 夜雨聆风
夜雨聆风





微调大模型终于被做成了「Web App」:100+模型、一张显卡、不写代码,近7000人疯狂收藏!
【导读】一个开源项目把微调大模型这件事,从「写几百行训练脚本」变成了「打开浏览器点点按钮」。LlamaFactory 支持 100+ 主流大模型、覆盖 LoRA/QLoRA/DPO/PPO 等几乎所有训练方法,用一张消费级显卡就能跑起来。一条推文拿下4200+ 点赞、近 7000 人收藏,有人直呼:「这就是大模型界的 Automatic1111!」
一条推文引爆全网:4254 赞、6877 收藏
2025 年 5 月 24 日,AI 博主 Avi Chawla 在 X 上发了一条推文。
内容很简单——
“Fine-tune 100+ LLMs directly from a UI!”
「直接通过用户界面微调 100 多个 LLM!」
就这一句话,配一段 LlamaFactory Web UI 的演示视频。
4254 个赞。587 次转发。6877 人收藏。

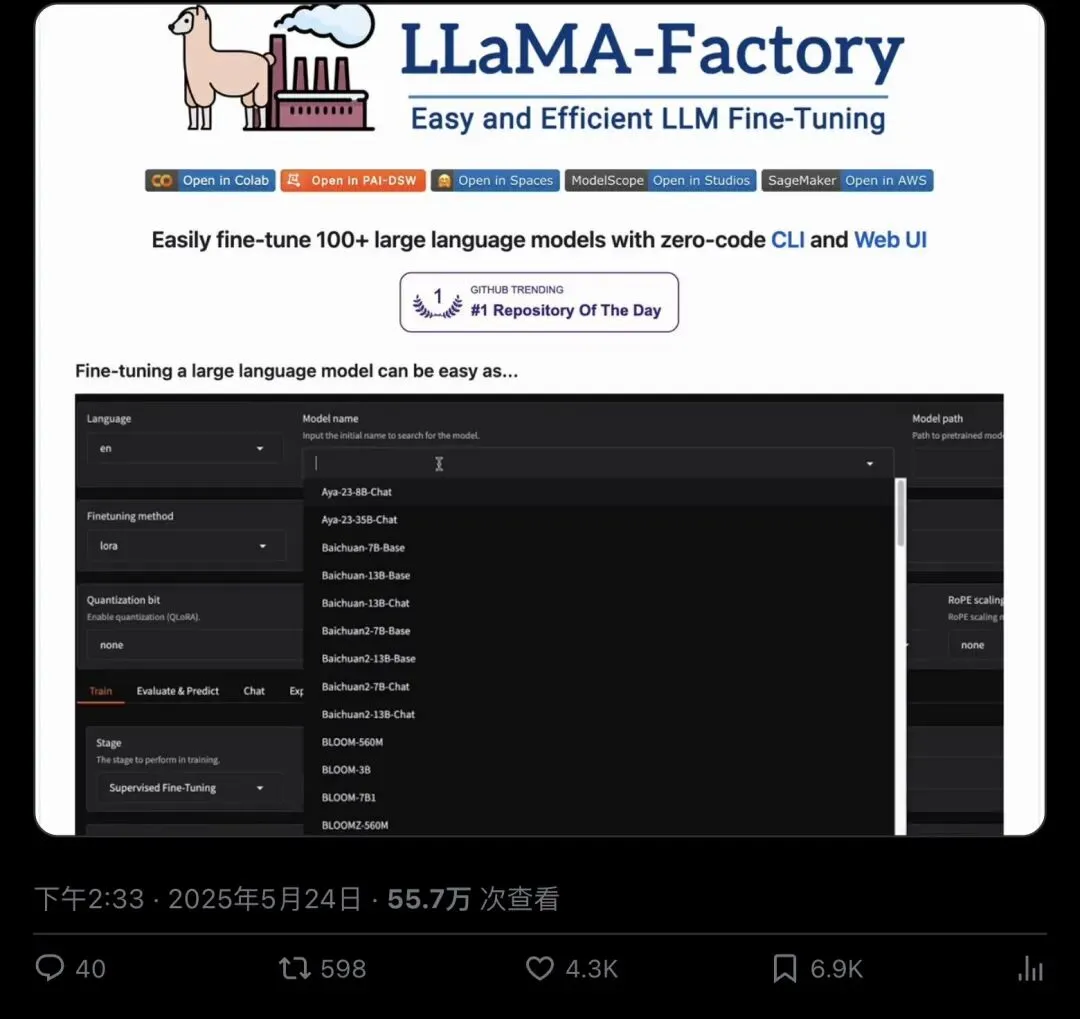
▲ Avi Chawla(@_avichawla)的推文,55.7 万次查看,近 7000 人收藏
这不是一个新项目的发布。LlamaFactory 已经存在快两年了。但这条推文戳中了所有 AI 开发者的痛点:微调大模型,真的太折腾了。
写训练脚本、配 YAML、装各种依赖、处理 OOM 报错、模型不收敛了反复调参……每一步都在劝退。
而 LlamaFactory 说:这些,我全包了。你只管打开浏览器。
这玩意到底是什么?
LlamaFactory(项目名 LLaMA-Factory)是北航研究者郑耀威(GitHub:hiyouga)主导开发的开源微调平台。
一句话概括:它把「微调大模型」这件需要写代码的工程活,做成了「填表单 + 点按钮」的产品。
官方 README 原话:
“Easily fine-tune 100+ large language models with zero-code CLI and Web UI”
「通过零代码的命令行和 Web UI,轻松微调 100 多个大语言模型。」
arXiv 论文标题更直白——《LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models》,把「100+」直接写进了标题。2024 年被 ACL(计算语言学顶会)接收为系统演示论文。
GitHub 星标超过6.9 万,265 位贡献者,被 NVIDIA、Amazon 等企业在生产环境中使用。
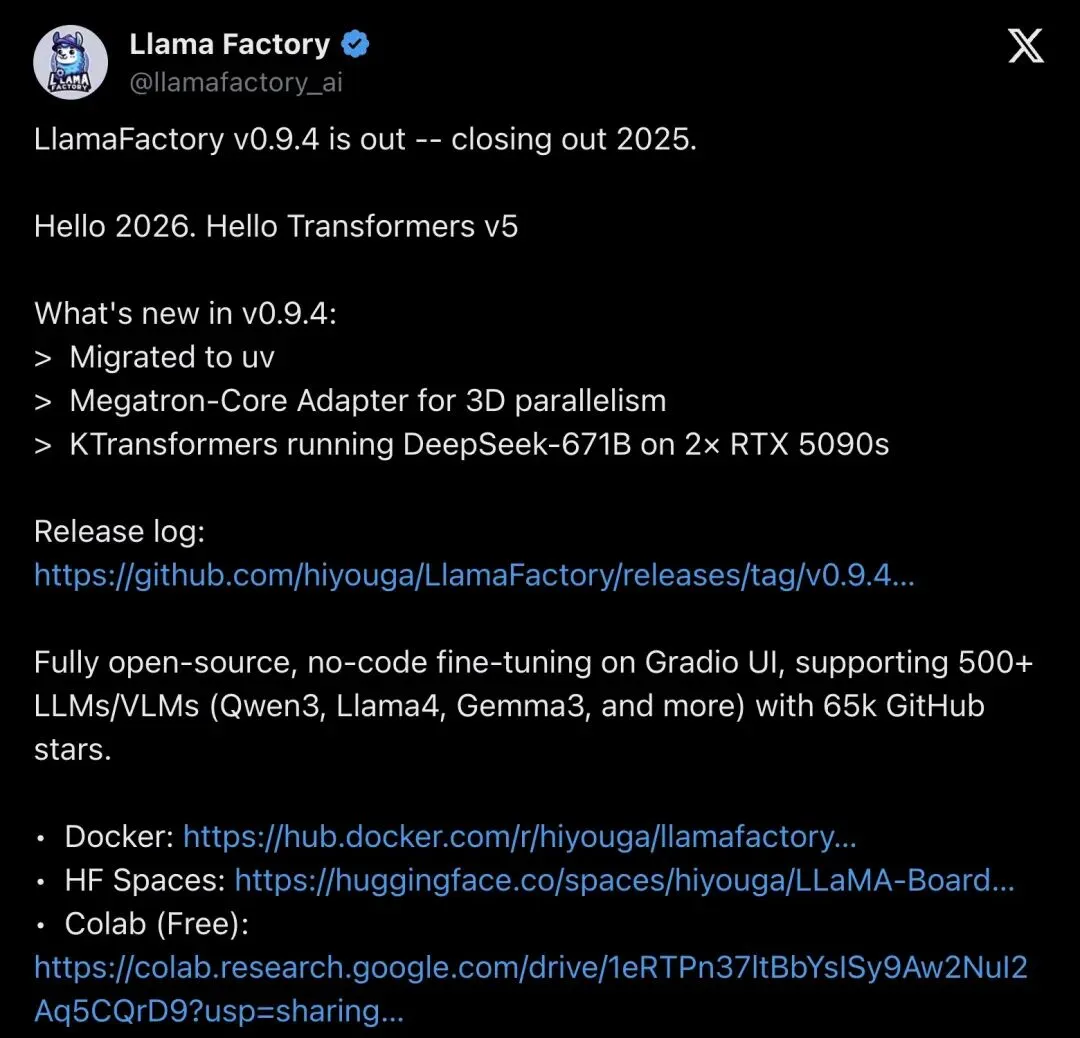
▲ LlamaFactory 官方推文,宣布 v0.9.4 版本发布,支持 500+ 模型
「单张消费级 GPU」到底怎么做到的?
先泼一盆冷水:不是所有 70B 大模型都能在一张 4090 上随便训。
但 LlamaFactory 的核心策略是:把省显存的技术栈产品化了。
关键词是两个——LoRA和QLoRA。
打个比方:全参数微调就像「重写整本书」,LoRA 是「在书旁边贴一小叠便签」——只训练极小一部分参数,显存需求暴降。QLoRA 更狠,先把模型压缩到 4-bit 精度再训练。
效果有多夸张?看 README 里的官方显存表:
|
|
|
|
|
|---|---|---|---|
|
|
120GB |
|
|
|
|
6GB | 12GB | 48GB |
|
|
4GB | 8GB | 24GB |
7B 模型 + QLoRA 4-bit = 6GB 显存。一张 GTX 1660 Ti 就够了。
14B 模型只要 12GB——一张 RTX 3060 搞定。
当然,README 也很诚实地写了:「FSDP+QLoRA fine-tunes a 70B model on2x24GBGPUs」——70B 级别即使压缩也需要两张 24GB 卡。
它没有神化「单卡」,但确实把「消费级 GPU 能做微调」这件事从理论变成了现实。

▲ 中文圈 @aigclink 的传播帖,1.2 万次查看,138 人收藏
Web UI 才是真正的「破圈杀器」
LlamaFactory 支持的功能列表长到让人窒息:
-
训练方法:SFT(指令微调)、DPO、PPO、KTO、ORPO、SimPO…… -
效率方案:LoRA、2/3/4/5/6/8-bit QLoRA、FlashAttention-2、Unsloth…… -
模型支持:LLaMA、Qwen、Mistral、DeepSeek、Gemma、Phi、Yi……
但真正让它「出圈」的,不是功能多。
是它把这些复杂到让人头秃的选项,做成了下拉框和输入框。
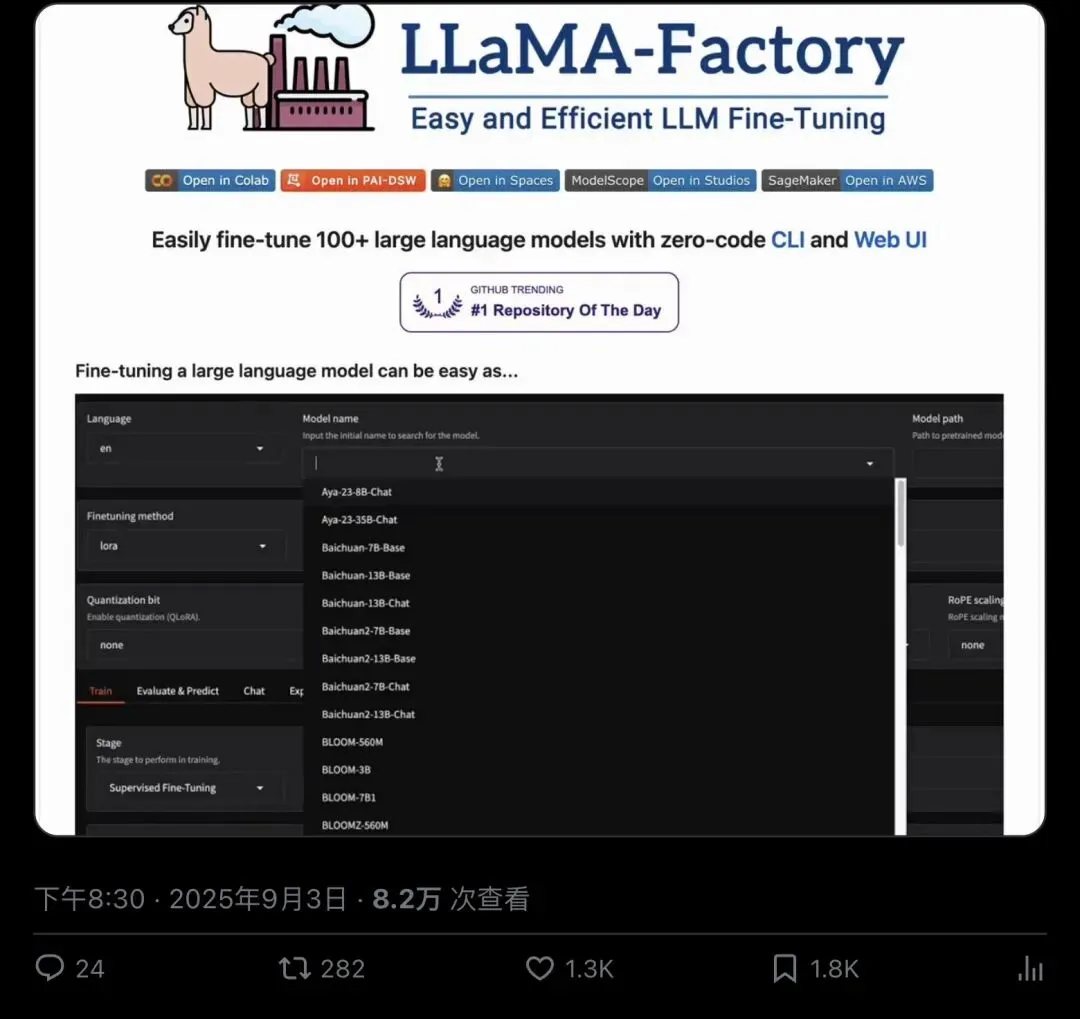
官方博客教程里,启动 Web UI 只需要一条命令:
“` llamafactory-cli webui “`
然后你就进入了一个 Gradio 页面——选模型、选训练方法(LoRA/QLoRA)、配学习率和 epochs、挂数据集、点开始训练。
整个过程不需要写一行 Python。
训练完了?还有下一步:
“` llamafactory-cli chat # 跟你微调的模型对话 llamafactory-cli export # 导出模型 “`
甚至可以直接从 UI 导出到 Ollama 和 vLLM,训完直接本地部署。
这不是训练脚本,这是一个完整的「微调工作流产品」。
「大模型界的 Automatic1111」
有一条推文说得最到位。
X 用户 @techNmak 写道:
“Fine-tuning an LLM used to require a PhD. Now it takes 3 clicks.” “I found the tool that democratizes custom models. It’s called LlamaFactory.”
“It is the ‘Automatic1111’ for Large Language Models.”
「微调 LLM 以前需要博士学位。现在只要点三下。」
「我找到了一个让所有人都能定制大模型的工具。它叫 LlamaFactory。」
「它就是大语言模型界的 Automatic1111。」


▲ @techNmak 把 LlamaFactory 比作「大模型的 Automatic1111」,1.8 万次查看
这个类比太精准了。
2023 年,Stable Diffusion 的 Automatic1111 WebUI 让「AI 画图」从程序员的命令行走进了每个人的浏览器。
2025 年,LlamaFactory 正在对「AI 微调」做同样的事。
推特上的集体复读:同一个「爆点公式」
翻一遍 X 上关于 LlamaFactory 的高赞帖子,你会发现一个有趣的现象——几乎所有爆款帖都在用同一个模板。
公式大概是这样的:
「Fine-tune 100+ LLMs」+「directly from a UI / no code」+「supports PPO/DPO/…」+「open-source + 很多 stars」
▲ @akshay_pachaar 的帖子,8.2 万次查看,1.8K 人收藏
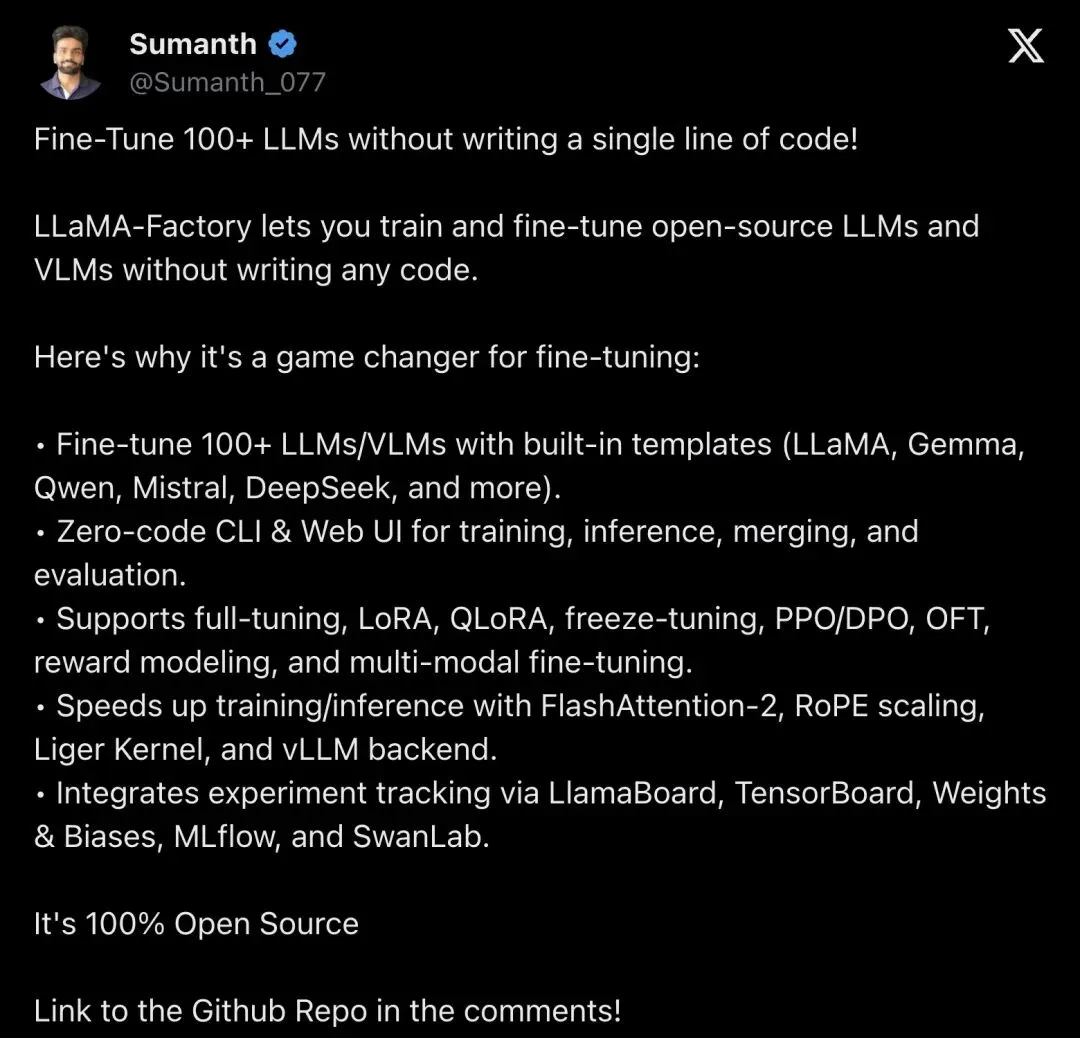

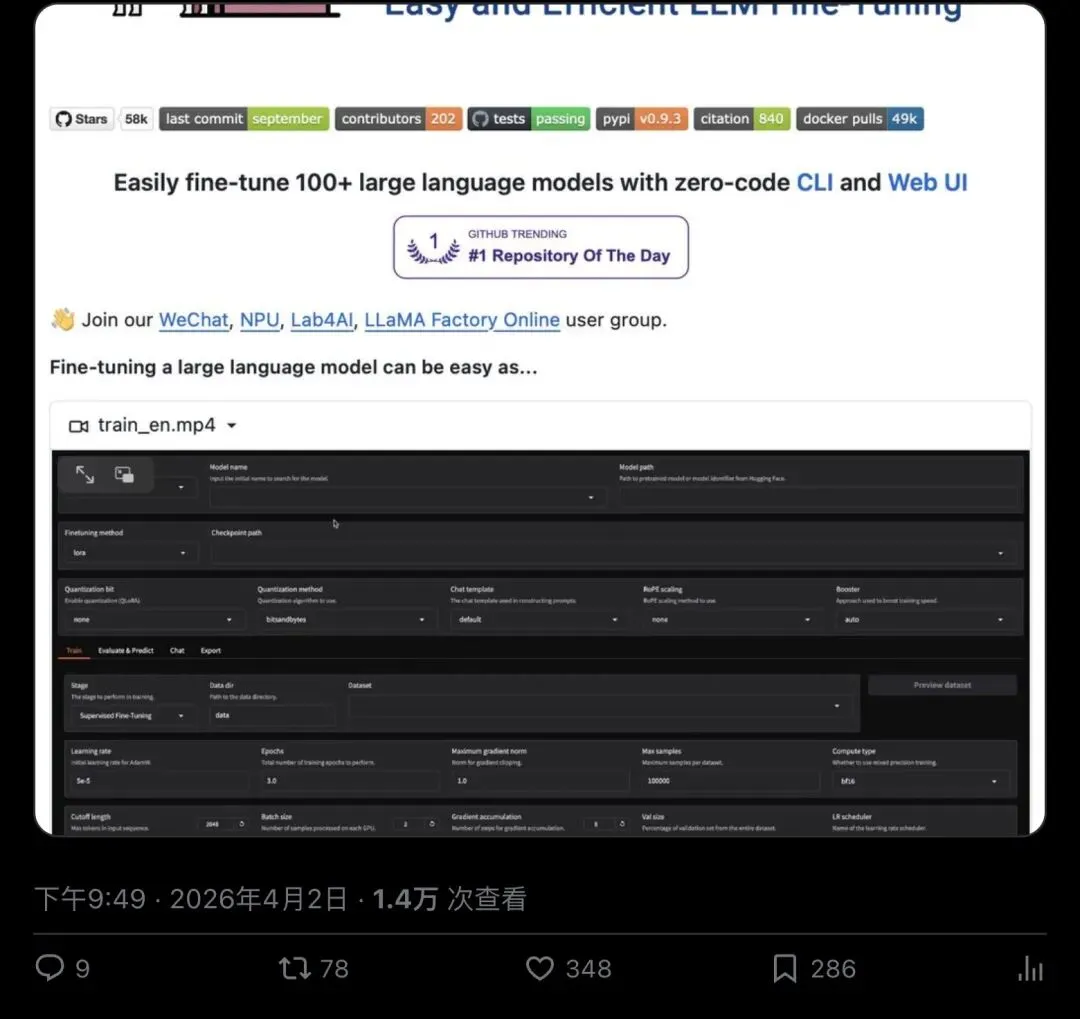
▲ @Sumanth_077 的功能详解帖,1.4 万次查看
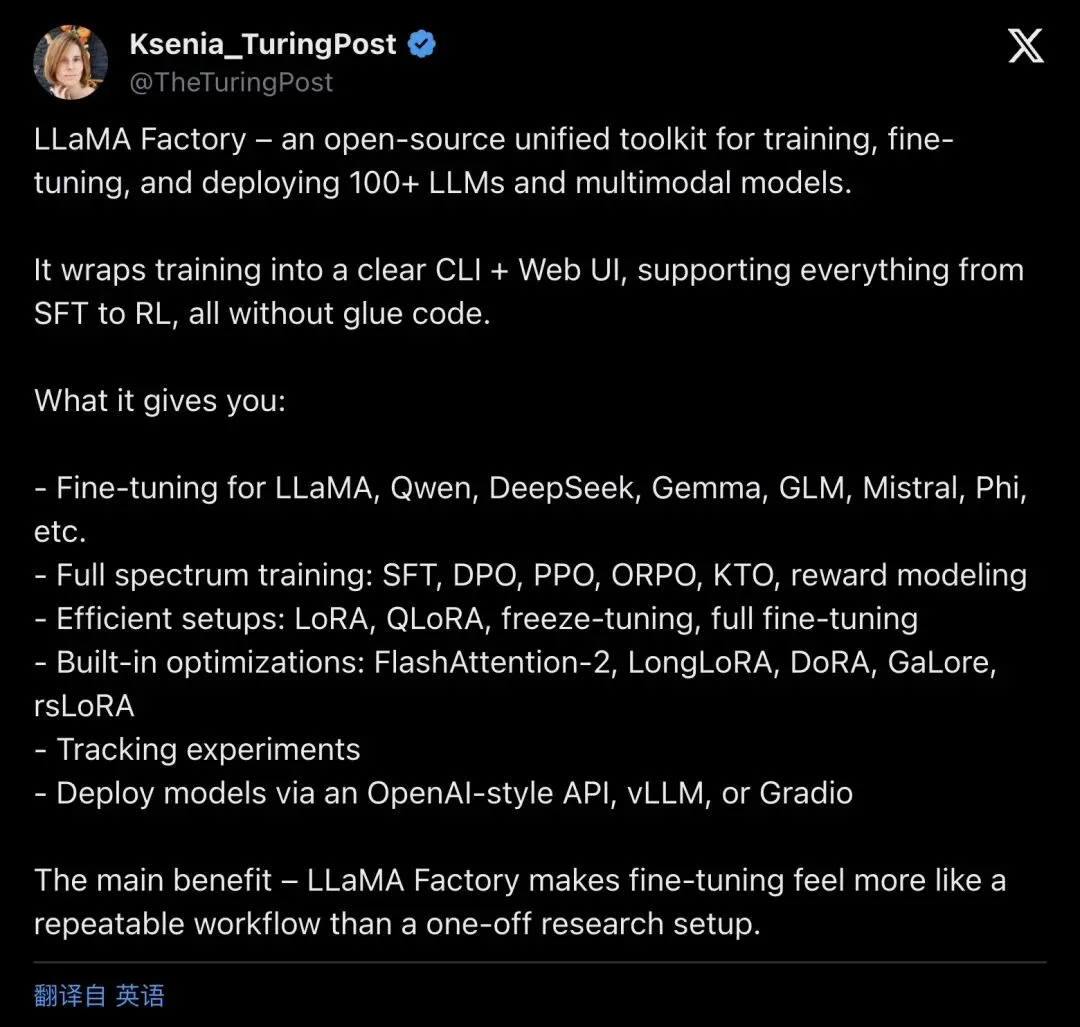

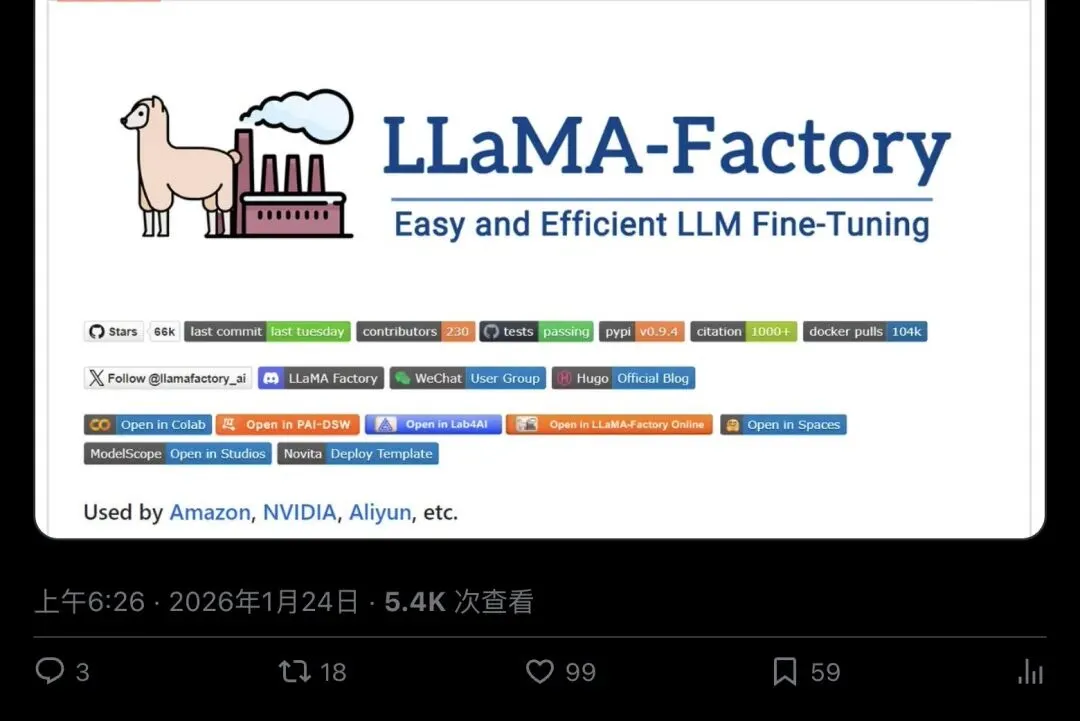
▲ 科技媒体 @TheTuringPost 的报道,5400 次查看
为什么同样的内容反复被传播?
因为 LlamaFactory 的核心卖点太好「复述」了——「100 个模型 + 一个界面 + 不写代码」,任何人在推文 280 字以内都能把故事讲完。
好产品自带传播力。当你的价值主张能用一句话说清楚,每个用户都会成为你的营销团队。
社区的另一面:「别太天真了」
Reddit 和 Hacker News 上的讨论,提供了更冷静的视角。
在 Reddit r/LocalLLaMA 社区,有人把 LlamaFactory 和 Axolotl(另一个微调框架)放在一起比较,认为 LlamaFactory「更流畅」(more streamlined)。但也有人追问:「为什么它在这个圈子没那么火?」
回答很直白:
“Marketing, lack of guides, ignorance?”
「营销不够、教程不全、信息茧房。」
Unsloth 的作者 danielhanchen 在另一个帖子里给了正面评价:
“Llama Factory … pretty cool for a UI for finetuning! … includes my OSS package Unsloth … 2.2x faster and use 62% less memory!!”
「LlamaFactory 的微调 UI 挺酷的!集成了我的 Unsloth,速度快 2.2 倍,显存省 62%!」
而 Hacker News 上的工程师们则更直接:
「别只看 fine-tune,它也支持 pre-training、reward model、RL。但——要好效果可能需要很强硬件。家用的话建议从小模型、窄任务开始。」
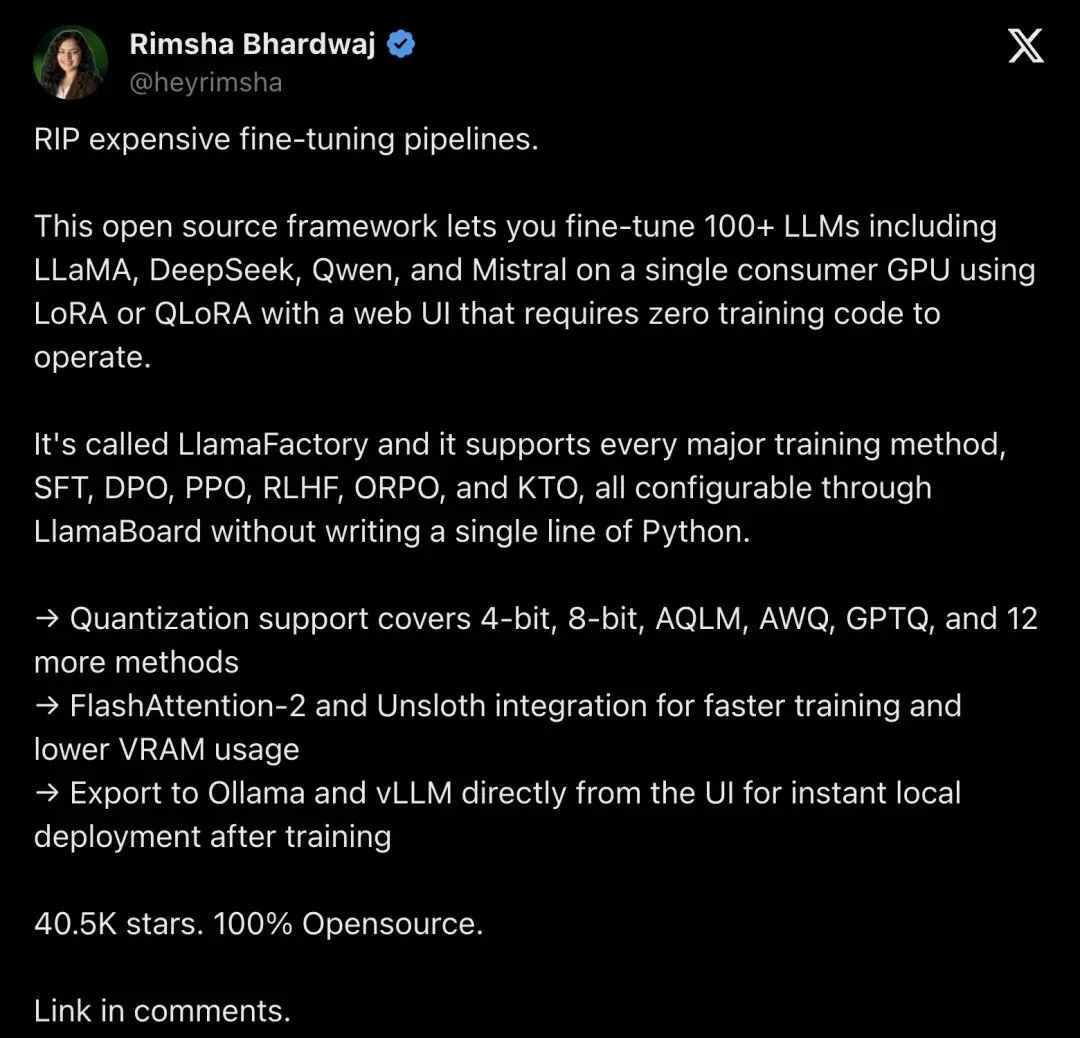

▲ @heyrimsha 的帖子,详细列出了 LlamaFactory 的量化支持和部署能力
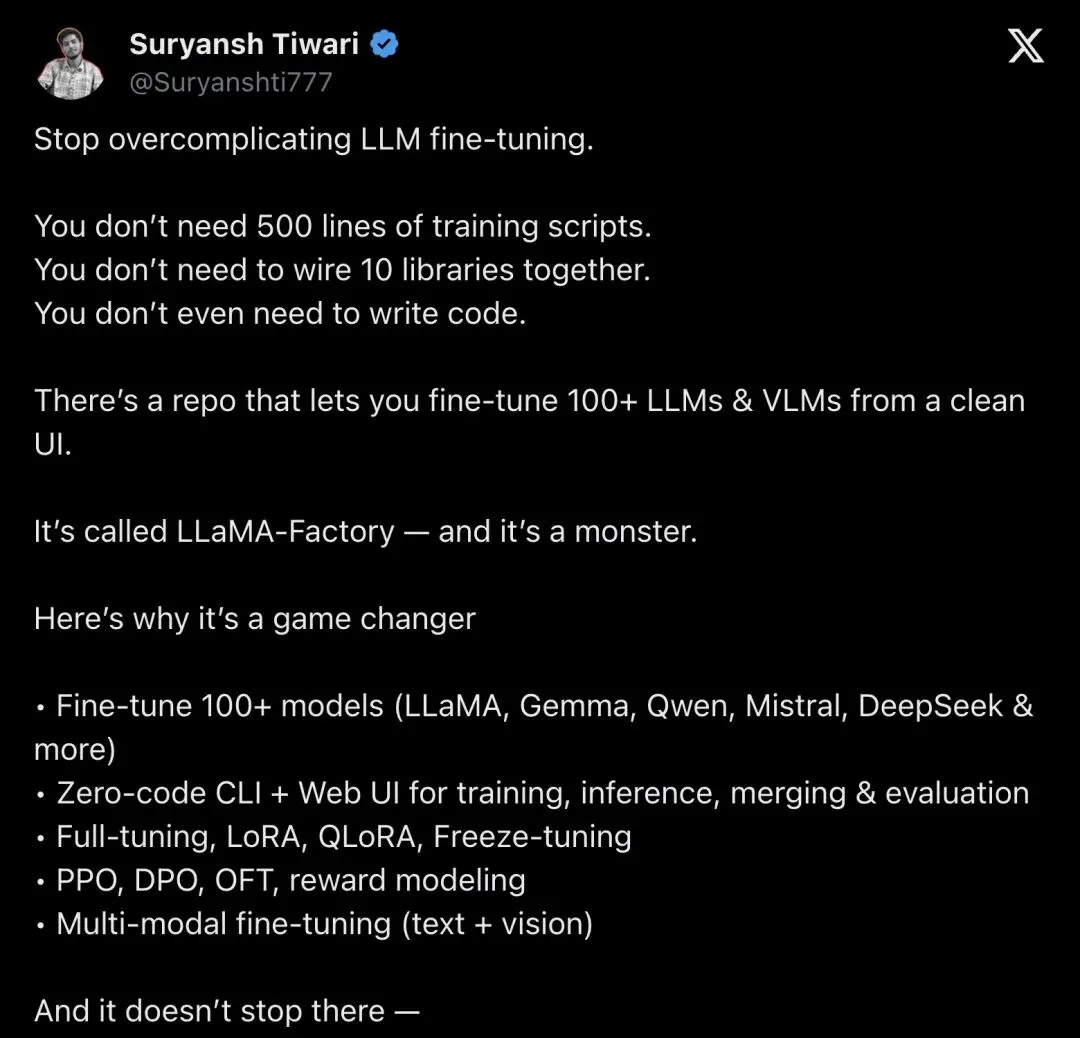



▲ @Suryanshti777 称 LlamaFactory 为「完整的微调基础设施层」
别忘了那头房间里的大象
说了这么多好话,必须补几句「清醒剂」。
第一,微调不等于变强。数据烂就是把模型推歪。LlamaFactory 降低了微调的门槛,但没有解决数据工程的问题。你用垃圾数据训出来的模型,只会更精准地输出垃圾。
第二,显存只是第一关。即使 QLoRA 把 7B 压到 6GB,训练时间、实验次数、评估方式仍然是实际成本。没有回归测试,你可能「以为模型更好了,其实更糟了」。
第三,WebUI 的「零代码」会制造幻觉。很多新手会误以为「点一下就能做出 GPT 级别的助手」。事实是:对话模板、系统提示词策略、数据格式,每一个都能让你的微调效果天差地别。
工具变简单了,不代表问题变简单了。
微调的「iPhone 时刻」?
回头看,LlamaFactory 做对了一件事:
它没有发明新技术,但把已有的技术做成了产品。
LoRA 是别人的论文。QLoRA 是别人的论文。DPO 是别人的论文。FlashAttention 是别人的论文。
LlamaFactory 做的事情是——把这些论文变成了下拉框。
就像 iPhone 没有发明触摸屏、没有发明摄像头、没有发明互联网,但它把这些东西放进了一块玻璃里。
当「微调 100 个大模型」变成了「打开浏览器 → 选模型 → 点训练」,这件事的参与者就不再只是 AI 研究员了。
每一个有数据、有业务场景的团队,都可以开始尝试。
客服对话微调成专属助手?可以。行业术语训练成垂直模型?可以。多模态识图 + 说明?也可以。
当然,能不能做好是另一回事。
但「能开始尝试」本身,就已经改变了游戏规则。
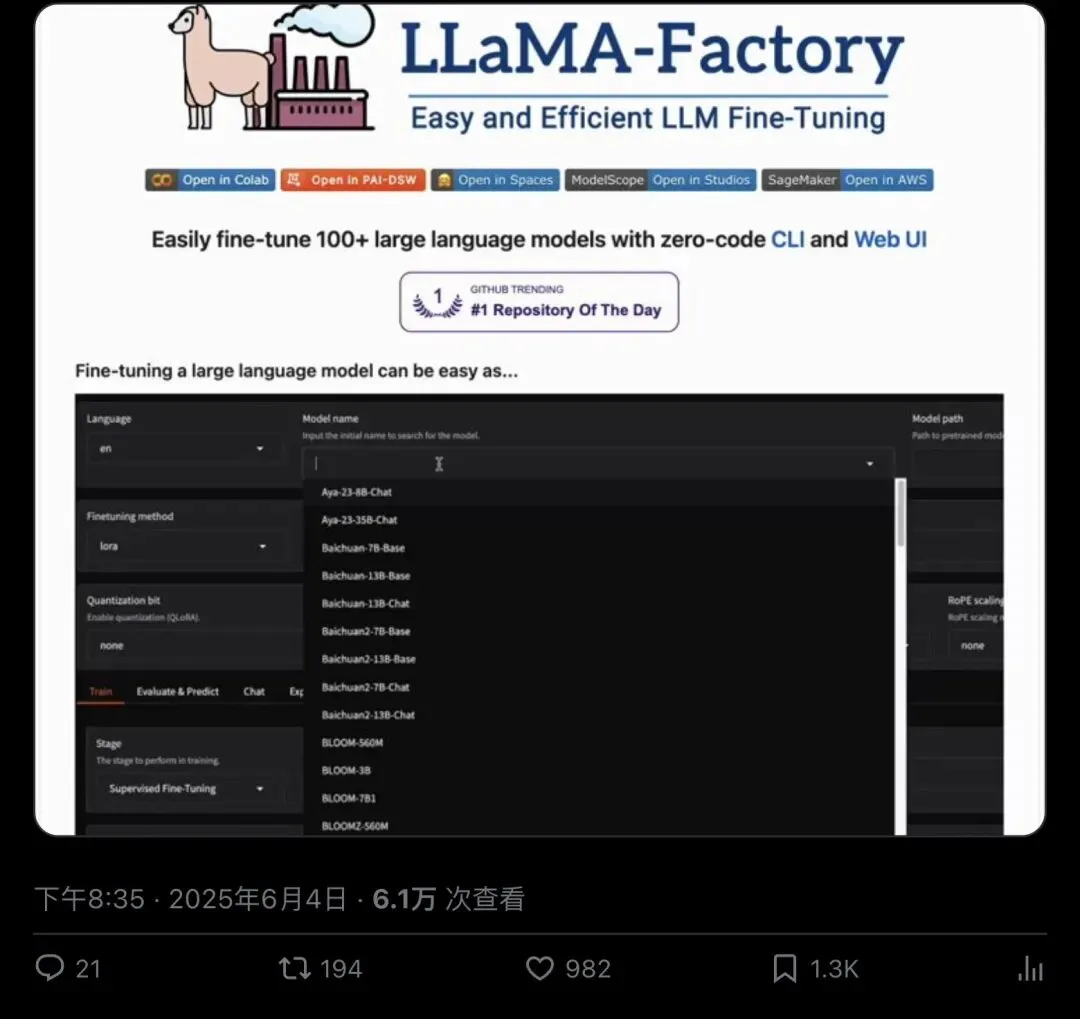
▲ @akshay_pachaar 的早期推文(2025 年 6 月),6.1 万次查看,51k+ stars 时期
LlamaFactory 的 GitHub 地址:https://github.com/hiyouga/LLaMA-Factory
论文地址:https://arxiv.org/abs/2403.13372
官方博客教程(Qwen3.5 微调):https://blog.llamafactory.net/en/posts/qwen3_5_finetuning/
— END —