 夜雨聆风
夜雨聆风





别一头扎进源码里:我是怎么用 Antigravity 阅读 Claude Code 的

这篇文章并不打算去深度阅读 Claude Code 本身,而是想讲讲,怎么借助 Google 的 antigravity 这样的 AI 工具,更高效地理解一份复杂代码。
Antigravity 的多 agent 模式
我能想到的一种方式是:在 Antigravity 里先让一个 agent 把控整体,从最上层分析整个 Claude Code,先把大模块分出来。 然后,再让其他 agent 分别去分析各个模块。 这样做的好处是:
-
• 把控整体的 agent 只负责大的方向,不会陷入太多细节。 -
• 其他 agent 各自负责自己的模块,互相之间不容易干扰。 -
• 如果模块和模块之间存在耦合,或者有明显的相互关系,还可以再加一个 agent 专门分析它们之间的联系。 -
• 各个模块的分析结果,还可以继续喂给新的 agent,进一步增强它对整体的理解。
我觉得最关键的一点是:模块一旦拆清楚了,我们在看代码、分析代码时,就不容易因小失大,也不容易一头钻进牛角尖里出不来。 你可以随时切换视角,也可以随时往上回看。 不会一下子扎进太深的细节里,也不会飘到太虚的高层概念上。
而且,大模型的上下文也不会被拉得太长,不容易因此“降智”。
Claude Code 的总体分析
我在 Agent Manager 中创建了一个 agent,并直接告诉它:
我想深度学习这个代码。请由浅到深地分模块引导我去学习这个源码。
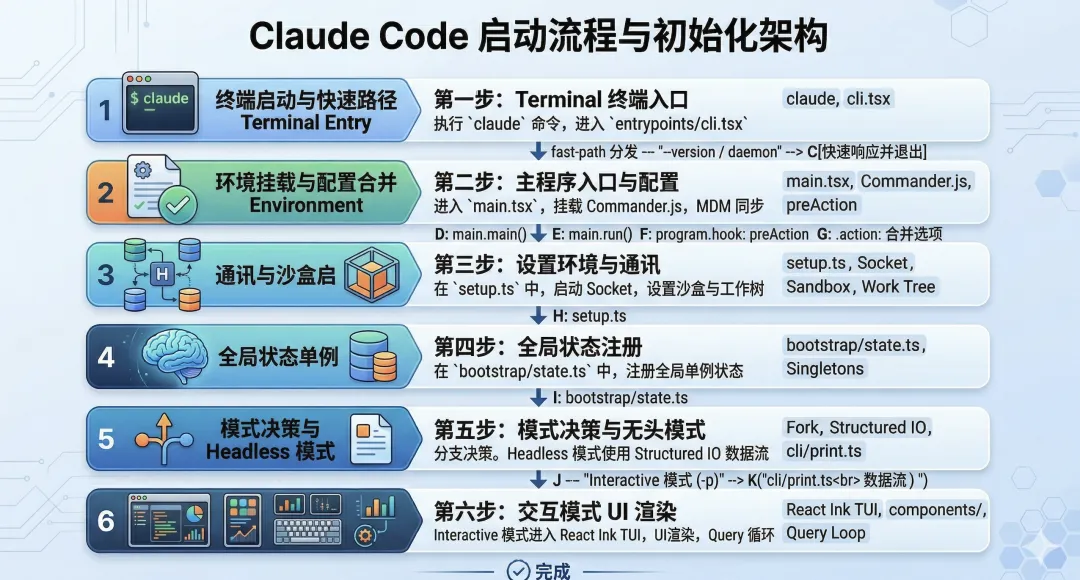
然后,它就给了我一个 源码学习路线图:
-
• 第一层:入口与初始化阶段 (The Entry Point & Bootstrapping) -
• 第二层:终端用户界面层 (The Terminal User Interface – TUI) -
• 第三层:对话上下文与状态管理 (State & Context Management) -
• 第四层:AI 引擎通信核心 (The AI Communication Engine) -
• 第五层:工具链与智能体编排 (Tools & Agentic Capabilities) -
• 第六层:高级特性与周边生态 (Advanced Features)
最后,它还会给一个简短点评,并告诉我下一步应该怎么做。
不过“下一步怎么做”我先放到一边,先把它回答的文字都丢给了 Gemini,用的是 Nano Banana2。 我让它把这些内容再整理一下,并画成图,结果还是很好看的,也很清晰。

这已经有点 PPT 级别的感觉了。 用 Nano Banana2 去生成总结图或者分析图,能让自己的分析笔记更清晰、更直观,也不会那么枯燥。
不同的 agent 阅读不同部分代码
我按上面的建议拆了 5 个 agent,每个 agent 负责阅读一部分。 我在 Agent Manager 里,Claude Code 源码对应的 workspace 下创建了 5 个 New Conversation,再把总结构里分出来的 5 个层次描述分别复制给它们。
当然,这并不是说一定要并发地让 agent 去阅读。 更准确地说,是通过大模型的不同会话来分别学习这份代码。 这样做的前提,是你已经先有了一张清晰的框架路线图。
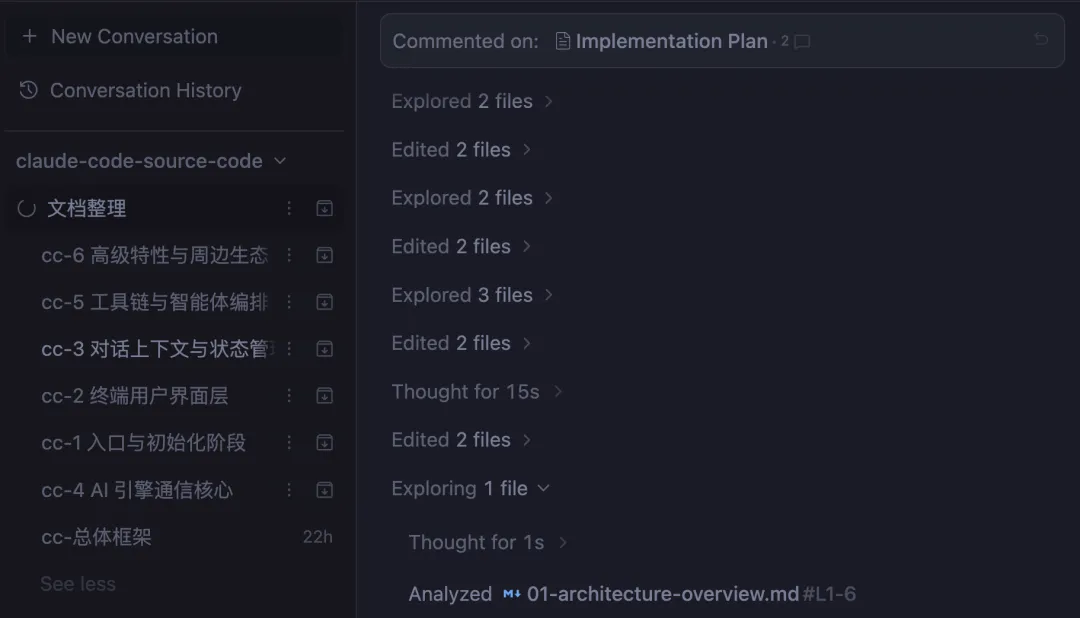
Agent Manager,也可以直接在右上角打开这个 workspace 的会话。如下图: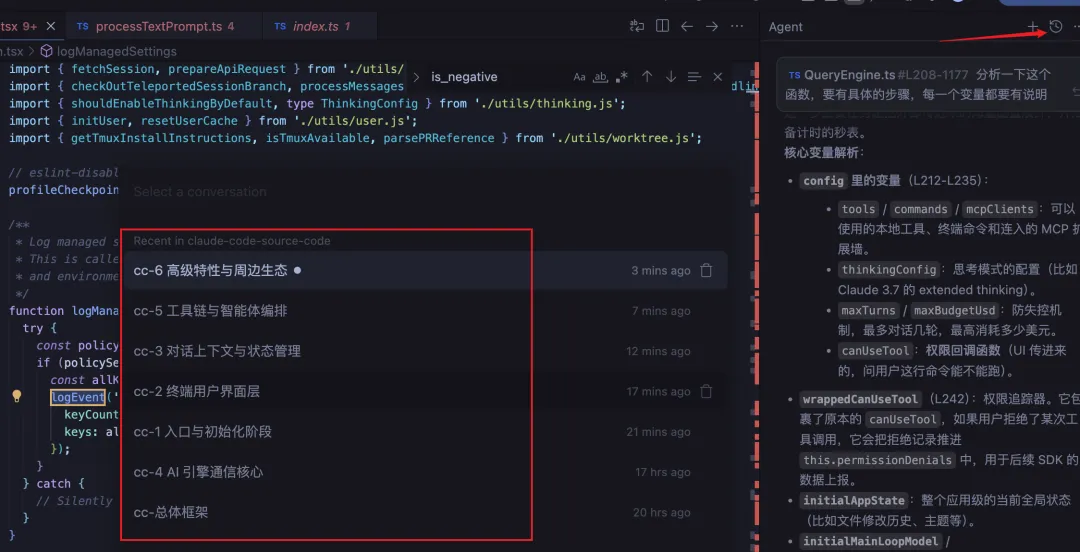
分模块的技术级拆解
agent 不仅能较好地分析出这一部分的主要功能,也会顺手注意到这些功能分别落在哪些代码文件里。
如果我们想知道 Claude Code 在执行命令时到底发生了什么,就可以让 agent 去分析第一部分,也就是“终端启动与快速路径”。 比如一些简单的参数,像 --version,本身可以直接输出结果,那就没必要把整套主代码都导入进来。 这种设计其实就是一种懒启动,用来规避主代码的加载。
如果想继续了解别的子模块,就让 agent 接着往下分析。 当然,你也可以另外新建一个会话。
我们也可以让 agent 直接画流程图。如下图:
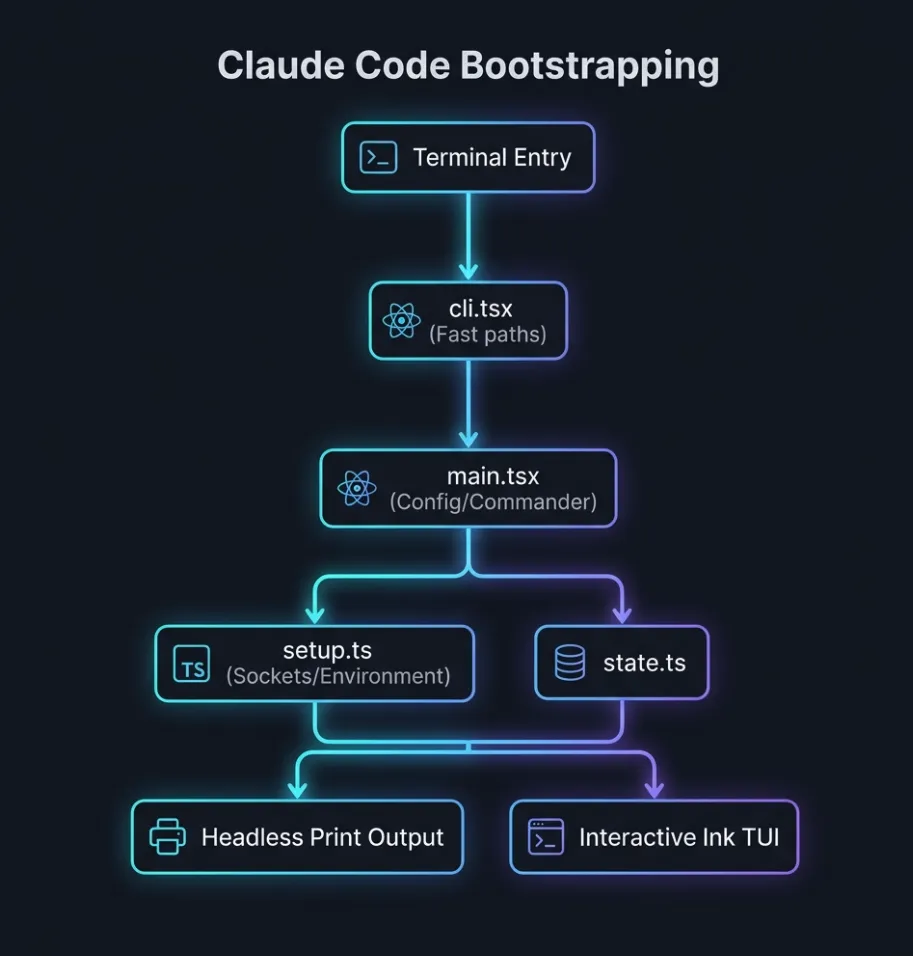
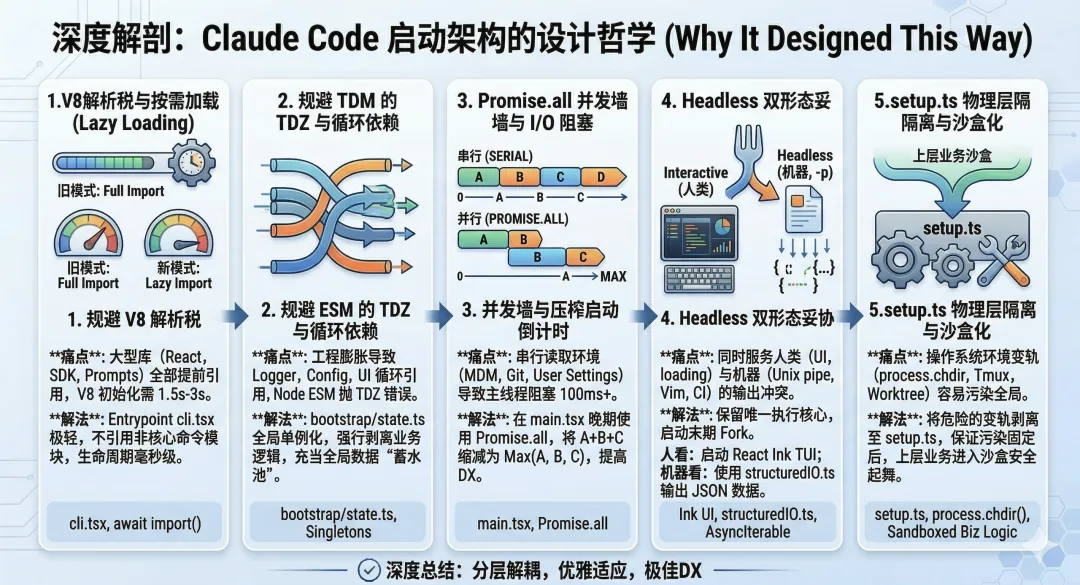
如果我想知道,为什么 Claude Code 在启动阶段要这样设计,同样也可以把这个问题抛给 agent。 它分析完代码之后,通常会给出一个比较完整的解释,甚至还能顺手画出一些挺有意思的图。
把结果整理成知识库
以前我阅读代码,通常就是直接在代码上写注释,或者额外写个简单笔记,记下一些当时的思路,方便以后回头看。 现在用 antigravity 来辅助阅读代码,我更习惯把分析后的结果整理进知识库。 有时候我甚至会觉得,它整理出来的内容,比我自己写得还要完整。

我一般会直接这样和 agent 说:
请把刚才关于这个模块的分析,整理成一篇知识库笔记。要包含:模块职责、入口文件、核心文件、调用流程、依赖关系、关键设计、未解决问题。用我后面还能继续补充的格式来写,尽量结构化一点。
这样一来,它产出的内容通常就已经很像一份可以直接保存的笔记了。 如果有些地方我觉得还不够准确,自己再手动修一下就行。
-
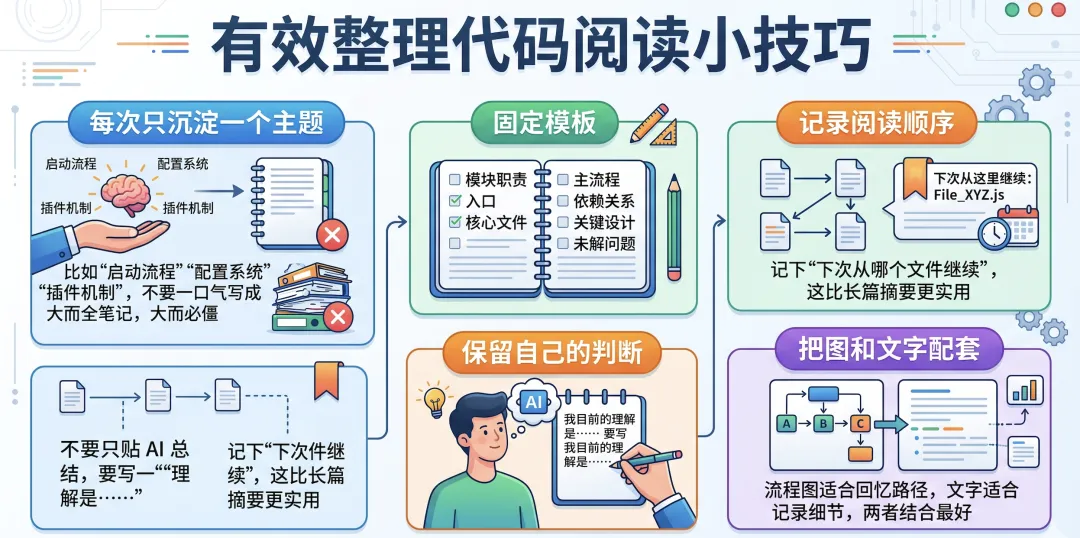
• 一次最好只整理一个主题,比如“启动流程”“配置系统”“插件机制”这种。不要一上来就想写成一篇大而全的总笔记,最后往往什么都沾一点,但不够深。 -
• 笔记最好有个固定写法,不然今天这样记,明天那样记,过几天自己再回来看也会乱。像模块职责、入口、核心文件、主流程这些,我现在都会尽量记上。 -
• 还有一个很有用的小习惯,就是顺手记一下“下次应该从哪个文件继续看”。这个东西看起来很小,但有时候比写一大段总结还顶用。 -
• 另外不要把 AI 给的内容原样贴进去就完了,最好还是补一句自己的理解。哪怕只写一句“我现在的理解是……”,后面再回来看也会清楚很多。 -
• 如果有图的话,最好和文字放在一起。因为流程图适合回忆路径,文字适合记细节,两边对着看会轻松很多。
防止被 AI 带偏
一定要记得,agent 只是辅助。 真正要学习代码、理解技术原理的人,始终还是我们自己。 AI 并不是你的学生,不是你教会了它怎么做事;它只是一个已经具备能力、但需要你去正确使用的工具。
很多人有一个不太好的“想法”,就是觉得等需要的时候再去问 AI 就行。 这个想法其实挺有毒的,因为最后很容易变成什么都没真正搞懂,连问题都提不明白。
只有我们自己先把基础技术原理学明白,再慢慢融会贯通,后面才能更好地去指挥 agent 干活。 不然就只能和 AI 不断拉扯: 你问了,它没完全明白你的意思;它答了很多,但又不是你真正想要的;然后你继续追问,它继续跑偏,最后陷入一个低效循环。
所以,我觉得下面这几个点一定要注意:
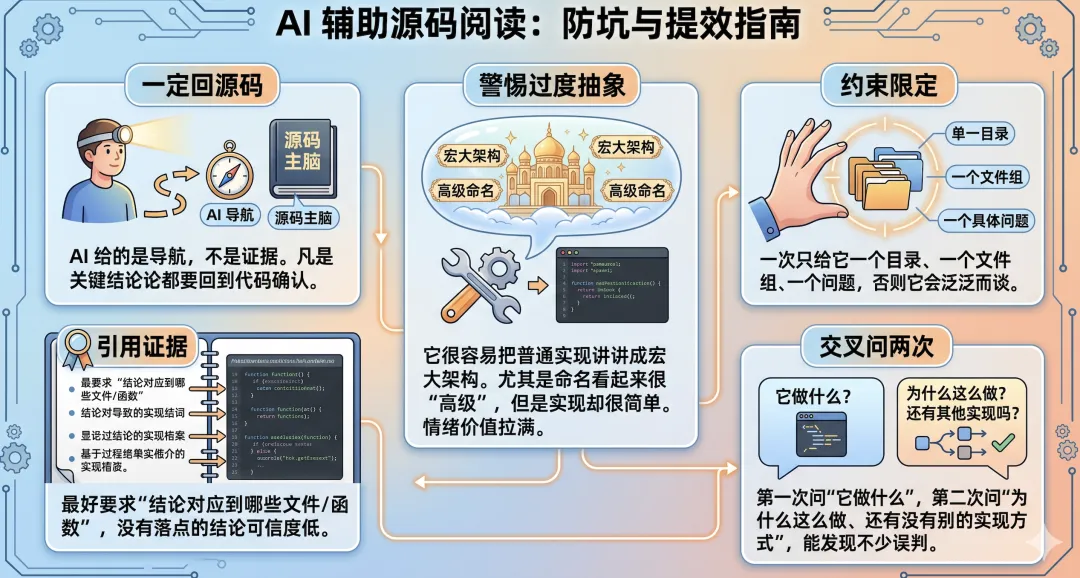
-
• 一定回源码:AI 给你的是导航,不是证据。 凡是关键结论,都要回到代码里确认。 -
• 警惕过度抽象:它很容易把普通实现讲成宏大架构,尤其是有些命名看起来很“高级”,实际实现却并不复杂,情绪价值很容易被它拉满。 -
• 约束范围:一次只给它一个目录、一个文件组、一个问题,否则它很容易泛泛而谈。 -
• 要它引用证据:最好要求它说清楚“这个结论对应哪些文件、哪些函数”,没有落点的结论可信度往往不高。
写在最后
我的感受是,在使用 antigravity 这类工具时,它最适合做的,不是替你把代码“看完”,而是先帮你把整体框架搭起来,再陪你一层一层往下走。 先分模块,再追主链路;先形成理解,再沉淀到知识库。 这样一来,读代码就不再只是一次性的探索,而会慢慢变成一个可以持续积累的过程。
以后不管是看一个新的开源项目,还是阅读公司内部的大型工程,我觉得都可以用类似的方法去做:先让 agent 帮你建立地图,再让不同的会话去拆不同模块,最后把真正有价值的结论沉淀到自己的知识库里。 这样时间花下去,理解就不会白费。
工具会一直变,模型也会一直变。 但“先搭框架,再钻细节;边分析,边沉淀”这件事,我觉得会一直有用。
本文为技术分享,文章纯手工写图片部分 Nano Banana 2 生成