当前时间: 2026-04-22 03:30:16
更新时间: 2026-04-22
分类:软件教程
评论(0)
用AI彻底改造投研流程
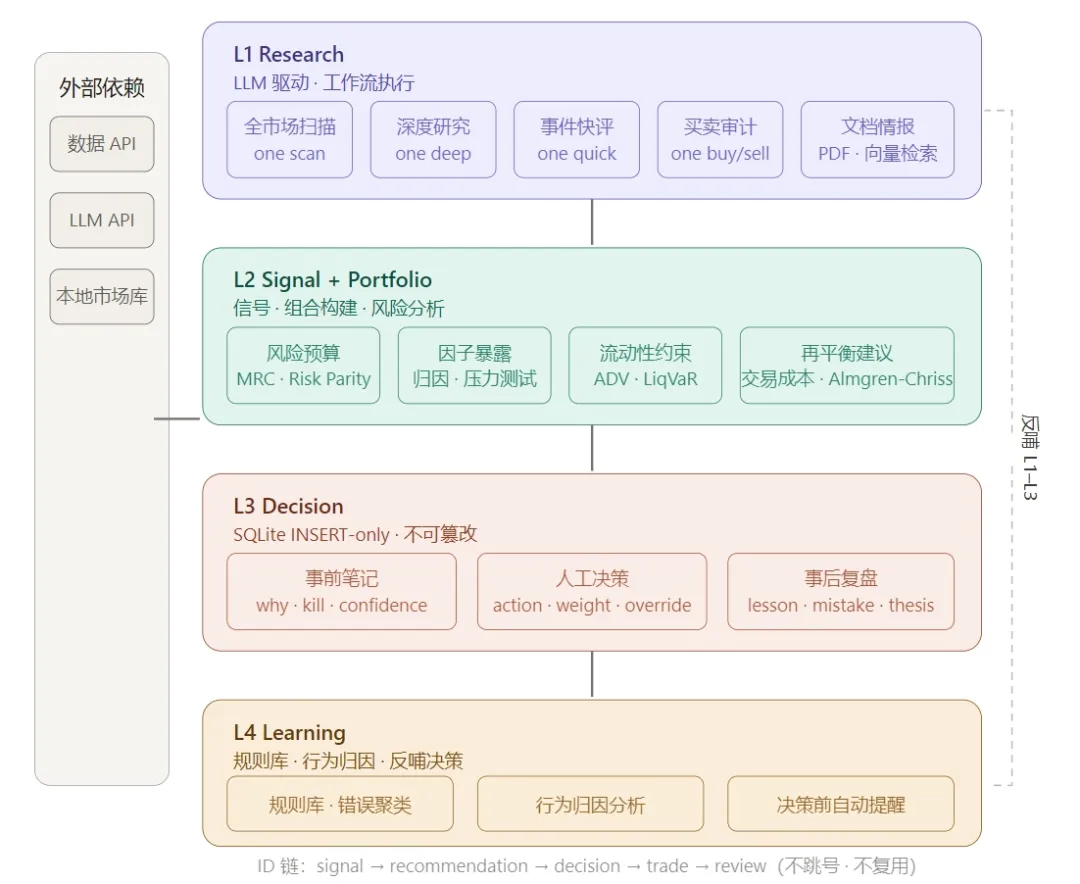
开发这套系统之前,我问过自己一个问题:一个认真做投资的个人投资者,每天花时间最多的事情是什么? 读公告、调研公司、填数据、写备忘、对比前后季度的表述变化、复制粘贴财务数字进模型……这些工作耗掉大半天,留给真正判断的时间反而所剩无几。卖方分析师有实习生团队分担,买方基金经理有研究助理跟进,但中间这个信息处理的过程耗时耗力,对精力和体力的消耗非常大。 所以我花了半年,写了一套叫 One 的系统,目标是把投研日常里所有可以工业化的部分全部内化进来,只把判断留给人。 系统是怎么工作的 用一句话描述:它是一个把研究、组合管理和决策记录整合在同一个地方的个人投研系统,四层结构从外往内分别处理信息获取、信号与组合、人工决策、以及经验积累。 第一层负责研究——扫描市场、深度分析单票、对特定事件快速评估、审计买卖逻辑。这一层由 LLM 驱动,背后是一套结构化的工作流体系,告诉模型每种研究任务应该按什么步骤、调用哪些工具、产出什么格式的报告。 第二层负责组合——信号汇总、仓位构建、风险分解。这里跑的是机构级的量化分析:风险预算分解、因子暴露、业绩归因、压力测试、流动性约束评估、再平衡建议。 第三层是决策记录——这是整套系统里我认为最重要、也最不一样的部分,后面会详细说。 第四层是学习——把每次复盘的教训汇成规则库,在下次做类似决策时自动触发提醒。这一层越用越有价值,是整个系统的长期护城河。 它替卖方分析师做了什么 在卖方机构里,研究员的日常工作有一条非常固定的流程:读文件、抽字段、更新财务模型、写研究报告。这条流程在人工操作下耗时漫长,而且大量时间花在搬运数据而不是分析判断上。 一份 10-K 年报动辄一两百页,分析师需要找到营收拆分、毛利率变化、各业务线的指引、以及管理层在风险因素一节里新增了哪些措辞。现在这套系统可以直接解析 PDF,把上述字段自动抽取出来,每个字段还附带置信度分数——没抽到的字段明确标注为”未披露”,而不是靠模型编一个数字填进去。电话会议纪要也一样:管理层语气是否变化、新的指引数字在哪里、和上季度相比哪些措辞悄悄消失了,这些过去要靠研究员反复对读的工作,现在可以自动完成。 所有文件读取之后,内容会进入一个向量数据库。这意味着你可以用自然语言检索——比如”NVDA 最近三个季度的毛利率指引”,系统会从所有已索引的文件里精确找到相关段落,而不是让你自己翻页。 分析师从公告里找到新的财务数字,手动填进 Excel 模型,对应的公式单元格随之更新,然后对比前后差异、判断哪些假设需要修正。这套系统里的金融模型模板库支持三张财务报表联动、DCF 估值、可比公司分析、以及分部加总估值四种模板。更重要的是,模型里的每个单元格都打了标签:历史事实、标准公式、假设、结论——前两类可以由系统自动更新,后两类必须人工确认。这道分界线防止了一件很危险的事:系统默默改掉了你的核心假设,而你毫不知情。 每次模型更新都会生成一份差异报告,告诉你哪些数字变了、变了多少。这比对着两个版本的 Excel 人工 diff 要可靠得多。 写研究报告这件事,原来高度依赖分析师个人的综合能力。 系统里有九个职责清晰的分析模块,分别负责:财报变化对比、管理层表述分析、新闻事件分级处理、财务模型更新、估值计算、风险识别与组合暴露告警、空头论点梳理(主动寻找反驳自己的证据)、一页决策卡合成、以及引用来源的合规检查。每个模块的输出都是结构化数据,没有来源的字段自动标记为”未经验证”,最终汇总成一份供人阅读的决策卡。 这条链路走完,卖方 equity research 里从读文件到出报告的主线,基本可以自动完成。 它替买方基金经理做了什么 买方关心的问题和卖方不同。卖方问的是”这票值不值得买”,买方问的是”买了之后整个组合发生了什么变化”,以及更难回答的那个问题:”我的决策过程是不是足够严谨、我有没有在重复同样的错误”。 大多数人的风险管理不超过”不把所有鸡蛋放在同一个篮子里”。这套系统里的组合分析层做的是机构级别的工作:风险预算分解,告诉你每个持仓对总组合风险的实际贡献是多少;因子暴露分析,告诉你你的组合在价值、成长、动量等维度上净暴露了多少;压力测试,模拟特定宏观情景下组合会损失多少;流动性约束分析,告诉你在极端情况下你能多快把持仓变现。 再平衡建议会自动生成:根据当前持仓偏离目标权重的程度、交易成本估算、以及流动性约束,给出具体的调仓方案。 以前这些分析要么要订阅昂贵的机构工具,要么要自己在 Python 里从头写。现在 notebook 里直接调用。 决策记录这件事,是整套系统里最难做、也最重要的部分。 买方机构普遍要求基金经理在交易前写 IC memo,记录投资逻辑、预期回报、可接受的下行风险、以及什么情况下应该止损出场。这件事道理大家都懂,但真正执行的时候有两个问题:一是懒得写,二是写了之后还能改。 如果事前笔记可以在事后修改,那复盘就没有意义——你永远无法知道当时到底是怎么想的,因为记录已经被美化过了。人类在亏损之后会不自觉地重构记忆,把自己描述成”早就知道有风险只是没有及时止损”,而不是”当时完全没有考虑到这个风险”。这两种说法得出的教训截然不同,而只有第二种是真实的。 所以这套系统在数据库层面做了一个强制约束:决策记录表只允许新增,不允许修改或删除。这不是靠应用层的逻辑来保证的,而是直接写在数据库触发器里——任何 UPDATE 或 DELETE 操作会直接报错。想补充说明,走单独的追加表,原始记录永远不动。 事前笔记的字段包括:为什么是现在(而不是三个月前)、核心逻辑是什么、预期回报是多少、可以接受的最大下行是多少、什么情况下应该离场、什么新信息会让你改变想法、主观信心打分、以及当下的情绪状态。 最后一个字段看起来多余,但在回溯的时候会发现它非常有价值——很多错误决策的背景都是情绪不稳定。 人工确认之后,决策记录落库。此后还有复盘环节:30天后、90天后,系统会提示你回来写复盘,记录教训、标注犯了哪种类型的错误、判断当初的逻辑是否得到了验证。 这三张表用外键串起来,构成一条完整的决策事件链:事前笔记 → 人工决策 → 交易记录 → 事后复盘。每一个环节都有时间戳、都不可篡改。 做投资的人都说要”向市场学习”,但很少有人真正建立了一套方法论来实现这件事。每次复盘的教训散落在各处,时间长了就忘了;即使记得,在下次面对类似情形时也未必能想起来。 这套系统的第四层做的事情是:把所有复盘里的教训汇总成一个规则库,在你下次做类似决策时自动触发提醒。具体来说,如果你在复盘中标注过”提前止损”这个错误类型,那下次你在相似情境下写事前笔记时,系统会在你进入决策流程之前提醒你:你在上一个类似的情况下犯过提前止损的错误。 系统还会对你的历史所有决策按错误类型做聚类分析,让你看到自己最频繁犯哪几种错。这种自我认知不是靠感觉积累的,而是数据说话。 为什么要做成一个系统而不是一堆工具 市面上不缺投研工具。财务数据有终端,因子分析有量化平台,笔记有 Notion,代码有 Jupyter。但这些工具之间是断开的,每次工作都要在不同界面之间来回切换,数据要手动搬运,逻辑链条没有人帮你记住。 更重要的是,这些工具里没有一个强制你在买入之前写下清晰的逻辑,也没有一个能在三个月后把你的预测和现实对比给你看。 One 解决的不是信息缺乏的问题,而是纪律缺失的问题。信息在互联网时代从来不是稀缺资源,稀缺的是系统性地执行投研流程的能力,以及对自己决策过程诚实的意愿。 这套系统的核心假设只有一个:投研日常里大部分工作是可以工业化、流程化的。剩下那几个关键节点——为什么是现在、止损条件是什么、仓位应该多大——必须人类亲自做。 最后 做完这套系统,我不认为 AI 能替代投资判断。判断依赖的是对行业的深度理解、对管理层的长期观察、以及在不确定中做出承诺的勇气——这些都不是程序能给的。 但我越来越相信,没有工业化流程支撑的判断,会被繁琐的事务性工作大量稀释。分析师花三小时读 10-K 填数字,这三小时本可以用来想清楚一个真正重要的问题。 把可以工业化的部分交出去。把剩下的时间用在真正需要你的地方。
上一篇AI火爆实战!我用AI做了一部10集都市漫剧:500元成本+3天时间,全流程公开
 夜雨聆风
夜雨聆风