 夜雨聆风
夜雨聆风





ZooKeeper选举原理深度剖析:从源码到实战

作为分布式系统的核心协调组件,ZooKeeper的高可用性依赖于可靠的Leader选举机制。当集群节点故障或网络分区时,如何快速选出新Leader避免脑裂?本文将从源码层面拆解FastLeaderElection算法的核心逻辑,带你彻底搞懂ZooKeeper选举的底层原理。
一、选举触发的核心场景
ZooKeeper集群在以下三种核心场景下会触发Leader选举:
1. 集群初始化启动:所有节点同时启动时,没有已存在的Leader,需要通过选举产生第一个Leader
2. Leader节点故障:当前Leader节点宕机或失去响应,集群需要快速选出新Leader
3. 网络分区恢复:网络分区修复后,原Leader可能与集群重新连接,需要重新确认Leader合法性
在这些场景下,ZooKeeper的FastLeaderElection算法会确保在最短时间内选出合法Leader,维持集群的高可用性。
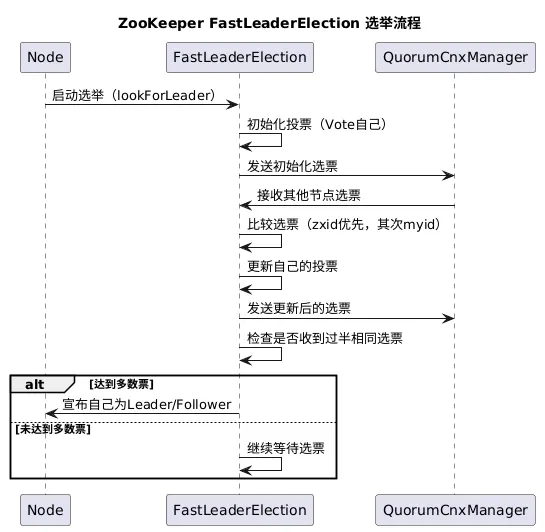
二、FastLeaderElection算法核心流程
FastLeaderElection是ZooKeeper默认采用的选举算法,其核心思想是通过选票广播与比较,让集群节点快速达成一致。以下是算法的核心流程:
-
初始化投票:每个节点启动选举时,首先将选票投给自己,包含三个核心参数:
–zxid:节点所存储的最新数据事务ID,代表数据的新旧程度
–myid:节点的唯一标识ID,配置文件中指定
–state:节点当前状态,初始为LOOKING(寻找Leader) -
选票广播:节点将自己的选票通过QuorumCnxManager发送给集群中所有其他节点
-
选票接收与处理:节点接收其他节点的选票,通过选票比较规则判断是否需要更新自己的投票
-
过半确认:当节点收到超过半数的相同选票时,确认该选票对应的节点为Leader,结束选举
三、源码深度解析:关键方法剖析
1. 选举入口:lookForLeader方法
lookForLeader是FastLeaderElection算法的核心入口方法,负责启动选举流程并处理选票:
public Vote lookForLeader() throws InterruptedException {
// 初始化投票为自己,使用最新的zxid和epoch
updateVote(new Vote(self.getId(), getLastLoggedZxid(), getCurrentEpoch()));
// 向所有其他节点发送初始化选票
sendNotifications();
// 循环等待直到选出Leader
while (state == LOOKING) {
// 从接收队列中获取其他节点的选票
Notification n = recvQueue.take();
// 处理收到的选票
switch (n.state) {
case LOOKING:
// 对方也在寻找Leader,比较选票并更新自己的投票
if (totalOrderPredicate(n.voteid, n.zxid, n.electionEpoch,
currentVote.getId(), currentVote.getZxid(), currentVote.getElectionEpoch())) {
// 更新自己的投票为更优的候选人
updateVote(new Vote(n.voteid, n.zxid, n.electionEpoch));
// 广播更新后的选票
sendNotifications();
}
break;
case LEADING:
// 对方已经成为Leader,验证其合法性
if (validateNotification(n)) {
// 确认Leader,结束选举
setCurrentVote(new Vote(n.leader, n.zxid, n.electionEpoch));
state = FOLLOWING;
}
break;
case FOLLOWING:
case OBSERVING:
// 对方已经跟随某个Leader,验证Leader合法性
if (validateNotification(n) && n.leader == currentVote.getId()) {
// 确认自己的投票正确,结束选举
state = FOLLOWING;
}
break;
}
// 检查是否收到超过半数的相同选票
if (hasAllQuorums()) {
// 确认Leader,结束选举循环
setCurrentVote(currentVote);
state = (currentVote.getId() == self.getId()) ? LEADING : FOLLOWING;
}
}
return currentVote;
}
2. 选票比较核心逻辑:totalOrderPredicate方法
选票比较是选举算法的核心,决定了谁能成为Leader。ZooKeeper采用zxid优先,myid补充的比较规则:
protected boolean totalOrderPredicate(long newId, long newZxid, long newEpoch,
long curId, long curZxid, long curEpoch) {
// 1. 优先比较epoch(选举轮次),更高的epoch代表更晚的选举
if (newEpoch > curEpoch) {
return true;
} else if (newEpoch < curEpoch) {
return false;
}
// 2. epoch相同则比较zxid,更大的zxid代表数据更完整
if (newZxid > curZxid) {
return true;
} else if (newZxid < curZxid) {
return false;
}
// 3. zxid相同则比较myid,更大的myid代表优先级更高
return newId > curId;
}
3. 过半机制:hasAllQuorums方法
ZooKeeper采用过半机制确保Leader的合法性,只有收到超过半数节点的认可,才能成为正式Leader:
protected boolean hasAllQuorums() {
// 统计支持当前候选人的节点数量
int count = 0;
for (Notification n : recvSet.values()) {
if (n.voteid == currentVote.getId()) {
count++;
}
}
// 判断是否超过半数
return count > quorumVerifier.getQuorumSize() / 2;
}
四、选举过程中的关键细节
- 脑裂避免:过半机制确保在网络分区场景下,只有一个分区能选出Leader,避免脑裂
- 选票广播优化:采用批量广播机制,减少网络开销,提高选举速度
- 状态机转换:节点在选举过程中会经历LOOKING -> LEADING/FOLLOWING的状态转换,确保状态一致性
- epoch机制:每个选举轮次都有唯一的epoch,避免旧选票干扰新选举
其实ZooKeeper选举核心就一句话:谁的数据新(zxid大)谁当Leader,数据一样就看谁的ID大。看完这篇源码解析,是不是觉得选举原理也没那么复杂?欢迎在评论区分享你遇到的ZooKeeper选举问题,一起交流探讨!