 夜雨聆风
夜雨聆风





双紫擒龙完整源码:为什么免费捡来的零散片段,最后往往拼不成一套完整的资料?
特别提示:本文仅为个人学习双紫擒龙指标编程的操作记录与技术开发交流。文中涉及的源码收集与代码拼凑逻辑,仅为客观技术结构展示,绝不代表对未来趋势的预测,也不构成任何操作建议。市场有风险,阅读需谨慎。

外面关于双紫擒龙源码的内容,其实不算少。你随手在各个论坛或者群里看一圈,经常能碰见别人分享的免费指标源码。
看得多了,很多人会很自然地产生一种感觉:既然网上到处都有人发,那我只要多花点时间,东拼西凑一下,这套双紫擒龙完整源码我就算是免费集齐了。
问题恰恰出在这里。
因为凑齐了几个免费的文本文件,不等于还原了底层的架构;拿到几个导入不报错的代码,也不等于理清了整套资料的联动关系。 这种把“免费拼凑”当成“完整获取”的做法,是阅读和整理技术资料时最大的隐形消耗。
一、免费片段,最容易被误会成拼一拼就能用的平替
很多人第一次接触这套资料时,都会下意识这么理解:代码嘛,无非就是一堆字母和数字的组合。只要我把免费拿到的主图装上,再去别的地方顺带下个免费的副图,拼在一起不就等于完整版本了吗?
这个理解表面上看极其合理,但真往下拆,其实很容易把人带偏。
因为双紫擒龙完整版本,并不是一堆积木,随便找几个零件就能搭成房子。它是一个上下游数据高度依赖的系统。把不同来源、不同批次的免费片段强行塞进同一个软件里,并不意味着它们在代码底层就能自动产生联系。 如果把这种物理上的拼凑当成逻辑上的闭环,后面很多结构关系自然就会跟着乱。

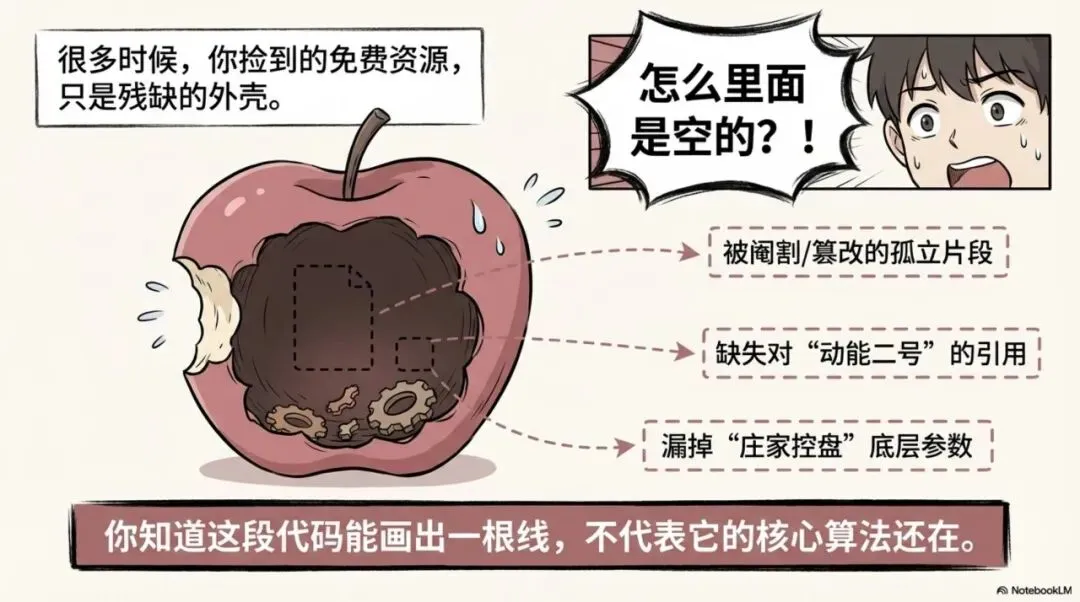
二、很多时候你捡到的免费资源,只是残缺的外壳
这也是外面免费内容最容易造成的误区。你看到一个名字叫双紫擒龙副图的文件,当然会觉得捡到了宝。
但问题是,这些被随意丢在网上的免费代码,很多时候是被阉割或篡改过的孤立片段。
片段最容易建立的,是零成本的满足感;整套资料真正难的,是底层运算的无缝衔接。 你知道这段代码能画出一根线,不代表你已经知道它是不是缺失了对动能二号的引用,或者是不是漏掉了庄家控盘的底层参数。这也是为什么,有些免费资料看起来名字是对的,真往下拆,还是会发现里面的核心算法其实已经被改得面目全非,甚至引用关系全断了。
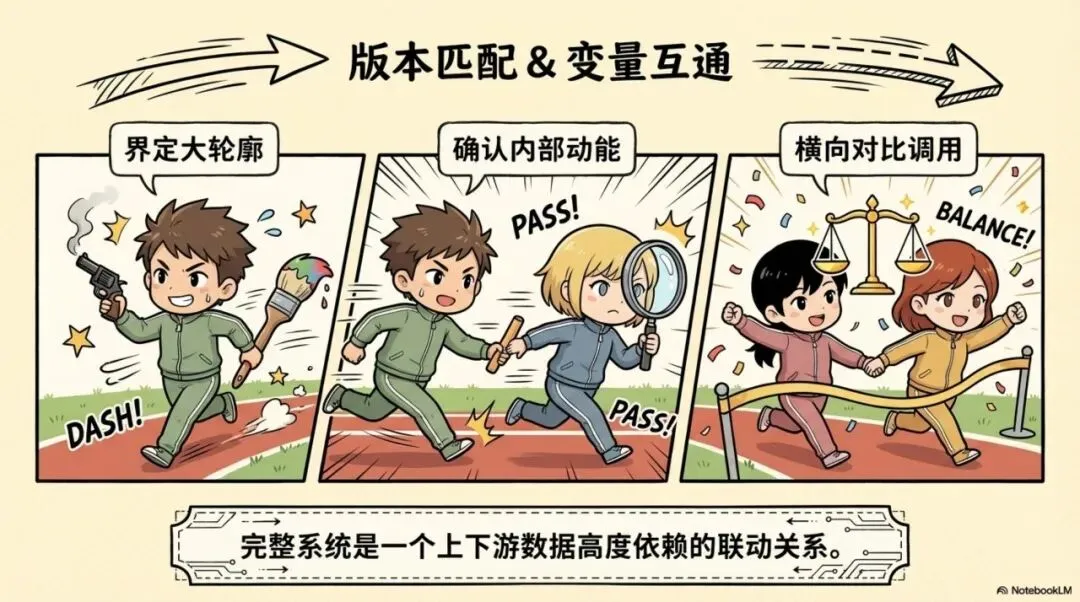
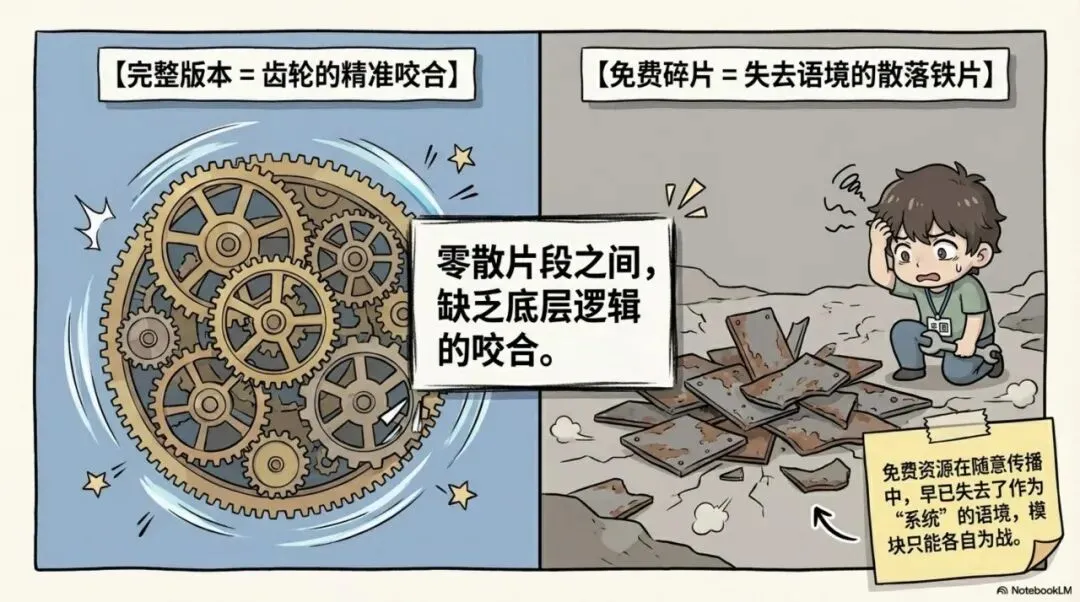
三、零散片段之间没有底层逻辑的咬合
如果把这件事说得再直一点,其实就一句话:完整版本是齿轮的咬合,免费碎片只是一地散落的铁片。
不是因为免费的东西一定不好,而是因为它们在被随意传播的过程中,本来就已经失去了作为“系统”的语境。双紫擒龙主图先界定出大轮廓,接着需要对应版本的副图去确认内部动能,再需要分时和排序去进行横向对比。

这就意味着,模块本来就是相互咬合的,不是各自为战的。 所以如果一上来只追求免费收集,而不去理顺它们版本是否匹配、变量是否互通,很多人就会自然觉得为什么信号不仅乱,还会报错;再想往深了理顺,又发现模块之间根本没有数据接口。问题不是你不懂代码,而是你用来搭建框架的材料本身就是碎的。
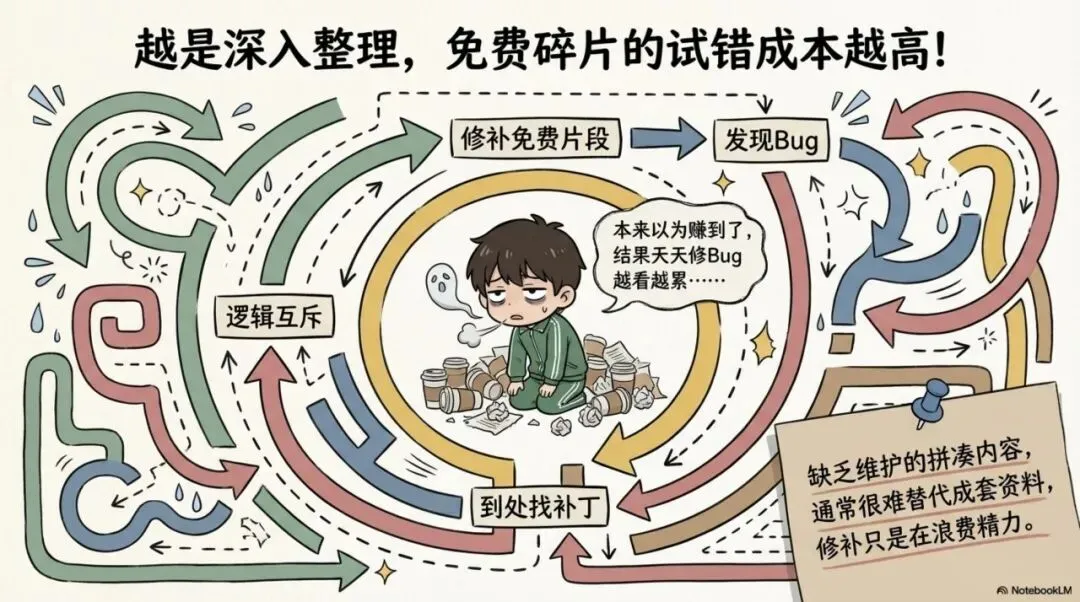
四、越是深入整理,越发现免费碎片的试错成本其实最高
这套资料我一直在持续整理。比起单独去到处搜刮免费的指标文件,我更在意的是整套源码资料的结构是不是顺畅的,主图和副图之间能不能真正接起来。
因为这类内容最容易出现的误区,就是拿着一堆免费捡来的零散片段反复修补,反而误以为自己赚到了。真往下拆,很多差别其实都不在花费的多少上,而在资料是不是成套、上下游的约束是不是齐全、代码的层级是不是清楚。

网上那些免费的拼凑内容当然也能看。它们最大的作用,是帮你粗略了解一下界面的样式。但如果真想继续往下理顺,这种缺乏维护的拼凑内容通常很难替代成套资料。尤其是那些连作者自己都不知道从哪复制来的资源,最大的问题往往就是逻辑互斥,后面自己再回头整理时,反而因为需要不停地去修复bug而越看越累。
说得更直接一点:存了一堆免费的公式文件,不等于看过整套资料;界面勉强能显示,也不等于真正把结构接起来。

五、双紫擒龙完整版本的关键,是代码生态的自洽
很多人会把完整理解成:主图我白嫖到了,副图我也找到了,那大概这套资料就齐了。其实完整版本真正的核心,从来不是你硬盘里存了多少个文件,而是这套代码生态有没有自洽。
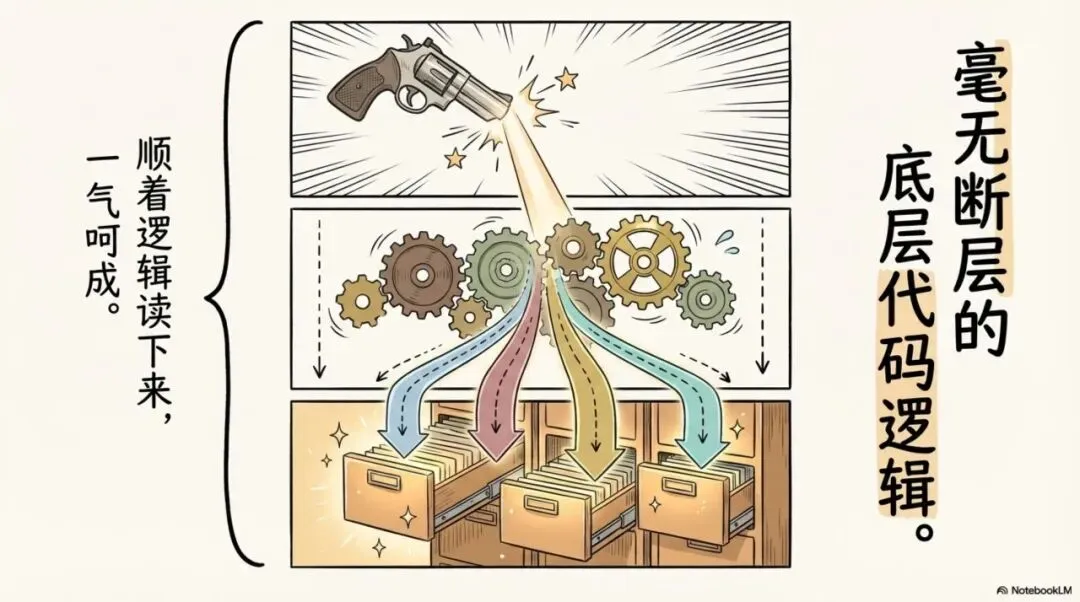
主图的信号有没有向下传递,副图的过滤条件有没有互相咬合,分时排序能不能准确调用前面的数据,它们之间是不是顺着一套毫无断层的底层代码逻辑读下来的。
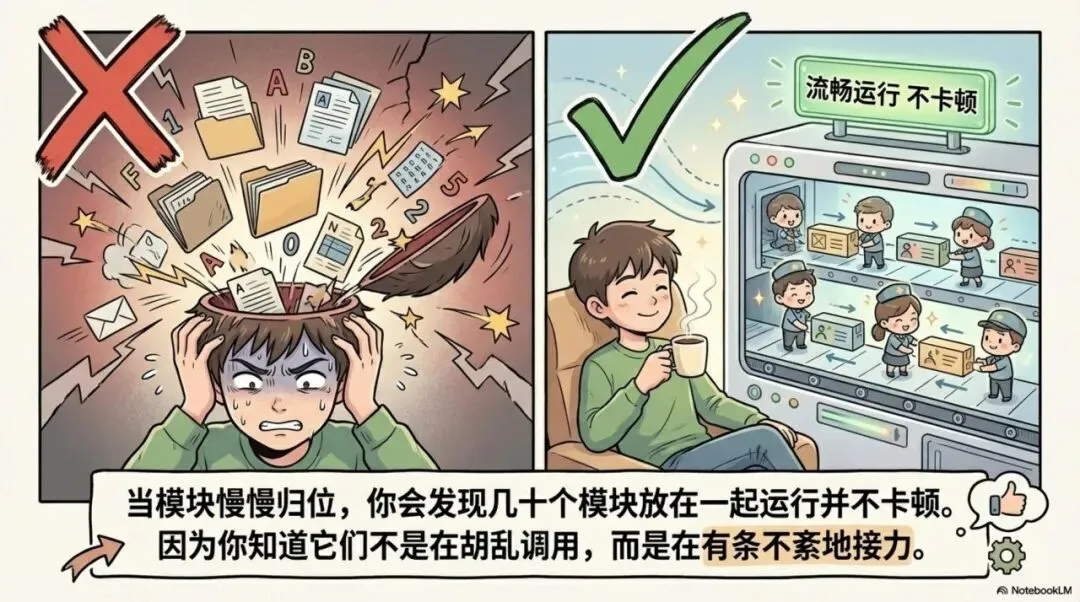
如果这些关系都是散的,那你攒的文件包再大,脑子里留下来的也只是一堆无法协同的乱码。 而如果这些位置都慢慢归位,你会发现几十个模块放在一起运行并不卡顿,因为你知道它们不是在胡乱调用,而是在有条不紊地接力。

如果你关注的是紫紫红黄双紫擒龙源码资料的结构说明、模块组成和整体整理,可以关注公众号,通过底部菜单查看资料说明。
本文仅作双紫擒龙源码结构与技术资料说明,不构成任何投资建议。