 夜雨聆风
夜雨聆风





AI 工具怎么用更省钱?我总结了 13 个实用小技巧
大家好,我是悟鸣。
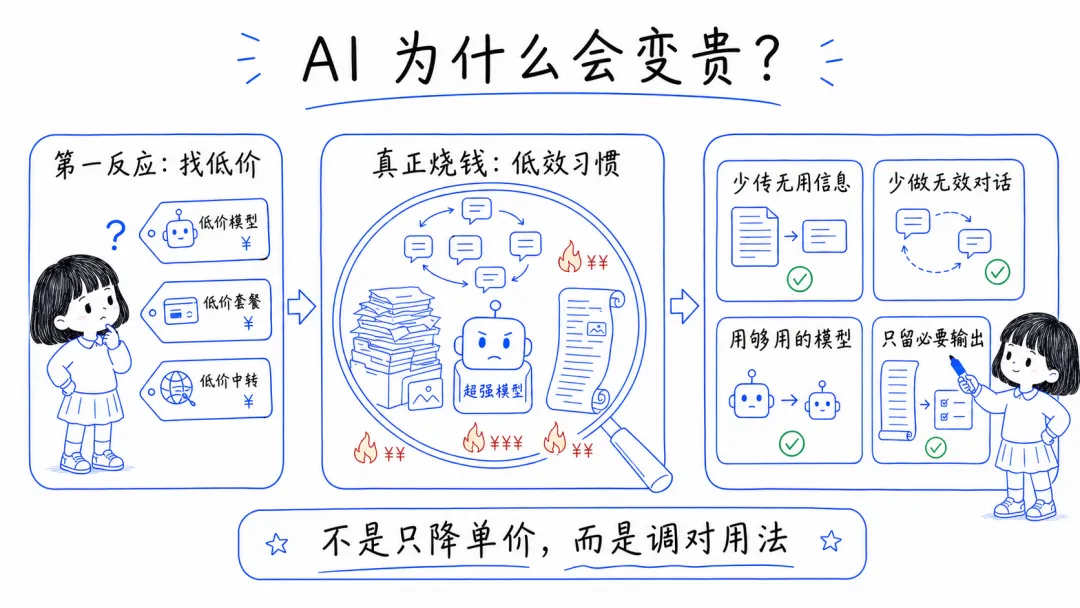
很多人一提到“AI 太贵”,第一反应是去找更便宜的模型、更低价的套餐,或者更便宜的中转站。
但我观察下来,真正让成本失控的,往往不是模型单价,而是使用习惯。
同样一个任务,有的人两三轮就结束,有的人来回拉扯十几轮;有的人只给必要材料,有的人把无关上下文一股脑全塞进去。钱就是这样一点点烧掉的。
所以这篇文章,我想分享一些自己平时常用的省钱思路。核心其实很简单:少传无用信息,少做无效对话,用够用的模型,只保留必要输出。
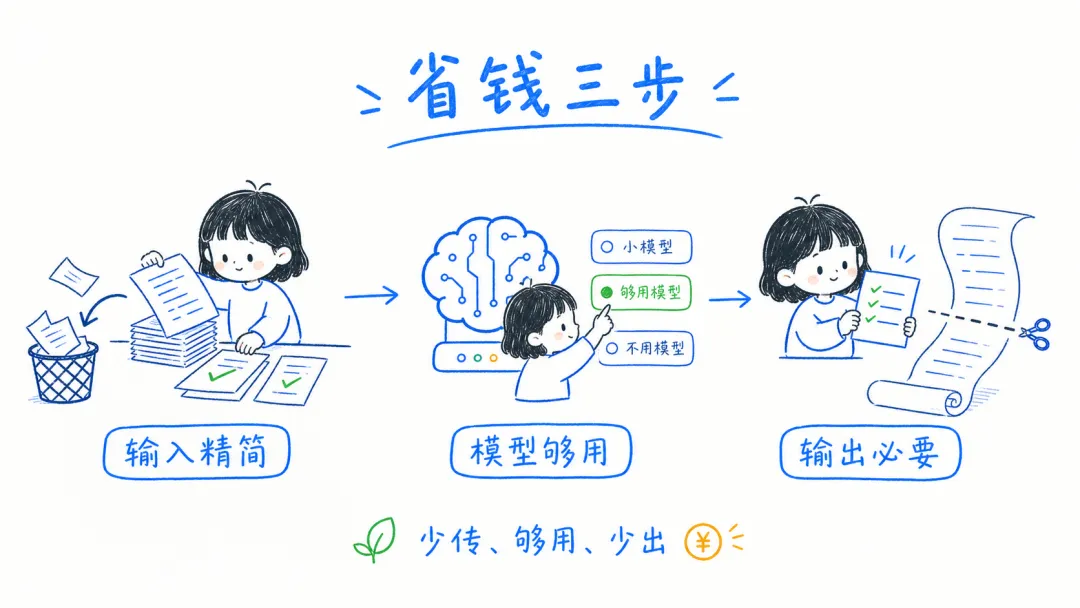
如果把一次 AI 调用拆开看,成本大致出在三件事上:输入、模型和输出。输入越长,模型越贵,输出越啰嗦,账单通常就越高。后面这些方法,基本也都是围绕这三件事展开的。
1. 高频使用时,先算清套餐账
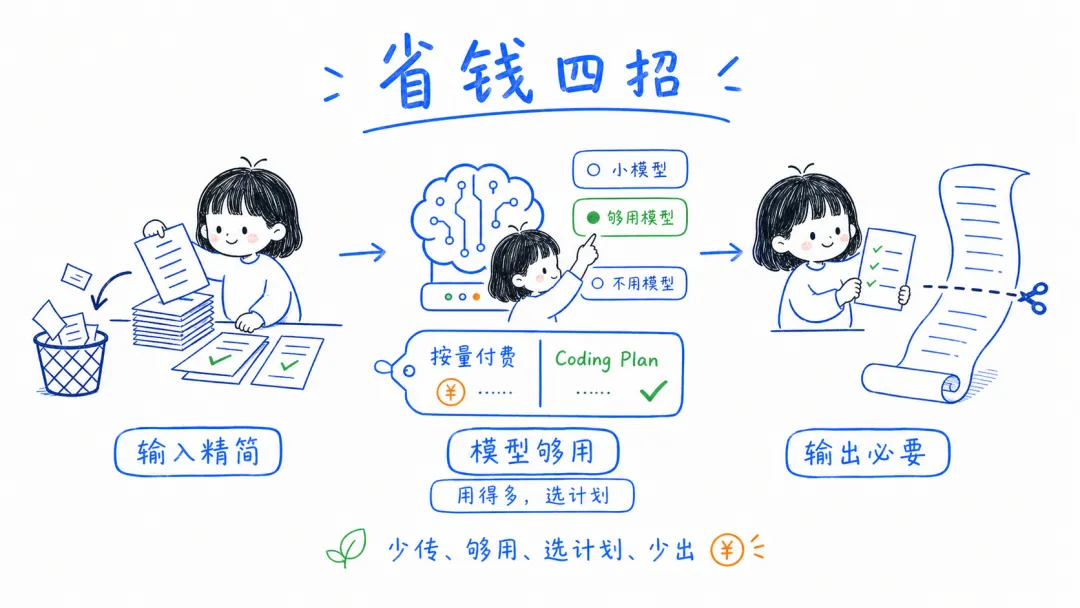
如果你本来就是高频用户,别只盯着按量计费。很多时候,订阅型的 Coding Plan 反而更划算,尤其是在你每天都要写代码、改稿、跑工作流的时候。
省钱的第一步,不一定是把单次成本压到最低,而是先选对计费方式。低频用户按量更灵活,高频用户用套餐往往更省。
2. 新话题及时开新对话,别让上下文越滚越长
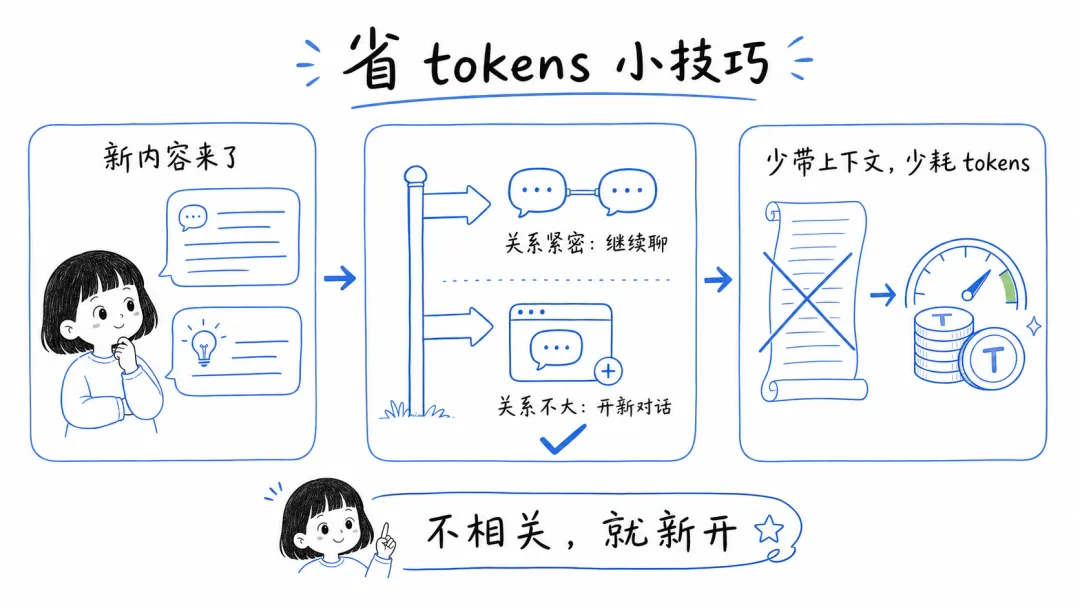
持续对话当然方便,但如果新问题和前面的内容关系已经不大,最好及时开一个新会话。否则你以为自己只是多问了一句,模型实际上是在带着一整段历史记录陪你重来一遍。
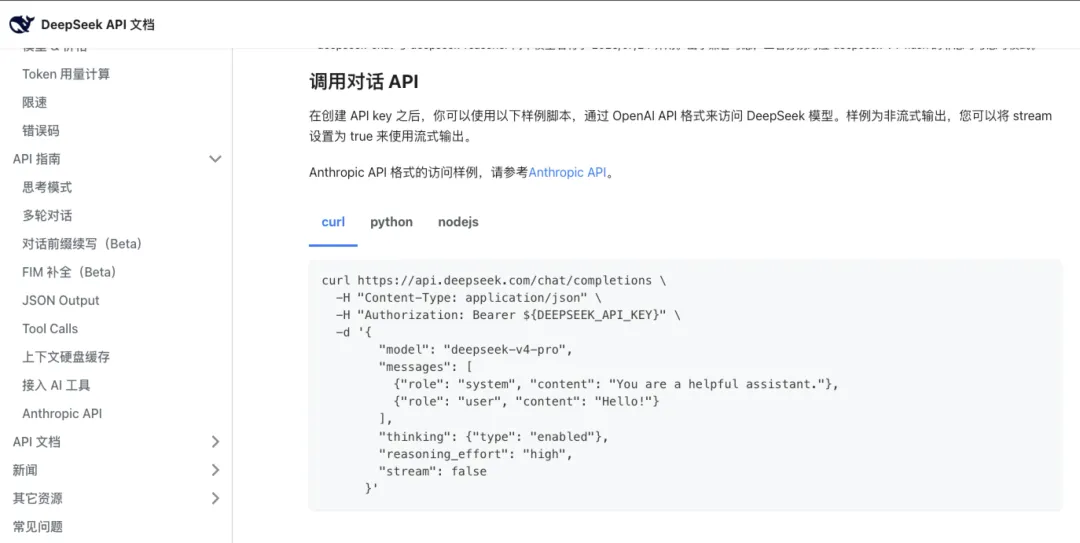
大模型并不会天然“记住你”。它之所以能接上前文,是因为系统会把系统提示词、历史消息和你的新输入一起重新发给模型。
每次请求都会把前面的内容继续叠加进去,所以对话越长,附带的上下文就越大,成本也会跟着涨。
所以只要话题切换了,或者前文已经不重要了,就尽快开新的对话。这样既能省 token,也能减少无关上下文对结果的干扰。
3. 一次把需求说清楚,少来回拉扯
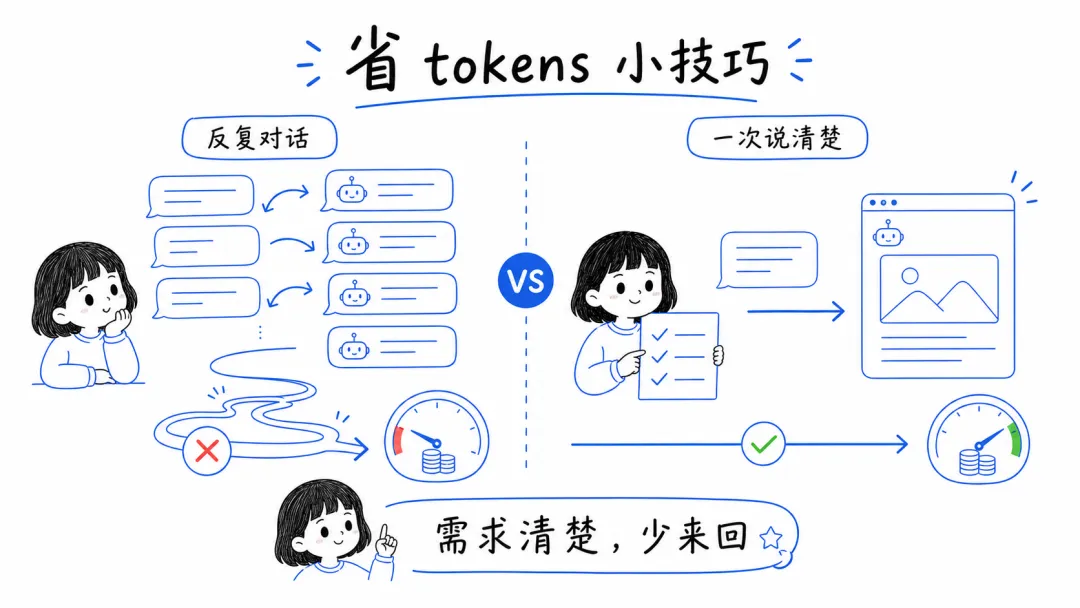
如果条件允许,尽量在一开始就把目标、限制条件、交付格式一次说清楚。
很多人的浪费,不是浪费在“大问题”上,而是浪费在“再改一点”“再补一句”“再换个版本”这种反复拉扯上。你说得越清楚,模型越容易一次给到更接近结果的答案,你自己的时间也省。
4. 输入只给必要信息,别把整个仓库都塞进去
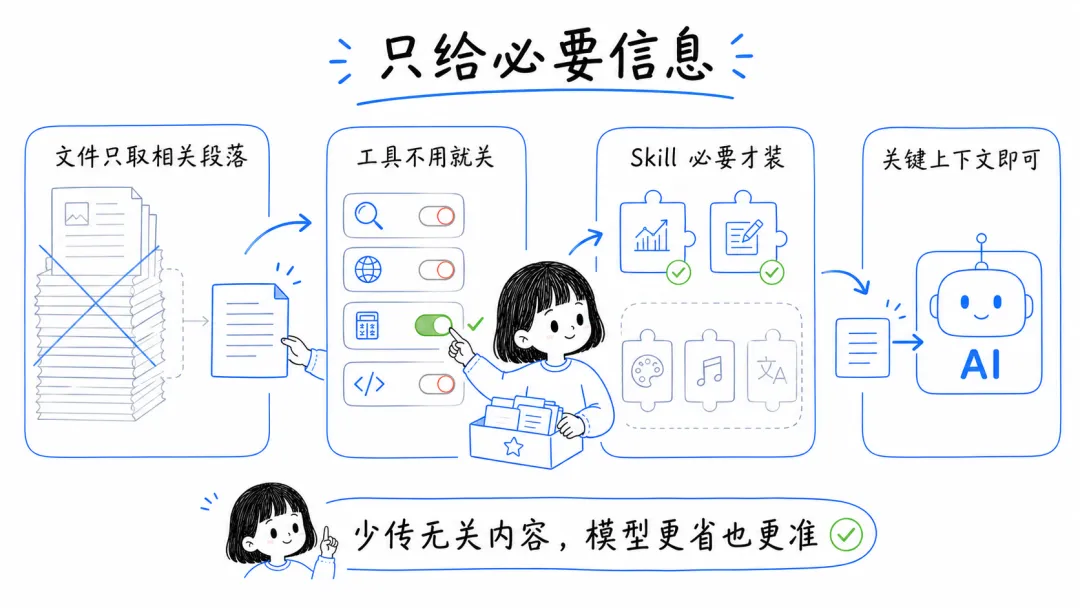
很多时候,AI 并不需要知道全部背景,它只需要知道和当前任务直接相关的那一部分。
比如一个文件很长,但你只想改其中一段,那就只给那一段;比如某些工具、某些 Skill 这次根本用不到,那就别全开着。输入越克制,成本越低,模型也越不容易被噪音带偏。
5. 模型分层使用,别什么活都上顶配

省钱很有效的一招,就是不同任务配不同模型。
比如做方向判断、写关键提示词、处理复杂推理,可以用更强的模型;整理格式、跑基础流程、做简单改写,可以交给更便宜的模型。
不是每一次调用都值得上“最贵那档”。把模型分层之后,你会发现整体成本能降很多,而且效果未必变差。
6. 能用传统工具解决的,就别硬让模型做
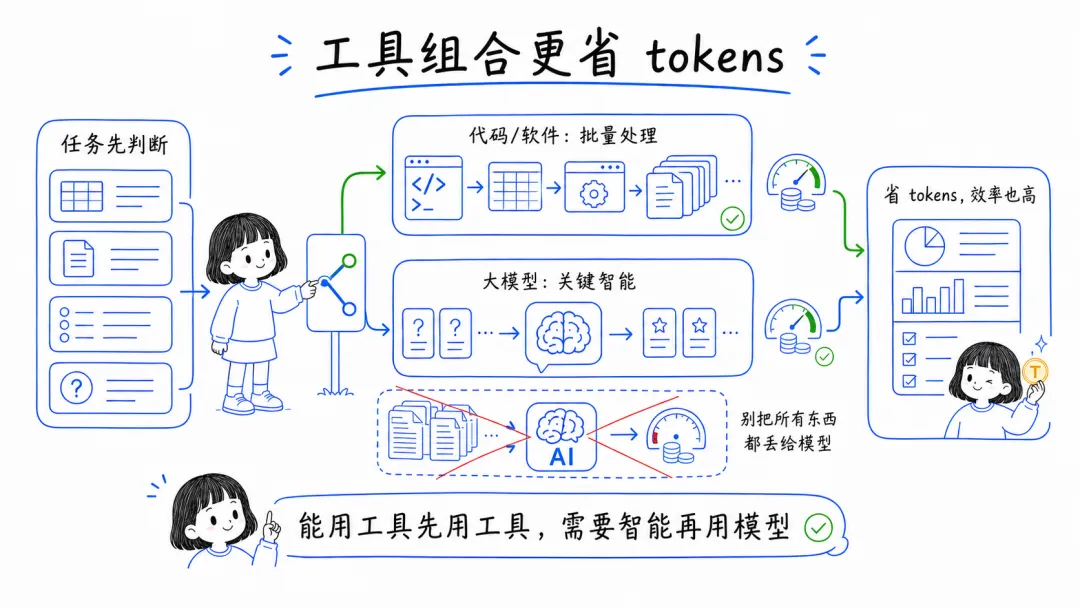
有些事情本来就更适合交给代码、脚本或者传统软件。
尤其是那些规则明确、重复性强、又很吃 token 的工作,优先用传统工具往往更省,也更稳定。把大模型留给真正需要理解、判断、生成的部分,成本和效率都会更健康。
7. 该压缩就压缩,别让长上下文一直拖着跑
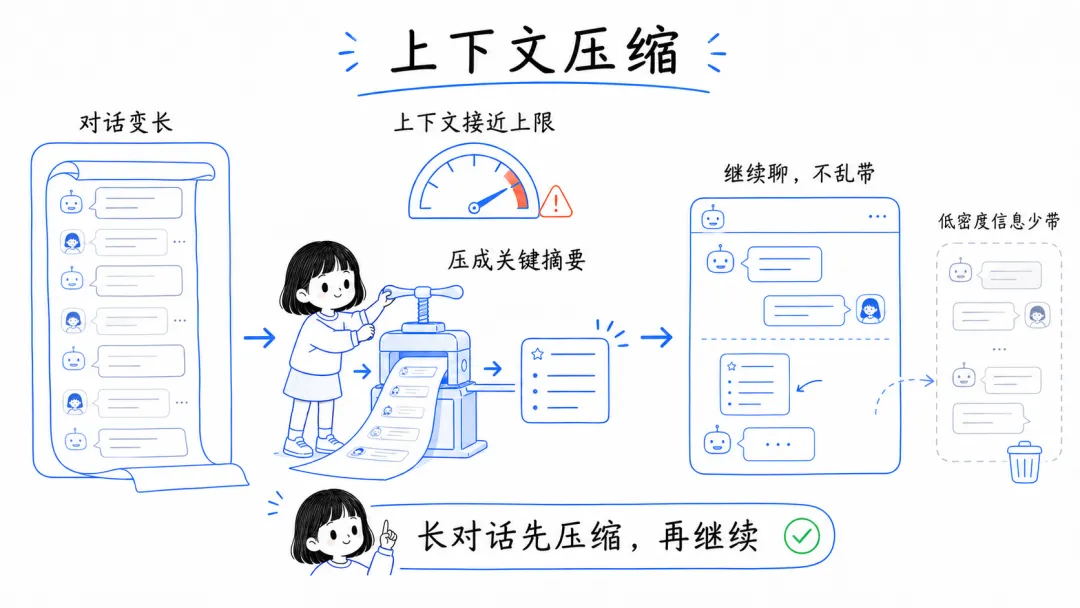
如果你必须长时间持续对话,可以考虑上下文压缩。对话一长,信息密度通常会越来越低,这时候还带着完整上下文继续聊,性价比就会很差。
必要的时候,手动做一次压缩也很有用。把前面已经讲过、但后面还要继续用的信息整理成短版本,再把长上下文替换掉,后续消耗会明显下降。
如果你也在维护长期记忆、项目设定或者 agent 配置,这类文件很容易越积越长。像龙虾里的 memory 或者 soul 文件,定期压缩一下,通常比一直堆着更省。
有些工具本身就支持自动压缩,甚至可以调整触发条件。能自动化的地方,尽量别靠自己每次手动盯着。
8. 把低频但很长的上下文卸载出去
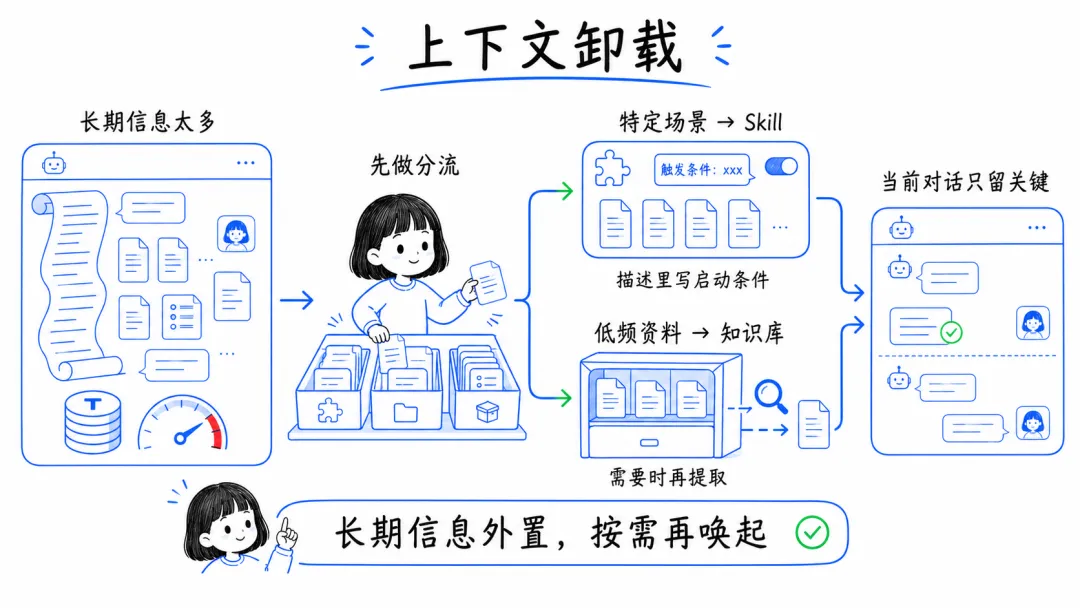
还有一种很有效的思路,是把不需要常驻的长上下文“卸载”出去。
比如某些长期记忆只有在特定任务下才会用到,就可以整理成 Skill,或者放进知识库,需要时再加载。这样做的好处是,常用对话会轻很多,只有在真正需要那部分信息的时候,才付那一笔 token 成本。
9. 让模型只输出你真正想要的东西
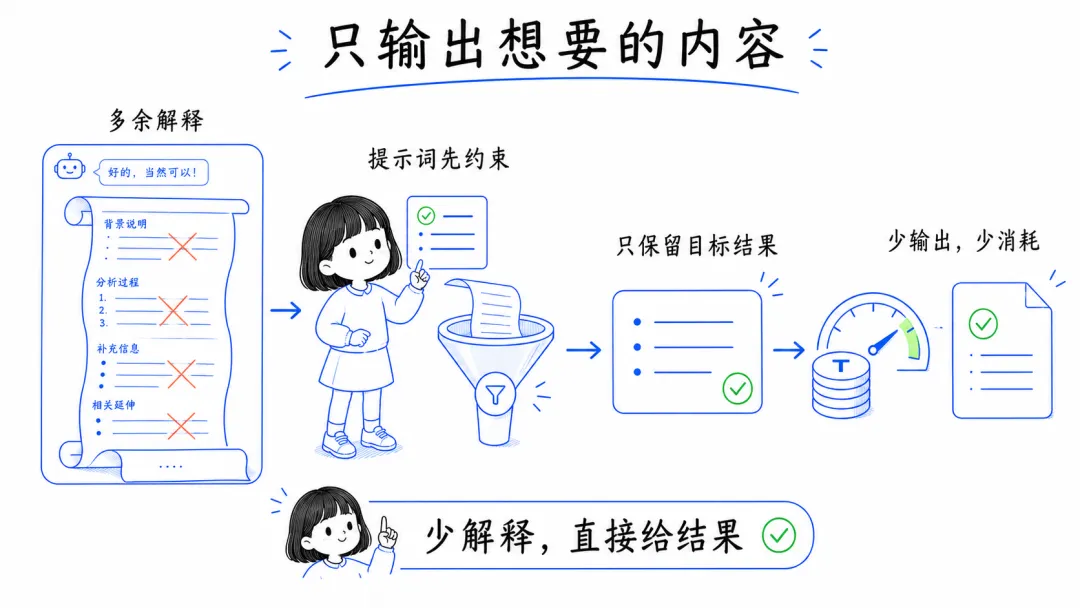
很多时候,我们浪费的不只是输入,还有输出。
如果你只需要一个标题、一段摘要、一份清单,就直接告诉它“只输出结果,不要解释过程”。省下来的不只是 token,还有你自己筛信息的时间。
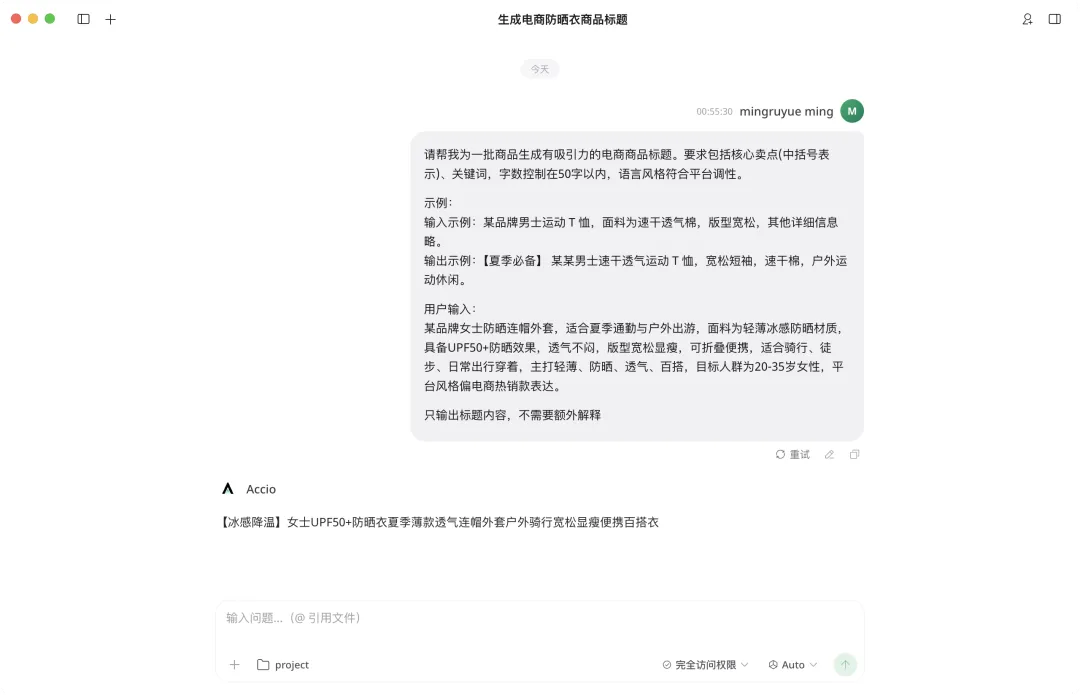
比如让它帮你产出一个商品标题,那就直接强调“只输出标题内容”。一句限制,往往就能省掉后面一大段没必要的解释。
10. 能用缓存的场景,尽量用缓存
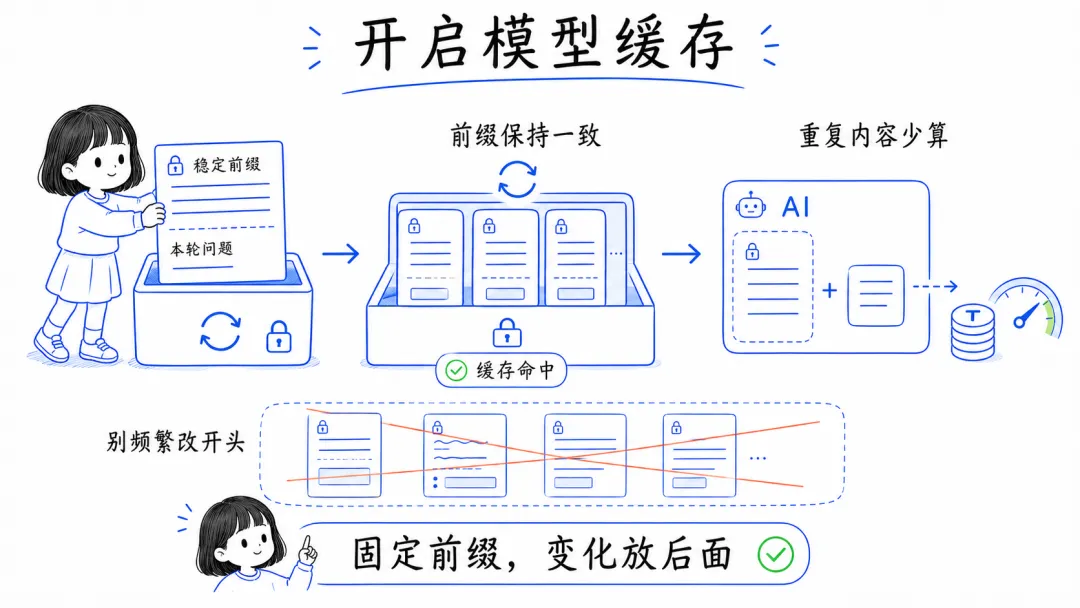
如果平台支持模型缓存,尽量把稳定的前缀保留下来。
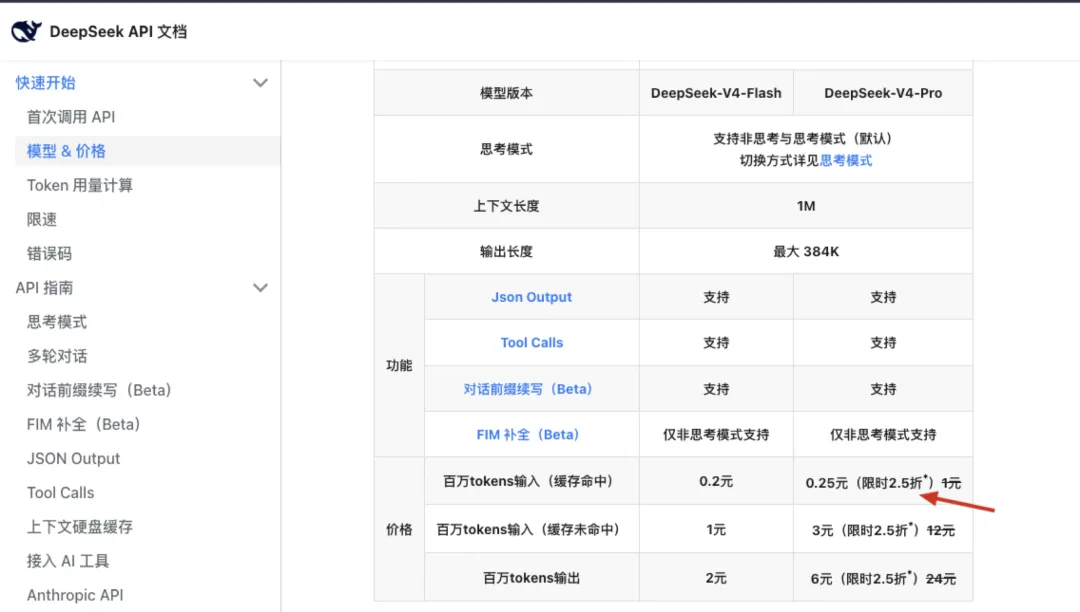
很多服务商对缓存命中的价格会便宜不少。对那些反复调用、前缀高度重复的工作流来说,这个收益很直接。
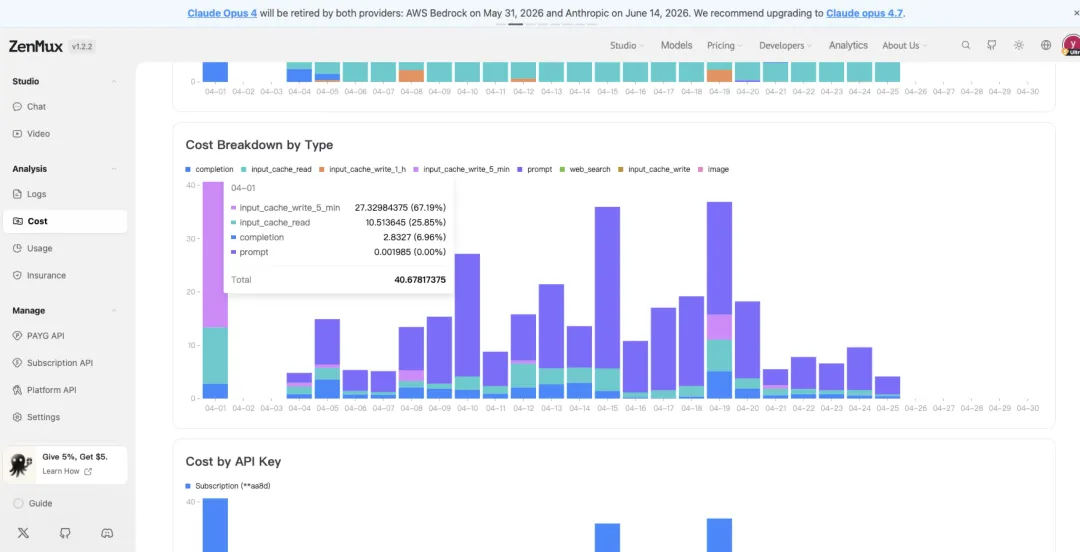
这是我在 ZenMux 里的一个消耗截图。

能看到命中缓存以后,token 成本会降下来不少。所以如果你的工作流本来就有很多固定前置内容,比如系统提示词、模板、长期说明,就值得专门设计一下缓存友好的结构。
11. 合理选择单智能体还是多智能体
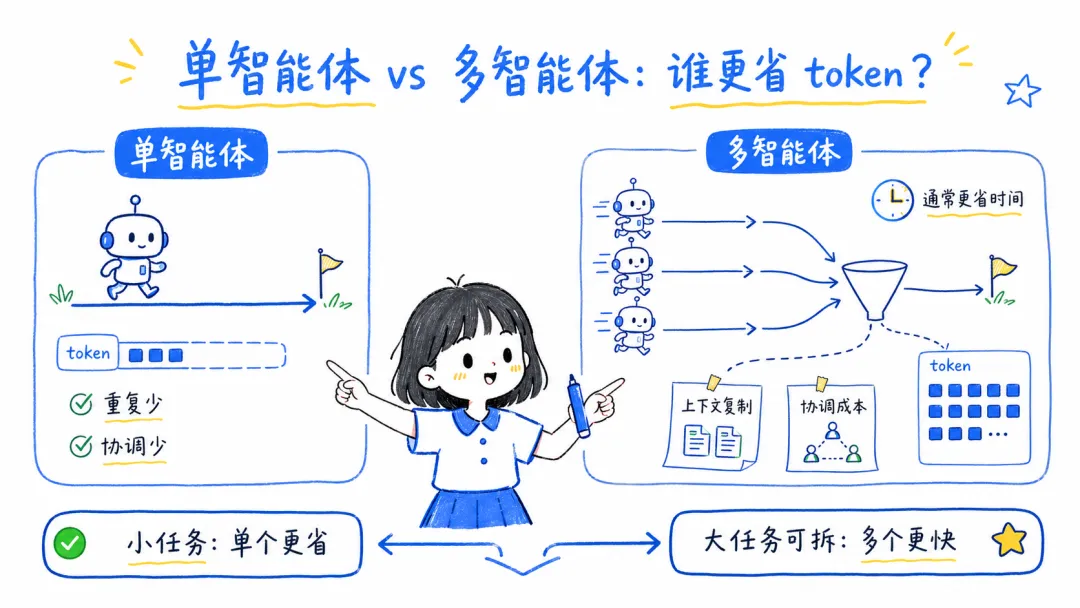
很多人总是喜欢看,很多人被自媒体的说辞忽悠了,总感觉多智能体什么都好,但实际上并不是。
对一些重复比较少的,协调也比较少的中小型任务的话,其实有的时候用单智能体反而更省资源,效果甚至更好。那对于复杂性的需要多协同的任务,那有可能多智能体效果更好。
12. 复杂任务先规划
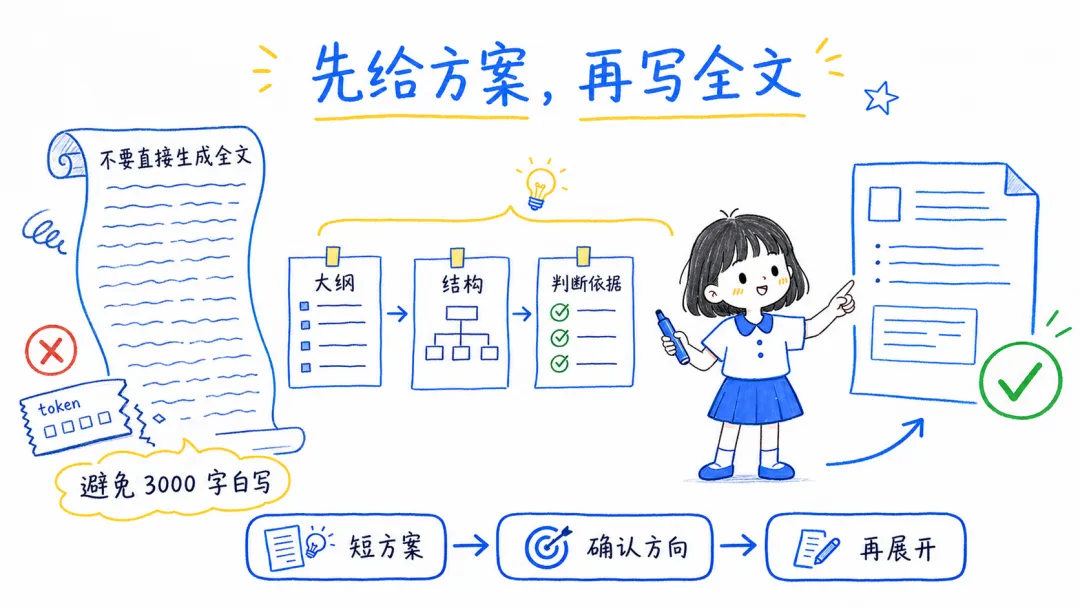
复杂任务先让模型给方案,不要一上来就生成全文 很多长文、脚本、方案类任务,最贵的不是思考,而是反复生成长文本。
可以先让模型输出大纲、结构、判断依据,确认方向没问题后再展开。
这样能避免“写了 3000 字才发现方向错了”的浪费。
13. 别为了便宜,掉进更贵的坑
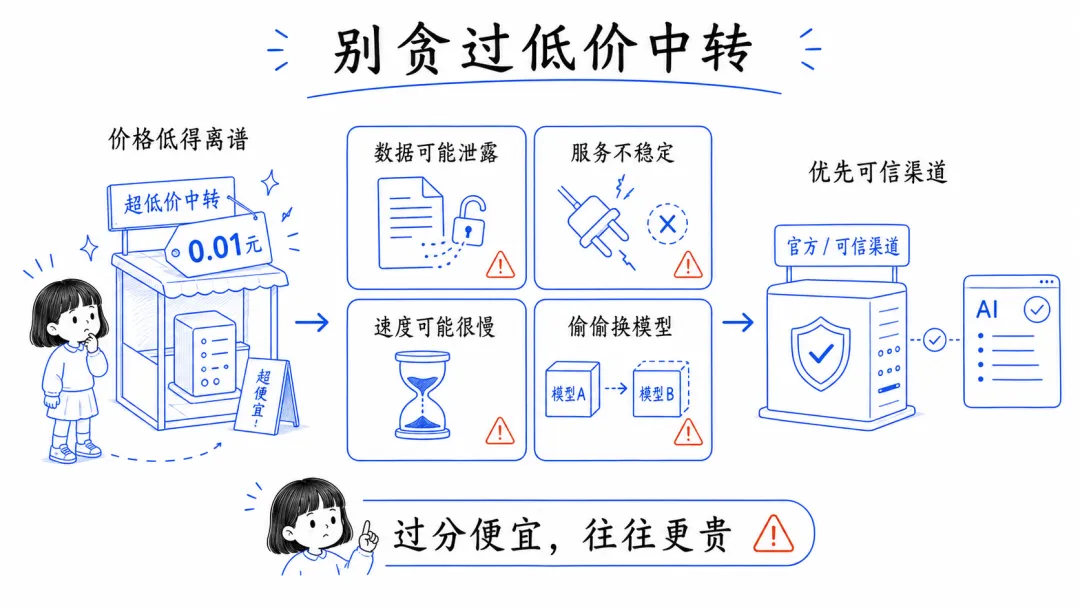
我不太推荐明显便宜得离谱的大模型中转站。价格低到不合理,往往意味着别的地方要付代价。
常见问题无非几种:数据风险更高、服务不稳定、速度慢、模型被偷偷替换,最后效果和体验都打折。
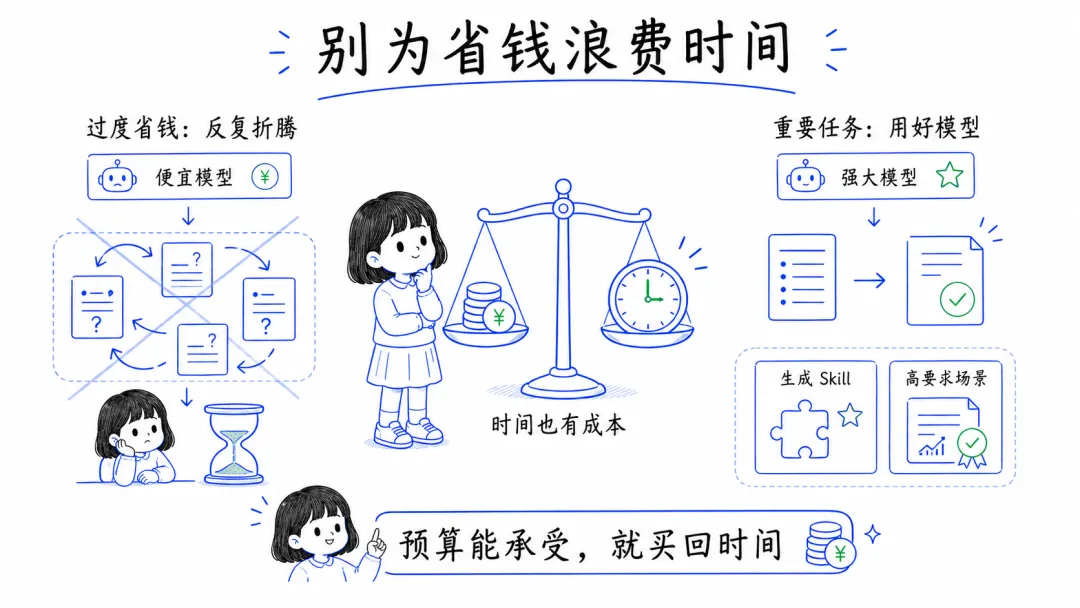
还有一点也很重要,不要为了省模型的钱,反而浪费自己更多时间。
如果是重要任务、要求高的场景,或者能直接影响结果质量的关键环节,该用更好的模型时还是要用。只要在自己能承受的范围内,时间很多时候比 token 更贵。
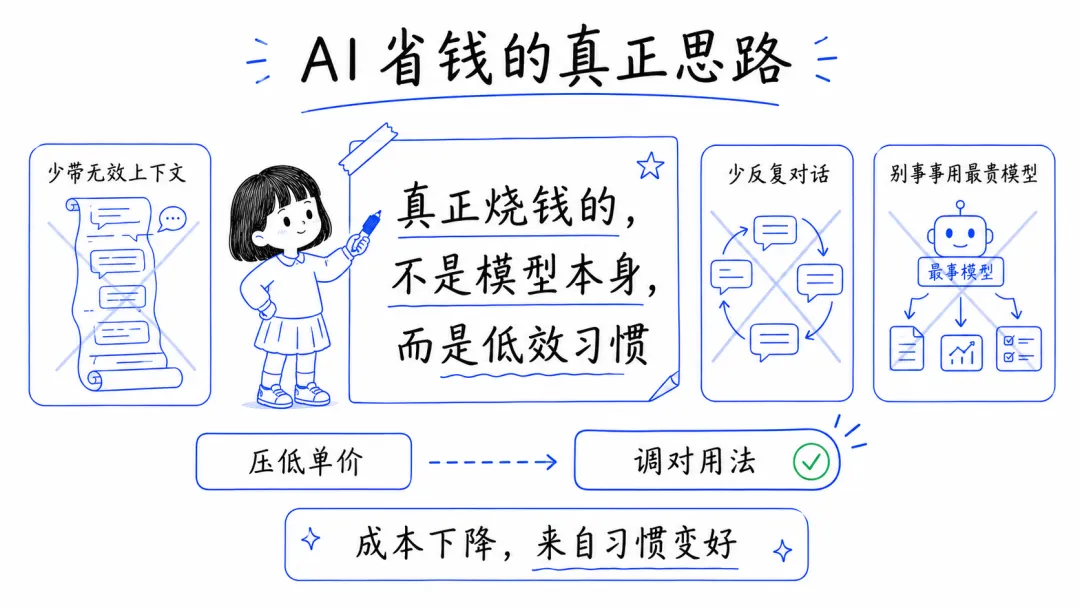
总的来说,AI 省钱并不是去极限压价,而是把使用方式调对。少一点无效上下文,少一点反复对话,少一点“所有事情都让最贵模型来做”,你的成本往往就会自然下来。
如果你只准备记一句话,我觉得可以记住这个:
真正烧钱的,很多时候不是模型本身,而是低效的使用习惯。
你还有哪些省钱小妙招?欢迎在评论区分享和交流。