 夜雨聆风
夜雨聆风=GROUPBY (row_fields,values,function,[field_headers],[total_depth],[sort_order],[filter_array],[field_relationship])
参数说明:
values:要进行运算的数据字段,相当于透视表的值标签。
function:进行运算的函数,比如求和、计数、求平均值等
[field_headers]:是否显示字段标题,有4个可选参数,根据需要进行选择。
[total_depth]:行标题是否包含总计,有5个可选参数,根据需要进行选择。
[sort_order]:一个数字,指示应如何对行进行排序。 数字对应于 row_fields 中的列,后跟值中的列。 如果数字为负数,则行按降序/反向排序。
[filter_array]:一个面向列的 1D 布尔值数组,指示是否应考虑相应的数据行。
[field_relationship]:指定向row_fields提供多个列时的关系字段。0:层次结构 (默认),1:表
函数应用示例
一、基本应用:
如下图所示,表格中记录了各物料的采购量情况,要计算各类别、物号或各品名的总采购量。
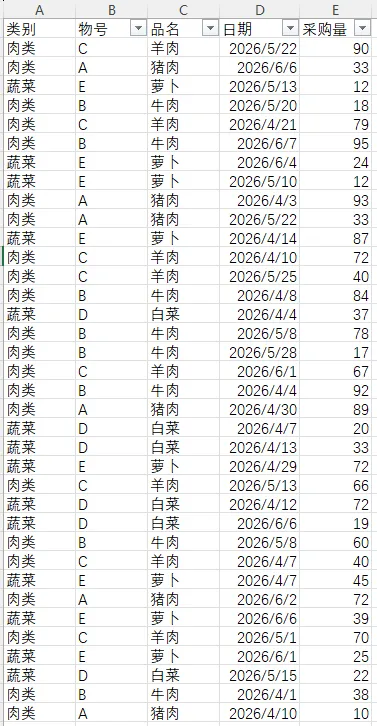
要求总采购量,方法很多,这里以按类别汇总演示GROUPBY的用法。在G1单元格输入“=GROUPBY(A1:A37,E1:E37,SUM,3)”,即可对类别进行汇总,运算函数为sum也就是求和,显示字段标题的参数为3,表示是并显示。结果如下图所示:
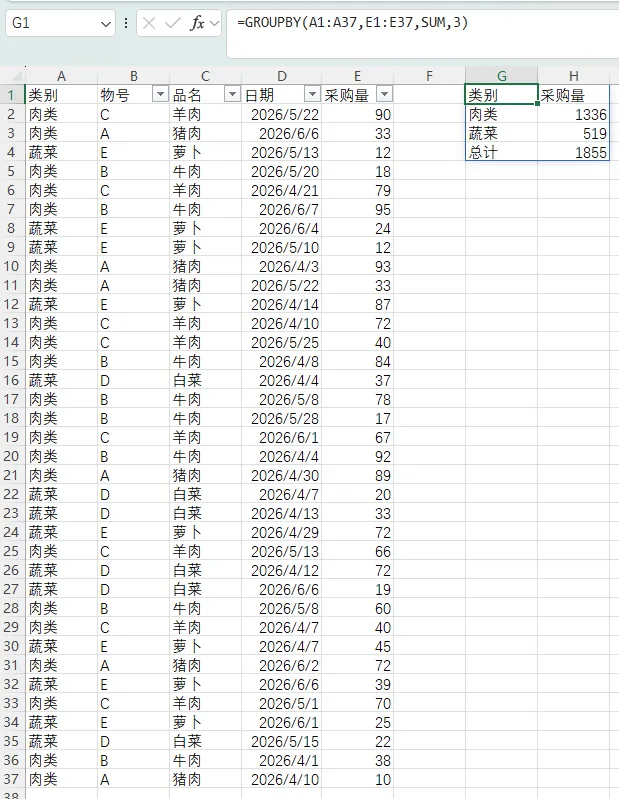
要进行透视的字段选择连续区域,或通过HSTACK选择不连续区域也是可以的,如下图所示:
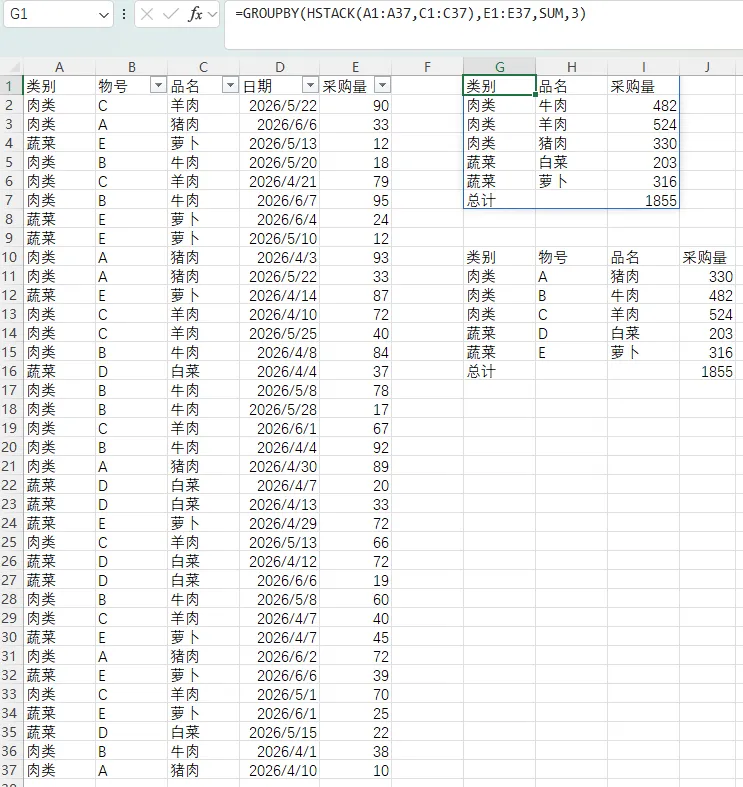
G1单元格公式为"=GROUPBY(HSTACK(A1:A37,C1:C37),E1:E37,SUM,3)";参数1为不连续的两列。
G10单元格公式为“=GROUPBY(A1:C37,E1:E37,SUM,3)”;参数1为连续的3列。
二、同时统计多个维度
如果要同时统计各品名的总采购量、采购次数、单次最大/小采购量、平均采购量又该怎么办呢?生成多次表吗?虽然可行,但显然不是我们要的。如果将这些计算维度放在同一张表,那它们显然是水平堆叠的,也就是放在不同列。HSTACK函数正好可以用来水平堆叠数组。为此可以将公式的第三个参数运算函数使用HSTACK函数堆叠要计算的各维度。
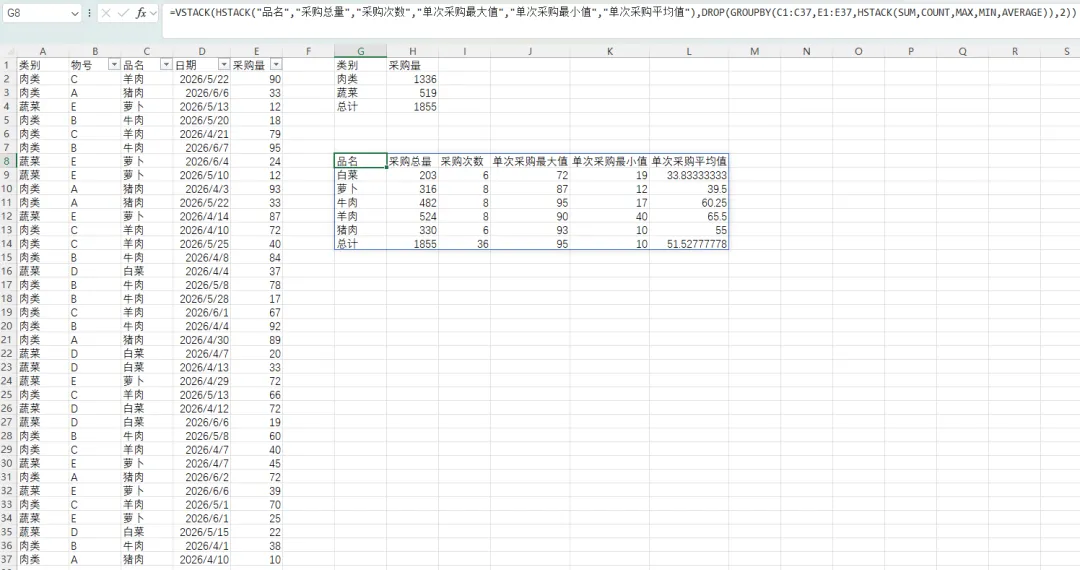
在G8单元格输入公式“=GROUPBY(C1:C37,E1:E37,HSTACK(SUM,COUNT,MAX,MIN,AVERAGE),3)”。运算函数的参数为HSTACK(SUM,COUNT,MAX,MIN,AVERAGE),表示计算和、次数、最大值、最小值、平均数这五个维度。公式返回结果如下图所示:
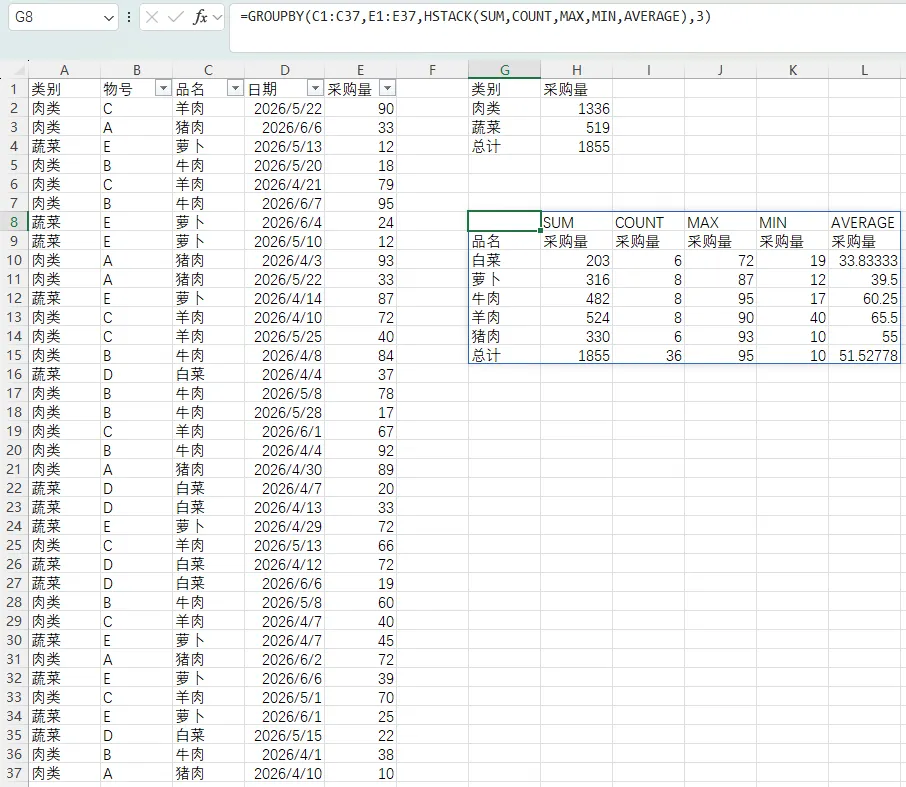
上图中返回的结果第一行给出了计算的维度名称,标题行计算的五个维度均是原表格的列名称“采购量”,可以嵌套其它函数进行格式整改。
将公示调整为“=VSTACK(HSTACK("品名","采购总量","采购次数","单次采购最大值","单次采购最小值","单次采购平均值"),DROP(GROUPBY(C1:C37,E1:E37,HSTACK(SUM,COUNT,MAX,MIN,AVERAGE)),2))”。公式使用drop函数去掉GROUPBY函数生成的前2行(计算类别名称行和自带的标题行),使用HSTACK创建想要显示的列名称,最后使用VSTACK连接成一个表格。结果如下图所示:
如果只是想简单的拉下总数之类的看看,那么GROUPBY函数也是一个不错的选择,这样就不用再麻烦拉数据透视表了。对该函数想了解更多用法的朋友可以自行尝试,根据是实际返回的结果进行验证。
