 夜雨聆风
夜雨聆风





教会 AI 说“不确定”,可能比让它更聪明还难
MIT CSAIL 最近一篇即将登上 ICLR 2026 的论文,用一个你小学数学就能听懂的训练目标,把大语言模型的过度自信砍掉了高达九成。
论文的发现有两层:第一,现在所有的推理模型,从 DeepSeek-R1 到 o1 系到 Qwen 的推理版本,使用的标准 RL 训练方法不是”对 calibration 帮不上忙”,而是在主动把 calibration 搞坏。训练越久,模型越聪明,越自信,越危险。第二,只要在原来的奖励函数上加一项中学生都看得懂的公式,模型就能同时学会答题和承认不会。
听起来像是一个技术补丁。但把这件事放回过去三年的大模型叙事里,它戳破的是一个更大的假设,即我们一直以为”让 AI 说我不知道”是一个 prompt 工程问题,是一个产品设计问题,最多是一个 RLHF 数据标注问题。而 MIT 这篇论文说:不,它是一个训练目标设计问题。从一开始就没人教过模型这件事。
一个被训练到”永远自信”的学生
想象一个被训练成”只关心答题对错”的学生。考卷发下来,答对得 1 分,答错 0 分,整整刷了十年题,这个学生最终会学成什么样?

MIT 那篇论文的第一作者之一 Mehul Damani 在 MIT News 里的原话很直白:“标准训练方法简单又有效,但它不给模型任何说出不确定的动力。所以模型自然而然就学会了:不会的时候,就猜。”
这就是现在所有推理模型的处境。从 OpenAI 的 o1、DeepSeek 的 R1,到各种 Qwen、Llama 推理微调版本,背后用的训练范式叫 RLVR(Reinforcement Learning with Verifiable Rewards),给模型一道数学题或者代码题,能自动判分,答对给 1 分,答错 0 分,反复试几万次。
这个范式确实把模型的推理能力推到了一个新高度。但这篇论文的另一位共同一作 Isha Puri 说了一句更刺骨的话:“最令人震惊的是,普通 RL 训练不是对 calibration 没帮助,它在主动把 calibration 搞坏。模型变得更强的同时,也变得更过度自信。”
翻译一下:刷题越多,这个学生不只是做题变准了,ta 对自己每个答案的自信心也一并暴涨,哪怕是 ta 蒙的那部分。这是一个双向增长,而且没人拦。
什么是 calibration?用天气预报就能讲清楚
Calibration 这个词在机器学习里听着拗口,但它的核心用天气预报就能讲清楚。
一个好的预报员说”明天 70% 概率下雨”。你统计 ta 所有说”70%”的那些天,真的下雨的比例应该接近 70%。ta 说”90%”的那些天,下雨比例接近 90%。ta 不仅要猜得准,还要知道自己有多准。
一个坏的预报员则相反:ta 对每天的天气都说”90% 下雨”,结果实际下雨率只有 60%。ta 的预测总体胜率可能还行,但 ta 的置信度和真实准确率脱钩了。
把预报员换成 LLM,这就是当下所有推理模型的状态。它对每个问题都以极高置信度给答案,但其中一部分它其实在猜。用户看不到这个”在猜”的信号,模型的语气、措辞、甚至 chain-of-thought 看起来都同样确定。
学术界衡量这个差距的指标叫 ECE(Expected Calibration Error,期望校准误差):把所有预测按置信度分桶,计算每桶内”模型声称的置信度”和”实际正确率”的差距加权平均。一个完美校准的模型 ECE 接近 0。而 MIT News 原文的一句话把这件事的赌注说得很清楚:
一个说”我有 95% 把握”但实际只对一半的模型,比一个直接答错的模型更危险,因为用户没有任何信号去寻求第二意见。
这是一个技术问题,但它真正的影响在治理层面。答错了你还能 debug、还能追责。但一个自信地答错的系统,让用户跳过了”让我再查一下”的那道防线。
RLCR:两行公式,把过度自信砍掉九成
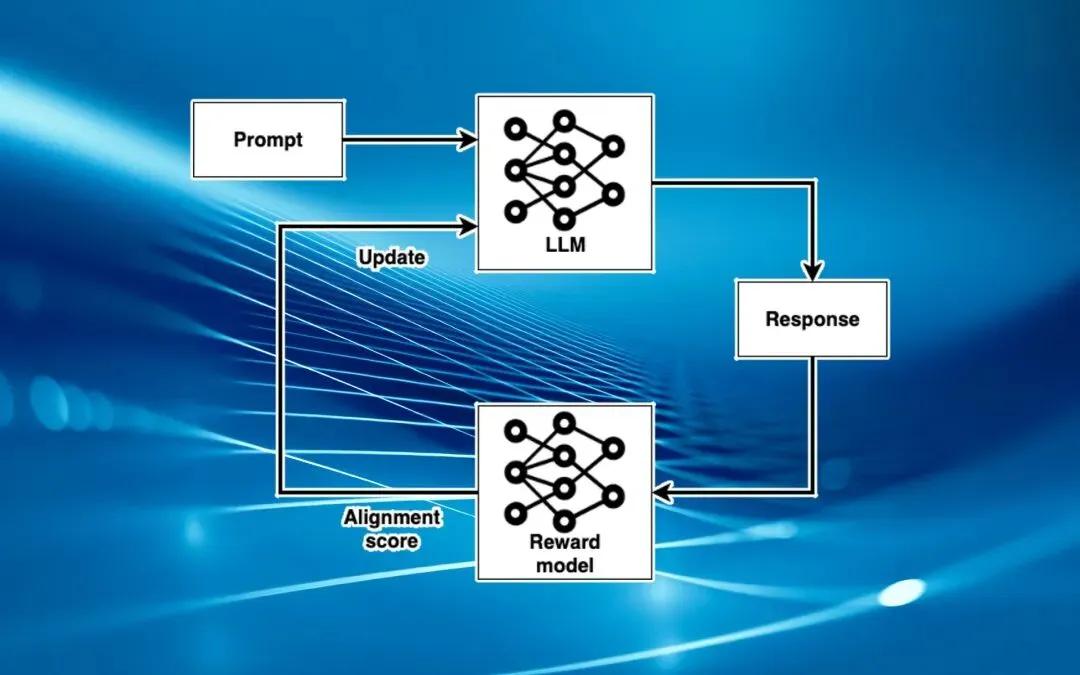
MIT 这篇论文的解法 RLCR(Reinforcement Learning with Calibration Rewards)本质是一次极简的 reward 重新设计。
原来的训练信号:答对得 1 分,答错 0 分。
RLCR 加了一项:让模型在答题时同时输出一个 0 到 1 之间的置信度 q,然后在原奖励上叠加一个 Brier Score。

翻译成人话:
- 答对了且置信度高:损失小,保住大部分奖励
- 答对了但置信度低:被扣分,因为你明明对了却没底气
- 答错了且置信度低:几乎不罚,因为你诚实承认了不会
- 答错了且置信度还很高:重罚,因为你在误导用户
这个公式的精妙之处在于它是数学上的一个”严格合适评分规则”(strictly proper scoring rule)。可以证明,当且仅当模型输出的 q 等于它答对的真实概率时,期望得分最大。模型没法通过撒谎拿高分。
训练框架用的是 DeepSeek R1 同款的 GRPO(做了点简化),基础模型是 Qwen2.5-7B,在 HotPotQA(多跳问答)和 MATH(数学推理)上训练。模型输出结构长这样:先给 think 段推理,再给 answer 段答案,然后是对不确定性的 analysis 段,最后是 confidence 段的一个数字。
结果 MIT 原话是”校准误差降低最高达 90%”,精度不降反升。更关键的是:在 6 个从来没训练过的测试集上,RLCR 依然一致改善。也就是说,模型学会的不是”在 HotPotQA 上什么时候蒙对”,而是“如何思考自己的不确定性”这件事本身,一种可迁移的元能力。
为什么以前的那些办法都不行
过去三年里,业界对付”AI 太自信”这件事,其实已经掏过三种办法,每种都有各自的坑。
第一种,Prompt 工程。在 system prompt 里写上”如果你不确定,请说不知道”。听起来简单,但这个指令没有训练信号支撑。模型今天可能听话,换个话题就忘了。更致命的是,它根本不量化,”我有点不确定”和”我八成错了”之间差着一整片医疗误诊的距离。
第二种,RLHF。OpenAI 和 Anthropic 花了大钱训练的 reward model,原本就该解决这类对齐问题。但 Anthropic 自己 2023 年发过一篇论文承认:RLHF 的结果是训出了谄媚(sycophancy)。原话是:”人类和偏好模型一定程度上都偏好写得漂亮的谄媚回答,哪怕它不对。”翻译:用户喜欢听自信的话,所以模型学会了说自信的话,哪怕这话是错的。RLHF 把”让用户满意”和”说真话”当成了同一件事,它们不是。
第三种,事后置信度分类器(post-hoc calibration)。训练完主模型,再单独训一个小分类器去估计主模型的置信度。这是自动驾驶领域玩了很多年的老路子。但 MIT 的实验显示,这种办法在跨域场景下表现很差,分类器看不到模型内部的 reasoning,它只能看最终输出猜一猜,泛化能力拉垮。
这三条路有个共同问题:都是在训练之后做补救。RLCR 的不同在于,它把 calibration 当成一个和正确性同等重要的训练目标,放进了 RL 的原生奖励信号里。不是事后拧螺丝,是从地基开始就铺钢筋。
律师事务所们一遍遍在 buy 这个教训
就在 MIT 发表这篇论文的同一周,纽约联邦法院上演了一个完美的反面教材。
4 月 22 日,华尔街顶级律所 Sullivan & Cromwell 不得不给联邦法官 Martin Glenn 写致歉信,它在 4 月 9 日提交的一份涉及 Prince Group / 陈志案的破产重组文件里,出现了 AI 生成的错误引用:法条引错了,案件摘要编造了,判例结论写歪了。更尴尬的是,这些错误是对家律所 Boies Schiller Flexner 发现并当庭指出来的。
S&C 的解释大致是:我们有 AI 使用规范,但这次”规范没有被遵守”。对熟悉法律行业的人来说,这句话翻译过来就是”有人没去核对”。
这不是新鲜事。2023 年纽约律师 Steven Schwartz 用 ChatGPT 写辩护状、结果引用了六个完全不存在的判例,被法院罚了 5000 美元并公开训诫。三年过去,华尔街顶流律所在同一个坑里又摔了一次。
真正的问题不是”AI 会编”,真正的问题是”AI 编的时候和它没编的时候语气完全一样”。
这就是 calibration 缺失的代价。Schwartz 看 ChatGPT 吐出的判例,Sullivan & Cromwell 的初级律师看模型给的法条,他们面对的都是一段语气笃定、格式规范、引用完整的文字。没有任何信号告诉他们”这一部分我是凭训练数据的碎片重建的,你最好去 Westlaw 核对一下”。
如果把 RLCR 训出来的模型换到这些场景里,它至少会在律师看到答案时附一句 confidence: 0.23。那个数字本身不能保证对错,但它能让一个即将交卷的律师停下来多查一次。
这是一件看似微小但结构上非常重要的改变,把”要不要再查一次”的决策权,从模型悄悄传回给了用户。
从自动驾驶学来的一课,迟到了五年
Calibration 对 LLM 是新概念,但在另一个 AI 领域已经成熟了至少五年:自动驾驶。
感知模型要识别前方的物体是不是行人。早期的系统是二元输出:是/不是。后来所有主流路线,从 Waymo 到特斯拉到 Mobileye,都把感知输出升级成了带不确定性的概率:epistemic uncertainty(模型对这种情况见过太少)和 aleatoric uncertainty(传感器噪声导致的本质不可知)。规划模块拿到的不再是”前方有行人”,而是”前方 82% 概率有行人,如果是行人位置的误差是 ±0.5 米”。决策会因此改变。
语言模型这条路迟迟走不通,一个原因是业界长期以”答对率”作为唯一比较维度。打榜表上只看 MMLU、GSM8K、HumanEval,没人看 ECE。另一个原因是,语言生成的不确定性比图像识别更难量化,图像里”是不是行人”是个明确的 binary,一段话的”正确性”却往往是连续的。
MIT 这篇论文本质上是把自动驾驶领域的那种严谨性搬回了语言模型训练。它的贡献不是发明一个新概念,Brier Score 是 1950 年就有的气象学工具,而是第一次把 proper scoring rule 和 RL 的 reward signal 无缝拼在一起,让模型在推理过程中学会像气象学家一样思考。
反过来想,这也解释了为什么这件事在这个时间点才能做:RLVR 作为训练范式本身也就两年历史,在此之前我们没有”推理模型”这种产品形态,calibration 谈不上从训练阶段介入。现在 DeepSeek R1、o1、Qwen 推理版本已经把 RL 变成主流,RLCR 正好卡在这一代范式的升级节点上。
真正有意思的问题:大厂会抄吗?
RLCR 的代码实现简单到让人怀疑,本质就是在现成的 GRPO 训练 pipeline 里改一行 reward 函数。这种”极简但根本”的工作有一个特征:要么大家都抄,要么集体装作没看见。
主动抄的可能性是存在的。DeepSeek 下一个版本如果想继续在推理 benchmark 上领跑,又想堵住”幻觉太自信”的批评,把 RLCR 塞进训练流程几乎是零成本。Qwen 团队一向技术嗅觉灵敏,阿里最近在推理模型上的动作很密,加这一项只会加分。Meta 的 Llama 推理版本、甚至 Anthropic 和 OpenAI 自己,理论上没人有理由不抄。
但也有一个反向力量不可忽视:校准过的模型在 demo 里不好看。
做过大模型产品的人都懂,一个自信地给答案的模型和一个”我觉得这件事我不太确定”的模型,在 A/B 测试里几乎一定是前者的用户满意度更高。用户不喜欢听到”不确定”。Demo 展示、Twitter 截图、VC 评估,所有这些环节都奖励过度自信。
这才是这项研究最深的 bug 不在技术层面,而在商业层面。训练阶段把 calibration 做好了,产品阶段可能反而被”优化”回去,用 RLHF 再拧一遍,让模型把”不确定”说得更委婉、更少,直到表面上看起来又是那个熟悉的、笃定的聊天助手。
这件事可能不会以”大厂抄”的形式落地,而是以”监管强推”的形式落地。FDA 对 AI 医疗器械已经明确要求不确定性量化,金融监管机构也在向这个方向靠拢。当 calibration 从”锦上添花”变成”合规门槛”,RLCR 这种从训练目标上解决问题的方法才会有真正的商业推力。
一句金句,值得截图
这篇论文真正的价值其实不在 90% 这个数字,而在它把一件我们一直放错位置的事情放回到了对的位置。
让 AI 说”我不知道”这件事,不是 prompt 工程师的工作,不是产品经理的工作,不是对齐研究员的工作,它是训练目标设计者的工作。它必须从最底层的 reward 信号里刻进去,否则后面所有补丁都只是表演。
三年前我们说 LLM 的最大问题是幻觉。两年前我们说是事实性。一年前我们说是安全对齐。今年,MIT 这篇论文给出了一个可能更精确的诊断:过去所有问题,本质上都是 calibration 问题的不同投影。一个知道自己什么时候不知道的模型,它天然就更少幻觉、更少编造事实、更少被 jailbreak。
所以如果要从这篇论文里掏出一句可以截图转发的话:
对 AI 来说,学会说”我不确定”比学会答对更难,因为训练流程从来就没教过它这件事。
这不是一个技术八卦,而是过去三年整个 AI 研究对”信任”这个概念的默认假设被轻巧地掀翻了。信任不是用户侧的感知问题,也不是模型大小的堆叠问题,它从 reward 函数的第二项里就开始决定了。
参考资料
[1] MIT News – Teaching AI models to say “I’m not sure”( 2026-04-22)
https://news.mit.edu/2026/teaching-ai-models-to-say-im-not-sure-0422
[2] arXiv – Beyond Binary Rewards: Training LMs to Reason About Their Uncertainty
https://arxiv.org/abs/2507.16806
[3] The Guardian – AI hallucinations found in high-profile Wall Street law firm filing( 2026-04-22)
https://www.theguardian.com/technology/2026/apr/22/ai-hallucinations-found-in-high-profile-wall-street-law-firm-filing
[4] Anthropic Research – Towards Understanding Sycophancy in Language Models
https://www.anthropic.com/research/towards-understanding-sycophancy-in-language-models
[5] arXiv – TruthfulQA: Measuring How Models Mimic Human Falsehoods( Lin et al., 2022)
https://arxiv.org/abs/2109.07958
[6] bdtechtalks – How RLCR teaches LLMs to know what they don’t know
https://bdtechtalks.com/2025/07/28/llm-rlcr/