 夜雨聆风
夜雨聆风





MySQL死锁全解析:从源码流程到避坑实战

你有没有遇到过线上MySQL突然卡住?业务日志报出”Deadlock found when trying to get lock”?作为后端开发,死锁就像隐形的地雷,轻则拖慢业务,重则直接导致服务雪崩。本文从InnoDB源码层面拆解死锁的本质,带你看懂死锁检测、成因和避坑方案,彻底搞定这个高频生产问题。
一、先搞懂:MySQL死锁到底是什么?
很多开发者觉得死锁就是两个事务互相等锁,但其实从InnoDB源码来看,死锁是多个事务因循环等待彼此持有的资源而陷入永久阻塞的状态,必须满足四个必要条件:互斥、请求与保持、不可剥夺、循环等待。不过今天我们不只是讲理论,而是从源码层面拆解每个条件的实现。
二、InnoDB锁的源码基础:行锁与间隙锁
InnoDB的锁是基于索引实现的,我们先看核心的锁结构体代码:
// 简化后的InnoDB行锁结构体
struct lock_t {
// 锁所属的事务
trx_t* trx;
// 锁的类型:共享锁(S)、排他锁(X)、间隙锁(GAP)
ulint type_mode;
// 锁对应的记录或者间隙
const dict_index_t* index;
// 锁的范围
const rec_t* rec;
};
InnoDB的行锁分为记录锁(Record Lock)和间隙锁(Gap Lock),还有Next-Key Lock(记录锁+间隙锁)。比如当我们执行SELECT * FROM user WHERE id = 1 FOR UPDATE的时候,InnoDB会对id=1的记录加上排他记录锁,如果id不是主键索引,还会加间隙锁。间隙锁的存在是为了解决幻读问题,但也会增加死锁的概率。
三、死锁检测的源码流程:从等待图到环检测
InnoDB的死锁检测是在lock_wait_graph模块实现的,整个流程可以用下面的UML图展示:
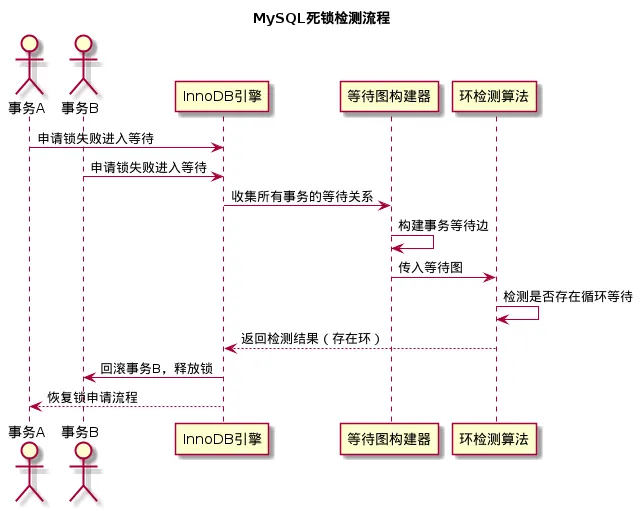
具体的源码流程是:
1. 当事务申请锁失败时,会被加入等待队列
2. InnoDB会调用lock_wait_graph_build构建等待图,每个事务是节点,等待关系是边
3. 调用lock_wait_graph_detect_cycle进行环检测,这里用到的是深度优先搜索(DFS)算法
4. 如果检测到环,就会选择回滚代价最小的事务(通常是行数最少的事务),释放其持有的锁,打破循环
我们可以看一下简化后的检测代码:
// 简化的死锁环检测代码
bool lock_wait_graph_detect_cycle(lock_wait_graph_t* graph) {
for each node in graph->nodes {
if (node is not visited) {
if (dfs_detect_cycle(node, visited, rec_stack)) {
return true; // 存在死锁环
}
}
}
return false;
}
bool dfs_detect_cycle(lock_wait_node_t* node, hash_table_t* visited, hash_table_t* rec_stack) {
hash_insert(visited, node->trx->id);
hash_insert(rec_stack, node->trx->id);
for each neighbor in node->wait_for->edges {
if (hash_get(rec_stack, neighbor->trx->id)) {
return true; // 找到环
}
if (!hash_get(visited, neighbor->trx->id)) {
if (dfs_detect_cycle(neighbor, visited, rec_stack)) {
return true;
}
}
}
hash_delete(rec_stack, node->trx->id);
return false;
}
四、常见生产死锁场景源码分析
场景1:事务执行顺序颠倒导致的死锁
比如两个事务分别执行:
-- 事务A
UPDATE order SET status = 1 WHERE id = 1;
UPDATE order SET status = 2 WHERE id = 2;
-- 事务B
UPDATE order SET status = 2 WHERE id = 2;
UPDATE order SET status = 1 WHERE id = 1;
从源码来看,事务A先持有id=1的排他锁,再申请id=2的锁;事务B先持有id=2的排他锁,再申请id=1的锁,这样就形成了循环等待,触发死锁检测。InnoDB的死锁检测会在1-2秒内发现这个环,然后回滚其中一个事务。
场景2:间隙锁导致的死锁
比如两个事务同时插入id在10-20之间的数据:
-- 事务A
INSERT INTO order(id, status) VALUES(15, 1);
-- 事务B
INSERT INTO order(id, status) VALUES(16, 1);
InnoDB的间隙锁会锁住id=10到20之间的间隙,两个事务都需要获取这个间隙的锁,就会形成死锁。源码中,间隙锁的申请会在lock_gap_lock函数中处理,当两个事务同时申请同一个间隙的锁时,就会互相等待。
场景3:索引失效导致的全表锁
如果我们执行UPDATE order SET status = 1 WHERE username = 'test',而username字段没有索引,那么InnoDB会进行全表扫描,给每一行记录都加上排他锁,这时候如果有多个事务执行这个语句,就会形成死锁。源码中,当索引失效时,InnoDB会升级为表锁,这时候锁的范围会变得非常大,死锁的概率也会急剧上升。
五、避坑方案:从源码角度落地的解决方案
- 固定事务执行顺序:让所有事务按照相同的顺序访问资源,比如所有事务都先更新id小的记录,再更新id大的记录,这样就不会形成循环等待。比如上面的场景1,我们可以让所有事务都先更新id=1,再更新id=2,这样就不会出现死锁。
- 减少锁持有时间:不要在事务中执行耗时的操作,比如远程调用、IO操作,尽量把耗时操作放到事务之外,源码中事务的锁持有时间和事务执行时间成正比,所以缩短事务执行时间就能减少死锁概率。比如把远程调用放到事务提交之后执行。
- 合理调整隔离级别:比如把RR隔离级别降级为RC,这样InnoDB不会使用间隙锁,减少锁的范围,降低死锁概率。不过降级隔离级别会带来幻读的问题,需要根据业务场景权衡。
- 使用较小的事务:尽量把大事务拆分为小事务,比如批量更新的时候,拆分成多个小批量更新,每个事务的锁持有时间更短。比如一次更新1000条数据拆成10次更新100条数据。
- 正确配置死锁检测参数:InnoDB默认会开启死锁检测,检测超时时间是50秒,可以通过
innodb_deadlock_detect参数配置。不要关闭死锁检测,否则死锁会导致事务永久阻塞,反而更麻烦。
六、线上死锁排查实战
当线上出现死锁的时候,我们可以用show engine innodb status命令查看死锁日志,日志中会包含死锁的事务信息、锁的信息和等待图。比如:
------------------------
LATEST DETECTED DEADLOCK
------------------------
2024-05-20 12:00:00 0x7f8d12345678
*** (1) TRANSACTION:
TRANSACTION 12345, ACTIVE 10 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 2 lock struct(s), heap size 1136, 1 row lock(s)
MySQL thread id 1234, OS thread handle 1234567890, query id 123456 localhost root updating
UPDATE order SET status = 1 WHERE id = 1
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 123 page no 45 n bits 728 index PRIMARY of table `test`.`order` trx id 12345 lock_mode X locks rec but not gap waiting
*** (2) TRANSACTION:
TRANSACTION 67890, ACTIVE 5 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 2 lock struct(s), heap size 1136, 1 row lock(s)
MySQL thread id 6789, OS thread handle 9876543210, query id 678901 localhost root updating
UPDATE order SET status = 2 WHERE id = 2
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 123 page no 45 n bits 728 index PRIMARY of table `test`.`order` trx id 67890 lock_mode X locks rec but not gap waiting
*** WE ROLL BACK TRANSACTION (1)
这个日志清晰的展示了两个事务的等待关系,我们可以快速定位死锁的原因。
好了,今天的死锁干货就到这里。其实死锁本质就是资源竞争的循环等待,只要我们摸透了InnoDB锁的底层逻辑,就能避开绝大多数坑。你线上遇到过哪些奇葩死锁?比如用了索引失效导致的全表锁?评论区聊聊,我们一起拆解~