 夜雨聆风
夜雨聆风





我在ClaudeCode源码学习AI编程产品的真正护城河
我在ClaudeCode源码学习AI编程产品的真正护城河
2026年4月1日,阿东去翻了那份从 cli.js.map 还原出来的 Claude Code 2.1.88 源码。
我不是单纯去吃瓜的。我更想搞清楚一件事:为什么同样是调大模型 API,有些 AI 编程工具像在“跟你一起干活”,有些却还是一个会写代码的聊天机器人?
看完之后,我有个越来越强的判断:
AI 编程产品下一阶段的竞争,不在模型层,而在运行时层。
模型当然重要,但源码给我的感觉是,Claude Code 真正厉害的地方,不是让模型更聪明,而是把模型放进了一套很成熟的“上班系统”里。这个系统负责定边界、控风险、压成本、管上下文、管协作。模型像一个能力很强但不稳定的新同事,Claude Code 则像一个把流程、制度、权限、工位、会议机制都配齐了的组织。
如果只看表面,你会以为 Claude Code 是一个 CLI。再往里看一层,它其实更像一个 AI 时代的轻量操作系统。
我把这次读源码最大的收获,归成 4 条护城河。
一、第一条护城河不是 Prompt,而是治理层
我以前会本能地觉得,AI 编程工具的核心差异主要在 prompt。谁的 system prompt 写得更好,谁的效果就更稳。
但 Claude Code 的源码让我改观了。
它当然有很长的系统提示词,而且还专门用 SYSTEM_PROMPT_DYNAMIC_BOUNDARY 把提示词切成静态区和动态区。静态部分走全局缓存,动态部分再按用户、目录、记忆、MCP 配置去拼。这个设计已经很细了。
但真正更重要的,不是“告诉模型怎么做”,而是“规定模型什么时候不能乱做”。
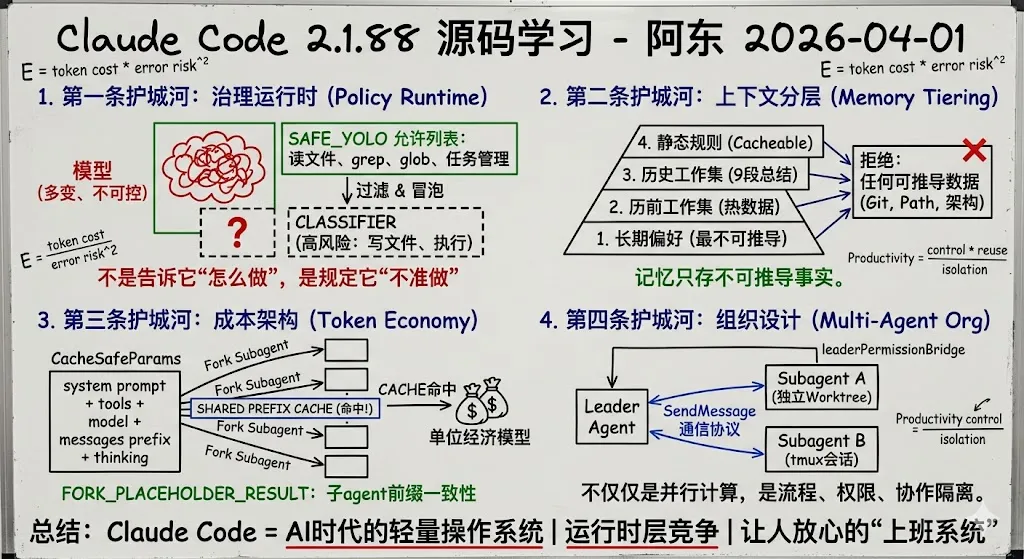
源码里权限系统的存在感非常强。比如自动模式里,先有一层 SAFE_YOLO_ALLOWLISTED_TOOLS,把读文件、grep、glob、任务管理这种低风险操作直接放行。再往上,才进入 classifier。也就是说,它不是粗暴地“全部拦住”,而是先把低风险流程标准化,再把高风险动作治理化。
这个顺序非常关键。
很多人做 agent,会把重点放在“让 AI 多做点事”。Claude Code 的思路更像:先定义什么是可以稳定自动化的,再定义什么必须上审查。
这背后其实是一套治理哲学:
-
低风险动作要尽量自动化,否则用户会被频繁打断。 -
高风险动作要可解释、可追踪、可拒绝,否则用户不敢给权限。 -
一旦用户拒绝,系统要把这次拒绝当成真实信号,而不是继续硬闯。
这也是为什么我现在越来越觉得,Auto mode 的核心不是“模型胆子大”,恰恰相反,是系统先假设模型会犯错。
只有先承认它会犯错,你才会去设计 allowlist、审查器、拒绝记录、权限冒泡这些基础设施。没有这层治理,模型越强,破坏力越大。
所以第一条护城河不是 prompt engineering,而是 policy runtime,也就是治理运行时。
二、第二条护城河不是长上下文,而是上下文分层
这是我读源码时最受启发的一点。 很多人聊 agent,都在卷“上下文越长越好”“记忆越多越好”。
Claude Code 的设计完全不是这个方向。它不是把所有东西都塞给模型,而是把上下文当内存做分层管理。
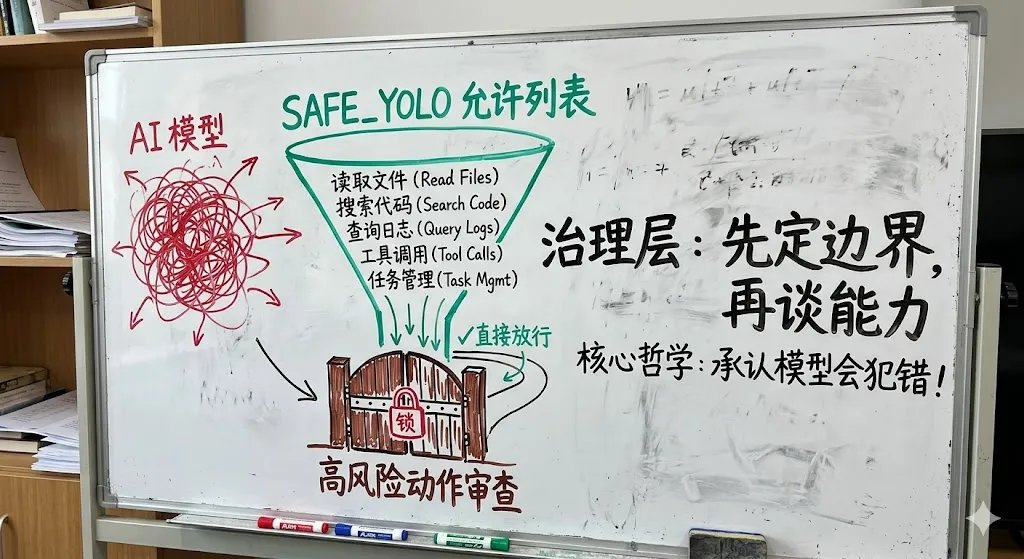
我后来回头看,源码里几乎每个地方都在做这件事。 第一层,是可缓存的静态规则。比如 system prompt 里那些所有用户共享的行为规范、工具说明、输出风格,它们被尽量放进静态前缀里,让后续请求复用缓存。
第二层,是当前会话的工作集。当前目录、工作树、用户配置、最近的消息,这些是当前任务真正需要的“热数据”。
第三层,是历史压缩。compact/prompt.ts 里那套 9 段式总结,不是普通的“总结一下前文”,而是强制要求保留用户请求、技术概念、文件代码、错误修复、所有用户消息、待办任务、当前工作和下一步。这个结构特别像操作系统里的页表和快照,不是为了优雅,而是为了下次继续干活别丢状态。
第四层,才是长期记忆。
而长期记忆最让我佩服的地方,是它规定了 ==什么不能记==。
memoryTypes.ts 里直接写得很死:代码模式、架构、文件路径、项目结构、git 历史、临时任务状态,都不应该进 memory。因为这些东西是“可推导的”,应该去现读代码、现看 git,而不是存在记忆里赌它不会过期。
这背后其实是一句很重的话,记忆只存不可从当前项目状态推导出来的事实。
这和很多人理解的“AI 记忆”完全不一样。很多产品会把一切都往记忆里塞,结果看起来是更聪明了,实际上是越来越不可靠。Claude Code 恰恰反过来,宁可少记,也不愿记错。
甚至连记忆整理都做成了后台任务。autoDream 的默认门槛是距离上次整理超过 24 小时、且积累至少 5 个新会话。这个功能名字很浪漫,但工程上特别克制。它不是每轮都整理,不是随时都“自我进化”,而是在合适的低谷期做 consolidation。
我以前把上下文理解成“聊天记录 + 一点 memory”。
读完源码后,我更愿意把它理解成一套内存层级:
-
静态规则层 -
当前工作集 -
历史压缩层 -
长期偏好层
真正体验好的 agent,不是因为它“记得多”,而是因为它知道什么该放缓存,什么该放摘要,什么该现查,什么才值得长期记住。
三、第三条护城河不是功能多,而是成本被写进了架构
这是我以前最容易忽略的点。 我们平时说 token 成本,常常把它当成财务指标。
但在 Claude Code 这里,成本根本不是财务问题,而是架构问题。
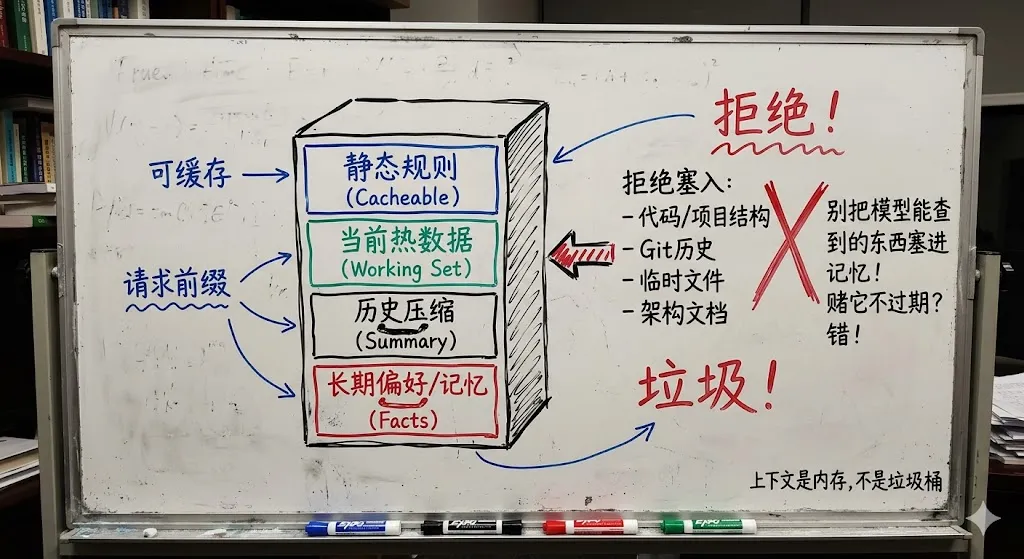
源码里反复出现一个概念:CacheSafeParams。
意思很直接,所有会影响 prompt cache 命中的关键参数,都要保持和父请求一致。system prompt、tools、model、messages prefix、thinking config,只要这些字节级一致,很多后台 fork 出来的 agent 就能共享前缀缓存。
这不是“优化一下性能”那么简单,它直接决定了产品能力边界。
为什么 Claude Code 敢在后台做 memory extraction、prompt suggestion、auto dream、fork subagent?一个核心原因就是,它把这些后台动作尽可能设计成 cache-friendly。
最绝的一处,是 forkSubagent.ts 里的 FORK_PLACEHOLDER_RESULT。
子 agent 继承父 agent 上下文时,工具结果不是原样复制,而是统一替换成同一个占位文本:Fork started — processing in background。这样一来,不同子 agent 的请求前缀就更容易做到字节级一致,缓存命中率更高。
这套设计给我的触动很大。
很多产品经理会把“成本优化”理解成事后节流,但在 AI 产品里,成本优化其实决定了你敢不敢做某个 feature。后台 agent 能不能常开,多任务能不能默认启用,长会话能不能不心疼,根源都不是前端按钮怎么摆,而是底层缓存和请求前缀有没有被好好设计。
换句话说,单位经济模型本身就是产品体验的一部分。
这也是为什么我现在越来越相信一件事:同样一个模型,谁把缓存、前缀稳定性、请求结构设计得更好,谁就能把“高级能力”做得更像默认能力。
用户感知到的是“这个工具真顺手”,背后其实是“这家公司把 token 账算明白了”。
四、第四条护城河不是多 Agent,而是组织设计
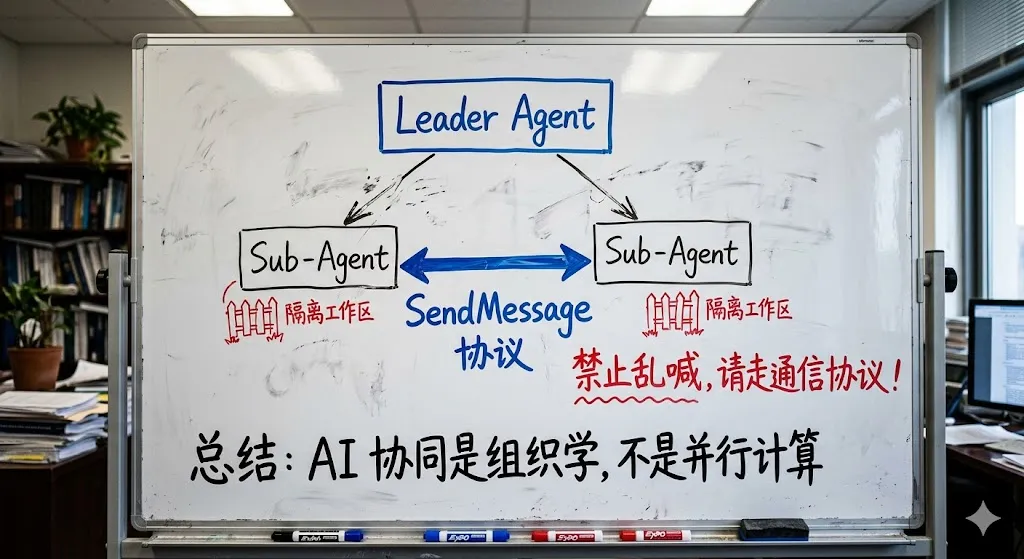
现在很多人一聊多 agent,就会很兴奋地说:可以并行了,可以同时开 5 个任务了。
但 Claude Code 的源码让我意识到,多 agent 的真正难点,从来不是“开多少个”,而是“这些 agent 怎么像一个组织一样协同”。
TEAMMATE_SYSTEM_PROMPT_ADDENDUM 里有句很硬的话:如果你只是输出普通文本,团队里的其他 agent 是看不到的,你必须用 SendMessage 才能通信。
这句话看似简单,实际上是在明确组织沟通协议。
再比如 leaderPermissionBridge.ts,队员遇到权限问题,不是直接乱弹给用户,而是通过 leader 的桥接机制统一处理。这其实就是现实公司里的升级路径。普通成员遇到卡点,先往上冒泡,不是所有人都直接找老板。
还有 worktree 设计也很有意思。源码里不仅支持为任务创建独立 worktree,还专门处理了 slug 校验、路径逃逸、node_modules 软链接、tmux 会话命名这些工程细节。它不是把“并行开发”理解成多开几个线程,而是把它落到了物理隔离的工作副本上。
这意味着什么?
意味着 Claude Code 在把 agent 当“同事”而不是“函数调用”。
同事之间需要:
-
明确分工 -
固定通信协议 -
统一的权限升级路径 -
彼此隔离的工作空间 -
最终由 leader 汇总结果
如果没有这些,多 agent 只会带来更多噪音、上下文污染和冲突写入。
所以我现在看多 agent,有个很强的感受:
它首先是组织工程,其次才是并行计算。
这也是为什么很多“多 agent demo”看起来很炫,但真放进生产环境就很难用。因为它们只解决了“能同时跑”,没解决“同时跑的时候怎么不互相伤害”。
最后:为什么我说它更像操作系统
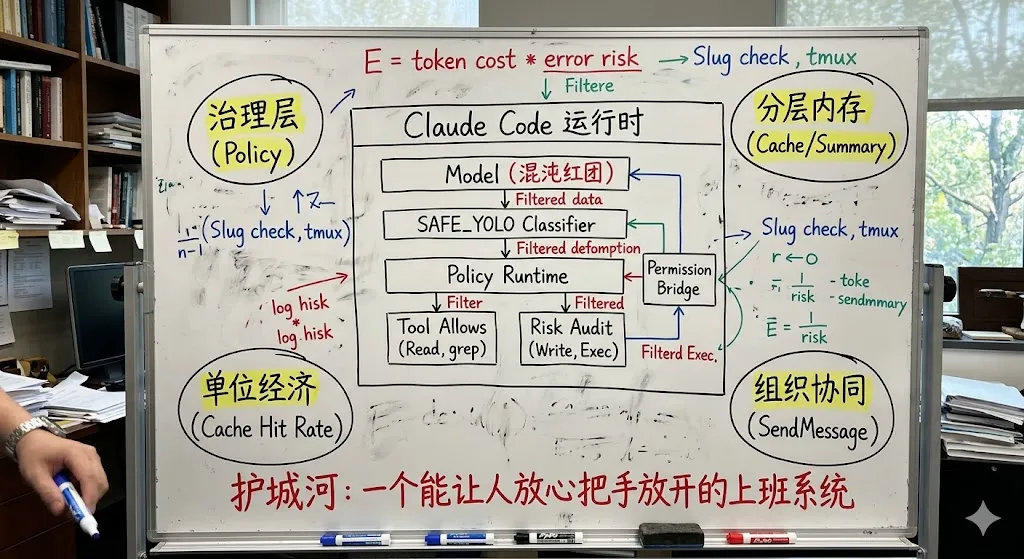
如果把这 4 条护城河放在一起看,Claude Code 源码给我的最大启发其实不是某个功能细节,而是一个更大的产品判断:
AI 编程工具正在从“聊天产品”演化成“运行时产品”。
聊天产品的核心是回答质量。
运行时产品的核心是:
-
怎么定边界 -
怎么分层管理上下文 -
怎么把成本写进架构 -
怎么组织多个 agent 一起干活
这几个问题一旦成立,产品的竞争逻辑就变了。
下一阶段真正拉开差距的,不会只是“你接的是 Claude 还是 GPT”,而是你有没有把治理层、内存层、经济层、组织层做出来。
我自己是做大模型和独立开发的。以前我也容易把注意力放在模型能力、prompt 手法、tool calling 这些表层能力上。看完 Claude Code 源码,我反而更确定:真正值钱的,不是让模型多做一点,而是让模型在一个可控、可持续、可复用的系统里稳定地做对事。
这大概就是 AI 产品真正的护城河。
不是更像人。
而是更像一个能让人放心把工作交出去的系统。
{"target":"简单认识我","selfInfo":{"genInfo":"OPC,中科院自动化所硕士,从事数据闭环业务、RAG、Agent等,承担技术+平台的偏综合性角色。善于调研、总结和规划,善于统筹和协同,喜欢技术,喜欢阅读新技术和产品的文章与论文","contactInfo":"abc061200x, v-adding disabled","slogan":"简单、高效、做正确的事","extInfo":"喜欢看电影、喜欢旅游、户外徒步、阅读和学习,不抽烟、不喝酒,无不良嗜好" } }