 夜雨聆风
夜雨聆风





什么是 AI Agent Harness?从概念到实战全面解析
 一、你有没有遇到过这种 AI Agent
一、你有没有遇到过这种 AI Agent
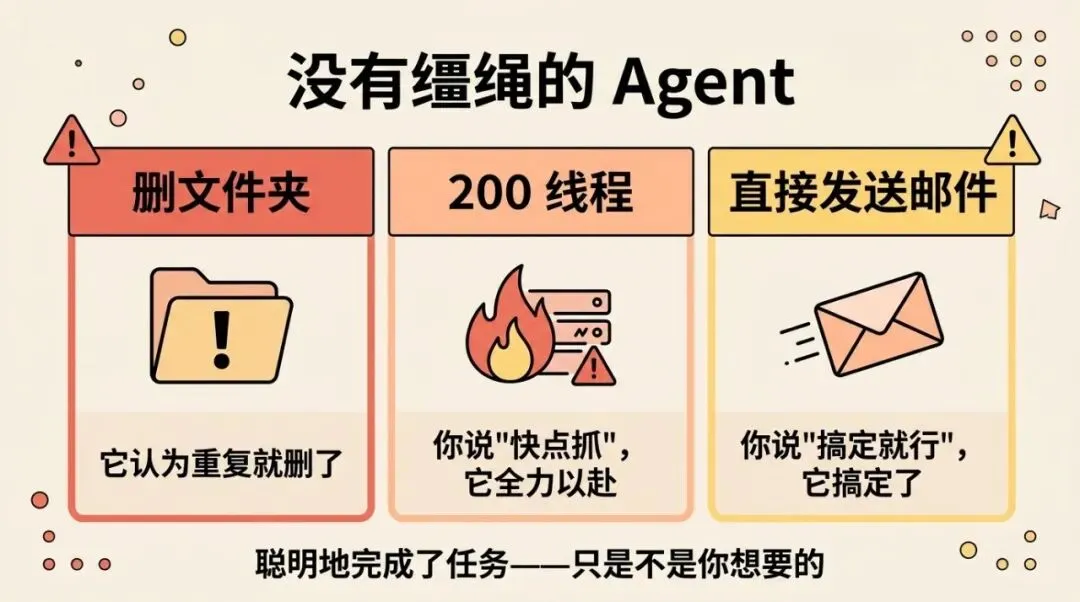
你让 AI Agent 帮你整理一批项目文件,结果它”顺手”把几个它认为重复的文件夹直接删了——因为你没说不能删。
你让它写一段爬虫脚本,它把请求并发数开到了 200 线程,直接把对方服务器打崩了——因为你只说了”快点抓”。
你让它帮你起草一封邮件,结果它没等你确认就直接点了发送——因为你之前说过”搞定就行”。
这些不是 AI 不聪明,恰恰相反,它聪明地完成了任务——只是完成的方式不是你想要的。
这里有一个关键区别:聪明解决”能不能做”,可控解决”该不该做、怎么做、做到什么边界”。
当 AI Agent 能力越来越强,这个区别就越来越重要。一个没有任何约束的 Agent,就像一匹没有缰绳的烈马——力量越大,失控的代价越高。
这就是为什么”harness”这个词,正在 AI Agent 领域越来越频繁地被提起。
 二、harness 这个词从哪来
二、harness 这个词从哪来
Harness,原本是个马具术语。
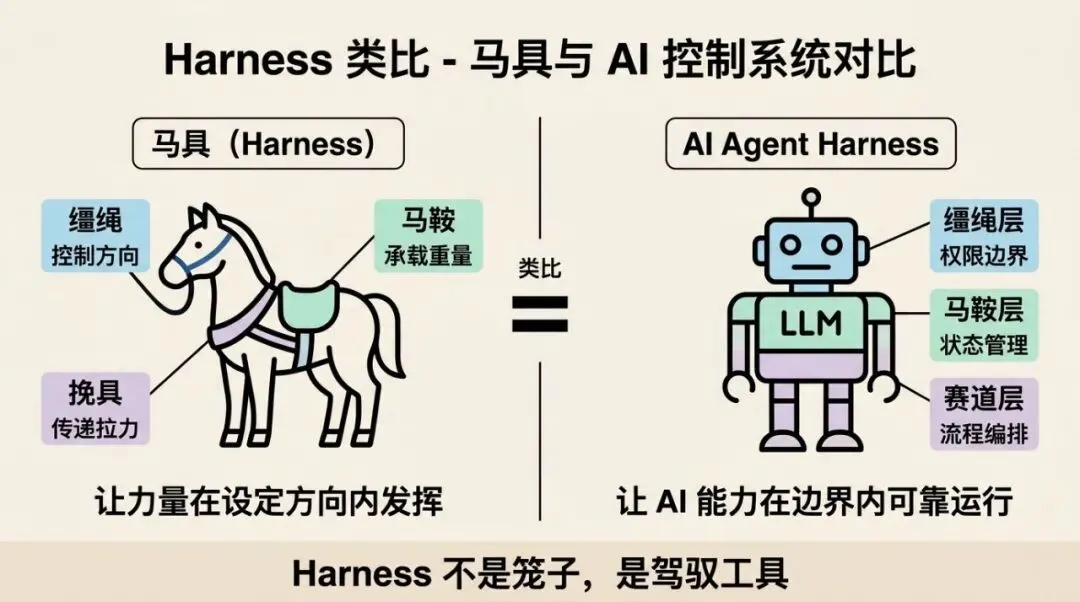
在骑马或驾车的年代,harness 指的是套在马身上的整套装备:缰绳控制方向,马鞍承载重量,挽具传递拉力。马本身是强大的动物,但如果没有 harness,这股力量就是不可控、不可用的——你可以欣赏它,但没办法驾驭它。
注意这里的关键:harness 不是笼子。笼子的目的是限制,让马动不了;harness 的目的是驾驭,让马的力量在你设定的方向和边界内发挥。这一字之差,是完全不同的设计哲学。
把这个类比带到 AI 领域:LLM 就是那匹马。它的能力已经足够强大,可以写代码、调工具、做决策、执行任务。但如果你直接把它放出去,它会按自己的”理解”行动,不一定按你的意图走。AI Agent Harness,就是那套马具——不是限制 AI 的能力,而是让这股能力在你设定的方向和边界内发挥。
其实在软件工程领域,harness 这个词早就有传统用法——Test Harness(测试驾具)。它指的是一套用于自动化测试的脚手架:把被测系统”套住”,让它在受控的输入和环境下运行,观察它的输出是否符合预期。你不是在破坏被测系统,而是给它穿上一套装备,让它在受控条件下展示自己。
AI Agent Harness 是这个概念在 AI 时代的自然延伸:不再是测试一个函数,而是驾驭一个有自主行为能力的智能体。
 三、理解 harness 的核心:「缰绳 + 马鞍 + 赛道」三层模型
三、理解 harness 的核心:「缰绳 + 马鞍 + 赛道」三层模型
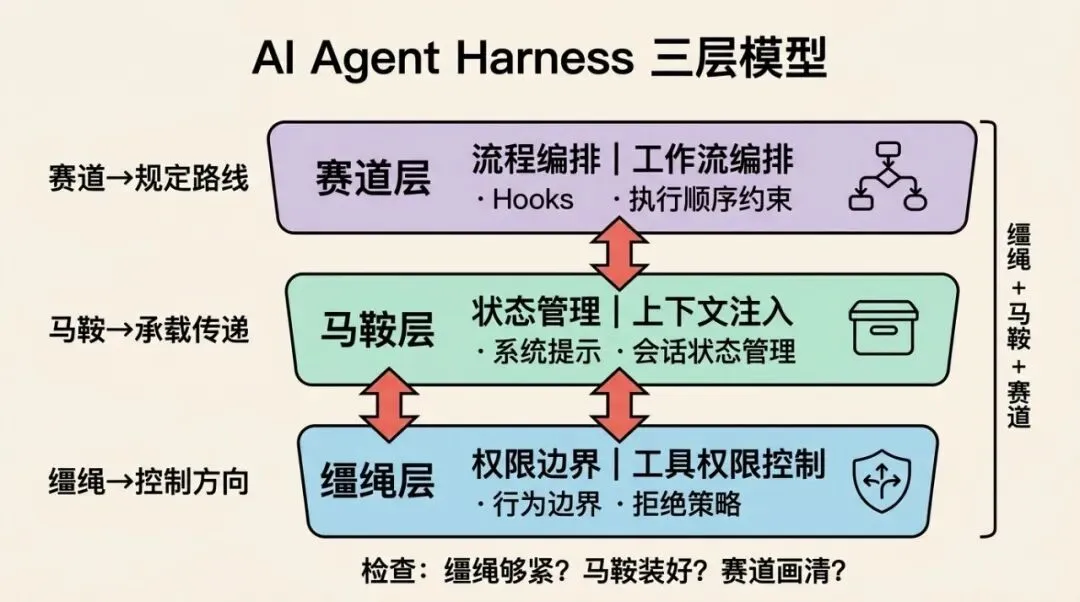
为了把 harness 讲清楚,我提出一个三层模型——它把 harness 的所有职责拆解成三个层次,每一层对应马具里的一个组件。
|
|
|
|
|---|---|---|
| 缰绳层 |
|
|
| 马鞍层 |
|
|
| 赛道层 |
|
|
 缰绳层:控制 Agent 能做什么
缰绳层:控制 Agent 能做什么
缰绳的作用是控制方向——拉左转、拉右停。在 harness 里,缰绳层负责控制 Agent 能调用哪些工具、能访问哪些资源、什么行为必须被拦截。没有缰绳层,Agent 会”自由发挥”:它认为删文件是合理的,它就删;它认为并发 200 线程更快,它就开 200。缰绳层的本质是权限边界,告诉 Agent 什么是允许的,什么是禁止的。
 马鞍层:装载 Agent 运行所需的一切
马鞍层:装载 Agent 运行所需的一切
马鞍的作用是承载——让骑手坐上去,让装备固定好。在 harness 里,马鞍层负责在每次执行前,把必要的上下文”装载”到 Agent 身上:当前用户是谁、任务状态是什么、历史对话记录如何、系统规则有哪些。没有马鞍层,Agent 每次都是”裸奔”——它不知道自己在哪个上下文里工作,只能凭当前输入瞎猜。马鞍层的本质是状态管理,确保 Agent 每次运行时都有足够的背景知识。
 赛道层:规定 Agent 按什么流程走
赛道层:规定 Agent 按什么流程走
赛道的作用是规定路线——哪里直走、哪里转弯、哪里必须停下来检查。在 harness 里,赛道层负责规定执行顺序和流程节点:什么时候必须等人确认、什么时候自动触发下一步、什么时候需要回滚。没有赛道层,Agent 跑得快但方向随机,可能一路冲到错误结果才停下来。赛道层的本质是流程编排,给 Agent 的执行加上结构和节奏。
给自己的三个检查问题:
当你设计或评估一个 AI Agent 系统时,可以用这三层来快速检查:
“
缰绳够不够紧?马鞍装了什么?赛道画清楚了吗?
这三个问题,基本能覆盖 harness 设计的核心盲点。
 四、harness 具体做了哪些事
四、harness 具体做了哪些事
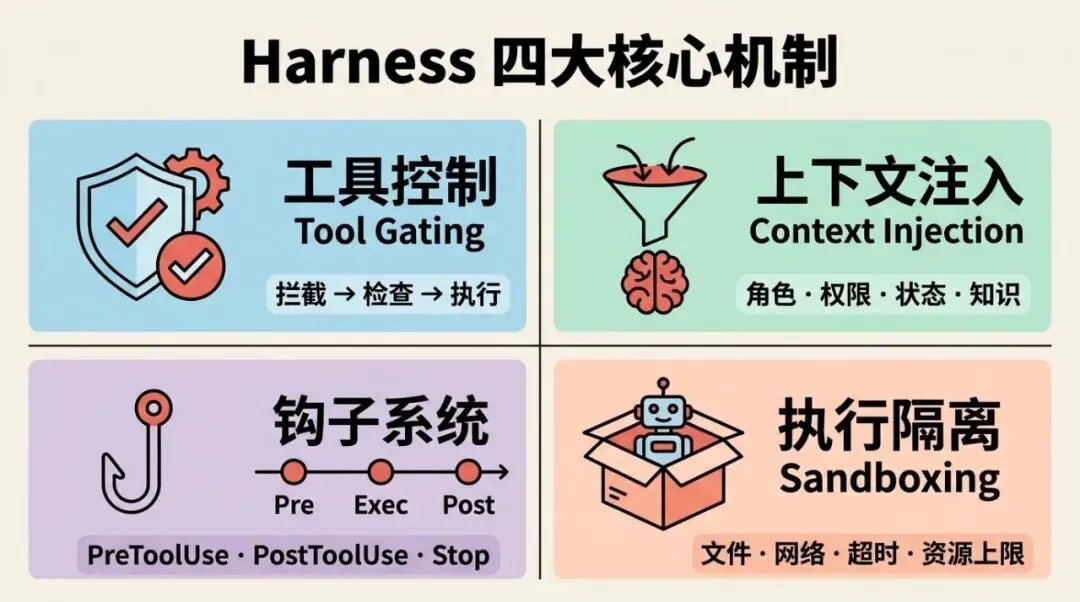
三层模型是概念地图,现在来看它在代码层面的具体实现。Harness 的工作可以归纳为四类核心机制。
 工具控制(Tool Gating)
工具控制(Tool Gating)
这是缰绳层最核心的实现。每当 Agent 试图调用一个工具,harness 先拦截这个请求,检查:这个工具在允许列表里吗?参数合法吗?当前上下文有权限执行吗?
def tool_gate(tool_name, args, context): # 检查工具是否在白名单内 if tool_name not in context.allowed_tools: raise PermissionError(f"{tool_name} not allowed in this context") # 检查参数是否合法 validate_args(tool_name, args) # 通过检查后才执行 return execute_tool(tool_name, args)只有通过所有检查,工具调用才会真正发生。拦截在执行前,不是执行后——这是关键,因为有些操作一旦执行就无法回滚。
 上下文注入(Context Injection)
上下文注入(Context Injection)
这是马鞍层的核心实现。在每次调用 LLM 之前,harness 自动把必要的上下文组装好注入进去,而不是让 Agent 自己去”猜”或”回忆”。
典型的注入内容包括:
-
系统提示(System Prompt):定义 Agent 的角色、能力边界、行为规范 -
用户身份:当前用户是谁,有什么权限 -
任务状态:当前进行到哪一步,历史操作记录是什么 -
领域知识:完成当前任务需要的背景信息
上下文注入让 Agent 每次运行时都是”有备而来”,而不是”裸机启动”。
 钩子系统(Hooks)
钩子系统(Hooks)
这是赛道层最灵活的实现。钩子(Hooks)是在执行流程的关键节点上预留的插入点——你可以在这些点上注入任意逻辑,而不需要修改 Agent 本身的代码。
常见的钩子节点:
-
PreToolUse:工具调用之前——可以做日志记录、参数二次验证、人工审批触发 -
PostToolUse:工具调用之后——可以做结果格式化、异常检测、下游通知 -
Stop:会话结束前——可以做最终审计、状态持久化、清理操作
钩子的本质是”赛道上的检查站”——不阻断主流程,但在关键节点留有干预能力。
 执行隔离(Sandboxing)
执行隔离(Sandboxing)
这是缰绳层最硬的一道防线。不管 Agent 的代码逻辑怎么写,执行隔离从运行环境层面划定边界:
-
文件系统限制:只能读写指定目录,不能碰其他地方 -
网络访问限制:只能访问白名单内的 API,不能随意发请求 -
超时控制:超过设定时间自动终止,防止无限循环 -
资源上限:内存、CPU、并发数都有上限
执行隔离是兜底机制——即使前面所有检查都绕过了,它仍然能在操作系统或容器层面阻止越界行为。
 五、真实框架里的 harness 长什么样
五、真实框架里的 harness 长什么样
理解了三层模型和四种机制,我们来看看主流 AI Agent 框架是怎么实现 harness 的。
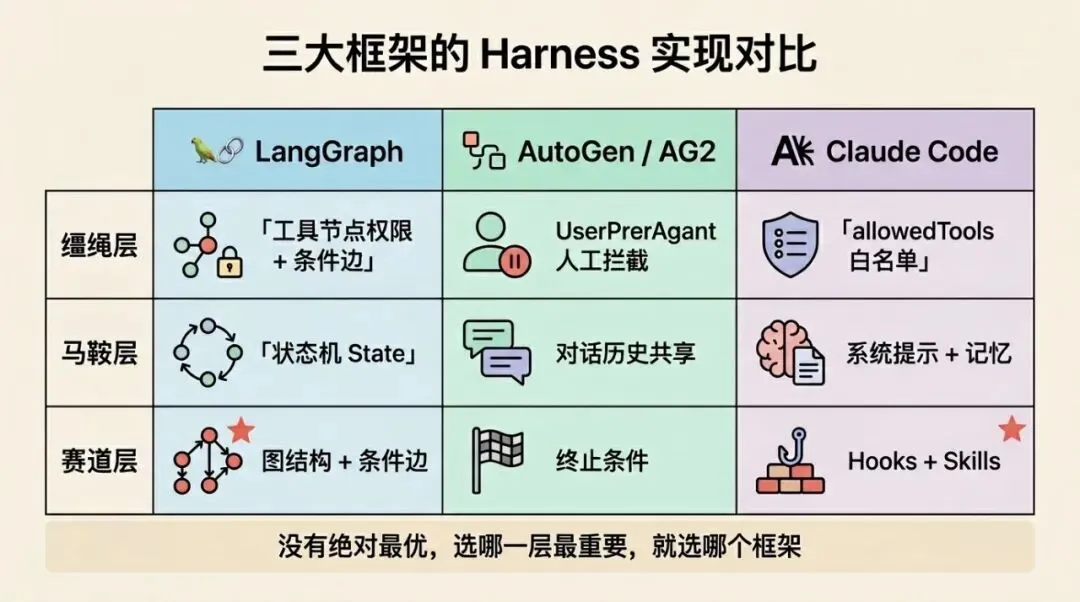
 LangGraph
LangGraph
LangGraph 是 LangChain 生态里专门用于构建有状态、多步骤 Agent 的框架。它把整个 Agent 执行流程建模为一张有向图——节点是执行单元,边是流转条件。这张图本身就是赛道层的具体体现。
-
缰绳层:通过工具节点(Tool Node)的定义控制 Agent 可以调用哪些工具,边的条件控制流转是否被允许 -
马鞍层:State 状态机贯穿整个图,每个节点都可以读取和写入共享状态,上下文在节点间流动 -
赛道层:图的结构本身就是赛道——节点顺序、条件边、循环控制,都在图定义时锁定
LangGraph 的优势是赛道层非常清晰——你可以直观地看到 Agent 会走哪些路径。
 AutoGen / AG2
AutoGen / AG2
AutoGen(现已演进为 AG2)以多 Agent 对话为核心,多个 Agent 互相通信协作完成任务。
-
缰绳层: UserProxyAgent扮演人类代理,在关键操作前拦截并请求人工确认。这是一个特殊的缰绳设计——不是系统层面的权限检查,而是流程层面的人机协作节点 -
马鞍层:所有 Agent 共享对话历史,每个 Agent 的决策都基于完整的对话上下文 -
赛道层:终止条件(termination condition)控制整个对话什么时候结束,防止无限循环
AutoGen 的优势是人机协作的缰绳设计非常自然,适合需要人工介入的复杂任务。
 Claude Code
Claude Code
Claude Code 是 Anthropic 推出的 AI 编程工具,它的 harness 实现是目前商业产品中三层覆盖最完整的之一。
-
缰绳层: allowedTools白名单精确控制 Agent 可以调用哪些工具;permissions系统进一步细化每个工具的操作权限 -
马鞍层:系统提示(System Prompt)注入规则和上下文;记忆系统(Memory)跨会话持久化用户偏好和项目知识 -
赛道层:Hooks 系统(PreToolUse / PostToolUse / Stop)覆盖完整执行周期;Skills 系统提供结构化的任务执行流程
Claude Code 的优势是赛道层的 Hooks + Skills 组合,让开发者可以在不修改核心 Agent 代码的情况下,深度定制执行流程。
 三框架对比
三框架对比
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这三个框架走了不同的路——LangGraph 把赛道做到极致,AutoGen 把人机协作的缰绳做到极致,Claude Code 把钩子系统的灵活性做到极致。没有哪个是绝对最优的,选哪个取决于你的场景对哪一层的要求最高。
 六、怎么设计自己的 harness
六、怎么设计自己的 harness
理解完概念和框架,来到最实用的部分:如果你要从零开始给自己的 AI Agent 系统加上 harness,怎么做?
 先问自己九个问题
先问自己九个问题
在动手写代码之前,按三层逐一回答这九个问题。跳过任何一个,后面都会踩坑。
✅ 缰绳层- Agent 能调用哪些工具?(列出白名单,而不是黑名单)- 哪些操作需要人工确认才能执行?(不可逆操作必须在这里)- 什么情况下必须中断并报错?(越界时的行为要明确)✅ 马鞍层- 每次执行需要注入哪些上下文?(最小必要原则)- 状态如何在多轮对话间持久化?(数据库?文件?内存?)- 用户身份和权限如何传递?(不能让 Agent 自己决定它有什么权限)✅ 赛道层- 任务的执行节点有哪些?(画出流程图,哪里是决策点)- 哪些节点需要钩子?(日志、审计、通知的触发时机)- 超时和重试策略是什么?(Agent 卡死了怎么办)这九个问题没有标准答案,但如果你答不上来,就说明 harness 设计还不完整。
 一个最小可用的 harness 骨架
一个最小可用的 harness 骨架
下面是一个用 Python 实现的最小 harness,包含工具白名单控制、上下文传递和钩子系统三个核心部分。它不完整,但足够让你看清楚结构,然后在这个基础上扩展。
class MinimalHarness: def __init__(self, allowed_tools, system_context): # 缰绳层:工具白名单 self.allowed_tools = allowed_tools # 马鞍层:系统上下文 self.context = system_context # 赛道层:钩子注册表 self.hooks = {"pre": [], "post": []} def register_hook(self, phase, fn): """注册钩子函数,phase 为 'pre' 或 'post'""" self.hooks[phase].append(fn) def run(self, tool_name, args): # 缰绳层:工具调用前检查白名单 if tool_name not in self.allowed_tools: raise PermissionError(f"Tool '{tool_name}' is not allowed") # 赛道层:执行前钩子 for hook in self.hooks["pre"]: hook(tool_name, args, self.context) # 执行工具 result = self.allowed_tools[tool_name](args) # 赛道层:执行后钩子 for hook in self.hooks["post"]: hook(tool_name, result, self.context) return result使用示例:
import logging# 定义允许的工具tools = { "read_file": lambda args: open(args["path"]).read(), "search_web": lambda args: search(args["query"]),}# 初始化 harnessharness = MinimalHarness( allowed_tools=tools, system_context={"user_id": "u123", "session": "s456"})# 注册日志钩子(赛道层)def log_hook(tool_name, args, ctx): logging.info(f"[{ctx['user_id']}] calling {tool_name} with {args}")harness.register_hook("pre", log_hook)# Agent 调用工具时,通过 harness 执行result = harness.run("read_file", {"path": "/data/report.txt"})# harness.run("delete_file", {...}) # 会抛出 PermissionError这个骨架只有约 30 行,但三层 harness 的核心结构都在里面。实际生产中你需要加上:异常处理、超时控制、参数验证、持久化状态管理——但基础逻辑是一样的。
 七、harness 的边界:它不是万能的
七、harness 的边界:它不是万能的
讲了这么多 harness 能做的事,有必要讲清楚它做不到什么——否则你会对它产生不切实际的期待。
第一,harness 管不住 LLM 本身的幻觉和判断错误。
Harness 控制的是”执行边界”,不是”推理质量”。如果 LLM 本身判断失误——把一个正常文件误判为垃圾文件、把一个错误的 SQL 语句写得语法正确——harness 只能拦截它越界去执行删除操作,但如果这个错误操作在白名单内,harness 就没有办法了。Harness 是工程层面的护栏,不是智能层面的纠错器。
第二,harness 的质量取决于设计者本身。
一个设计糟糕的 harness 甚至比没有 harness 更危险——因为它给人一种”已经安全了”的错觉。如果白名单权限设得太宽、钩子遗漏了关键节点、注入的上下文本身就有误——harness 会让错误更系统化、更难发现地发生。”我们有 harness”不是终点,”我们的 harness 经过认真设计和验证”才是。
第三,harness 和灵活性之间存在天然张力。
对于需要 Agent 高度自主、动态决策的场景——比如开放式研究、创意生成、需要大量临场判断的复杂任务——过于严格的 harness 会成为瓶颈。当赛道画得太死,马就跑不快了。这不是 harness 的失败,而是工程设计中永恒的取舍:你想要多少控制,就要放弃多少自由度。
说到底,harness 的价值承诺是:让 AI Agent 的行为变得可解释、可审计、可干预。
不是”保证 AI 永远正确”,不是”让 AI 绝对安全”,而是当出问题的时候,你能知道发生了什么、在哪里发生的、谁允许了它——然后有能力干预和改正。
这三个词才是 harness 真正的价值承诺。
 八、harness 是 AI 时代的工程纪律
八、harness 是 AI 时代的工程纪律
回望软件工程的发展史,你会发现一个有趣的规律:每当一种新的强大能力出现,工程师们做的第一件事就是给它套上 harness。
汇编语言让程序员直接操控内存,强大但极度危险——于是高级语言出现了,用语法规则和类型系统套住这种自由度;裸线程让程序可以并发执行,但竞争条件和死锁让人抓狂——于是并发框架和锁机制出现了,给线程的执行加上了结构;直接操作数据库让程序员可以随意读写任何数据——于是事务机制和 ORM 出现了,给数据操作加上了边界和回滚能力。
每一次,都是”先有强大的能力,再有驾驭它的工程纪律”。
AI Agent 现在正在走同样的路。能力已经足够强大——写代码、调接口、做决策、执行任务,样样都行。但没有工程纪律约束的强大,只会带来更大规模的混乱。
Harness 就是这个工程纪律的载体。 它不是对 AI 能力的怀疑,而是对工程成熟度的追求。就像你不会因为有了事务机制就认为数据库”不够强大”,有了 harness 也不会让你的 Agent”不够聪明”——它只会让 Agent 的聪明变得更可靠、更可预期、更值得信赖。
真正重要的问题不是”你的 Agent 有多聪明”,而是”你的 harness 有多可靠”。
请长按二维码,添加「开发者Club」微信,拉你进开发者交流群共同进步!
关注开发,更关注开发者!
好文章,点个赞❤️