 夜雨聆风
夜雨聆风





大模型是怎么读PDF的,以及为什么这件事比你想的麻烦
上一篇我写了MinerU——一个在把PDF喂给AI之前专门做解析的工具。
有读者可能会问:现在Claude、Gemini、GPT都支持直接上传PDF了,为什么还需要单独做这一步?
这个问题问得好。答案需要先搞清楚大模型读PDF这件事背后到底发生了什么。
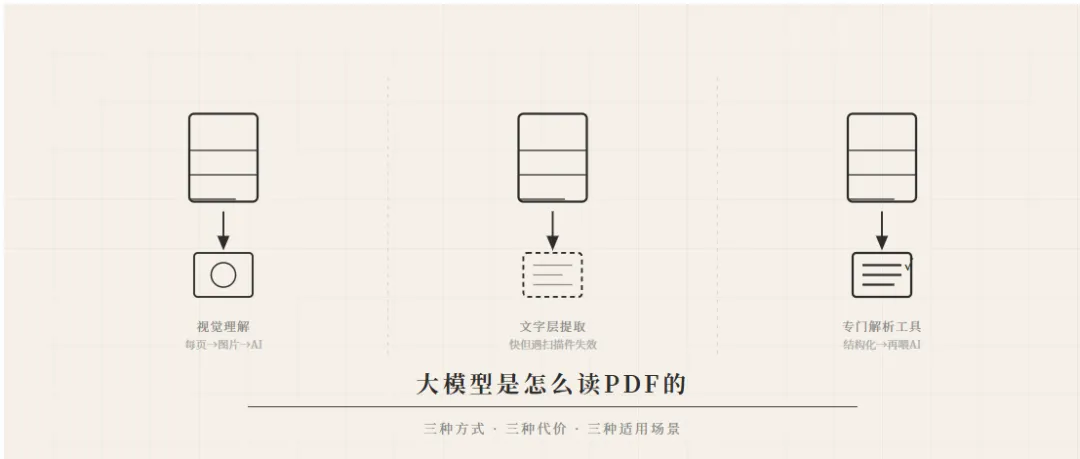
一、三种读PDF的方式
目前大模型处理PDF,主要走三条路。
第一条路:把每页变成图片,用视觉模型理解。
这是Claude、Gemini、GPT-4o的原生支持方式。你上传一个PDF,模型会把每一页渲染成图片,然后用视觉能力去看这些图片,提取文字和结构。
优点是简单——对用户来说,上传即用。
缺点是成本高、稳定性差。每一页都按图片计算token,一份50页的论文,Claude大约消耗75000到150000个token,Gemini相对便宜,GPT-4o居中。更关键的是,视觉模型在处理复杂布局时不够稳定——双栏论文、嵌套表格、行间公式,经常识别错乱。
第二条路:直接提取PDF文字层。
PDF文件里,有些是带有真实文字层的(text-based PDF),有些只是扫描图片。对于前者,可以用基础工具(如pypdf、pdfplumber)直接提取文字,速度快、成本极低。
但这条路的问题是:文字提取出来是什么顺序,取决于PDF里元素的排列方式,而不是人类的阅读顺序。双栏论文提取出来经常是左栏右栏混在一起,表格变成乱码,公式消失。遇到扫描件,这条路完全失效。
第三条路:专门的文档解析工具。
MinerU、LlamaParse这类工具走的是这条路。它们先做结构分析——识别阅读顺序、区分文字和表格和公式、处理扫描件OCR——然后输出结构化的Markdown或JSON,再交给大模型处理。
多一个步骤,但原材料的质量完全不同。
二、对学术PDF来说,差距有多大
有一个评测用800多份真实文档对17种解析方案做了系统测试,包括开源工具、商业API,以及直接用大模型处理。
几个值得记住的数字:
即使是表现最好的方案,文本相似度也没有超过88%。没有任何一种方式在复杂文档上能做到完美。
更有意思的发现是:不同文档类型之间的差距很大。同一个解析方案,在普通文档上可能得分70%以上,在学术论文上掉到60%甚至更低。学术PDF的双栏布局、大量公式、复杂图表,对所有方案都是挑战。
还有一个反直觉的结论:用大模型直接解析PDF,并不总是比专门工具更好。LlamaParse在鲁棒性指标上表现比Gemini更稳,而成本只有后者的十分之一。GPT-4o-mini的文本提取得分还过得去,但文档结构破坏率极高——对需要保留结构的RAG场景来说是致命的。
三、不同场景,不同选择
这不是说原生PDF支持没有价值。对于不同的使用场景,合适的工具是不同的。
如果你只是想快速问一个PDF里的某个问题,Claude或Gemini的原生支持完全够用——上传,提问,拿答案。简单、即时、不需要额外配置。
如果你在处理大量文献、需要批量提取信息、或者要把PDF内容作为后续AI处理的输入,直接上传的方式就开始出现问题。成本积累很快,质量不稳定,而且扫描件处理得不好。
如果你的PDF里有大量公式、复杂表格、或者是扫描版,专门解析工具几乎是必须的。视觉模型对公式的识别比人们想象的更不可靠,一个认错的符号可能改变整个表达式的含义。
对于做研究的人,处理的往往是最后这种情况——学术论文、扫描文献、充满公式的技术文档。这正是专门解析工具存在的意义。
四、流程上的一个建议
我现在的做法是把这件事拆开来想:
理解类任务——快速读一篇文献、提问、做笔记——直接上传给Claude或Gemini,足够了。
提取类任务——批量处理文献、结构化摘录信息、作为Claude Code的输入——先用MinerU解析成Markdown,再交给AI处理。
两条路并不矛盾。它们解决的是不同的问题。
真正的效率,不是找到一个工具解决所有问题,而是知道在什么情况下用什么工具。
参考:Applied AI PDF Parsing Benchmark,评测覆盖17种解析方案,800+真实文档。