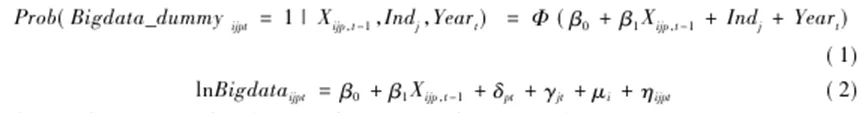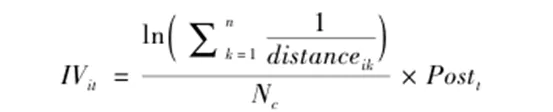文献分享|大数据应用对中国企业市场价值的影响——来自中国上市公司年报文本分析的证据
推进大数据与实体经济的深度融合成为中国新一轮的经济增长点。本文通过对A股上市公司的年报进行文本分析,构建了衡量公司层面“大数据”应用程度的指标,探讨了企业大数据应用的发展状况及决定因素,检验了大数据应用对公司市场价值的影响。研究发现:第一,规模较大、有形资产比例较低、盈利能力较强,以及所在地区市场化程度较高的公司更可能在生产经营过程中应用大数据;第二,大数据的应用可以显著提高公司的市场价值;第三,主要的影响机制在于大数据的应用显著提高了公司的生产效率和研发投入,而相关技术和人才供给的不足可能会阻碍大数据对市场价值的积极影响。本文结论对中国未来大数据相关的政策设计具有参考价值,为推动实体企业生产经营与大数据的高效融合提供了经验证据和指导建议。
关键词 :大数据;文本分析;市场价值;生产效率;研发投入
第一,利用非结构化的文本数据构建了公司层面的大数据应用程度的衡量指标。采用文本分析的方法抓取了中国A股上市公司年报中与“大数据”相关的关键词,构造了大数据应用程度的变量,并检验了其有效性。与以往的研究相比,本文对大数据应用的度量更为直接、有效、准确,且全面覆盖了A股所有行业的公司样本,因此能够直观地刻画中国上市公司大数据发展水平的动态变化过程及其影响因素,为后续研究奠定了扎实的数据基础 。
第二,实证检验了大数据应用对公司市场价值的积极意义,并深入探索了其影响机制,为大数据应用对于公司竞争力提高、宏观经济增长的意义构建了理论基础,提供了实证依据。本文的分析立足于中国企业的数据,充分结合中国的大数据政策优势、数字基础设施建设、人才供应条件等宏观要素,从而提供了根植于中国实际的政策建议,助力中国经济高质量发展。 第三,通过探索大数据对公司市场价值影响的异质性,发现规模不同的公司、股权性质不同的公司、竞争激烈程度不同的行业采用大数据对公司市场价值的提高效果存在差异。 第四,丰富了公司市场价值影响因素的相关研究。本文发现大数据的应用是影响公司股票市场价值的重要因素,这为数字经济趋势下公司市场价值影响因素的研究提供了新证据。
(一)大数据应用于生产效率
作者认为,大数据可以通过三个通路来提高企业的经营效率。 第一是改善信息获取与决策效率。通过对大量市场数据和消费者数据的分析,企业可以更准确地了解市场需求,从而做出更科学的经营决策。例如,零售企业可以通过分析消费者的购买记录和线上浏览行为,预测哪些产品需求会上升,从而提前调整库存结构。 第二是降低劳动力成本,推动生产自动化。大数据应用可以实现传统产业生产过程的自动化转型,替代部分原本由劳动力承担的生产工作,从而降低单位产出的劳动力成本。例如,在制造业中,许多”预测性任务”(如质量检测、设备维护预判)可以通过大数据分析以更低的边际成本完成,减少人工参与的同时提高预测效率。 第三是优化组织管理,降低内部协调成本。大数据应用可以使企业内部各组织之间信息传递的成本更低、效率更高,从而实现更加扁平、高效的管理模式。例如,通过物流管理系统对产品库存和发货情况进行实时监控,企业可以迅速做出调拨决策,平衡供应链供需两端,降低物流费用和管理成本。 作者认为,大数据还可以通过三个通路促进企业研发创新。 第一是精准把握市场需求,明确创新方向。通过分析海量结构化与非结构化数据(如消费者行为数据),企业能够更前瞻性地识别消费者需求和偏好,使研发方向更贴合市场需求结构,从而降低研发成果商业化失败的风险,提高研发动力。例如,互联网平台企业通过分析用户数据,能够更早发现消费趋势并推出符合需求的新功能或产品。 第二是降低研发不确定性与成本。研发活动具有高风险、高投入特征,而大数据的预测能力能够显著降低研发过程中的不确定性,减少企业为规避风险而投入不足的问题,从而增强研发动机。 第三是积累研发资源、提高创新效率并催生根本性革新。一方面,大数据扩大了企业信息搜索空间,提高了从已有技术中提炼创新成果的能力,促进过程创新;另一方面,大数据应用可能催生对创新方法和产业结构的根本性变革。例如,基于非结构化数据的模式识别技术催生了新一代自动驾驶技术,这种”创造新产品的新方法”比单一产品发明具有更广泛深远的影响。 作者也指出,大数据应用转化为企业价值的过程可能存在摩擦和时滞,主要体现在两个层面。 第一,大数据应用本身存在较高的技术门槛,且需要一系列互补性资产的配合。一方面,非结构化数据的处理、多数据源系统的整合等技术难度较大;另一方面,大数据的增值作用离不开生产经营重构、商业模式创新、组织结构调整、员工技能培训、软件定制开发等互补性投入,企业在引进大数据设备和人才过程中还面临着资源重新分配、劳动力重组、生产线调试等调整成本。只有互补性投入与大数据应用齐头并进,其价值创造才能充分发挥。 第二,现实中大数据与实体经济的融合还受到人才供给和技术基础设施的限制。从人才角度,企业内部员工技能与需求不匹配会形成障碍,而外部劳动力市场上大数据相关的高素质人才供给存在缺口;从技术环境角度,所在地区的数据服务供给和数据中心等新型基础设施建设是重要保障,行业技术使用密度不足也会削弱大数据应用的绩效改善效果。随着大数据应用在行业和地区范围内的普及加深,规模效应可能会逐步提高其向企业价值转化的效率。 1、样本选择和数据来源
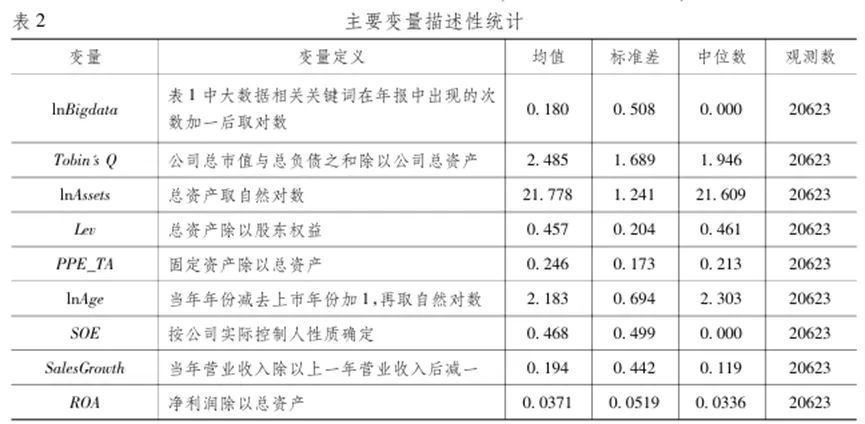
本文以2006—2017年中国A股所有上市公司作为初始的研究样本,依次剔除如下样本: (1)ST、*ST和PT公司; (2)IPO当年的观测值和已退市的公司; (3)净资产为负的观测值; (4)主要变量缺失的公司; (5)信息传输、软件和信息技术服务业的上市公司。大数据产业本身属于信息技术类行业,因此大数据直接相关的行业可能与其他行业受到的影响有所不同。根据本文的理论分析,大数据应用对公司市场价值的影响不应该只局限于与大数据直接相关的行业,而是在非大数据直接相关的行业中也存在显著影响,大数据与实体经济的融合以及非大数据直接相关的企业的数字化转型是本文关注的核心,因此本文将信息传输、软件和信息技术服务业剔除后进行后续分析。最终,获得2501家上市公司共20623个样本。公司大数据应用的相关变量来自于对公司年报的文本分析,其他市场交易和财务数据主要来自于国泰安(CSMAR)数据库,CPI数据来自于国家统计局。为了避免极端值的干扰,本文对连续变量进行上下1%的缩尾处理。 本文借鉴Saunders&Tambe(2013),提出了一种新的衡量方式:基于上市公司披露的年报的文本信息,通过Python程序批量抓取年报中与“大数据”应用相关的关键词,根据所有关键词在年报中出现的总次数来构造大数据相关变量。 具体而言,本文利用关键词在公司年报中出现的次数来度量公司的大数据应用程度。关键词的选取借鉴了以往文献(Chen etal.,2012; McAfee&Brynjolfsson,2012; Farboodi etal,2019)、政府文件以及业界报告等。我们一方面紧扣大数据的定义;另一方面则尽可能地避免了选择的随机性,按照普适性原则进行筛选。表1展示了本文构造变量所依据的“大数据”相关关键词,并详细阐释各个关键词的定义及其与大数据应用之间的紧密关联。本文将最核心的大数据应用的衡量指标(lnBigdata)具体定义为:公司年报中提及表1中大数据相关关键词的次数加一后取对数。由于大数据应用情况随年份增长趋势明显,本文将lnBigdata按照“公司—年份”的观测值确定每年缩尾(winsorize)上下极值各1%。 本文主要的被解释变量是公司估值,用托宾Q值(Tobin’sQ)来衡量,这是常见的刻画公司绩效和成长性的指标。 本文的控制变量包括:公司规模(lnAssets)、公司杠杆率(Lev)、固定资产比率( PPE_TA)、公司年龄(lnAge)、国有性质的虚拟变量(SOE)、销售收入增长率( SalesGrowth) 和总资产收益率(ROA)。 表2报告了主要变量的描述性统计结果。在2006—2017年间,共有20623个公司—年度观测值,覆盖了绝大部分A股上市公司。其中大数据应用程度指标(lnBigdata)的均值为0.180,中值为0,标准差为0.508,说明样本中公司的大数据应用程度存在很大差异。托宾Q值(Tobin’s Q)的均值是2.485,与其他文献中上市公司的数据统计量相吻合(吴超鹏和唐菂,2016)。 1、中国上市公司的大数据应用整体情况与变化
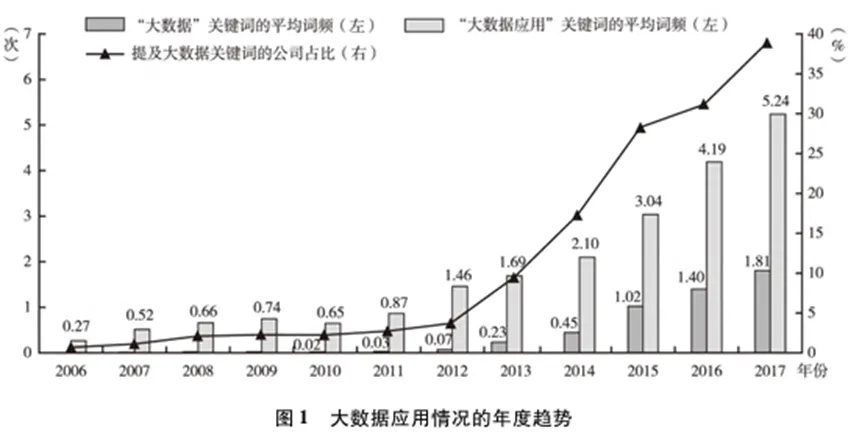
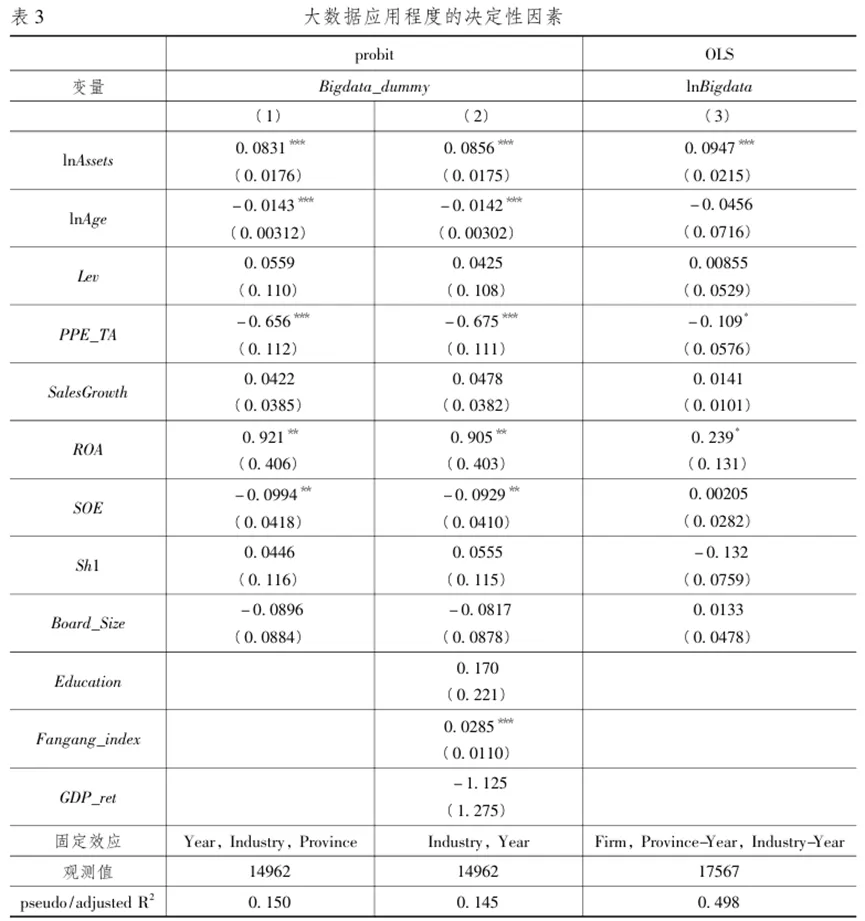
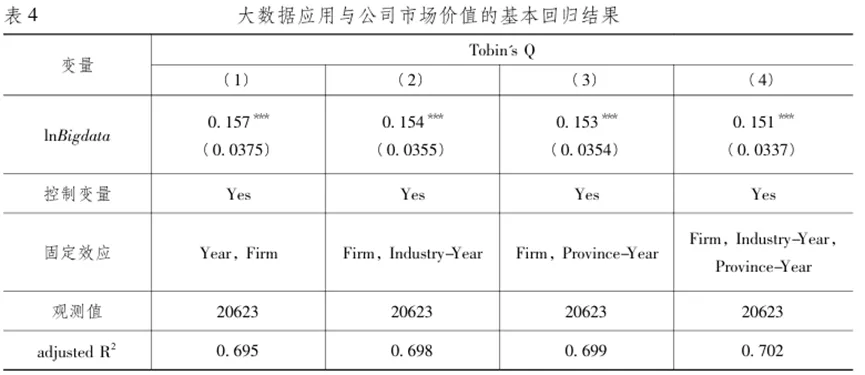
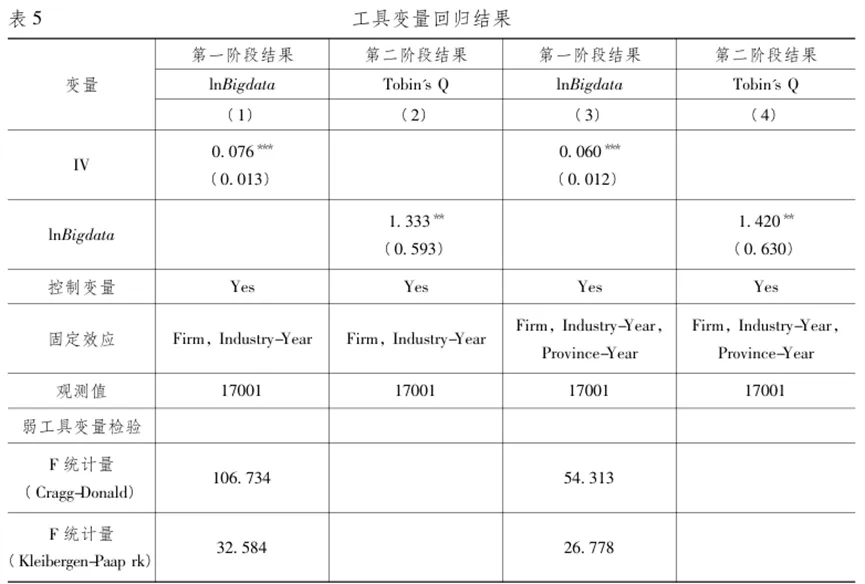
图1反映了2006—2017年间公司层面的大数据应用程度的变化趋势。可以看出,在2012年之前公司年报中提到“大数据”这一关键词的平均次数较低,之后公司提及“大数据”的平均次数从2012年的0.07次快速增长到2017年的1.81次,涵盖的公司数量占比从不足5%上升到38.93%。“大数据应用”关键词指表1中列举的关键词集合,其出现次数也呈现出类似的趋势。上述趋势与中央、各省市出台大数据行动计划的时间较为吻合。本文将大数据指标与公司其他财务数据进一步匹配,最终保留20623条观测值用于后续分析。 本文分别采用probit(模型1)和OLS(模型2)模型分析大数据应用程度的决定因素: 其中,i代表企业,t代表年份,j代表行业,p代表省份;模型(1)的被解释变量为公司年报中是否提及大数据相关关键词的虚拟变量(Bigdata_dummy) ;模型(2)的被解释变量为公司年报中披露大数据相关关键词的频率加一后取对数( lnBigdata)。Xijp,t-1代表一系列可能影响公司的大数据应用程度的滞后一期变量。其中公司规模(lnAssets)、年龄(lnAge)、杠杆率(Lev)、固定资产比率(PPE_TA)、销售收入增长率(SalesGrowth)、总资产收益率(ROA)、股权的国有性质(SOE)的定义与本文数据部分一致。公司治理变量包括第一大股东持股比例(Sh1),第一大股东持有股数占总股数的比重;董事会规模(Board_Size),董事会人数取对数。随时间变化的省级层面的因素包括:公司注册地所在省份的教育程度(Education),即大专以上学历人数占比;市场化程度(Fangang_index),即王小鲁等(2019)的地区市场化指数; GDP年度增速(GDP_ret) 。 模型(1)中的Indj代表行业固定效应,Yeart代表年份固定效应;模型(2)还控制了省份—年的固定效应(δpt)和行业—年的固定效应(γjt)以控制潜在的公司所处地区经济环境和行业发展等因素的影响,控制了公司层面的固定效应(μi)以控制公司不随时间变化的特质性;ηijpt代表随机误差项,标准误在企业和年份层面上进行双向聚类。 表3汇报了大数据应用程度的决定性因素的分析结果。由于大数据投入在时间上可能存在序列相关性,第1列和第2列仅保留公司首次在年报中披露“大数据”相关关键词的年份及其之前年份的观测值,剔除了首次披露之后年份的数据,考察了公司开启大数据相关投资的决定性因素。被解释变量为大数据披露虚拟变量(Bigdata_dummy),采用Probit模型进行估计。第1列控制了行业层面和省份层面的固定效应,第2列仅控制了行业层面的固定效应,加入省份层面滞后一期的相关指标。第3列报告了基于大数据应用程度的连续变量(lnBigdata)和全样本的分析。综合表3的结果发现:规模较大的公司、有形资产占比低、盈利能力强的公司更可能应用大数据;所在地区市场化程度越高,上市公司越可能应用大数据。 本文使用以下基准模型研究大数据应用程度对公司在股票市场上价值的影响: 其中,Yijpt为第t年p省份j行业的i公司市场价值指标,即托宾Q值(Tobin’s Q) ;核心解释变量BigDataijpt表示公司层面的大数据应用程度(lnBigdata),即公司年报中披露大数据相关关键词的频率加一后取对数;Controlsijpt代表相关控制变量,包括企业的规模、杠杆率、固定资产比率、年龄、股权的国有性质、销售收入增长率和总资产收益率。δpt表示“省份—年份固定效应”以控制不同地区随时间变化的特征,γjt表示“行业—年份固定效应”以控制不同行业随时间变化的特征,μi代表公司固定效应。ξijpt代表随机误差项,标准误在企业和年份层面上进行双向聚类。我们重点关注系数γ1的符号及其显著性,其经济含义是大数据应用对公司市场价值的影响。 表4报告了模型(3)估计结果。由于回归系数与标准误的估计结果可能较大程度上受到固定效应的影响,第1列至第4列考察不同固定效应的控制对研究结论的影响,以确保结果的稳健性。第1列至第4列中lnBigdata的系数均在1%的水平上显著为正,即公司的大数据应用程度越大,其市场价值越高。可以看出,大数据应用显著提高公司的市场价值这一结论非常稳健。以第(4)列为例,披露了一个“大数据”相关关键词的公司的托宾Q值,比没有披露任何相关关键词的公司平均而言高出4.21%( ln2×0.151/2.485)。这说明大数据应用对公司市场价值的影响在经济意义上也是显著的。总体而言,表4的研究结果表明公司应用大数据越多,其在股票市场上的价值越高。考虑到研究结果的可靠性,下文的回归模型都以控制最严格的固定效应为基准。 就本文研究问题而言,内生性主要有以下来源:第一,反向因果。绩效好、估值高的公司现金流充足,外部融资成本低,更有能力去付出较高成本来投入大数据技术和搭建数据平台等,进而导致回归估计系数被高估。第二,遗漏变量,可能存在难以观测的因素同时与公司的大数据应用和股票市场价值相关。例如,应用大数据的公司可能处在快速发展时期或者管理层有前瞻性进而带动公司的成长性,造成回归估计系数被高估;但公司如果面临较少的增长机会或者预期到业绩的负面冲击,也会因较低的机会成本而进行数字化转型,造成回归估计系数被低估。总体而言,OLS回归系数估计偏误的方向从理论上并不明确。 本文构建工具变量来缓解可能存在的内生性问题。工具变量的设计基于2009年启动的“基础学科拔尖学生培养试验计划”,又称“珠峰计划”,由教育部联合中组部、财政部发起,旨在培养拔尖创新人才,推动高等教育改革,推动创新型国家的建设。 本文主要关注的解释变量是大数据应用程度指标(lnBigdata),人力资源成本是大数据决策的关键。理工科专业培养了与大数据应用息息相关的数理能力、编程能力和工程设计思维,因此理工科专业人才在大数据应用中发挥着至关重要的作用。以往的业界经验和学术研究都证实了理工类技术人才的匮乏是公司采用大数据或人工智能技术的瓶颈(Tambe,2014; Babina etal.,2021)。“珠峰计划”第一批试点针对人群为理工科学生,它的实施增加了理工类人才供给,进而有效地缓解了试点大学附近的大数据人才供给不足的问题,降低了附近公司应用大数据的劳动力成本。 该计划的第一批试点于2009年正式启动,大部分高校于2010年正式开始实施,因此受该计划影响的第一批学生大部分是2010年入学的本科生,受影响学生毕业的年份为2014年及之后的年份。2014年大学生毕业的时点为年中,该年份难以完全被归为受影响之前或之后的时间段,因此本文在工具变量回归分析中均将2014年的观测值剔除。工具变量( IVit)构造如下: 其中,i代表公司,k代表第一批试点高校,c代表公司办公地点所在的城市;distanceik表示通过上市公司i办公地点的经纬度与高校k主校区的经纬度计算的直线距离(单位为公里);n为第一批试点高校的数目(n=17);Nc表示2014年公司i的办公地点所在城市c中的上市公司的总数量;Postt为时间虚拟变量,2014年之后设为1,2014 年之前则设为0。根据工具变量的设计,上市公司与试点大学之间的距离越近(即distanceik越小),该公司受到政策的辐射力度越大,越有可能提高大数据应用程度;而上市公司办公地点所在城市的上市公司数目越多(即Nc越大),则上述辐射力度越可能被削弱。因此,该工具变量从理论上满足工具变量的相关性要求。此外,该工具变量很难通过其他渠道对公司层面的市场价值产生影响,理论上满足排他性要求。表5报告了工具变量回归的结果和相关检验。由于工具变量的变动很大程度上依赖于公司所地,因此第1—2列没有控制“省份—年”固定效应;第3—4列控制了全面的固定效应。两者结果一致。以第3—4列为例,第3列报告了第一阶段的回归结果,即核心变量lnBigdata回归到工具变量上,发现工具变量的系数显著为正。这表明在政策之后,距离试点高校越近的上市公司对大数据应用程度越高,与预期相符。第一阶段的Cragg-Donald F统计量为54.313,Kleibergen-Paap rk F统计量为26.778,远高于Stock-Yogo弱工具变量检验(零假设是弱工具变量)的10%临界值16.38,说明工具变量满足相关性假设。此外,工具变量与模型(3)的残差项的相关性非常微弱(相关系数0.018)。第二阶段回归中大数据应用指标的系数仍然在5%水平上显著为正,即处理了内生性问题后,大数据应用提高公司市场价值的基本结论不变。 为了进一步验证结果的可靠性,本文从如下多个角度进行了稳健性检验。 更换大数据衡量指标。首先,词频数据可能存在一定的噪音。为此,本文将lnBigdata更换为虚拟变量Bigdata_dummy,代表公司在年报中是否披露了大数据相关的关键词。此外,我们构造分类变量,该变量取值为0表示公司年报中没有披露任何大数据相关关键词;如果公司年报中披露了相关关键词,则分年份按照词频由小到大排序并三等分,前1/3观测值的分类变量取值为1,中间1/3取值为2,后1/3取值为3。其次,我们还关注了大数据词频密度,即“大数据相关关键词在公司年报中出现的总次数除以该年报的总词汇量(单位:百)”,以反映大数据信息在年报中出现的密度。再次,还考量了更为广义的关键词集合的词频变量,③即除了大数据自身定义之外,还包括数据收集、处理和应用相关的技术、平台和资源(Saunders&Tambe,2013; Srinivasan&Chen,2020)。最后,为了避免所选关键词的行业特质性的干扰,进一步开展如下工作:一是在词典中剔除与行业相关的关键词,即公司所在行业出现的平均次数最高的一个关键词;二是剔除大数据应用指标中的行业趋势,将lnBigdata减去所在行业当年的lnBigdata均值(demean by industry-year),从而剔除“行业—年”层面的共同度量偏差。上述更换大数据衡量指标的结果均稳健。 更换研究样本。第一,为了验证信息技术类行业同样适用于本文的分析结论,我们将A股全部行业的上市公司作为研究样本。第二,由于金融业公司的资本结构和盈利模式与其他公司存在较大差异,我们在基准样本的基础之上剔除金融业公司。最后,为了避免企业因为追逐热点而在年报中虚假披露大数据信息,我们仅使用大数据发展早期的样本(即2014年及之前的数据)进行分析。上述所有更换研究样本的方案取得的结果均与结论一致。 更换聚类方式。为了检验不同的聚类方式下回归结果的稳健性,本文进一步分别采用公司层面和“省份—行业”层面的聚类方式,结果均稳健。 1、生产效率和研发投入
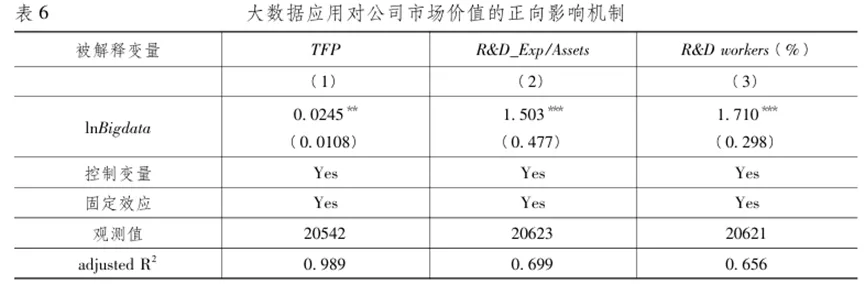
为了检验生产效率提高的渠道是否有效,借鉴以往文献(Liu&Lu,2015; Liu&Qiu,2016),本文采用全要素生产率(TFP)来衡量公司的生产效率,考察大数据应用程度对公司生产效率的影响。本文采用当前主流的LP方法(Levinsohn&Petrin,2003)估算公司的全要素生产率。具体而言,按照证监会《上市公司行业分类指引(2012年版)》中的二级行业划分标准,本文利用销售收入、员工数目、固定资产和中间投入的信息,分行业来估计TFP。将TFP作为被解释变量执行模型(3)的回归,表6中第1列的结果表明: lnBigdata的估计系数显著为正。这表明大数据的应用帮助公司显著提高了自身的生产效率。
表 6 中第 (2) 列和第 (3) 列汇报了大数据应用对公司研发强度的影响。本文从 R & D 的资金投入和人员投入两个角度来衡量公司的研发强度 : 第 (2) 列的被解释变量是R& D 支出除以滞后一期的总资产 (R & D_Exp/Assets) ,其中总资产以千计 ; 第 ( 3) 列中的被解释变量是研发人员在所有员工中所占比例 (R & Dworkers) 。同样采用模型 (3) 进行回归,结果发现大数据应用程度的提高对公司的研发强度有显著的正向影响,从而印证了影响渠道 : 大数据应用通过促进公司研发来提高其市场价值。
2 、大数据应用中的摩擦
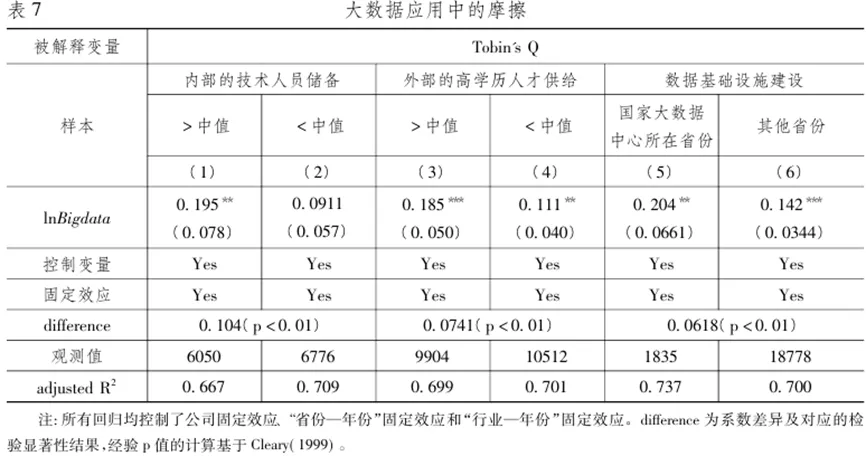
为验证人才需求方面的摩擦,我们分别从公司内部技术人员储备和公司所在地区的外部高学历劳动力供给两个层面进行检验。首先,我们分析在不同的技术人员储备的子样本下,大数据应用对公司价值影响的差异,从而体现公司内部技术人员储备带来的摩擦。具体而言,基于公司在样本初期员工中技术或研发人员占比,行业内的中位数将公司样本划分为两组,并分别基于这两组子样本来估计模型 (3) 。结果在表 7 的第 (1) — (2) 列报告,第 (1) 列的 lnBigdata 系数估计值为 0.195 且在 5% 置信水平下显著,而第 (2) 列的系数估计则不显著,两者之间的系数差异显著。因此,只有内部技术人员储备较为充足的公司能更好地将大数据转化为公司的市场估值。
其次,我们利用不同地区之间的高学历劳动力供给情况的差异,分析基准效应的异质性。在大数据与实体经济的融合过程中,劳动力与组织管理的同步革新离不开当地劳动力市场中高素质人才的供给(Tambe,2014; Babina et al.,2021)。因此,我们根据不同省份劳动力市场供给条件的差异,进行分样本检验。具体而言,我们计算了公司所在省份的大专以上学历的人口占比,按照每年的中位数将公司样本划分为两组,并分别基于这两组样本来估计模型(3),结果在表7的第(3)列与第(4)列中报告。结果表明,第(3)列的lnBigdata系数估计值为0.185且在1%置信水平下显著;而高学历劳动力供给较少的地区第(4)列对应的系数仅为0.111。两者之间的系数差异显著(p值<0.01)。因此,高学历劳动力供给充足的地区的公司能够更好地将大数据转化为公司的市场价值。 为了验证技术支持方面的摩擦,我们以公司所在省份是否拥有“国家大数据中心(包括北京、贵州、乌兰察布)”作为所在环境的数据基础设施建设情况的度量,将所有样本划分为位于“国家大数据中心所在省份”和“其他省份”的两组子样本,并分别基于这两组样本来估计模型(3),结果在表7的第(5)列与第(6)列中报告。结果表明,位于数据基础设施建设好的地区的公司能够更好地实现大数据对公司的增值效果,两组子样本的系数估计值之间差异显著(p值<0.01)。 不同类型公司的大数据储备有所不同,大数据应用的成本也存在差异,将大数据转化为企业价值的动力也不尽相同。本部分从公司规模、国有性质、行业竞争程度探讨大数据应用对公司市场价值影响的异质性。 大数据应用对不同规模公司的影响可能存在差异。Begenau etal.(2018)发现,大公司的数据更为丰富,因此基于大数据的预测更精确,从而降低生产的不确定性和融资成本。因此,大公司的大数据应用可能对市场价值的提升效果更好。但是,相对于大公司,小公司受到分析师的追踪分析和投资者的关注不足,自身生产经营中和外部资本市场上的信息不对称程度更为严重(Botosan,1997)。因此,大数据的应用对于小公司获得更多信息来提高预测精度的意义更为重大。而Farboodi et al.(2019)则认为公司的初始规模并不是决定其是否成功的关键因素。为了厘清上述逻辑,我们按照总资产是否大于行业中位数构造虚拟变量,并在模型(3)中引入它与大数据应用指标的交乘项。结果发现,小公司更能从大数据应用中实现市场价值的提高。 大数据应用对国有公司和非国有公司的市场价值可能会产生不同的影响,原因在于这两类公司在经营目标、外部经营环境和公司内部治理等方面存在显著差异: (1)在经营目标方面,非国有公司更加注重追求经济效益(姚洋和章奇,2001),而国有公司会更注重社会和政治目标(林毅夫等,2004)。因此非国有公司会更有动力利用数据挖掘信息和提高生产效率,进而获得更高的市场估值;而国有企业的大数据信息披露更可能是出于政策性目的,可能不会影响公司的市场价值。(2)在外部经营环境方面,国有公司相比于非国有公司面临更优越的外部经营环境,包括更易获得的银行贷款和更多政策优惠(Allen et al.,2005),因此挖掘大数据背后价值的动力不足。(3)从公司的内部治理角度,由于没有明确的所有者,国有企业容易被内部人控制,因此公司治理水平更弱(钱颖一,1999),进而导致国有企业的投资效率低,大数据无法发挥为公司增值的效果。我们在模型(3)中加入大数据应用与国有性质虚拟变量的交乘项,结果发现大数据应用对非国有公司市场价值的提升作用较大且在统计意义上显著,但是对国有公司的影响很小且为负,与上述推论完全一致。因此,大数据应用可能会加大非国有公司和国有公司之间的效率和估值差异。 不同行业层面的竞争程度下,大数据应用对企业的影响也可能有所不同。一方面,根据Coibion et al.(2018)的研究,竞争更激烈的行业中的公司拥有更多市场环境的信息,也更愿意提高对信息的挖掘程度和利用效率,因此它们在应用大数据后能够更准确地预测各个经济变量。另一方面,Melville et al.( 2007)发现处于竞争压力下的企业会更多地利用信息技术类资产(例如大数据分析) 来开拓新的商业模式、决策过程等,从而实现创新能力和生产力的提高。因此,竞争激烈行业的公司可能更有动力利用大数据来提高生产效率,实现企业增值。我们以证监会分类的二级行业内所有样本行业主营业务利润率标准差的倒数来衡量该行业的竞争程度(Nickell,1996),按照中位数生成虚拟变量,与大数据应用指标交乘后加入模型(3)中进行估计。结果与推论一致:交乘项系数显著为正,即大数据应用对公司市场绩效的提升效果在竞争行业中更为显著。 本文发现,不同公司在生产经营过程中应用大数据的概率有所不同。规模较大、有形资产比例较低、盈利能力较强,以及所在地区市场化程度较高的公司更可能应用大数据。而大数据应用能够显著提高公司的市场价值。本文通过利用2009年启动的“基础学科拔尖学生培养试验计划”来构造工具变量,缓解了内生性问题,得到了一致结论。机制分析表明,大数据的应用显著提高了公司的生产效率和研发投入,进而促进了公司市场价值的提升,而技术和人才供给的匮乏可能会阻碍大数据应用对企业的增值效果。大数据应用对不同公司市场价值的积极影响在小规模公司、非国有公司和竞争激烈的行业中尤为显著。 本文的研究结论对于中国企业的大数据应用与政策设计有以下几点启示。第一,大数据的应用切实提高了市场价值,推动企业数字化转型的意义深远。第二,技术和人才的供给是企业高效利用大数据的关键所在。第三,不同公司与大数据的融合深度和价值转化效率存在差异。
分享人:童安琪
原文:张叶青,陆瑶,李乐芸.大数据应用对中国企业市场价值的影响——来自中国上市公司年报文本分析的证据[J].经济研究,2021,56(12):42-59.
文献来源:
https://kns.cnki.net/kcms2/article/abstract?v=Jz5IuRg0t02LkD3PoUZLjArn2hqU7S6wlS6FkL1voxcJhED0Zdn4L2fCYtSSyReFP6P8HHEDQLL6r4trM5YMRhQmLocsNzY4xDvKsp2ZAkroIZ3qjQDnGfIJfR5yMgpuw8UZfHjCVdBMrJnz2iWSTVxWwWhMqKRaqhPYLwTZGUG9BSYZJQ6Vaw==&uniplatform=NZKPT&language=CHS
 夜雨聆风
夜雨聆风