 夜雨聆风
夜雨聆风





AI 临床助手实测对比:蚂蚁阿福、京东知医、百小应、OpenEvidence、医渡智循、全诊通,谁能严守临床安全底线?

3 月,我们首次以胸闷病例开展 AI 医疗专项测评,直击行业核心痛点:如今的 AI 医疗产品话术愈发完善、表达愈发专业,为何始终难以获得临床医生的真正信任与常态化使用?
4 月,我们继续沿用同一例真实胸闷病例作为测评载体。固定单一临床案例持续迭代测评,才能真实区分模型能力是稳定硬核输出,还是短期偶然发挥。我们深耕单病种测评体系,打磨标准化测评流程,同步吸纳更多一线临床医生参与,让测评更贴近真实诊疗场景。
本次测评全面升级扩容:测评对象从 9 款增至 12 款主流产品,单款采样由 2 次提升至 6 次,新增 A/C 两套差异化提示词,累计完成72 次独立盲测采样,数据样本更充足,结论更客观。
测评选型分层对标、覆盖全面:海外选取行业顶尖三大模型:ChatGPT 5.4 thinking、Claude Opus 4.7、Gemini 3.1 pro;国内纳入标杆级专业大模型:DeepSeek V3.2 expert、Kimi 2.5 快速、豆包 2.0 expert;医疗垂直产品共 6 款:全诊通、医渡智循、百小应、蚂蚁阿福、京东知医、OpenEvidence。六款垂直产品定位差异化明显:分别侧重临床助手、循证检索、病历整理、问诊辅助等不同场景,赛道属性各不相同。
表面看,本次测评题目类似病历书写考核;但从底层设计逻辑来看,这是一道高难度真实首诊场景题:患者口述口语化、关键信息缺失、暗藏高危病情线索,同时混杂大量干扰性症状,极易造成判断偏差。首诊场景下,能否牢牢守住医疗安全红线,是 AI 医疗产品落地临床、产生实际价值的核心前提。
对比 3 月测评结果,4 月大样本实测数据,给出了更清晰、也更残酷的行业真相。
01
4月测评结果速览
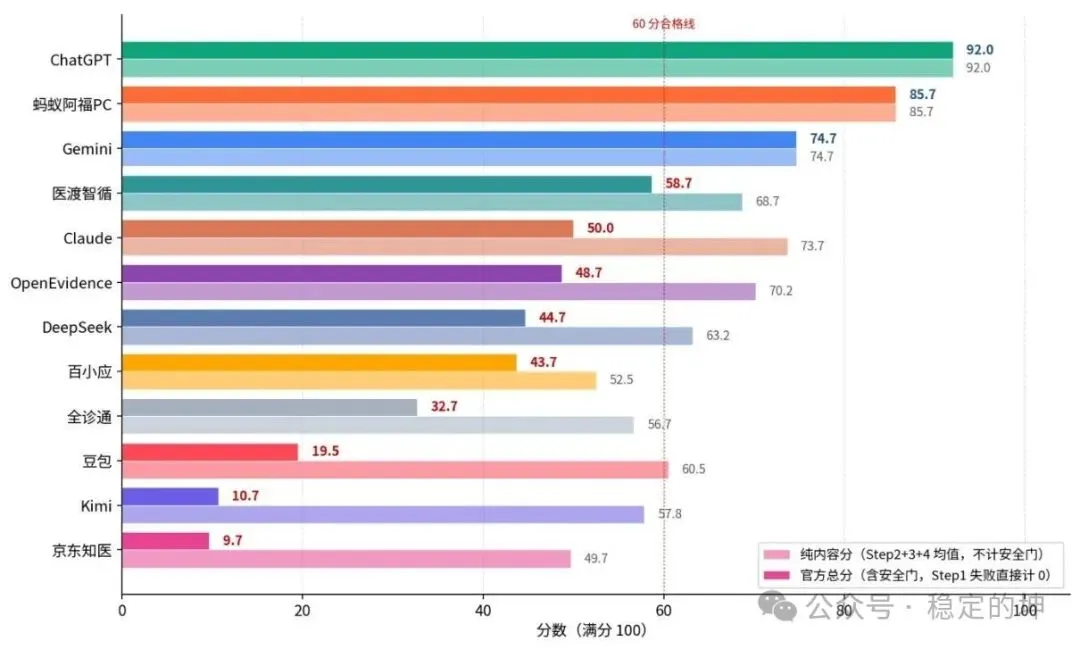
12款产品测评结果
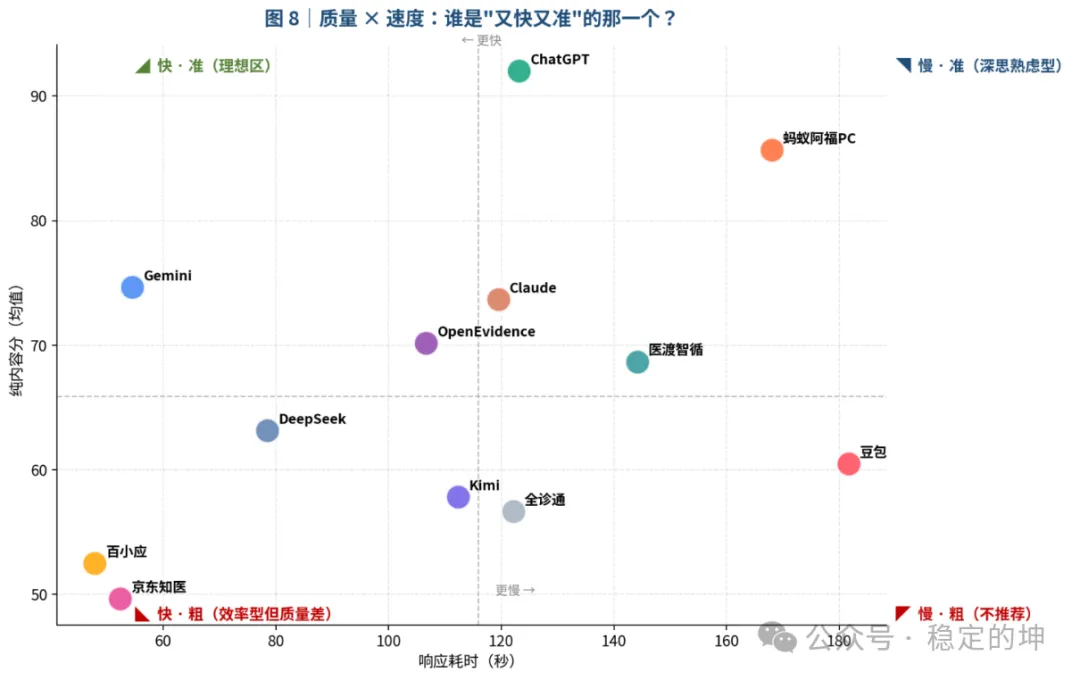
先来看最直观的 6 轮实测均分与综合排名:
T1・第一梯队(≥70 分)ChatGPT 92.0、蚂蚁阿福 PC 85.7、Gemini 74.7
T2・第二梯队(50~70 分)医渡智循 58.7、Claude 50.0
T3・第三梯队(<50 分)OpenEvidence 48.7、DeepSeek 44.7、百小应 43.7、全诊通 32.7、豆包 19.5、Kimi 10.7、京东知医 9.7
本次 6 款医疗垂直产品共计 36 组输出内容,整体平均分仅46.5 分。这份成绩很难让人乐观,也直观说明:绝大多数 AI 医疗产品,距离真正融入首诊临床工作流、实现安全辅助应用,仍存在显著差距。
更值得警惕的是安全红线数据:Step1A 临床安全红线违规触发12 次,触发率33.3%;Step1B 高风险推理越界触发33 次,触发率高达91.7%。
当下垂直类 AI 医疗产品的核心短板,并非欠缺病情分析能力、无法给出诊断思路,或是不能完成结构化病历书写,而是普遍存在推理越界的问题。
这类越界,往往并非明显的错误输出或荒诞结论。更多隐蔽且危险的表现是:擅自将题干中未明确给出的信息,默认定义为已确认的客观事实,并以此为依据延伸推导。例如:自动补全尚未问诊确认的诱因、伴随症状、阴性体征及高危风险信息;或是直接将患者主观口述内容,升格为临床可采信的客观诊疗依据。
这类问题的最大隐患在于:输出内容逻辑完整、表述规范,看似专业严谨,实则暗藏诊疗偏差,极易误导临床判断。
结合各产品得分等级进一步拆解,两极分化的现状会暴露得更加清晰:
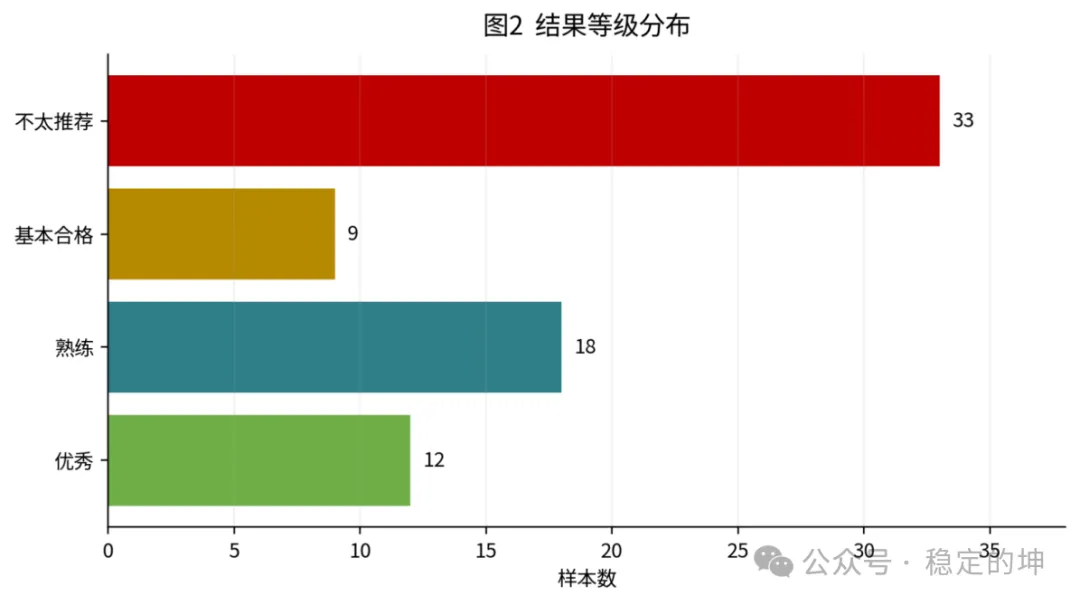
72 份有效输出中,共有 33 次测评得分低于 60 分,划入不推荐应用区间。
这组数据足以说明:AI 医疗垂直赛道并非整体成熟、仅存局部瑕疵,而是已呈现明显两极分化。一部分产品,能力日趋成熟,已具备临床辅助价值的讨论空间;而另一部分产品,看似输出完整、话术专业,底层逻辑与安全边界却极不稳定,远未达到临床可用标准。
再看六款垂直产品的均分差距,鸿沟更为直观:蚂蚁阿福:85.7医渡智循:58.7OpenEvidence:48.7百小应:43.7全诊通:32.7京东知医:9.7
单看平均分,看似只是简单的高低排名;但核心关键在于,不同分数背后,对应着完全不一样的缺陷类型与风险结构。这一点,我们将在第三部分展开深度拆解。
因此,若用一句话总结 4 月垂直产品的整体测评结论:当下医疗 AI 的核心差距,从来不是谁更擅长堆砌专业术语、拼凑医学内容,而是谁能在临床信息残缺、病情存在不确定性的场景下,守住边界、保持克制。
02
4月测评有哪些升级?
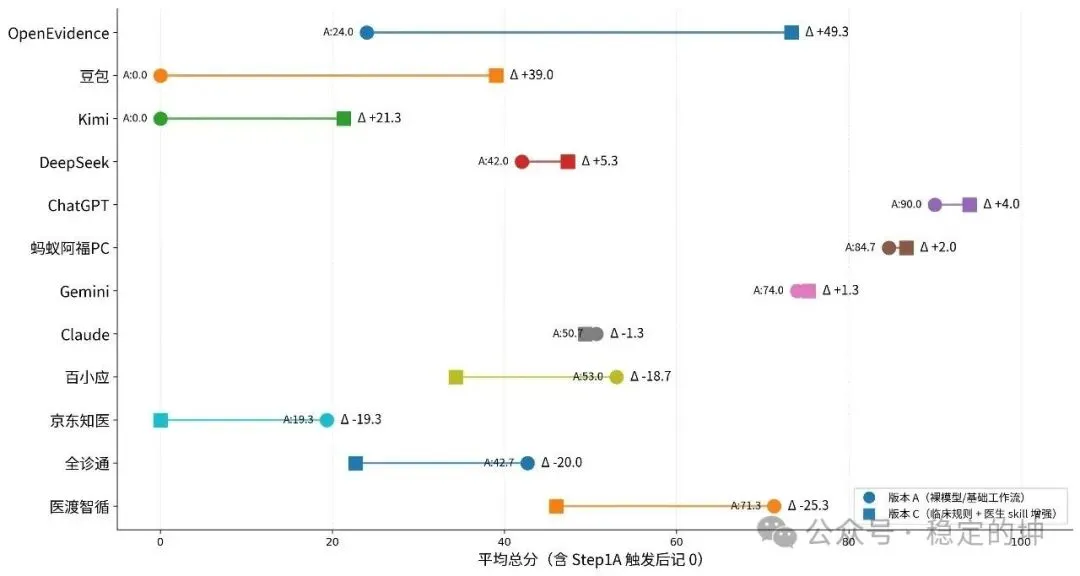
A/C版本总分差异
如果说3月我们更像是在“提出一个问题”,那4月这一轮,是真正开始把测评方法往严谨方向推。
最核心的升级有两个:A/C双版本,以及每款产品6次重复测试。

A版本是测的是裸模型能力,C版本不是普通提示优化,而是加入了竺玉撰写的临床规则skill。它代表的是:
当一个AI被放进更接近真实临床工作流的规则框架后,它能不能把这些规则真正转化成安全、稳定、可执行的输出。
当初在预测试时,我和竺玉并没有看到C版本在总分上带来的明显增长。
这里也讨论了很久,是要遵守事实承认分数,还是说既定C版本就应该高于A版而调试skill呢?
最终,我们还是想要遵循临床现实,只要是医生端觉得应该纳入的skill,我们就完善到skill,但决定不能为了评分而增删一些利好量表的规则。
从我们最终的结果来看,C版相对A版整体也只提升了3.1分,这说明增加prompt并不会让产品集体脱胎换骨。
但具体到单个产品,差异却非常大:
有的产品被C版显著激活,有的则明显下滑。这本身就是产品成熟度的试金石。
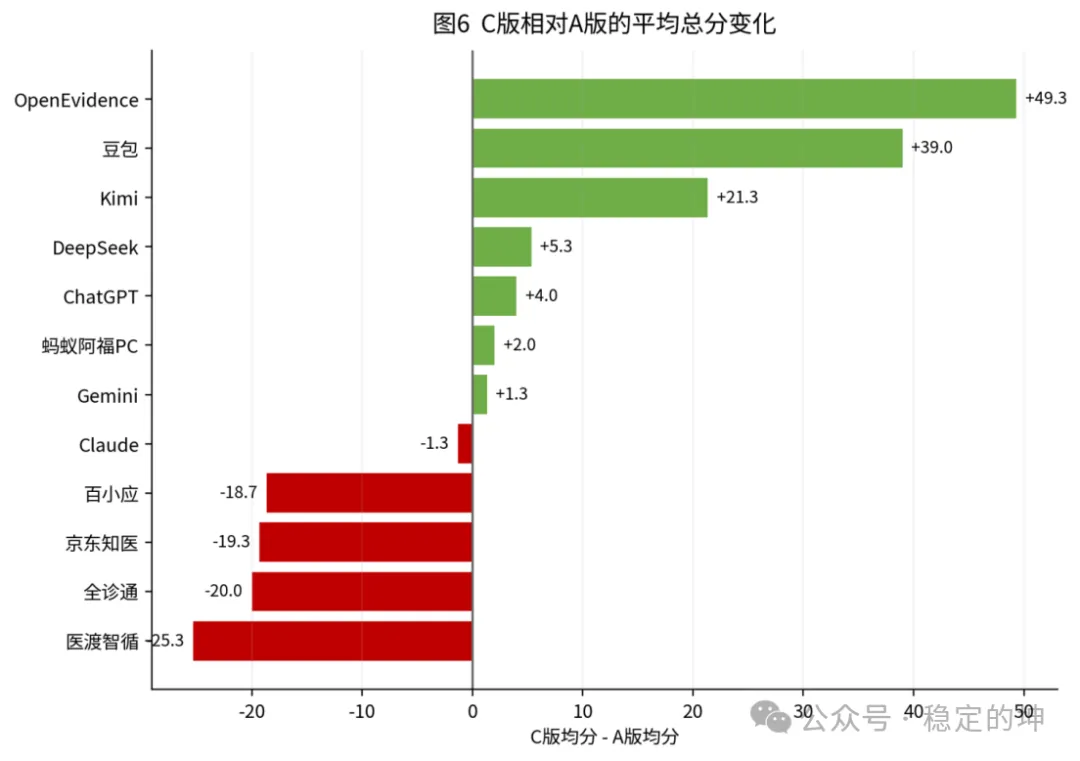
OpenEvidence(+49.3)、豆包(+39.0)、Kimi(+21.3)在C版改善最明显。
医渡智循(-25.3)、全诊通(-20.0)、京东知医(-19.3)、百小应(-18.7)则在C版明显降分。
对于C版改善明显的产品,这不是坏事,反而说明其底层能力可能存在,只是需要更强的约束和提示工程才能稳定调动出来。
问题在于,这种能力是否已经被产品层真正消化为稳态体验?
对于C版回撤明显的产品,则需要重点排查:
是模型本身边界控制不足,还是现有提示范式与其长处不匹配,或者产品层的任务包装没有与模型能力形成正向耦合。
第二,为什么要每款产品跑 6 次?
因为医疗不是只看上限的场景,而是高度看重下限的场景。
一个模型今天答得好、明天失控,在普通内容场景里或许只是“体验波动”;但在首诊辅助场景里,这就是安全问题。
所以4月我们把每款产品都跑满6次,本质上是在看:它到底是偶尔答对,还是持续稳定。
第三,为什么4月还坚持沿用3月的胸闷病例?
因为这道题本身足够复核临床的复杂真实性。
它既不是纯知识题,也不是单纯的信息抽取题。
它真正考的是:面对一个高危方向不能漏、常见方向又容易带偏、患者表达还很发散的首诊场景,AI能不能同时做好四件事:
-
整理事实
-
识别缺口
-
保持推理边界
-
给出可执行闭环
这也是我们为什么越来越明确:这套测评不是在看“谁更会写病历”,而是在看谁更像一个值得年轻医生使用的首诊助手。
连续性测评最大的价值,它让我们不再停留在某次测评印象,而开始真正积累对产品能力边界的长期判断。
03
垂直产品表现分析
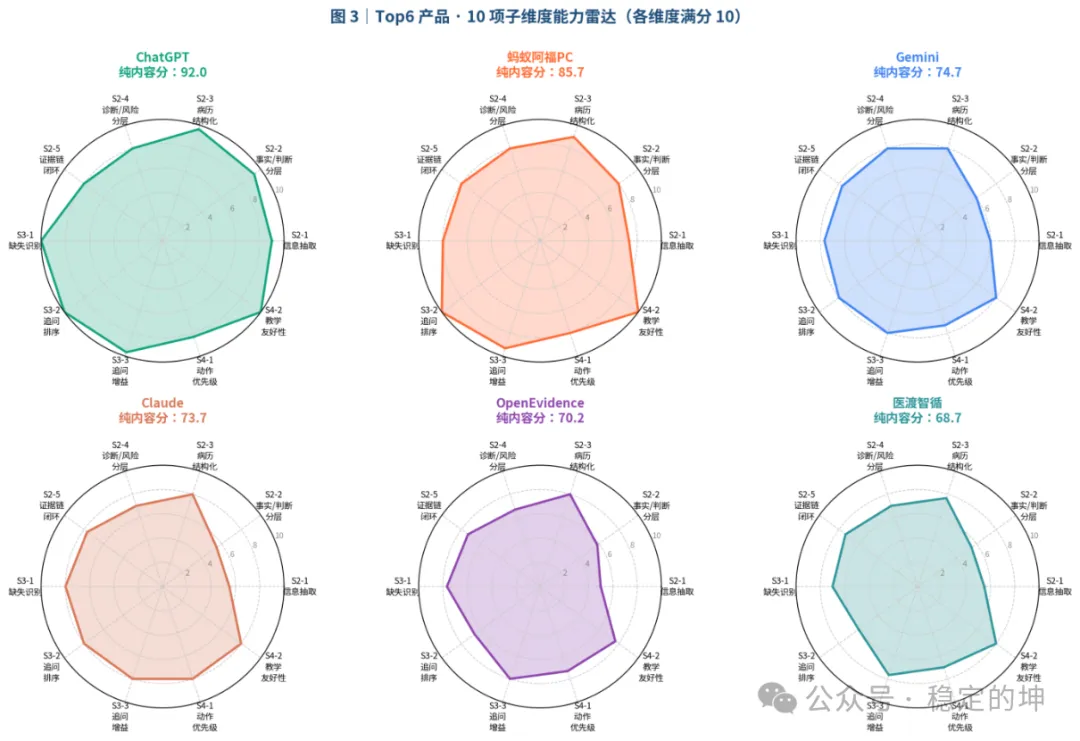
6款垂直产品10项子维度能力雷达(各维度满分 10)
1. 蚂蚁阿福:当前垂直医疗产品中,最接近首诊临床辅助落地的选择
蚂蚁阿福本次测评表现十分亮眼:综合均分85.7,六轮测试整体表现稳定,且Step1A 临床安全红线零违规触发。
这份成绩不只是垂直赛道内部排名领先,更关键是同时达成了医疗场景三大核心要求:安全、稳定、可落地。它不仅能够完整梳理病史信息、抓取关键疑点、给出清晰的下一步诊疗建议,多轮重复测评下的输出波动也极小,一致性表现突出。
即便优势显著,产品仍存在短板:6 轮测评中,有 3 次触发 Step1B 高风险推理越界标记。因此我们对它的客观判断是:已大幅领跑同类垂直医疗产品,但想要进一步拉开差距、完全适配严谨临床场景,核心突破点不在于完善功能,而在于强化不确定信息下的克制性。即便是目前综合表现最优的垂直产品,依旧未能做到:在临床信息不足、证据不充分时,主动停止过度推演。
2. 医渡智循:专业上限可观,但场景稳定性严重不足
医渡智循本次综合均分58.7,但版本分化极其明显:A 提示词版本可达71.3,C 提示词版本仅46.0。
数据足以说明:它并非缺乏临床专业能力,而是输出质量高度依赖提问方式与场景包装。依托自身扎实的医疗知识库、数据沉淀与临床理解能力,在适配的任务逻辑下,它能呈现出色的专业度,具备合格的首诊辅助思维。
但 4 月实测数据印证了核心短板:优质能力无法固化为稳定常态。一旦提问逻辑、表述形式发生变化,信息筛选边界、病情主线判断就会出现明显偏差。这类产品的潜在风险极具迷惑性:不会频繁出现低级错误,却容易让临床使用者误判其稳定性。本质问题不在于医学认知不足,而是无法在各类真实、复杂的首诊场景中,长期守住统一的诊疗安全边界。
3. OpenEvidence:核心能力在线,但极度依赖提示词结构
OpenEvidence 是六款垂直产品中特征最鲜明的一款。整体均分48.7看似平平无奇,但拆分版本数据差异悬殊:A 版仅24.0,C 版高达73.3。
这足以证明其能力短板并非技术薄弱,而是对提示词、指令结构高度敏感。在适配的指令逻辑下,它能快速输出高水准、高专业性的临床内容;可一旦脱离适配框架,就极易出现擅自补全未知信息、混淆客观事实与主观判断等越界问题。
回归临床实用视角,这类 “上限极高、下限不稳” 的产品隐患突出。医疗诊疗容不得波动与侥幸,从不为极致上限买单,只要求稳定可靠的底线。综合来看,OpenEvidence技术潜力充足,但仍需完成深度产品化优化与临床场景约束,现阶段更偏向实验性工具,尚未建成适配临床的稳定运行体系。
4. 百小应:结构化呈现完善,但底层事实逻辑根基薄弱
百小应的问题极具行业代表性,也是多数中端 AI 医疗产品的通病。直观来看,它的输出逻辑完整、格式规范,病历结构化梳理能力成熟,整体观感专业,很容易让人产生 “可用” 的第一印象。
深入拆解内容就能发现,核心短板十分突出:原始信息抽取不准确,事实分层逻辑薄弱。虽然可以搭建完整的诊疗文书框架,但会悄悄补全题干未明确提及的病史、体征、诱因等未知信息。
在临床场景中,这类隐蔽性错误的危害远大于直白的低级失误。临床医生不易察觉细节篡改,往往会被看似合理、逻辑自洽的内容带偏诊疗思路。百小应的现状,折射出行业普遍痛点:表层形式迭代过快,底层事实校验、边界约束等核心能力跟不上。
5. 全诊通:具备首诊识别意识,却习惯性越界前置判断
本次胸闷首诊测评,高度契合全诊通的产品定位,但最终表现远不达临床预期。产品并非完全没有诊疗思维,部分输出中可以清晰看到,它能够识别高危病情线索,也具备基础的问诊追问意识,并非机械化模板生成。
其致命问题在于推理逻辑本末倒置:尚未完成关键信息问诊与核实,就提前预设结论、补全未知病情信息。整套分析流程看似闭环完整,实则全部建立在模型主观脑补的虚假事实之上。
同时,跨版本波动问题突出:A 版均分42.7,C 版骤降至22.7。这说明缺陷并非单点问题,而是全场景的稳定性、边界管控能力全面缺失,距离临床辅助标准差距显著。
6. 京东知医:综合垫底,基础信息可靠性存在硬伤
京东知医本次测评数据直白且刺眼:综合均分仅9.7,6 轮测试中有 5 次触发 Step1A 临床安全红线。
如果说其他产品尚且存在能力上限、优化空间的讨论价值,京东知医的问题已经下沉至最基础层面:无法客观尊重、还原题干原始病史信息。首诊辅助的核心前提,是精准记录、客观呈现患者基础病情,连原始信息都无法准确复刻,后续所有诊疗分析、风险判断都无从谈起。
对于青年医师、基层医护这类核心使用人群而言,这款产品的隐性风险极大:输出格式完整、话术通俗,看似能够辅助工作,却会在病史采集这一源头环节出现偏差,从根本上误导临床判断。这不是单项功能落后,而是作为医疗辅助工具,最基础的信息记录与事实保真能力尚未建立。
写在最后:

如果说3月我们更像是在发问:
为什么AI医疗产品越来越像医生,却仍然很难真正进入临床?
那4月这轮测评,至少让我更清楚了一件事:
垂直医疗产品真正的分水岭,不是知识量,不是格式感,不是会不会引用医学语言,而是它能不能在不确定条件下尊重事实边界。
蚂蚁阿福之所以领先,不只是因为它分高,而是因为它开始展现出一种更接近临床助手的能力:知道哪里可以整理,哪里只能判断,哪里必须留白。
而多数产品的问题,也不是完全不会,而是太急着把场景补完整、太急着证明自己懂医疗。
可真实临床从来不是这样运转的。
医疗场景不奖励过度自信,它奖励的是克制、留白和对事实的敬畏。
AI医生助手最重要的能力,不是把病历写漂亮,而是在证据不足时,仍然能停下来,把判断权留给医生。
图片、信息来源:稳定的坤
添加医微客小编微信(微信号:ewkey1),享受研究方案、数据报告、SCI文章免费评估服务。




