 夜雨聆风
夜雨聆风





模拟版图AI,开始抢工程师的饭碗了
在芯片设计的世界里,数字电路早已高度自动化——综合、布局布线、时序收敛,工程师按下按钮,工具吐出GDSII。但模拟版图设计,至今仍是一门需要“金手指”的手艺。器件匹配、寄生效应、阱邻近效应、电流密度均匀性……每一个细节都需要工程师用经验和直觉去雕琢。一块好的模拟版图,被称作“芯片上的艺术”。
正因为如此,当AI大举入侵各行各业时,模拟版图设计始终是一块难啃的骨头。不是算法不够聪明,而是“老师”太少——高质量、有标注的模拟版图数据极度稀缺。更何况,模拟版图任务种类繁杂:画接触孔、打通孔、填dummy、做阱、布金属线……每一项都像是独立的技艺,难以用一个模型通吃。
然而,一篇近期发表在TCAS-I上的论文,正在挑战这种“经验不可替代”的叙事。来自韩国浦项科技大学(POSTECH)的研究团队,首次提出了一个面向模拟版图设计自动化的UNet基础模型,及其配套的自监督学习方法。它不仅能在五项核心版图任务上达到96.6%的通过率,更令人不安的是——它生成的版图,经过后仿真验证,在模拟性能上居然与人类专家设计不相上下。
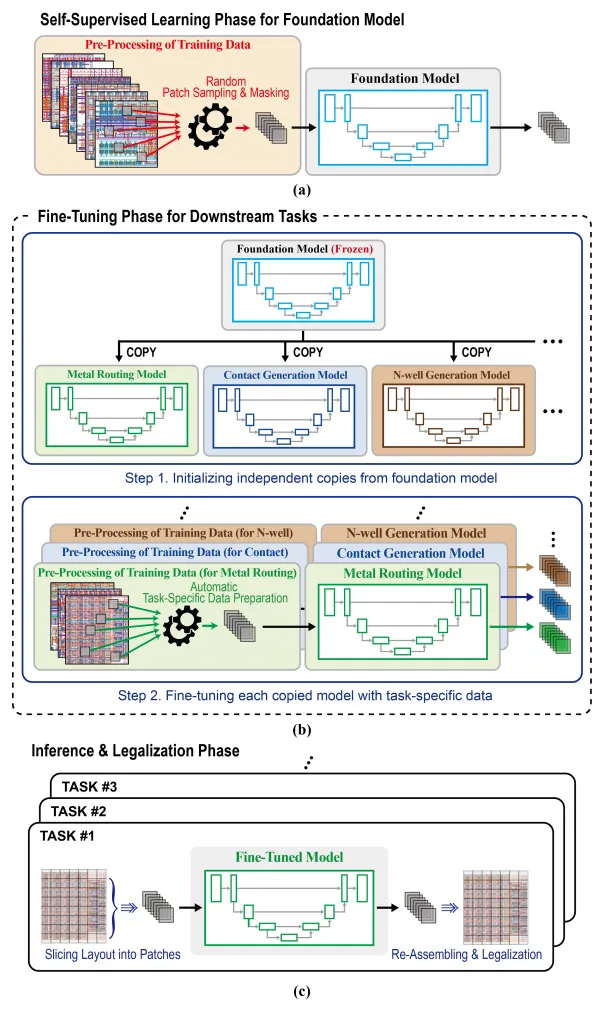
当AI开始学会“手感”,工程师的护城河,还在吗?
一个不需要老师的学习方法
故事的关键,在于他们解决了一个此前困扰整个领域的问题:没有标注数据,怎么训练模型?
传统的深度学习路线需要大量的“输入-输出”配对数据。比如,要训练一个生成接触孔的模型,你得有上千个“缺少接触孔的版图→完整版图”的样本对。在模拟版图领域,这样的数据几乎没有。人工标注不仅耗时,而且容易出错。
POSTECH团队想出了一个“取巧”的办法。他们的思路极其朴素:既然没有老师,那就让模型做“完形填空”。
具体来说,他们从仅有的6个经过硅验证的手工版图中,随机裁剪出大约15,000个固定大小的版图碎块。然后,对这些碎块进行“随机掩码”——随机性地抹掉某些图层上的图形元素。被抹掉一部分图形的碎块作为输入,被抹掉的那些图形元素作为输出目标。就这样,无需任何人工标注,他们自动生成了324,000个训练样本。
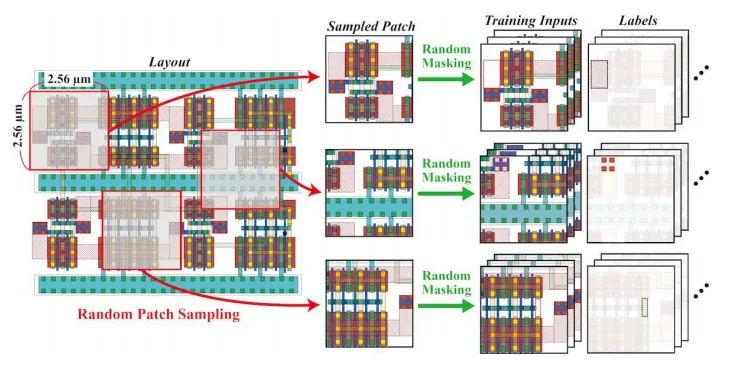
这就是所谓的自监督学习。模型在预训练阶段的任务只有一个:根据残缺的版图,猜出被挖掉的部分应该长什么样。正是在这种“修复残图”的过程中,模型隐式地学到了什么是“合理”的版图模式——金属走线不该无故断开,接触孔应该出现在金属与有源区的交叠处,N阱的边界应该包裹住所有PMOS器件……
这些知识不是靠规则灌输的,而是从为数不多但设计精良的人类作品中“悟”出来的。预训练完成后,这个基础模型就具备了模拟版图的“通识教育”背景。
一个模型,五项任务,一次微调
有了“通识”,接下来的事情就简单了。
对于任何具体的下游任务,只需要用少量任务特定的数据对基础模型进行微调,它就能迅速适应新任务。研究团队演示了五类核心版图生成任务:接触孔、通孔、dummy finger、N阱、金属走线。
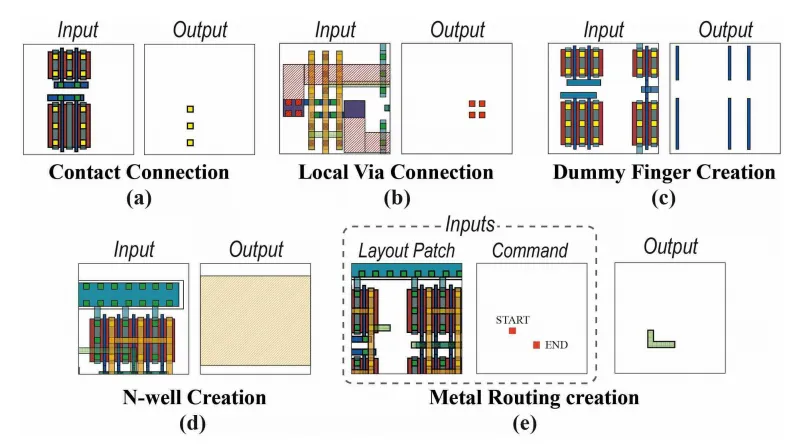
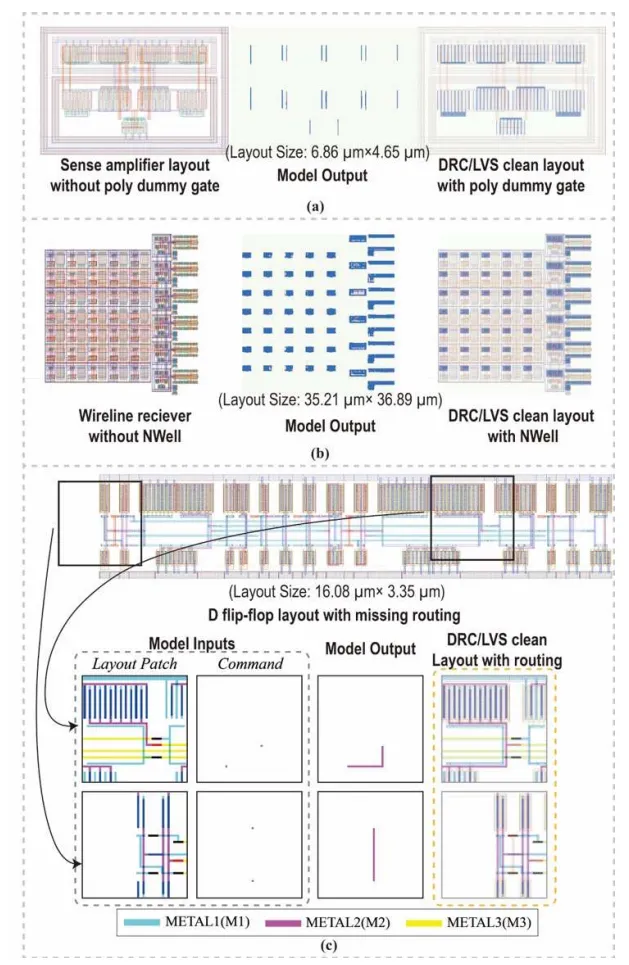
微调所需的数据量少得惊人。以接触孔生成为例,仅用50个样本进行微调,模型就在全部300个测试版图上达到了100%的DRC/LVS通过率——因为接触孔的生成模式相对简单,基础模型在预训练阶段已经掌握得足够好了。
更具说服力的是金属走线任务。这是五类任务中最复杂的一类:模型需要根据给定的起点和终点,在复杂的版图环境中找到合适的路径,还要避开障碍、满足设计规则。要达到0.95的Dice分数(衡量生成图形与真值重合度的指标),从头训练一个模型需要2,320个样本,而微调基础模型只需要290个——数据需求降至1/8。当训练数据进一步缩减到290个时,微调模型的验证损失比从头训练模型低90%,Dice分数高出40%。
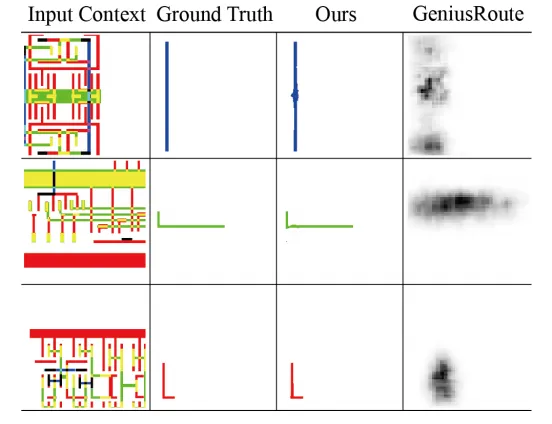
这意味着什么?意味着基础模型预训练阶段学到的“通识”,在数据稀缺时发挥了巨大作用。从头训练的模型在少量数据上容易严重过拟合,而基础模型已经有了对新任务的“先验知识”,它只需要在原有基础上做局部调整,而不是从零开始摸索所有规则。
跨任务的泛化能力同样令人惊叹。在全部5项任务、1,824个测试样本中,微调后的模型成功为96.6%的样本生成了DRC/LVS clean的版图。一个模型,通吃五类任务——这在模拟版图自动化领域是前所未有的。
它真的懂模拟电路吗?
然而,仅通过DRC和LVS验证,只能说明版图“没有明显错误”,不能说明它“性能优秀”。模拟电路对版图的敏感性远超数字电路。同样满足设计规则的版图,可能因为器件匹配不佳而失调电压飙升,也可能因为寄生效应过大而带宽骤降。
AI生成的版图,是“样子货”,还是真能打的“实力派”?
POSTECH团队显然也意识到了这个问题的分量。他们做了一个关键实验:选取一个高速线接收器电路,将其N阱层全部删除,然后让微调后的模型重新生成N阱。接着,提取寄生参数,进行后仿真,将结果与人类专家设计的原始版图对比。
结果让模拟工程师们很难不在意:
- 灵敏度
:模型版图1.6mV vs 人类版图2.05mV(越低越好,AI胜) - 失调电压(3σ)
:模型版图15.57mV vs 人类版图16.44mV(越低越好,AI胜) - 输入参考噪声
:模型版图0.457mVrms vs 人类版图0.317mVrms(越低越好,人类胜)
两个赢了,一个输了。整体而言,模型生成的N阱方案在模拟性能上与人类设计基本持平,甚至在关键指标上有轻微优势。
这说明什么?说明模型并不是在机械地模仿几何图形。它从人类专家的设计中学到了一些更深层的东西——比如,N阱边缘应该与PMOS器件保持怎样的距离,阱的形状如何影响应力分布从而影响载流子迁移率……这些物理效应,模型并不“理解”,但它通过大量观察优秀设计,找到了能复现类似效果的模式。
这是一种“知其然,而不知其所以然”的直觉——但很多时候,好的模拟版图工程师不也依赖这种在实践中磨练出来的直觉吗?
从“一个工艺”到“所有工艺”的想象空间
模拟版图设计还有一个令人头疼的特点:换一个工艺节点,很多规则都要重新适应。28nm的经验不能直接搬到65nm,反之亦然。如果模型只能在单一工艺上工作,它的实用价值将大打折扣。
POSTECH团队的实验再次打破了这种担忧。他们将在28nm工艺上训练好的N阱生成模型,直接应用于一个65nm的接收器版图,所需的调整仅仅是:改变像素尺寸(从10nm变为17nm)和映射图层编号。模型从未见过任何65nm版图,但在“零样本”条件下,它生成的N阱与真值的IoU达到了91.3%。
这种跨工艺的泛化能力,意味着基础模型学到的不是某个特定工艺的“死规则”,而是更通用的“好版图应该长什么样”的审美。只要在预处理阶段做好换算,同一个模型就有可能在多个工艺节点上发挥作用。这对于需要同时维护多个工艺设计套件的团队来说,是一个巨大的吸引力。
讨论:模拟芯片工程师的“金手指”会褪色吗?
读完这篇论文,一个无法回避的问题是:如果AI已经能生成性能可媲美人类的模拟版图,那么模拟版图工程师的不可替代性在哪里?
我认为,答案不是一个简单的“会被替代”或“不会”,而是角色会发生根本性转变。
这篇论文展示的能力仍然有边界。它处理的是相对局部的、模式化的任务——在已有版图框架下补全缺失的元素,或者完成单根走线。它还不能从电路网表出发,独立完成完整的芯片级版图规划。它还依赖于人类专家提供的初始版图作为“上下文”,而这些初始版图的设计质量直接影响模型的输出。
更重要的是,当前模型仍然需要人类来做最终决策。比如,论文中提到通孔生成的总体成功率是88%,对于失败的那些案例,需要人类判断是调整输入还是接受替代方案。在金属走线任务中,布线顺序和优先级目前仍需人类规划,模型只在单根走线的生成上发挥作用。
但方向已经清晰了。如果说今天模拟版图工程师70%的时间花在“执行”——画形状、对规则、调间距,30%的时间花在“决策”——评估架构、权衡约束、做出折衷;那么随着这类基础模型的成熟,“执行”部分的比重将不断下降,而“决策”部分的价值将更加凸显。
未来的模拟版图工程师,可能更像一个“AI指挥家”。他不需要亲手画每一条线,但他需要知道:给AI什么样的输入,如何评估AI的输出,在哪些关键点上需要人工干预,如何设计版图的全局架构让AI在局部有最优发挥。金手指不会消失,但它将从“画线的手”变成“指挥的手”。
而对于整个行业来说,这篇论文的意义在于,它第一次系统性地验证了“基础模型+自监督学习+微调”这一范式在模拟版图自动化中的可行性。从需要为每个任务从头开发专用模型,到用一个预训练基础模型快速适配各种下游任务,这种改变将大幅降低AI辅助版图设计的门槛和成本。
正如论文作者在结尾所展望的,这只是一个开始。更大规模的数据集、更多样的下游任务、更复杂的全局版图生成,都是有待探索的下一站。但至少从这篇论文来看,通往“模拟版图自动驾驶”的道路,已经亮起了第一盏绿灯。
工程师们,准备好和AI做同事了吗?
回顾芯片设计的历史,每一次工具的革命都会引发“人是否会被替代”的焦虑。从手绘版图到CAD工具,从原理图网表到RTL综合,技术的跃迁改变的是工程师的工作方式,而不是消灭了工程师这个职业。
但这一次略有不同。因为AI学的不再是确定的规则,而是人类设计师的品味和直觉。当一种曾经被认为是“只可意会不可言传”的能力开始被AI捕获和复用时,我们确实需要重新思考,作为工程师,我们的核心价值究竟在哪里。
或许,这也是一个契机——把那些重复性的、依赖经验的“劳动”交给AI,让自己有更多精力去做那些真正需要创造力和系统思维的“设计”。
所以问题不是“金手指还灵不灵”,而是“你的下一根手指,愿意伸向哪里?”