夜雨聆风
夜雨聆风





AI 记忆上下文机制深度分析
一、上下文窗口的本质
1.1 什么是上下文窗口
上下文窗口(Context Window)是 LLM 在单次推理中能够处理的最大 token 数量,由模型架构中的注意力机制决定。它包含:
- 系统提示词(System Prompt):角色定义、行为约束、工具描述等
- 对话历史(Conversation History):用户与 AI 的多轮交互记录
- 工具调用结果(Tool Results):外部工具返回的数据
- 检索增强内容(RAG Content):从知识库检索的相关片段
- 当前用户输入(User Input):本次用户的查询

1.2 主流模型的上下文容量
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
关键认知:上下文窗口是硬性上限,超出则触发截断或报错。 重要区分:名义上下文 ≠ 有效上下文。模型声明支持 128K 不意味着 128K 范围内信息都能被准确利用,实际有效利用率通常仅为窗口的 50-70%(详见 3.2 Lost in the Middle)。
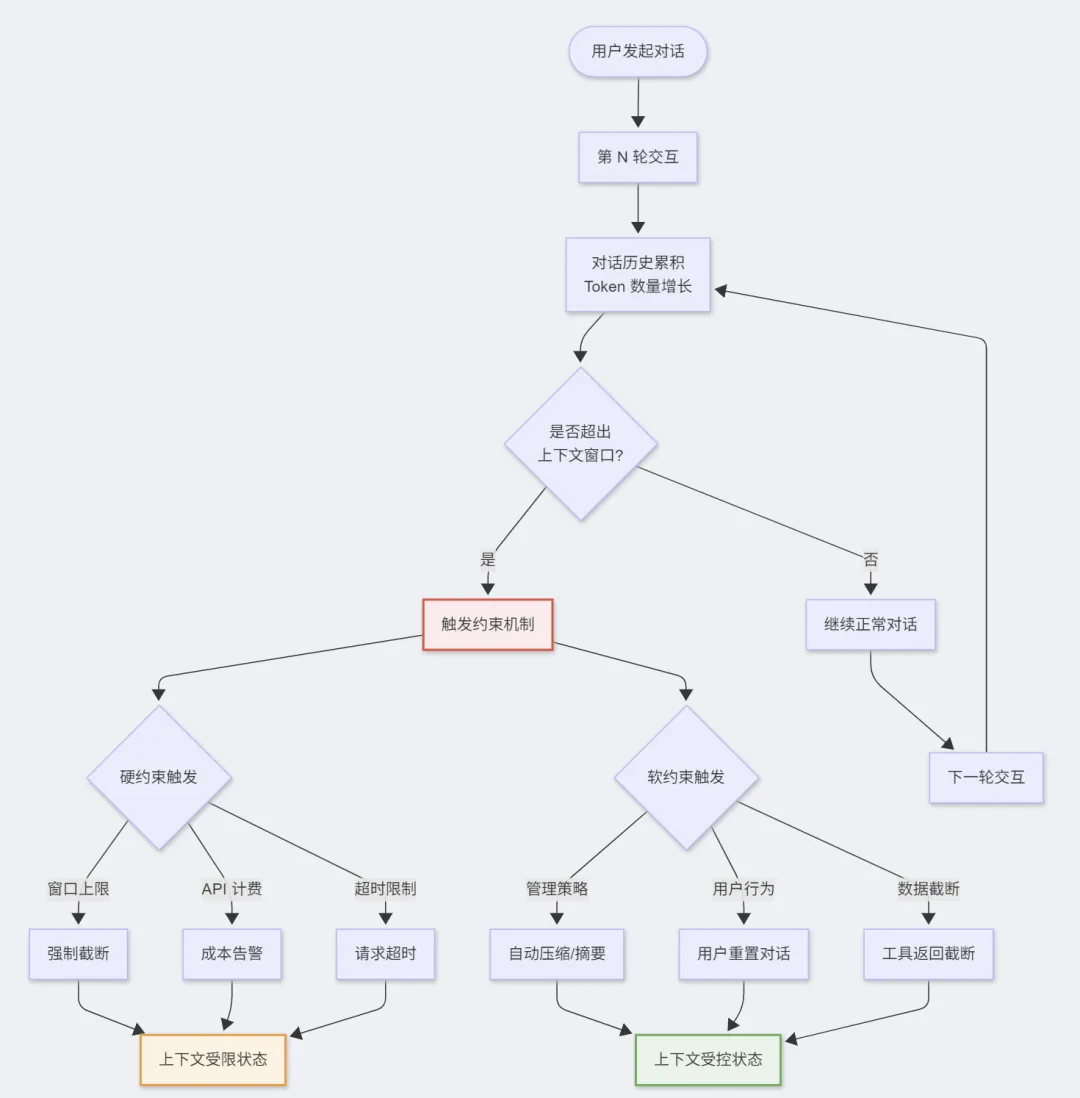
二、上下文是否会无限膨胀?
2.1 理论上:会持续增长
在没有干预机制的情况下,对话历史会随交互轮次单调递增:
Round 1: System(500) + User(100) + AI(200) = 800 tokensRound 2: System(500) + H1(300) + User(100) + AI(200) = 1,100 tokensRound 3: System(500) + H2(600) + User(100) + AI(200) = 1,400 tokens...Round N: System(500) + H(N-1)(...) + User + AI → ∞
膨胀速率取决于:
-
交互频率和轮次 -
单次回复的平均长度 -
工具调用返回的数据量 -
检索增强注入的内容量
2.2 实际上:受多种机制约束
上下文膨胀受到以下硬约束和软约束:
硬约束
- 模型上下文窗口上限:绝对天花板,无法超越
- API 计费限制:Token 越多,费用越高,经济性约束
- 请求超时限制:过长的输入导致推理超时
软约束
- 平台实现的上下文管理策略
(见第四节) - 用户侧的对话重置行为
- 工具返回数据的截断策略
2.3 膨胀的典型场景
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
📊 流程图:上下文膨胀与约束机制
三、上下文增长对执行效率的影响
3.1 推理延迟:二次方复杂度
标准Transformer的自注意力机制在预填充阶段(Prefill)的计算复杂度为 O(n²),其中 n 为序列长度(注:解码阶段因 KV Cache 只需计算新增 token 对历史的注意力,每步为 O(n)):
预填充注意力计算量 ∝ n² × d(d 为模型维度 d_model)当 n 从 4K → 128K 时:计算量增长 = (128/4)² = 1024 倍
实际影响(示意值,受模型和硬件影响):
- 4K tokens:推理延迟 ~1-2秒
- 32K tokens:推理延迟 ~5-10秒
- 128K tokens:推理延迟 ~20-60秒
- 1M tokens:推理延迟可达分钟级
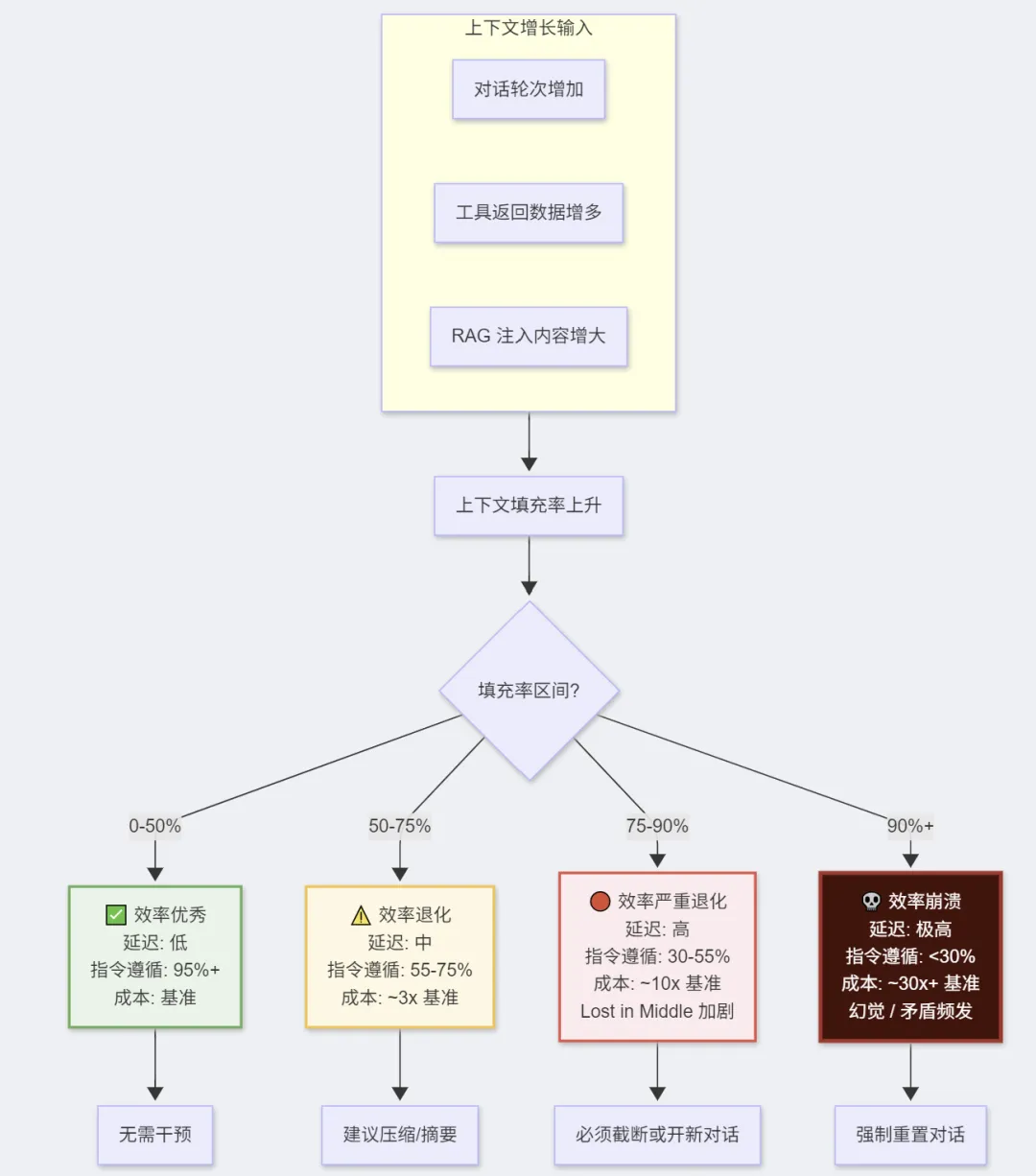
3.2 注意力稀释(Lost in the Middle)
研究表明,LLM 存在 “中间信息丢失” 现象:
信息召回率分布:位置: [开始] ████████████████░░░░░░████████████████ [结尾]权重: 高 低 高↑ 开头信息 ↑ 中间信息被稀释 ↑ 结尾信息保留良好 容易被忽略 保留良好
影响:
-
早期对话中的重要指令可能被后续内容”淹没” -
中间轮次的关键决策可能被遗忘 -
工具返回的大量数据可能相互干扰
3.3 指令遵循能力下降
随着上下文增长,模型对系统提示词的遵循能力衰减:
上下文填充率 vs 指令遵循度(示意):0-25% ████████████████████ 95-100% 指令遵循优秀25-50% ████████████████░░░░ 75-90% 偶有偏差50-75% ████████████░░░░░░░░ 55-75% 明显退化75-100%████████░░░░░░░░░░░░ 30-55% 严重退化
3.4 事实一致性降低
在上下文中,模型更容易产生:
- 自相矛盾:前后回答不一致
- 幻觉增强:编造上下文中不存在的信息
- 重复生成:循环输出相似内容
3.5 成本超线性增长
费用 = Input Tokens × 单价 + Output Tokens × 单价典型定价(GPT-4 Turbo 级别):- Input: $10 / 1M tokens- Output: $30 / 1M tokens每轮对话的输入 token 增长:第1轮输入: 1K → 第2轮输入: 2K → 第3轮输入: 3K ... → 第N轮输入: ~N×平均轮长度· 单轮输入量 ∝ N(线性增长)· N轮总输入量 = 1K + 2K + 3K + ... ≈ N×(N+1)/2 × 平均轮长度 → O(N²)一个 50 轮对话的估算:- 第50轮输入: ~80K input tokens → $0.8/轮(对比新对话 $0.01/轮,差距 80 倍)- 50轮总输入: ~1,275K tokens → 累计 $12.75
📊 流程图:效率衰减全景流程
四、上下文处理机制
4.1 截断策略(Truncation)
最基础也最粗暴的策略:
原始历史: [Sys] [M1][M2][M3][M4][M5][M6][M7][M8][M9][M10]系统提示 ↑ 超出窗口 ↑截断后: [Sys] [M6][M7][M8][M9][M10]保留系统提示 保留最近的对话
变体:
- 滑动窗口:固定保留最近 N 轮
- 优先截断:按优先级保留(系统提示 > 当前对话 > 历史)
- 选择性截断:保留关键决策,丢弃冗余对话
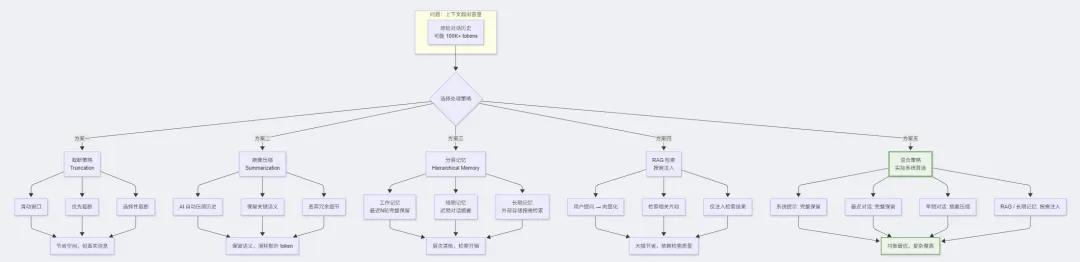
4.2 摘要压缩(Summarization)
用 AI 自身压缩历史:
原始历史(5000 tokens):User: 帮我写一个登录页面AI: 好的,这是登录页面代码...[长代码]User: 加上记住密码功能AI: 已添加...[修改代码]User: 修改颜色为蓝色AI: 已修改...压缩摘要(500 tokens):[对话摘要:用户要求创建登录页面,包含记住密码功能,主色调为蓝色。当前文件:login.vue,主要组件:LoginForm、RememberPassword。]当前对话:User: 再加一个注册入口
优点:大幅减少 token,保留语义 缺点:摘要过程本身消耗 token,可能丢失细节
4.3 分层记忆架构(Hierarchical Memory)

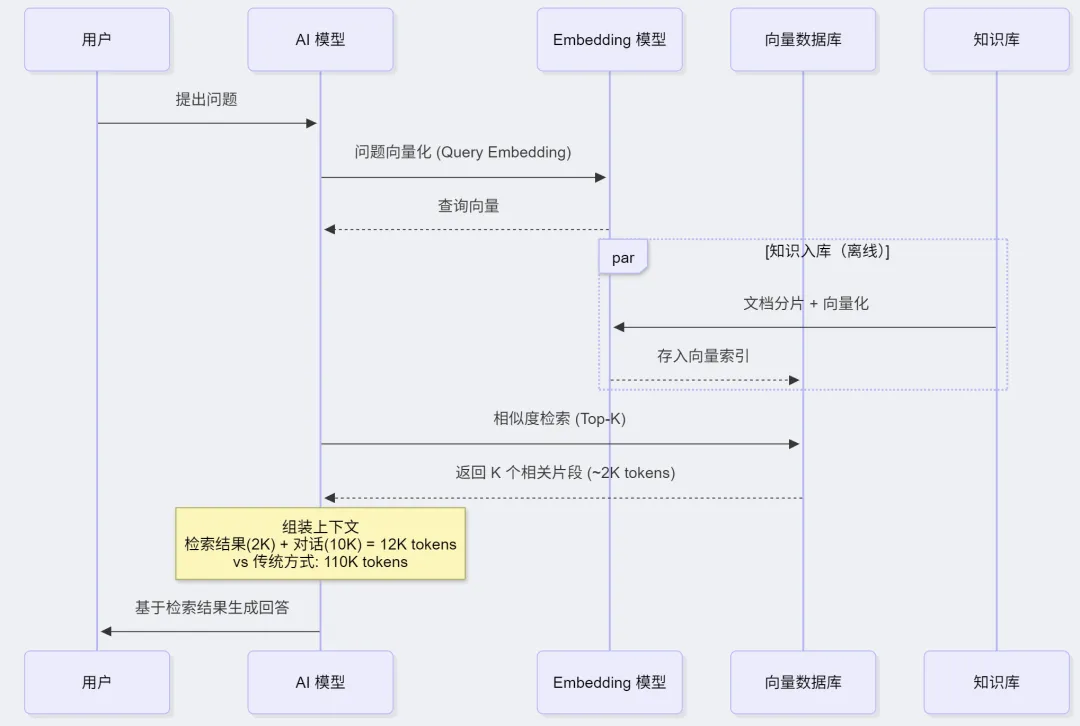
4.4 RAG 增强检索(Retrieval-Augmented Generation)
不在上下文中存储所有信息,而是按需检索:
传统方式:Context = 全部知识(100K tokens) + 对话(10K) = 110K tokensRAG 方式:1. 用户提问 → 向量化查询2. 检索最相关的 K 个片段(~2K tokens)3. Context = 检索结果(2K) + 对话(10K) = 12K tokens节省:~90% 的上下文空间
📊 流程图:RAG 检索增强流程
4.5 混合策略(实际系统常用)
现代 AI 助手通常组合多种策略:
上下文组成(优先级从高到低):1. 系统提示词 → 始终完整保留2. 当前用户输入 → 始终完整保留3. 工具定义 → 始终完整保留4. 最近 3-5 轮对话 → 完整保留(工作记忆)5. 更早对话的摘要 → 压缩保留(短期记忆)6. RAG 检索结果 → 按需注入7. 长期记忆检索 → 按需注入总目标:控制在上下文窗口的 60-70% 以内
📊 流程图:上下文处理机制总览
Lexical error on line 4. Unrecognized text....{上下文预算<br/>目标: 60-70%} BUDGET --> AL-----------------------^
五、CodeBuddy 的上下文管理实践
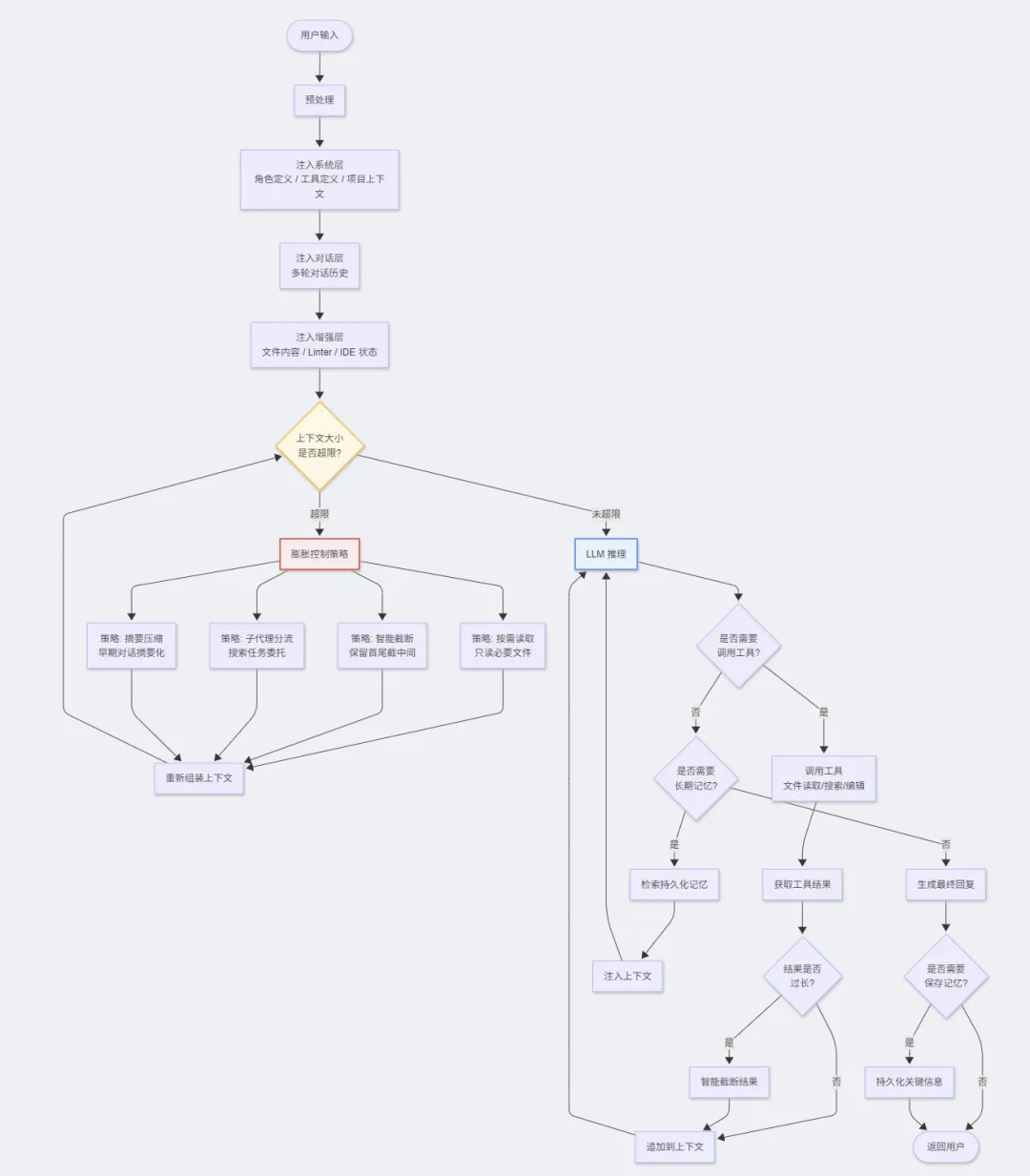
5.1 上下文注入机制
每次对话中,系统自动注入:┌─ 系统层 ─────────────────────────────┐│ 角色定义 + 行为约束 + 输出格式要求 ││ 工具定义(所有可用工具的 schema) ││ 集成状态(已连接的服务信息) ││ 项目上下文(文件结构、打开的文件) ││ 用户偏好(语言、OS、Shell 类型) │├─ 对话层 ─────────────────────────────┤│ 多轮对话历史(含工具调用和返回) │├─ 增强层 ─────────────────────────────┤│ 搜索/读取的文件内容 ││ 代码诊断信息(linter 错误) ││ IDE 状态(光标位置、选中内容) │└───────────────────────────────────────┘
5.2 上下文膨胀控制
策略1: 按需读取- 不预加载整个项目,只在需要时读取特定文件- 优先使用搜索而非全文读取策略2: 智能截断- 工具返回结果超长时自动截断- 保留文件首尾,中间用 "... existing code ..." 替代策略3: 子代理分流- 复杂搜索任务委托给子代理- 子代理只返回结论,不返回中间过程- 主上下文不被搜索过程污染策略4: 对话轮次限制- 超过一定轮次后提示用户开启新对话- 或自动压缩早期对话为摘要策略5: Todo 列表替代对话记忆- 用结构化的 Todo 列表替代线性对话历史- 状态信息存储在 Todo 中而非反复提及
5.3 长期记忆机制
记忆存储(Memory System):┌─────────────┐ ┌─────────────┐│ 当前上下文 │ │ 持久化记忆 ││ (临时) │ ←─→ │ (跨会话) ││ 对话历史 │ │ 用户偏好 ││ 工具结果 │ │ 项目知识 │└─────────────┘ │ 决策记录 │└─────────────┘↑按需检索注入上下文
📊 流程图:单次对话请求的完整处理流程
六、前沿优化方向
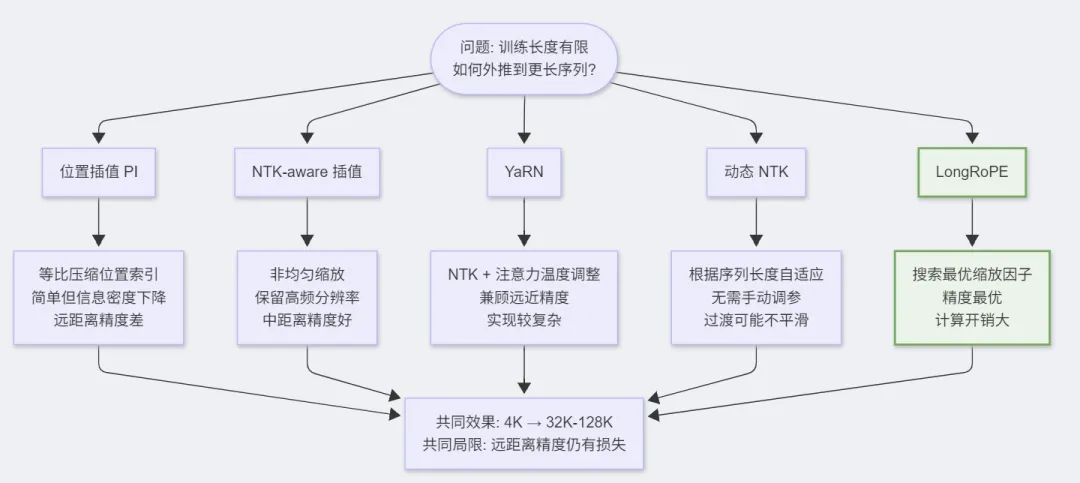
6.1 稀疏注意力(Sparse Attention)
核心问题:模型训练时只见过有限长度,如何外推到更长序列?主流方案:┌─ 位置插值 (PI) ─────────┐ 等比压缩位置索引,信息密度下降┌─ NTK-aware 插值 ─────┐ 非均匀缩放,保留高频分辨率┌─ YaRN ────┐ 结合 NTK + 注意力温度调整┌─ 动态 NTK ────┐ 根据序列长度自适应缩放┌─ LongRoPE ────┐ 搜索最优缩放因子效果:可将 4K 训练长度外推至 32K-128K,但远距离精度仍有损失
6.3 KV Cache 优化
Needle In A Haystack(大海捞针):- 在长文本中随机位置插入关键信息- 测试模型能否准确召回- 结果:多数模型在中间位置表现显著下降LongBench:- 多任务长上下文评测- 涵盖摘要、QA、代码完成等InfiniteBench:- 测试 100K+ token 场景- 包含检索、计数、代码调试等
6.4 长上下文评估基准
Needle In A Haystack(大海捞针):- 在长文本中随机位置插入关键信息- 测试模型能否准确召回- 结果:多数模型在中间位置表现显著下降LongBench:- 多任务长上下文评测- 涵盖摘要、QA、代码完成等InfiniteBench:- 测试 100K+ token 场景- 包含检索、计数、代码调试等
6.5 上下文缓存(Prompt Caching)
无缓存:每次请求都重新处理全部上下文有缓存:┌─ 缓存层 ─────────────┐│ System Prompt (命中) │ ← 不重复计算│ 工具定义 (命中) │ ← 不重复计算│ 历史对话 (部分命中) │ ← 增量计算│ 新增内容 (未命中) │ ← 需要计算└───────────────────────┘效果:减少 50-90% 的输入 token 计费(因提供商而异:OpenAI 缓存命中 50% 折扣,Anthropic 约 90% 折扣但写入时额外收费),处理时间同步大幅缩短
Lexical error on line 29. Unrecognized text....[组合最终结果<br/>节省 50-90% 处理时间] DELTA -------------------------^
Parse error on line 9:...A --> A1[稀疏注意力<br/>O(n²) → O(n√n)] A-----------------------^Expecting 'SQE', 'DOUBLECIRCLEEND', 'PE', '-)', 'STADIUMEND', 'SUBROUTINEEND', 'PIPE', 'CYLINDEREND', 'DIAMOND_STOP', 'TAGEND', 'TRAPEND', 'INVTRAPEND', 'UNICODE_TEXT', 'TEXT', 'TAGSTART', got 'PS'
七、核心结论
7.1 上下文膨胀是必然趋势,但可控
|
|
|
|---|---|
|
|
|
|
|
是
|
|
|
有
|
|
|
|
7.2 效率衰减的非线性特征
上下文利用效率 = f(填充率, 信息密度, 位置分布)关键发现:1. 0-50% 填充率:效率下降平缓(~5%)2. 50-75% 填充率:效率下降加速(~15%)3. 75-90% 填充率:效率急剧下降(~30%)4. 90%+ 填充率:效率断崖式下跌(~50%+)→ 最优策略:将上下文控制在窗口的 60-70%
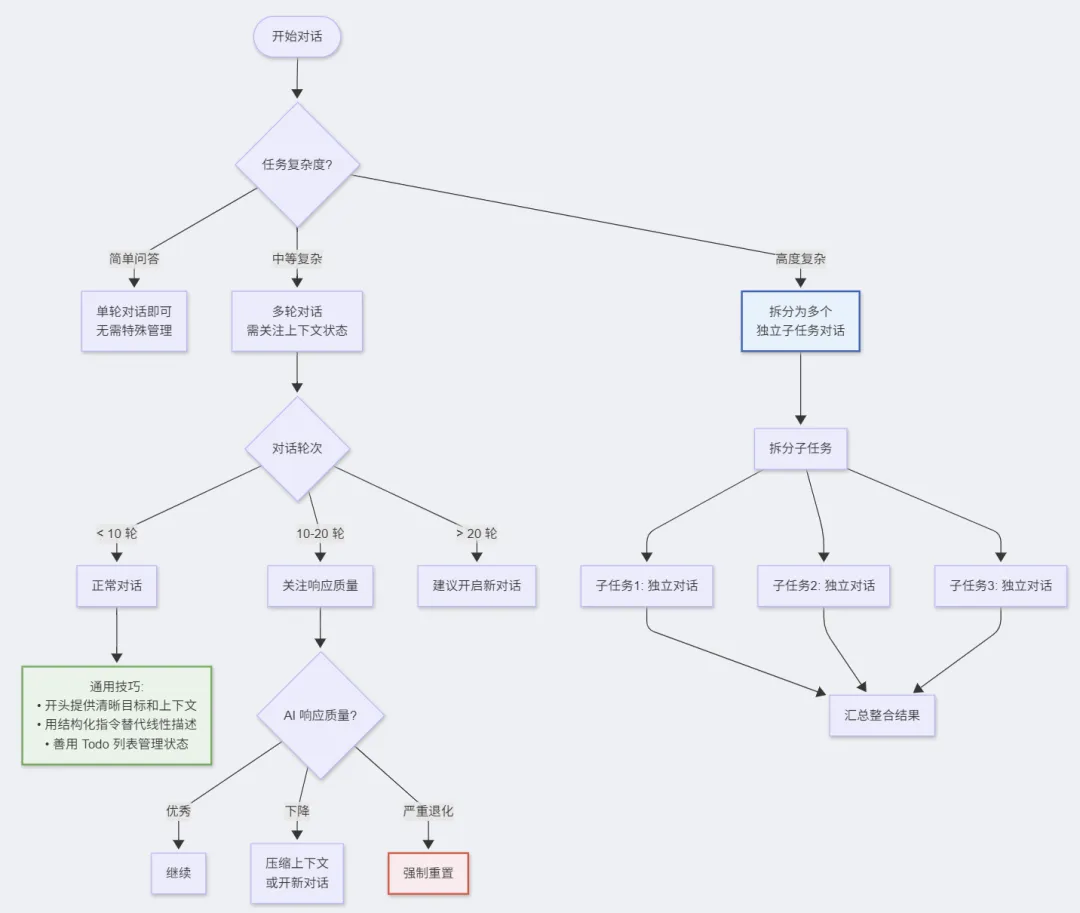
7.3 最佳实践建议
对于 AI 系统设计者:
-
实现分层记忆架构(工作/短期/长期) -
采用”按需注入”而非”全部加载” -
在对话轮次和上下文利用率之间建立反馈回路 -
利用子代理分流计算密集型任务 -
实现智能的上下文压缩和摘要机制
对于 AI 使用者:
-
复杂任务拆分为多个独立对话 -
定期开启新对话,避免上下文污染 -
在对话开头提供清晰的上下文和目标 -
善用结构化指令(Todo、大纲)而非线性描述 -
关注 AI 的响应质量,及时重置退化的对话
📊 流程图:用户最佳实践决策树