 夜雨聆风
夜雨聆风





3.26-1|通过扩散解码进行文档解析OCR与逆渲染;怪物猎人基于动作和明确状态的动态世界建模的大型数据集
动态世界建模与文档结构化解析:通过扩散解码进行文档解析OCR与逆渲染;怪物猎人基于动作和明确状态的动态世界建模的大型数据集
MinerU-Diffusion: Rethinking Document OCR as Inverse Rendering via Diffusion Decoding
2026-03-23|Shanghai AI Lab, OpenDataLab, PKU|🔺110
http://arxiv.org/abs/2603.22458v1https://huggingface.co/papers/2603.22458https://github.com/opendatalab/MinerU-Diffusion
研究背景与意义

在数字化浪潮中,文档光学字符识别(OCR)已不再局限于简单的文字转录,而是进化为对复杂版面、表格及公式的深度结构化解析。然而,当前主流的视觉语言模型(VLM)大多深陷于“自回归解码”的泥潭。这种逐字生成的模式如同在一根细绳上行走,不仅处理长文档时效率极低,且一旦前文出错,错误便会如雪崩般累积。更严重的是,这些模型往往过度依赖语言逻辑进行“脑补”,当视觉信号模糊时,它们会根据上下文瞎猜,产生严重的语义幻觉。
本研究的核心目标是打破这种“从左到右”的思维定势。研究者指出,文档解析本质上是一个“逆渲染”过程,即从二维图像还原回一维序列,其生成顺序不应被死板地固定。通过引入扩散模型,本研究旨在回归 OCR “看图说话”的物理本质,在大幅提升解析速度的同时,增强模型对复杂排版的鲁棒性,为高效、精准的文档数字化开辟新路径。
研究方法与创新
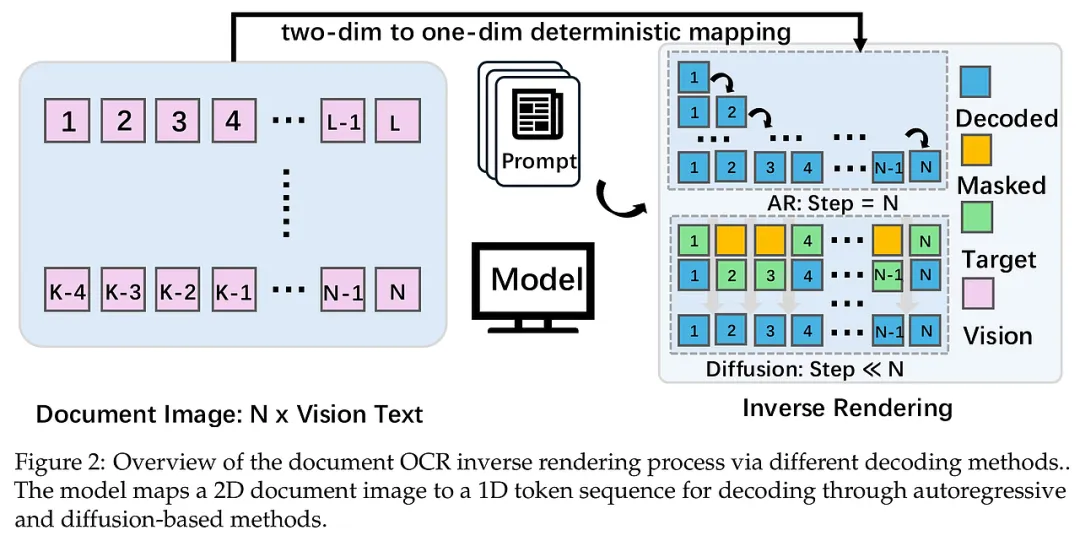
1. 范式重构:从自回归到逆渲染扩散 MinerU-Diffusion 的核心创新在于将 OCR 任务重新定义为基于视觉引导的“逆渲染”问题。传统方法将文字生成视为一种因果链条,而本研究认为,文档中的字符分布更多地取决于空间布局而非单纯的语义先后。因此,模型采用了离散扩散机制(Discrete Diffusion),让所有字符像拼图一样,在全局范围内同时进行迭代修正。这种设计允许模型在推理过程中多次“回头看”并修正之前的错误,彻底解耦了生成顺序与语义理解,强制模型更多地依赖图像本身的视觉证据,而非盲目跟随语言先验。
2. 架构突破:块状扩散解码器(Block-wise Diffusion) 为了解决全局扩散在处理超长文档时计算量呈平方级增长($O(L^2)$)以及位置预测不稳定的问题,研究者提出了一种巧妙的“块状注意力”结构。它将长达数千个 Token 的序列切分为多个连续的块(Block)。在块与块之间,模型保留了粗粒度的因果逻辑,确保了长程解析的稳定性;但在每个块内部,字符则是完全并行生成的。这种“局部并行、全局锚定”的策略,不仅让模型能够利用 KV 缓存(KV-cache)来节省计算资源,还通过块边界有效地约束了空间位置,防止了长文档解析中常见的“定位漂移”现象。
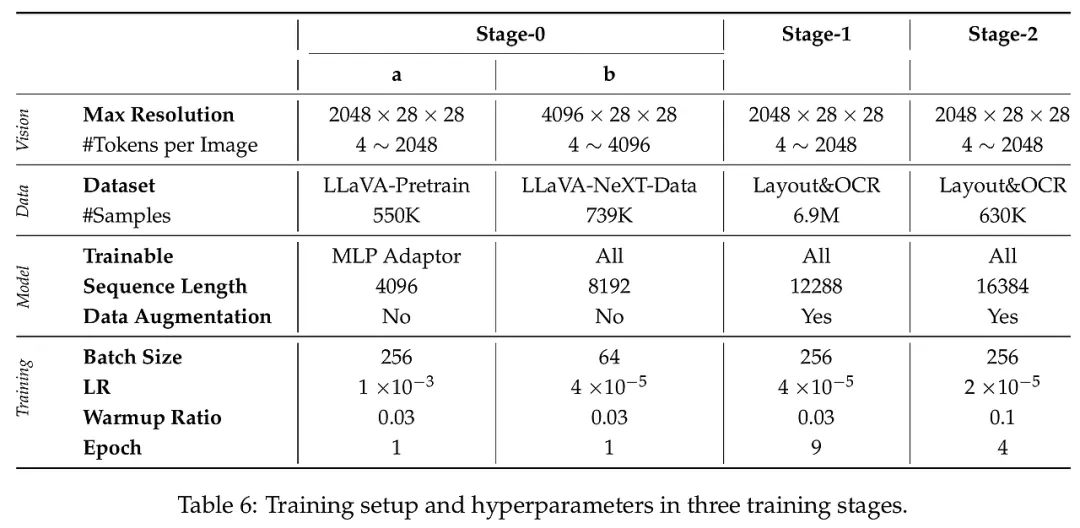
3. 训练策略:不确定性驱动的课程学习 扩散模型的训练往往比自回归模型更难收敛。为此,研究者设计了一套“由浅入深”的两阶段进化方案。第一阶段是“多样性基础学习”,利用海量且风格各异的文档数据,让模型建立起稳健的视觉-语义对齐基础。第二阶段则是“难点攻坚”,即不确定性驱动的精修。模型会通过多次随机推理,找出那些识别结果不一致、预测信心不足的“硬骨头”样本(如模糊的公式、密集的表格边缘),随后引入高精度的人工辅助标注进行针对性微调。这种策略极大地提高了数据的利用效率,使模型在面对复杂边缘案例时具有极高的边界判定精度。
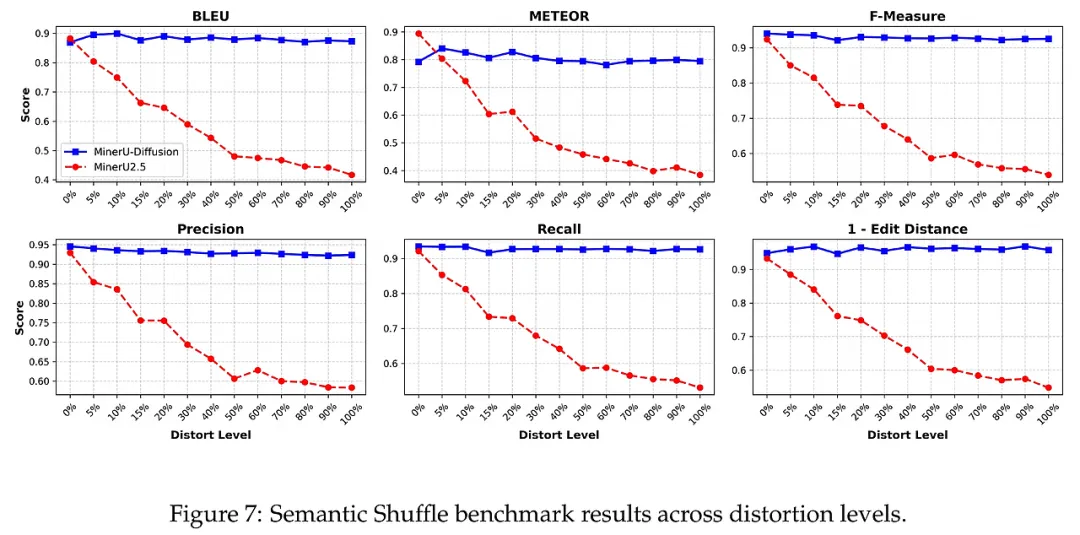
4. 鲁棒性增强:对抗语义幻觉 该方法在处理非逻辑文本(如打乱顺序的表格数据)时展现了显著优势。由于扩散解码不强制要求“上文预测下文”,它能够平稳地处理那些缺乏语义连贯性的视觉符号。实验中提出的“语义洗牌”基准测试证明,当文档的逻辑结构被破坏时,传统的自回归模型往往会因为无法“脑补”而崩溃,而 MinerU-Diffusion 依然能凭借强大的视觉逆渲染能力,精准地还原图像内容。这种对视觉证据的极度尊重,是该方法区别于传统生成式 OCR 的最大技术亮点。
实验设计与结果分析
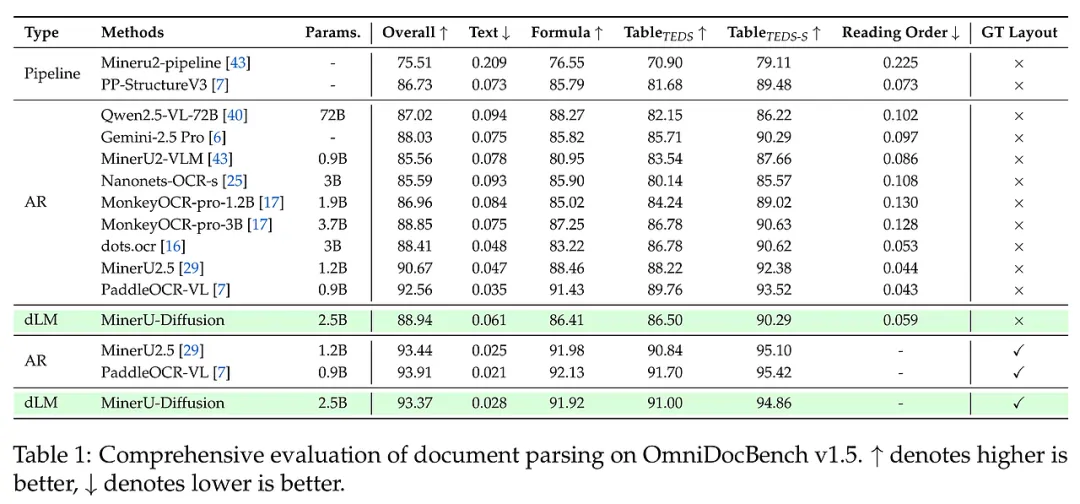
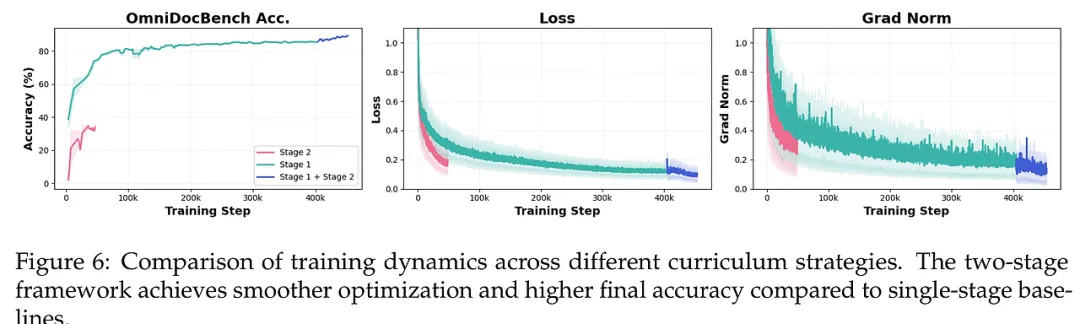
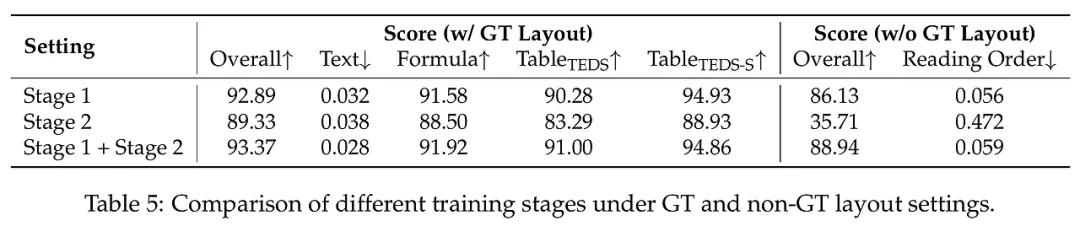
研究团队在 OmniDocBench 等多个权威基准上进行了严苛测试,场景覆盖了学术论文、财务报表、教材及复杂考试试卷。实验结果令人振奋:MinerU-Diffusion 在保持与顶尖自回归模型(如 PaddleOCR-VL)相当的识别准确率的前提下,解码速度实现了质的飞跃,最高提速达 3.2 倍。
在针对表格和公式的专项测试中,该模型凭借并行纠错能力,在 TEDS 和 CDM 等指标上均表现优异。最值得关注的是“语义洗牌”实验:当研究者人为打乱文档的语义逻辑后,自回归模型的性能大幅下滑,而 MinerU-Diffusion 的表现极其稳健。这有力地证明了该模型成功克服了对语言先验的过度依赖,真正实现了以视觉为核心的可靠识别。此外,消融实验证实,动态置信度阈值的引入让模型能在速度与精度之间找到完美的平衡点。
结论与展望
MinerU-Diffusion 的成功标志着文档 OCR 建模范式的重大转型。它证明了扩散模型不仅能画画,在处理高度确定性的符号识别任务时,同样能展现出远超自回归模型的效率与鲁棒性。该研究不仅解决了长文档解析的延迟痛点,更通过“逆渲染”视角为多模态理解提供了新的理论支撑。
尽管表现出色,但模型目前在极端复杂的版面预判上仍有提升空间,部分性能仍受限于前端版面分析的精度。展望未来,研究团队计划进一步优化视觉特征与扩散过程的深度融合,探索在更低算力消耗下实现全页面的全局扩散。这种不依赖“脑补”、纯粹基于视觉证据的解析技术,将成为未来构建通用文档智能系统的基石,推动海量历史文献与专业数据的数字化进程迈向新阶段。
WildWorld: A Large-Scale Dataset for Dynamic World Modeling with Actions and Explicit State toward Generative ARPG
2026-03-24|Shanda AI, BIT, SII, MSU-BIT, THU|🔺66
http://arxiv.org/abs/2603.23497v1https://huggingface.co/papers/2603.23497https://shandaai.github.io/wildworld-project/
研究背景与意义
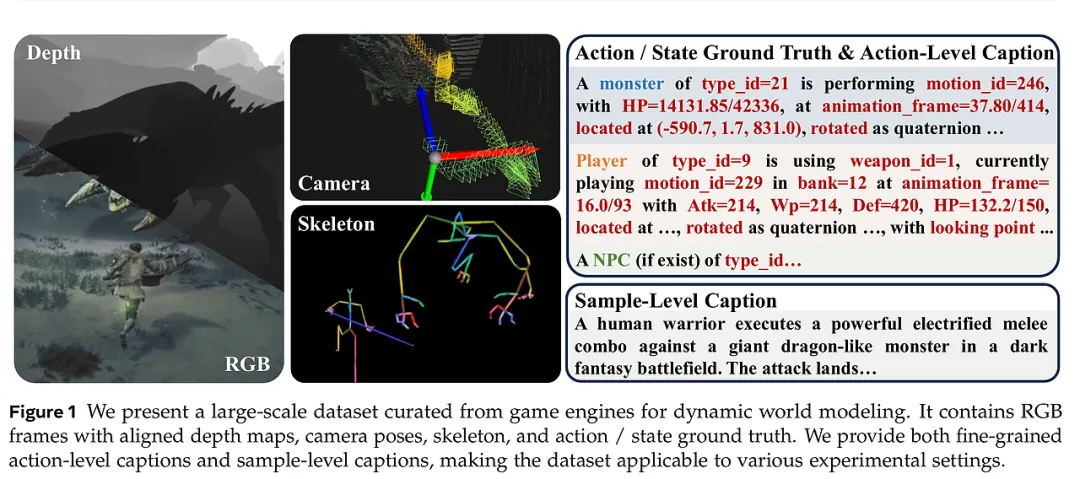
在人工智能迈向通用具身智能的过程中,构建能够理解并预测世界演化的“世界模型”是核心挑战。当前的视频生成模型虽能产出视觉惊艳的片段,却往往在“逻辑一致性”上折戟沉生。究其根源,现有的世界模型训练集大多将动作(Action)与像素变化直接挂钩,忽略了驱动世界演化的深层逻辑——“隐状态(Latent State)”。例如,在游戏中“射击”这一动作的结果,高度依赖于“弹药余量”这一看不见的状态;若缺乏对状态的显式建模,模型便难以在长程预测中维持因果链条的稳定性。
本研究推出的 WildWorld 填补了这一空白。它不仅是一个规模宏大的数据集,更是一次范式革新:通过从顶级 3A 游戏《怪物猎人:荒野》中自动化采集超 1.08 亿帧的高精度数据,并辅以详尽的动作与状态标注,研究者试图为 AI 提供一本关于“物理世界逻辑”的教科书。这不仅对生成式 ARPG 游戏开发具有直接意义,更为构建具备逻辑推理能力的交互式世界模型奠定了数据基石。
研究方法与创新
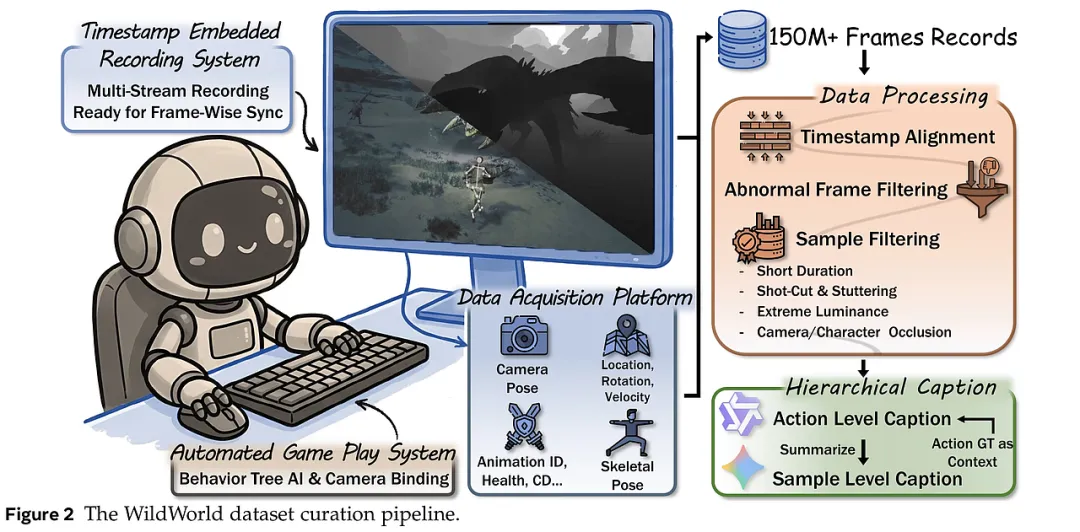
1. 自动化的高保真数据采集架构 研究团队开发了一套精密的工具链,直接植入《怪物猎人:荒野》的游戏引擎底层。不同于传统的视频抓取,该平台实现了“三流合一”的同步记录:
-
动作流(Action Stream): 记录了超过 450 种精细动作,包括复杂的连招、技能释放和环境交互。 -
状态流(State Stream): 实时抓取角色的 3D 骨架、绝对坐标、生命值、耐力值及动画 ID 等底层逻辑变量。 -
观测流(Observation Stream): 包含无 UI 的 RGB 画面、深度图及相机参数。 通过这种方式,研究者成功将“玩家输入-内部逻辑变化-视觉呈现”这一完整的因果链条数字化。为了保证数据的多样性与长程性,团队利用游戏内置的 AI 行为树驱动角色进行自动化战斗,模拟出高维度、非重复的动态交互场景,单段样本时长可达 30 分钟以上。
2. 层次化标注与质量过滤体系 为了让模型更好地理解语义,研究者引入了层次化描述机制。利用 Qwen3-VL 等大模型,对每一段动作序列生成细粒度的描述,并汇总为样本级的摘要。在数据清洗阶段,研究者设计了多维度的过滤器:剔除光照极端、视角遮挡、动作停滞或转场剪辑的无效帧,确保训练数据的纯净度与视觉连贯性。这种对数据质量的极致追求,使得 WildWorld 在动作丰富度(5960 种动作组合)和场景复杂性(5 种地貌、动态天气)上远超同类数据集。
3. 状态感知视频生成模型(StateCtrl) 本研究最显著的技术创新在于提出了 StateCtrl 模型。传统的视频生成模型(如 Sora 类架构)通常只接受文本或简单动作指令,而 StateCtrl 引入了显式的状态注入机制:
-
结构化状态建模: 将离散状态(如武器类型)通过 Embedding 映射,将连续状态(如 HP、位置)通过 MLP 编码。 -
实体关系推理: 采用 Transformer 架构建模玩家、怪物与环境实体间的交互关系,生成统一的状态嵌入向量。 -
自回归状态预测: 模型不仅能根据当前状态生成视频,还包含一个状态预测器,能够自回归地推演下一帧的状态。这种“状态驱动生成”的模式,使得模型在长程演化中能够依据逻辑(如 HP 归零则触发死亡动画)而非仅仅依赖像素外推,极大地提升了生成的物理合理性。
4. 评测范式的革新:WildBench 研究者指出,传统的视觉质量指标(如 FVD)无法衡量世界模型的“交互灵魂”。为此,他们提出了 WildBench 评测基准,核心包含两个维度:
-
动作遵循(Action Following): 利用多模态大模型判断生成的视频是否准确执行了输入的动作指令。 -
状态对齐(State Alignment): 通过追踪视频中的骨架关键点,并与真实状态轨迹进行对比,量化模型对物理逻辑的还原程度。这种从“看起像”到“做得对”的评测转变,为世界模型的研究指明了客观方向。
实验设计与结果分析
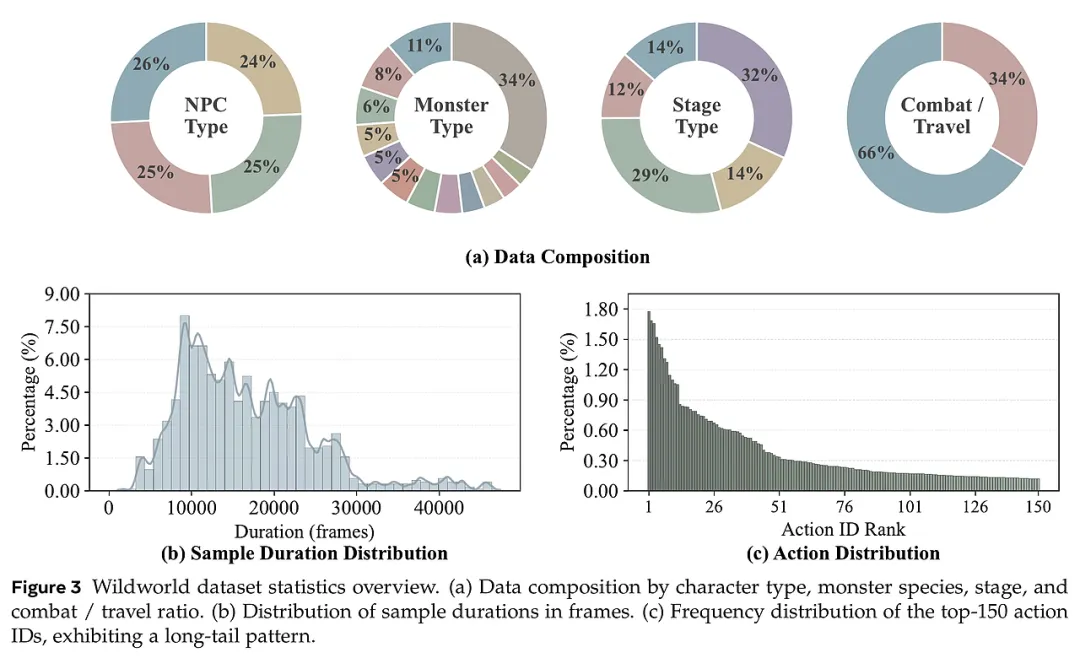

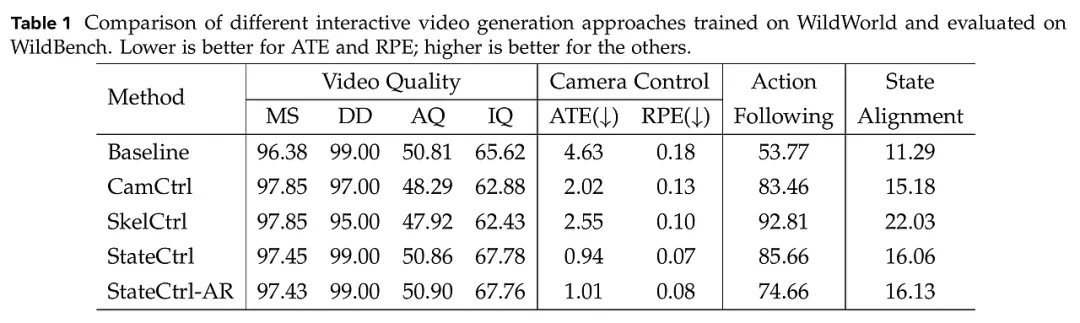
研究团队在 WildBench 上对比了多种前沿方案,包括相机控制(CamCtrl)、骨架控制(SkelCtrl)及本研究提出的状态控制(StateCtrl)。实验结果揭示了几个深刻的洞察:
首先,显式控制显著优于通用生成。相比于基准模型,所有引入交互控制的模型在动作遵循度上都有大幅提升。其中,SkelCtrl 在动作准确性上表现最佳,因为它直接获得了最精细的运动引导;而 StateCtrl 则在视觉质量与逻辑一致性之间取得了更好的平衡。
其次,现有模型在长程语义理解上仍存在巨大鸿沟。尽管模型在短期动作(如单次挥剑)上表现良好,但在涉及复杂逻辑(如根据剩余体力决定是否能发动大招)的长序列生成中,依然会出现状态漂移。实验数据表明,StateCtrl-AR(自回归版本)虽然展现了自主推演世界的潜力,但误差累积问题仍是制约其完美复现复杂 ARPG 逻辑的瓶颈。这证明了 WildWorld 数据集极具挑战性,足以作为下一代交互式 AI 的“磨刀石”。
结论与展望
《WildWorld》不仅是目前规模最大、标注最详尽的交互式世界模型数据集,它更深刻地揭示了“状态显式化”是通往高保真物理模拟的必经之路。通过将 3A 级游戏的复杂逻辑转化为可学习的标注,研究团队为生成式 AI 开辟了一个全新的战场:从简单的像素预测转向深刻的动力学模拟。
未来展望: 随着该数据集的开源,我们有望看到“AI 原生游戏”的雏形——即游戏世界不再由预设的代码驱动,而是由一个理解状态演化的生成式模型实时构建。未来的研究方向将聚焦于如何进一步降低自回归预测的累积误差,以及如何将这种从虚拟游戏中习得的复杂交互逻辑迁移到现实世界的机器人控制中。WildWorld 的出现,标志着世界模型的研究正从“看图说话”的初级阶段,迈向“逻辑自洽”的深水区。