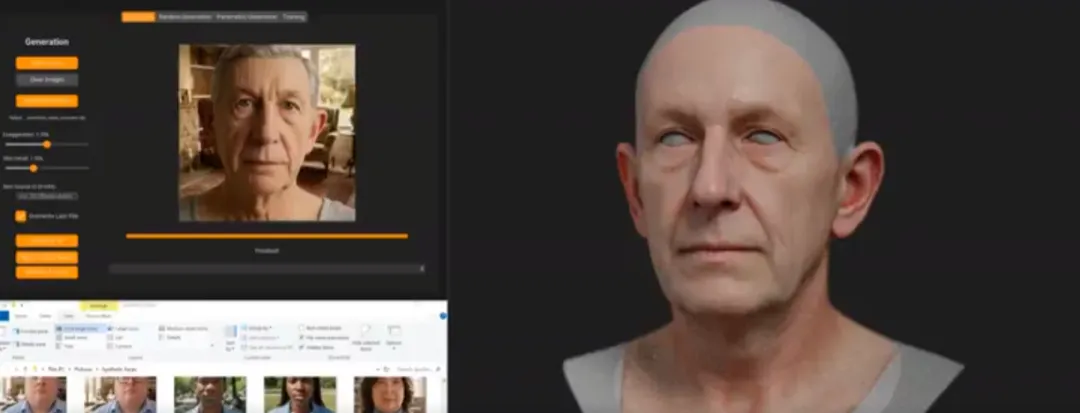
SP‑6M :人脸扫描数据集,通过一张照片快速进行3D人像重建
Ten24 团队推出 SP‑6M 数据集(高分辨率人类头部扫描库),包含超过 115 万张 RAW CR2 图像和 1.6 万套 3D 扫描数据。研究者利用该数据集探索从单张图片到高保真 3D 人像的重建技术。
亮点:
1. 超大规模数据集: SP‑6M 提供超过 1,158,411 张未压缩 RAW CR2 图像和 16,297 个 3D 扫描,涵盖 7,632 名参与者,每人拍摄 11 种表情,用于支持高质量面部表情建模。 2. 重拓扑网格: 数据集包括重拓扑的中性人脸模型和完整配套纹理,可用于训练生成式和几何网络。 3. 3D 人像重建探索: Ten24 展示了基于 SP‑6M 的早期研究,能够从单张照片恢复头部几何和纹理。这项工作借助 3D 高斯散射及深度学习,实现了自然发型、光照等条件下的高保真重建。

⭐项目地址:
https://www.sp-6m.com/🤖️AI 创作
Runway: 支持自定义AI角色语音
Runway 为其视频生成工具引入了自定义语音功能,用户现在可以根据文本提示或参考音频设计独特的语音。用户可以在 Generative Audio 中训练专属声音并为虚拟角色配音。
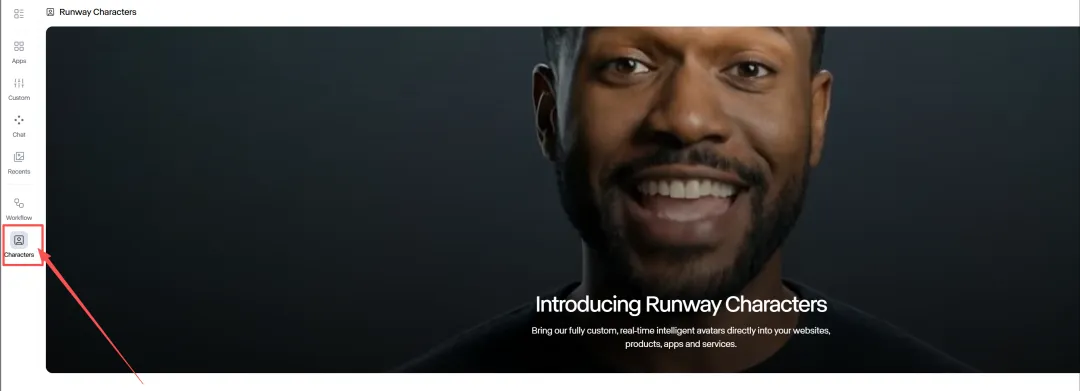
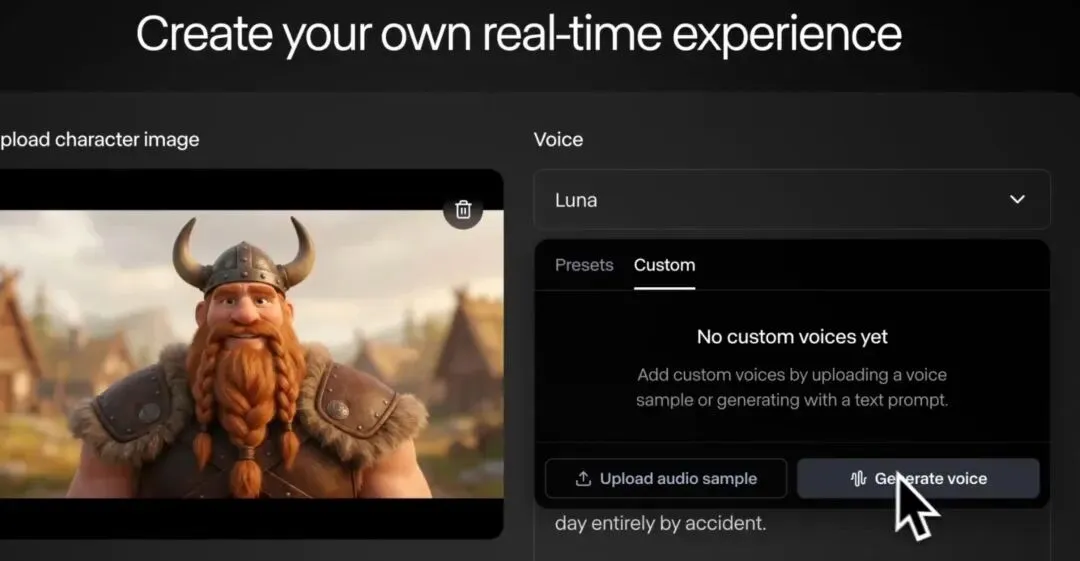
- 文本驱动语音设计: 用户只需输入描述性文字(如“带有沙哑感的低沉男音”),即可生成全新的、从未存在过的音色,支持调整语调、语速和情感表现力。
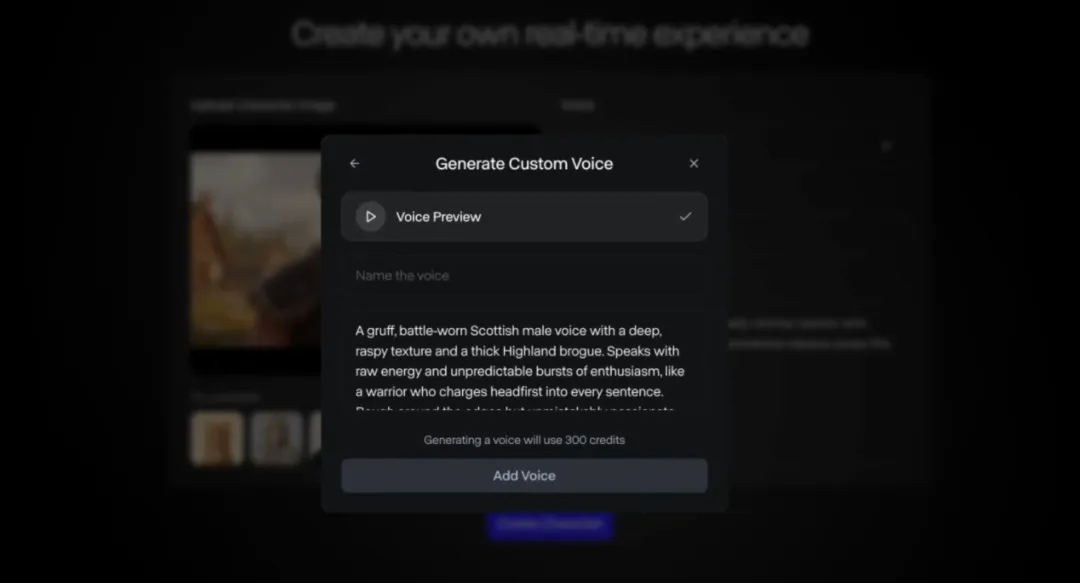
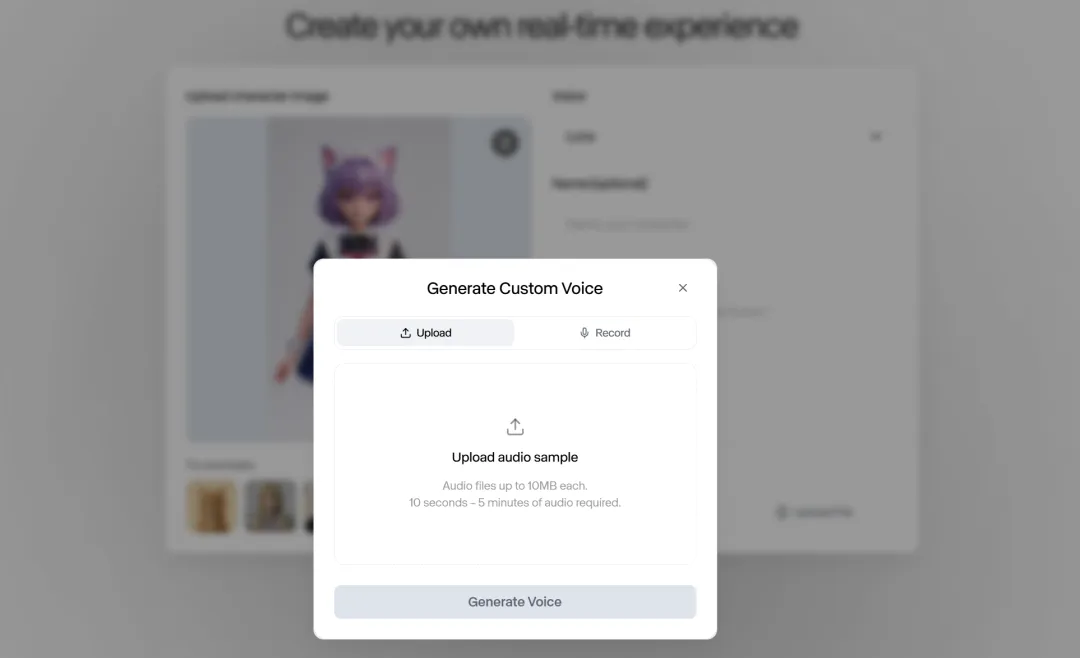
- 训练自己的声音: 用户上传 10 秒到 5 分钟的语音样本,或录制官方提供的脚本,即可为声音命名并提交训练。
- 角色与语音匹配: 生成的语音可以完美同步到视频中的 AI 角色上,实现音画合一的沉浸式体验。
- 每个自定义声音需要 300 积分训练,仅供上传者本人或经授权的声音使用,保障版权和隐私
⭐阅读详情:
https://docs.dev.runwayml.com/characters/custom-voice/HeyGen 发布 Avatar V:15 秒视频打造数字分身
HeyGen 推出下一代视频生成模型 Avatar V,用户录制 15 秒视频即可生成数字分身,模型可保持面部身份和动作一致性,并支持不同服装、背景等外观变化
- 15 秒录制即可生成: Avatar V 通过一次 15 秒的手机录制就能捕捉用户真实的面部几何、微表情和动作模式。
- 身份一致性: 相比以往仅在短片段里保持效果的模型,Avatar V 通过深度训练解决了“身份漂移”问题,使长视频中人脸在各种角度和动作下始终保持用户本人的形象。
- 多角度和多外观生成: 模型将“表演”与“外观”分离;用户只需录制一次,就可以在后续生成不同服装、场景或风格的视频,而人物动作仍来自真实录制
- 多语言支持: 支持 175 种以上语言,让数字分身能进行全球化表达。
使用说明:
⭐使用地址:
https://www.heygen.com/avatars/avatar-vBlack Forest Labs 发布 FLUX.2 Small Decoder:更轻、更快的高质量图像生成
Black Forest Labs 推出 FLUX.2 Small Decoder,这是一个经过蒸馏的 VAE 解码器,旨在不牺牲图像质量的前提下,显著优化生成效率。
- 解码速度提升: 相比完整版解码器,解码速度提升了约 1.4 倍,显著缩短了图像生成的最后一步耗时。
- 显存占用降低: 显存需求降低约 1.4 倍,使得在显存受限的设备上生成更高分辨率的图像成为可能。
- 参数量大幅精简: 通过优化通道宽度,参数量从 50M 减少到 28M,更适合资源受限的环境部署。
- 无缝替换: 作为标准 FLUX.2 解码器的“即插即用”替代品,与 FLUX.2-klein 等系列模型完全兼容,图像质量几乎无损。

⭐项目地址:
https://huggingface.co/black-forest-labs/FLUX.2-small-decoder🤖️AI 模型/应用
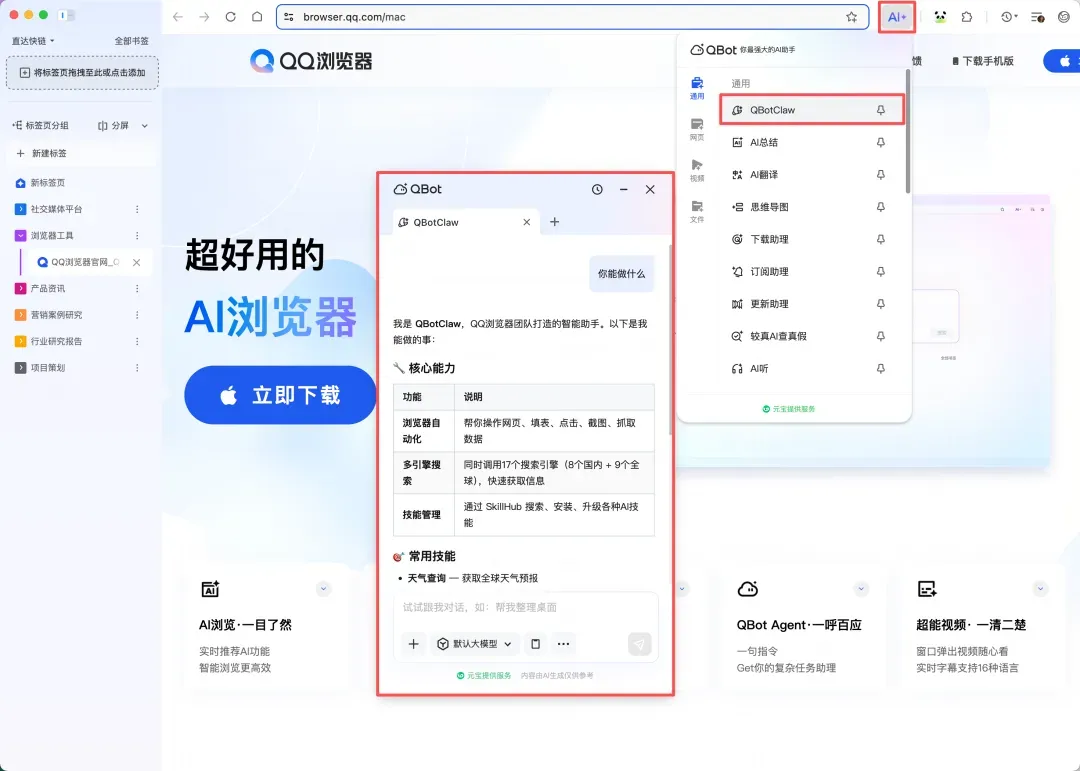
腾讯云:发布 AI 浏览器QBotClaw
腾讯云在 QQ 浏览器中上线智能助手 QBotClaw。用户无需安装额外软件,只需在 QQ 浏览器侧边栏启用即可免费使用,还支持通过微信 Clawbot 扫码与电脑端浏览器直连。Mac 版已上线,Windows 版即将推出。
- 精准网页操作: 内置自研 Skill 库,能精准识别动态网页元素,支持购物比价、跨平台发帖等复杂自动化任务。
- 深度上下文记忆: 基于浏览器运行,能感知当前页面内容、登录账号和打开的文件,无需反复交代背景。
- 兼容开放技能: QBotClaw 完全兼容 OpenClaw 技能,用户可配置不同国内大模型的 API Key,灵活调用多家模型能力
⭐相关信息:
说句话就能干活的 AI 浏览器来了字节跳动发布 Seeduplex:全双工语音大模型,交互更自然
字节跳动发布了原生全双工语音大模型 Seeduplex。相比早期半双工端到端语音模型,Seeduplex 基于“边听边说”的新框架,能够在用户讲话的同时持续聆听,大幅提升交互自然度和流畅度。目前该模型已在豆包 App 全量上线,旨在提升实时语音助手的对话能力并支持更拟人化的用户体验

- 精准抗干扰: 具备持续倾听能力,能精准忽略背景噪音和无关人声。在复杂环境下,误回复率和误打断率减少了一半。
- 动态判停: 综合语音和语义特征判断用户意图。面对用户思考时的犹豫,它会耐心倾听;用户说完后,响应极快,抢话率下降 40%。
- 超低延迟: 相比传统半双工方案,接话延迟降低约 250ms,在快问快答或飞花令等高频互动场景中表现极佳。
⭐信息来源:
https://seed.bytedance.com/zh/seeduplexLiquid AI 发布 LFM2.5-VL-450M:专为边缘设备设计的轻量级视觉语言模型,能够在极低算力下实现复杂的场景理解。
Liquid AI 发布 LFM2.5-VL-450M,这是一款专为边缘设备设计的轻量级视觉语言模型,能够在极低算力下实现复杂的场景理解。这是其 LFM2‑VL‑450M 的增强版,新模型通过扩大预训练数据量和强化学习优化,提升了多语言理解、目标检测和指令遵循能力。
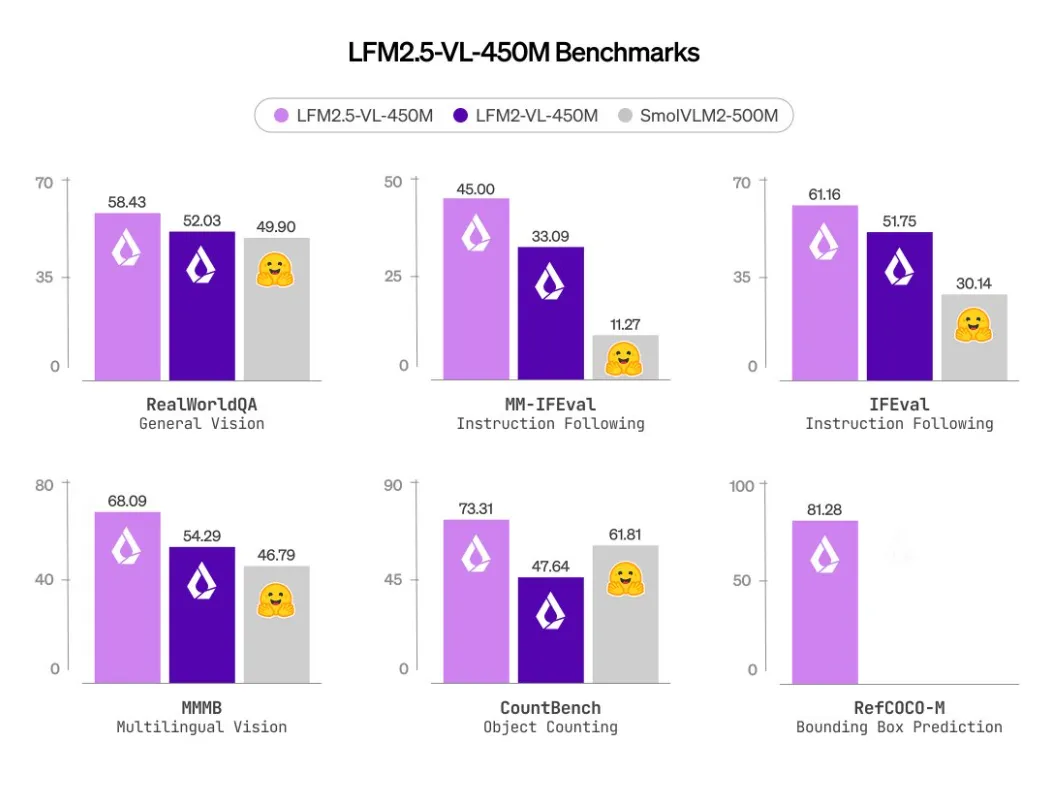
- 训练规模和功能改进: 新模型的预训练语料从 10 万亿 token 扩大到 28 万亿,并通过偏好优化和强化学习提高了视觉‑语言对齐能力。
- 新增功能: 增加对象检测和边界框预测(RefCOCO‑M 指标从 0 提升到 81.28),并加入函数调用能力,以便将视觉输出转换成结构化指令。
- 多语言支持: 在 MM‑MBench 多语言基准中,模型对阿拉伯语、中文、法语、德语、日语、韩语、葡萄牙语、西班牙语等语言的理解分数由 54.29 提升至 68.09。
- 实时性能: LFM2.5‑VL‑450M 在 Jetson Orin 等边缘设备上处理 512×512 图像时延约 240 毫秒,适用于每秒 4 帧的实时视频流,手机 SoC 上在小分辨率下也能保持秒级响应。
⭐来源:
https://www.liquid.ai/blog/lfm2-5-vl-450m⚠️部分内容由AI生成,可能存在偏差
💗有任何疑问,请提前联系邮箱:alolg@163.com
