 夜雨聆风
夜雨聆风





给AI知识库导了全部文档后,第一周最多的问题不是答错,是答出了不该答的
做AI知识库的团队,上线前最紧张的通常是一件事:答得准不准。
命中率高不高,能不能覆盖常见问题,答案有没有跑偏。这些确实该看。
但很多团队真正在第一周就出状况的,不是”答错了”。是另一种情况:答出了不该答的东西。
什么叫”答出了不该答的”?
想象一个场景。团队把内部文档全量导进了知识库,客服机器人第二天就能回答客户问题了,效果看起来不错。
第三天,一个客户问了一句:”你们这个产品之前出过什么问题?”
机器人很认真地回答了。因为内部有一份事故复盘文档,记录了去年的一次服务中断。这份文档原本只在内部流转,但现在它是知识库的一部分,机器人觉得这就是正确答案。
客户截图发到了社群里。

这种事为什么会发生?因为大部分团队导文档的时候,思路是”全导进去,覆盖面越大越好”。
逻辑上没错。知识库嘛,知识越多越好。
但问题在于,你公司的内部文档不全是”可以给客户看的知识”。里面最容易混进去、也最致命的是两类:
- 事故记录和客诉原文。
内部复盘写得越详细,被知识库引用后暴露得越彻底。客户问”你们之前出过什么事”,机器人会老老实实把事故经过讲一遍。 - 报价策略和折扣底线。
销售部门的内部文档里有底价、有折扣规则、有客户分级策略。这些一旦被知识库当成”可回答的素材”,等于把你的定价逻辑公开了。
其他类型的文档——老版本说明、未发布规划、员工信息——也该清理,但优先级没有这两类高。上面这两类出一次事,后果是直接面对客户的。
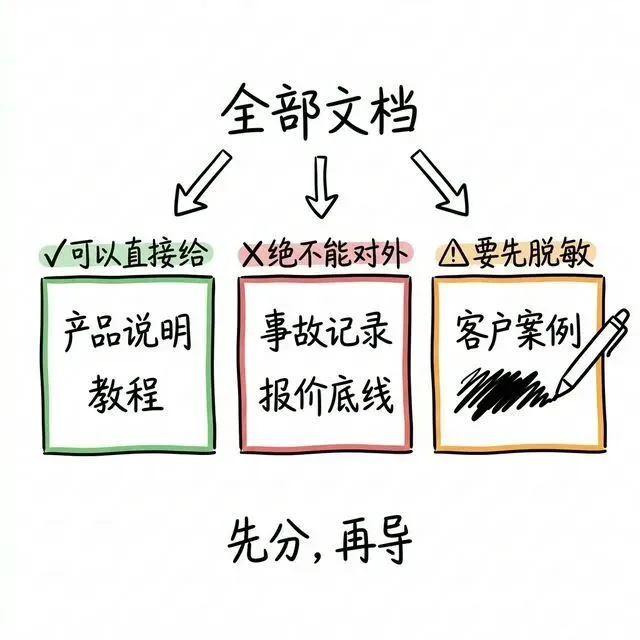
所以知识库上线前,真正该做的第一步不是”导文档”,而是”分文档”。
至少要分成三类:
第一类:可以直接给客户看的。
产品说明、使用教程、常见问题、服务条款。这些导进去没问题。
第二类:对内有用但绝不能对外的。
事故记录、内部复盘、客诉原始记录、报价策略、折扣底线。这些必须从知识库里剔除,一份都不能留。
第三类:灰色地带——看起来可以给,但要脱敏。
比如案例文档里带了客户真名,比如合同模板里有条款细节。这类不是不能用,但必须先把敏感信息去掉再导入。
很多团队出问题,就是因为跳过了”分”这一步,把三类文档混在一起一次性全倒进去了。
知识库跟人不一样。人知道哪些话不该对客户说,因为人有判断力。知识库没有。你喂给它什么,它就拿什么当答案。它不会区分”这份文档是内部复盘”还是”这份文档是产品说明”——在它眼里,全是知识。
所以你的责任不是指望它判断对错,而是确保它能接触到的材料本身就是安全的。
具体怎么做:
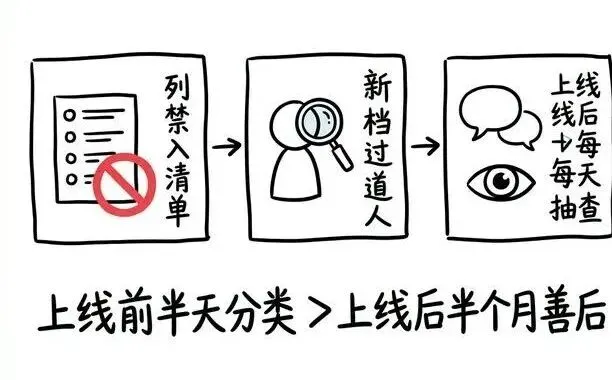
1. 导文档之前,先列一份”禁入清单”。
定义哪些类型的文档绝对不能进知识库。把这份清单写下来,贴在知识库管理入口。不是口头交代,是白纸黑字。
2. 新文档入库要过一道人。
不是所有人都能往知识库里加文档。指定一个人负责确认:这份材料里有没有不该给客户看的内容?
这个审核不需要很复杂,但必须有。没有这一步,知识库会随着时间越来越危险——因为每个部门都觉得”把我们的文档也加进去吧”,加着加着就混进去了。
3. 上线第一周,每天抽查回答。
不是测命中率,而是看:有没有哪条回答里出现了不该出现的信息。价格策略、事故细节、客户姓名——只要出现一次,就说明有文档没过滤干净。
答错了可以补,答慢了可以优化。但答出了不该答的,尤其是涉及内部信息、客户隐私、商业策略,这个后果不是修改一条答案能挽回的。
上线前多花半天做一次文档分类,比上线后花半个月处理一次信息泄露事故,值得得多。
如果你们团队正在搭AI知识库,可以把这篇转给负责导文档的同事。
你们团队上知识库的时候碰到过什么坑?欢迎留言或私信,我在整理更多真实案例。