 夜雨聆风
夜雨聆风





2026年 AI 视频工具的终局?看完 LibTV 这 5 个实操细节,我把其他都卸载了
大家好,我是鹏哥。
如果你还在用那种“输入一句话,坐等视频吐出来”的工具,那么你还没入门 AI 视频的职业玩家圈子。
现在的 AI 视频圈子极度内卷。实操者最头疼的不是生成速度,而是“不可控”。角色在镜头间“基因变异”是常态,这种“开盲盒”式的创作根本没法承接严肃的商业项目。
这两天我深度跑了 LibTV。跑通它的底层逻辑后,我发现这玩意儿简直是为“一人公司”量身定制的生产力怪兽。它彻底摒弃了传统的“时间轴”思维,改用了“无限画布”和“节点流”逻辑。
今天带大家拆解这套系统,看它如何把 AI 视频从“玄学”变成稳赚不赔的工业生意。
01| 维度重构:从“碎片拼凑”到“全链路一体化”
在 LibTV 出现之前,我为了做一个 AI 漫剧,需要搭建一套极其复杂的 n8n 自动化流程。
大家看下图我以前的AI漫剧n8n工作流:首先让 LLM 改编生成剧本,再分发任务去生成角色 Prompt,接着调用生图模型出定妆图,最后再由另一个节点去跑视频生成,中间还要人工介入审美判定。这种“补丁叠补丁”的架构,不仅维护成本高,而且各环节数据割裂,稍微改动一个分镜就要全盘重跑。
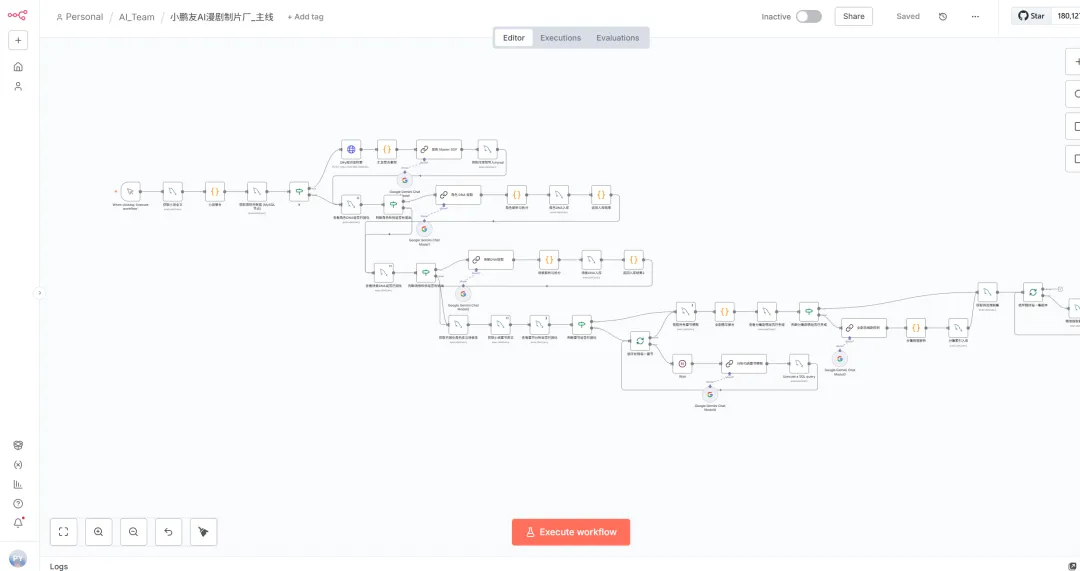
这不再是简单的“生成器”,而是一个全链路一体化的视频生产指挥部。
在这种非线性流里,你可以同时对比多套风格。改了剧本,点击“重生成”即可。这种从“上帝视角”俯瞰整个项目的掌控感,才是商业级别创作者的核心竞争力。
02| 角色库 3.0:用“三视图”钉死 AI 的变脸焦虑
做 AI 视频最痛点是角色一致性。
以前在 n8n 流程里,我们需要通过 Seed 值、LoRA 权重来反复“对齐”角色特征,稳定性全靠运气。LibTV 引入了角色三视图功能:直接生成标准的正面、侧面、背面视图。系统会将这些视图锁定为“锚点”,后续生成的所有分镜都会强行对齐这些特征向量。
这就不再是撞运气,而是真正的“数字资产”化。

有了这套资产,你可以建立自己的“数字演员经纪公司”,手握几十个永远不老、永远听话的数字演员。这在未来的虚拟偶像、短剧、甚至是电商直播带货中,才是真正的“内容杠杆”。
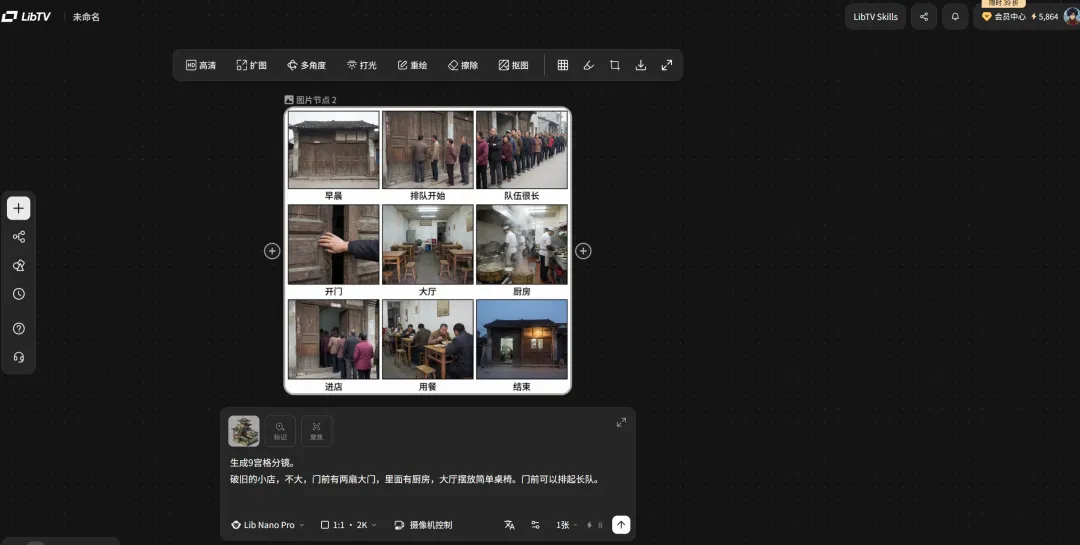
03| 分镜革命:9 宫格的“导演视角”选择逻辑
以往调分镜门槛极高,非专业人士很难写出精准的运镜词。
LibTV 引入了 9/25 宫格分镜生成。你只需要输入一句场景描述,它瞬间生成几十种机位供你挑选:远景交代环境、特写捕捉情绪、俯拍展示格局,一目了然。
你不再是调参数的打工人,而是监视器后面拍板的导演。
这种“超市化”选择逻辑,把影视专业的审美积累解构成了一道选择题。这种效率,就是一人公司对抗传统剪辑师的底气。
04| 暴力美学:实测短视频的一键流转
纸上谈兵没意思,咱们直接上个狠的:用 LibTV 跑一个 15秒的商业短视频样例。
假设需求是复刻一个“赛博朋克风格的咖啡机广告”。
-
剧本节点:输入“未来都市,极简咖啡机,光影流转,蒸汽氤氲”。
-
逻辑流转:系统自动分拆出 12 个关键分镜节点。
-
批量生成:利用 9 宫格锁定机位后,一键下发生成指令。
传统做法可能需要 半天的后期剪辑,而在 LibTV 的画布上,从剧本到成片输出,我只用了不到 5分钟。
05| 算力主权:本地 Node 节点的物理压制
做大规模内容工厂,云端的 Token 消耗是惊人的。
我现在的方案是:利用 OpenClaw 的分布式能力,把 LibTV 的执行端(Node)挂在本地算力集群上。
-
隐私性:资产不出本地局域网。
-
零成本:内网传输 4K 视频,速度起飞且无订阅费负担。
-
确定性:本地 GPU 满载工作的快感,是共享算力给不了的。
一旦拥有了“算力主权”,内容生产成本就会被无限摊薄,这才是长期主义的基石。
06| 对标分析:为什么 LibTV 比 Runway 和 Kling 更硬核?
很多人会问:鹏哥,Runway 很强,Kling 也很炸裂,为什么你要推 LibTV?
咱们说句大实话:
-
Runway/Kling:它们是顶级的“生成器”,但不是顶级的“工作流”。你用它们生成的视频是独立的碎片,要把这些碎片串成一个逻辑严密的故事,你需要极强的手动剪辑功底。
-
LibTV:它是顶级的“操作系统”。它把生成、编排、逻辑判定全都集成在了一块画布上,包含了市面上所有AI视频大模型。它解决的是“从 1 到 100”的工业化产出问题。
Runway 像是那把绝世好剑,只有剑客能舞好;LibTV 像是那条自动化生产线,哪怕你只是个厂长,也能产出高精尖产品。
我在评论区等你,咱们聊点透彻的。