 夜雨聆风
夜雨聆风





辍学进 OpenAI,不是 ChatGPT 的功劳
2025 年 9 月 30 日,OpenAI 发布 Sora 2,致谢页 Research 段落署名了一位 22 岁的瑞典籍辍学者 Gabriel Petersson。半年之后,这个人公开主张「最好的学习方法是自上而下,大学课程效率不高」,被中英文 AI 圈反复传播。这场传播真正值得追问的,并不在于这个人本身有多厉害,而在于它折射出 AI 普及之后学习这件事的稀缺性正在转移——知识开始过剩,「把知识变成价值的能力」开始稀缺。这篇文章想处理的,是这一转移落到教育者和学生头上时,各自要做出哪些具体动作的改变。

晨光仍在,讲台正在被重写。© UThan Zaw / Unsplash
过剩与稀缺
教育的所有形态——讲堂、教科书、考试、文凭——都建立在一个未明说的前提之上:知识是稀缺的。
要学线性代数,得有人来教;要懂神经网络反向传播,得查论文;要明白一段代码为什么报错,得问 Stack Overflow 然后等三个小时。整个教育产业的供给逻辑,就是用「老师 + 教材 + 考试 + 证书」把稀缺的知识打包卖给学生,再用文凭给完成购买的学生发一张「我学过了」的证明。
ChatGPT 之后,这个前提的第一层在塌方。
不是所有的知识都已经被 AI 完整覆盖——前沿研究、私域经验、隐性知识仍然稀缺。但作为教育系统主战场的「本科教科书级别的基础知识」,已经事实上对任何有手机的人开放。一个偏远县城的高三学生现在可以问 ChatGPT 详细解释傅里叶变换,跟一个剑桥本科生问导师的回答在第一次解释这个层面没有显著差距。

书还在原处,问题已经走远。© Jean Vella / Unsplash
用 Petersson 在 Extraordinary 播客里的原话讲:大学不再垄断基础知识——任何人现在都可以从 ChatGPT 那里拿到这些基础知识。
这句话说得轻飘飘,但它戳中的是一个有 800 年历史的体系的最底层假设。中世纪大学之所以建立,是因为羊皮纸卷昂贵、抄写员稀少、有学问的人聚集在少数城市。现代大学的合法性,相当一部分仍然继承自这个稀缺性逻辑。当稀缺性消失,合法性就需要被重新论证。
但稀缺性不是消失了,它转移了。
把任何一个 22 岁、刚毕业、用 ChatGPT 学完了一遍机器学习教材的本科生,跟 22 岁的 Petersson 放在一起对比,结果不是「知识水平的差距」——前者可能背得更熟、考试分数更高。真正的差距是另一种东西:把知识变成可被市场识别的价值的能力。这种能力没有名字,没有教科书,没有学位认证,但它现在是 AI 时代教育系统里最稀缺的东西。
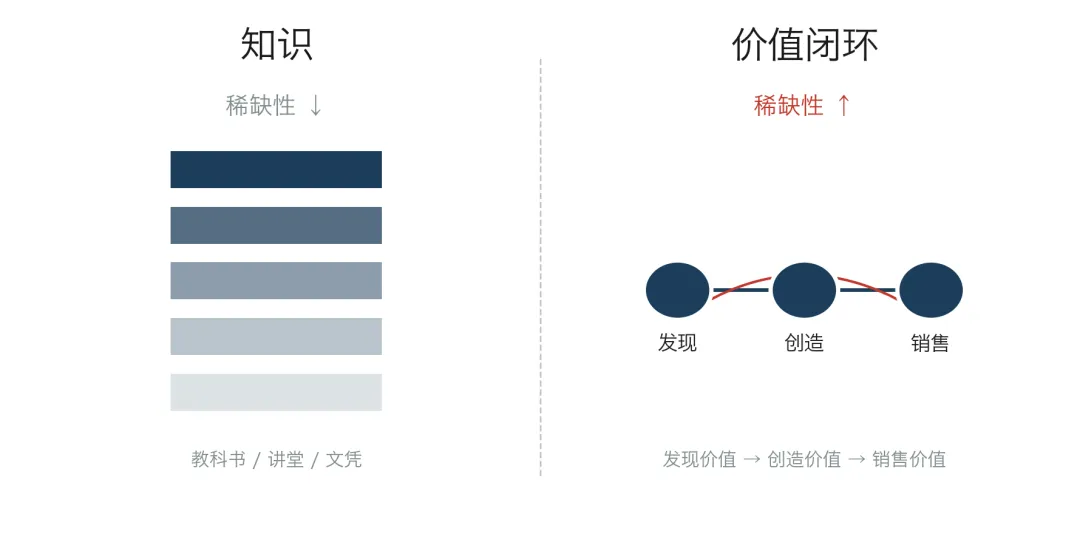
图 01 稀缺性的转移:从「掌握知识」到「价值闭环」
把这种能力拆开看,是三段:发现价值、创造价值、销售价值。Petersson 的全部职业生涯——从 14 岁倒卖宝可梦卡到 22 岁做 Sora 2 cameo 病毒视频——其实是同一个三段式循环的反复执行。
三段式价值闭环
把 Petersson 公开档案里 14 到 22 岁的项目按时间顺序排出来,会看到一个非常一致的动作模板:
14 岁,研究宝可梦卡的 PSA 评级和稀缺性体系,倒卖赚 2 万美元以上。少年期,运营商业化的 Minecraft 服务器,组建 Clash of Clans 战队,YouTube Minecraft 延时摄影做到百万级播放。2020 年疫情第一周,做瑞典本地洗手液比价站,第一周营收 22,000 美元,触达 5% 瑞典人口。2021–2023,做开源 Web 表格 fast-grid,至今 GitHub 2.3k stars。2024,被 OpenAI 拒一次后,连续一周每天 16 小时为 Midjourney 定制网站作为「证明已经在做你想做的事」的演示,重新打动 OpenAI。2025-09,Sora 2 发布日制作病毒 cameo 视频,让作品自己替自己说话。
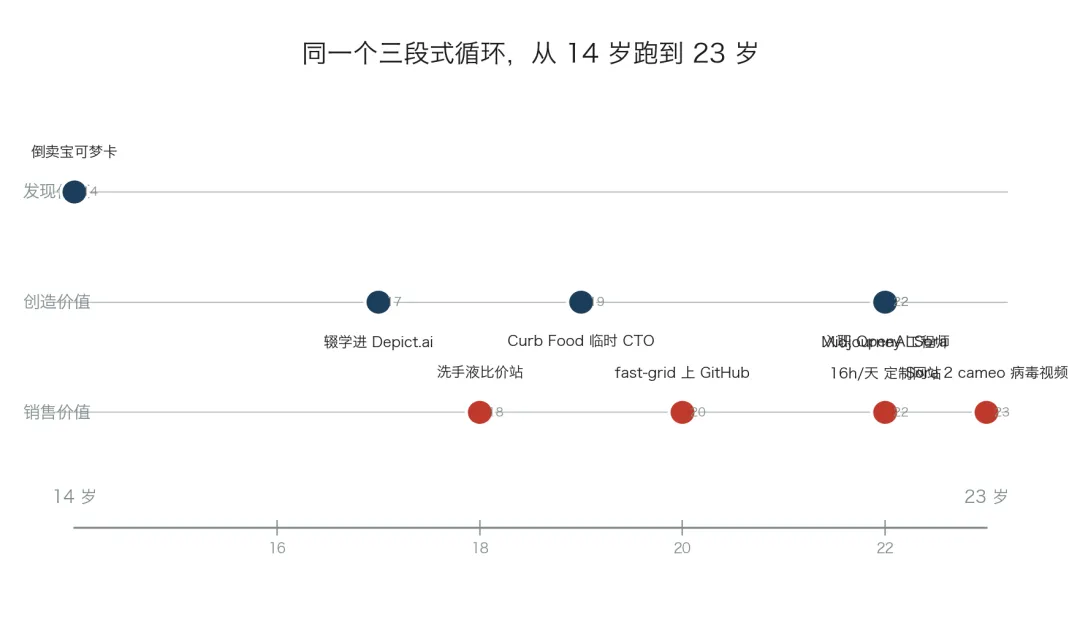
图 02 九件作品,同一个三段式循环——从 14 岁跑到 23 岁
九件事,每一件都包含三个相同动作。
第一段:发现价值。 他先看到一个别人没注意到、或注意到但不愿做的市场缺口。宝可梦卡的稀缺定价没被本地玩家正确理解;瑞典疫情第一周没有人做洗手液比价;Web 上没有真正性能足够好的表格组件;Midjourney 网站存在他能改进的具体问题。这一段动作跟「我聪明所以我看到」基本无关,靠的是长时间盯着某一个具体场景、看见里面低效之处的眼光——这种眼光跟智商关系不大,跟「在场」关系很大。
第二段:创造价值。 他用最快的速度把发现变成可以跑、可以看、可以用的作品。注意「最快」这个词——优先级是抢「能让人看到」这个状态,不是抢完美。fast-grid 走的是先写出来跑给人看、再因为别人开始用而被推着继续打磨这种顺序。Petersson 做事的特征是短周期闭环:一周、两周、一个月,必须有一个能拿出去给别人看的东西。

发现、创造、销售——先从手开始。© Mariana B. / Unsplash
第三段:销售价值。 这是最被中文传播忽略的一段。他做出东西之后从来没有「等被发现」这种姿态,他主动构造让作品被看到的场景。fast-grid 上 GitHub、洗手液站买好友账号扩流量、Midjourney 网站做成定制演示视频递给 HR 之外的人、Sora 2 cameo 视频在发布日大规模传播——这一段动作的核心是绕过中介,让作品和决策者直接相见。
把这三段连起来读,会发现一件事:这套循环跟 AI 没有任何关系。它是 Petersson 14 岁就已经在跑的循环。AI 在他身上的作用,是把第二段(创造价值)的执行速度,从「一周做一个能跑的东西」加速到「三天做一个 SOTA 模型」。AI 没有给他这套方法,AI 给他的是这套方法的执行倍率。
这是一个很容易被忽略的因果关系。中文圈在传播他的故事时,普遍把「AI」放在因果链的起点——「他靠 AI 自学成才」「ChatGPT 让他绕过了大学」。但实际的因果链是反过来的:他先有了这套三段式循环,再用 AI 加速循环里的执行环节。
如果你只学会了用 AI,没有学会三段式循环,结局不是 Petersson,是「用 AI 写了一万行没人看的代码」。
这是教育系统应该真正担心的事情。
费曼方法之困
回到最近被广泛讨论的那个具体方法——「自上而下学习」。它在 Petersson 身上是有效的,但它有效所依赖的隐藏前提,需要被拆开看。
他在 X 上推过一条「如何进入 AI」的四步法:先在语言模型和图像模型里二选一;用 ChatGPT 从零搭一个;遇到任何凭直觉理解不了的东西,就递归地向 ChatGPT 追问;把理解过的东西讲回去,找出自己理解上的缺口。
最后一条——「讲回去找出理解的缺口」——就是费曼学习法第三步的精确翻译。
整套方法在结构上等于「费曼方法 + 项目作为入口 + ChatGPT 作为陪练」。听起来很完美。但费曼方法之所以有效,依赖三个外部约束。当听众从「12 岁的孩子」换成 ChatGPT,三个约束都在松动。
第一个约束:不顺从的检验者。
费曼方法的核心引擎是「输出暴露」——你以为你懂了,但讲出来的时候才知道你没懂。这个引擎能跑起来,是因为对面那个 12 岁的孩子会一直问「为什么」直到你答不出来。
ChatGPT 不会。它的对话设计是高度顺从的,它会用更平滑的语言把你的错误表述重新组织一遍,会在你坚持错误观点时倾向于妥协。这种设计在客户服务里是优势,在教育场景里是一种系统性的反约束。
第二个约束:知识的冗余度。
费曼方法的回填路径是教科书、原始文献、找一个真懂的老师。这些来源跟 ChatGPT 的差异不在便利性,在冗余度。
教科书是被多代研究者审视、同行评议、时间筛选过的知识压缩包。它包含「为什么这个概念是这样定义的」「曾经有过哪些错误尝试」「在什么条件下结论会失效」等等冗余信息——你第一次学时用不上,但未来遇到边界条件时会救你。
ChatGPT 给出的解释是基于训练数据的统计平均,倾向于给最常见的解释,不会主动告诉你「这个结论在 X 条件下失效」,除非你主动问。但「你不知道你需要问 X」恰恰是初学者的常态。
第三个约束:先验知识的隐藏门槛。
教育心理学里有一篇被引用一万多次的论文:Kirschner、Sweller、Clark 2006 年发表在 Educational Psychologist 上的 Why Minimal Guidance During Instruction Does Not Work。基于认知负荷理论,他们的论断是:最小化引导的教学方法(包括建构主义、发现学习、PBL、探究式学习)在过去半个世纪的实证研究中反复败给直接教学法——除非学习者已经具备较高的先验知识,可以为自己提供「内部引导」。
把这一限定套到 Petersson 身上:他在使用「自上而下用 AI 学」之前,已经积累了五年密集的工程实践——前端工程、推荐系统、Canvas 渲染、超参数调参。他不是从零开始用 AI 学 AI,他是在已有先验知识的基础上用 AI 补完最后一公里。
他自己其实承认了这一点。在 Extraordinary 播客里他坦白:他早年试过去上吴恩达的那门经典机器学习课,完全听不懂,当时觉得自己就是太笨。他后来用 ChatGPT 把同样的内容重学了一遍——能让他重学成功的真正变量,与其说是 ChatGPT 这个工具,更像是他在两次尝试之间已经积累的多年工程实践。
把这三个松动的约束放在一起看,会得到一个对教育者非常重要的判断:「用 AI 学 AI」在 Petersson 身上之所以有效,更多要归因于他已经凑齐了让这套方法生效的三个隐藏条件——而非这套方法本身具有普遍适用性。把这套方法照搬给一个普通本科生,结局可能是一个把基础数学跳过了、再也补不回来的半成品工程师。
MIT Kosmyna 等人 2025 年的一项 fMRI 研究给了第一批实证警告——用 GenAI 辅助写作的学生,大脑活动减少、写作同质化加剧、对自己写出的内容的回忆能力下降。研究者用了一个有点刺耳的措辞:「学到了的感觉,不等于真的学到」。
这个发现对所有想模仿 Petersson 路径的人是一个冷静剂。学习的体验感和学习的实质效果之间,可能正在出现一道新的、由 AI 工具制造出来的断裂。
教师与学生的新动作
把以上拼起来,一个对教育者和学生都成立的命题浮出水面:AI 时代的教育,不是 AI 取代大学,是大学的角色被重新分配。
被分配走的,是「知识传递」这一段——AI 可以做,做得比绝大多数授课老师更耐心、更可访问、更不嫌学生蠢。被留下的,是 AI 在当前架构下还无法承担的那些角色。
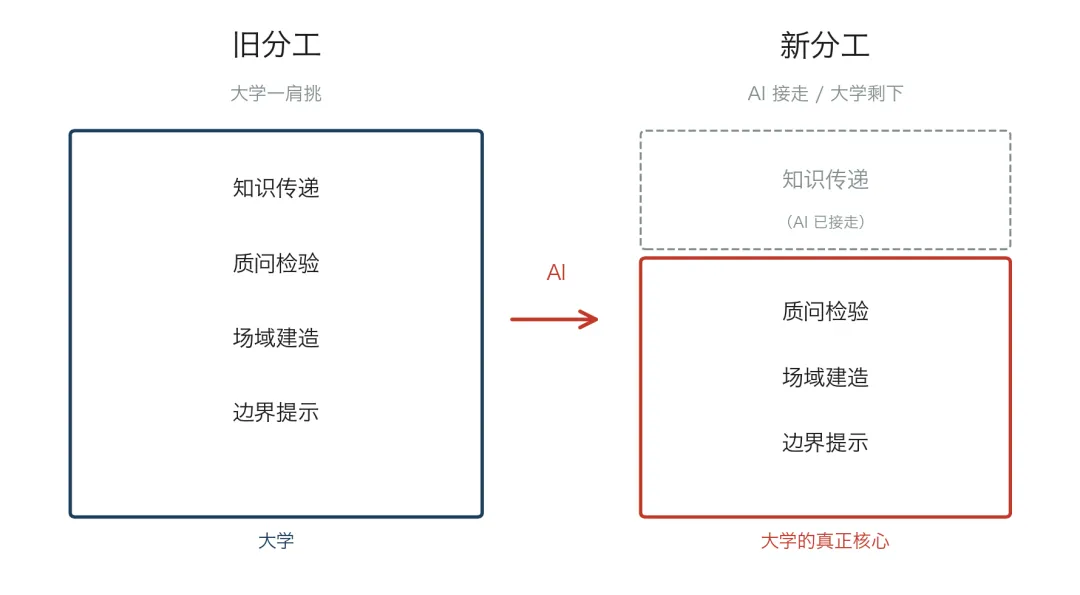
图 03 大学的角色,正在被悄悄重新分配
对教育者来说,留下的角色至少有三个。
第一个:质问者。 这是 AI 现阶段最不擅长的角色。一个真正的老师能听出一个学生哪里讲得含糊、哪里在用术语掩盖理解空洞、哪里在用 ChatGPT 的口吻而不是自己的口吻说话。这种「不顺从」的能力是教育产生的源头,过去它分散在助教、答辩组、师徒关系里,现在它需要被有意识地集中和强化。Andrej Karpathy 2024 年创办 Eureka Labs 走的就是这条路——他想做的产品形态不再是一个会回答问题的 AI 助手,而是一个像 Feynman 一样会让学生卡住的 AI 老师。这个尝试是否会成功还是未知,但它指向的方向是对的。
第二个:场域建造者。 价值闭环的「销售价值」一段,需要场域才能发生。一个学生写出 fast-grid 级别的开源项目,需要 GitHub 这个场域;做出一个跑得起来的小产品,需要一个能让作品被同学、被招聘官、被同业看到的场域。大学最值得保留的资产之一,是它天然能构造高密度同侪场域的能力——这是 ChatGPT 无法复制的。但今天大多数大学的同侪场域是结构性闭环(绩点、保研、考公),而不是作品场域。把后者建起来,是教育者可做的具体动作。
第三个:边界条件提示者。 ChatGPT 倾向于给最常见解释,不主动提示边界条件。教师的真正价值开始集中在「这个结论在什么条件下会失效」「这个方法在什么人身上不成立」「这个工具在什么场景里反而是反约束」这一类的边界提示上。本文从头到尾在做的事情,其实就是这一类提示——把 Petersson 方法生效的隐藏前提拆开来给读者看。一个在 AI 时代仍然有用的教师,更接近于一个长期沉浸在某个领域、能稳定提供边界条件提示的人。

教室散开成一张桌子,老师站到一边。© FORTYTWO / Unsplash
对学生来说,留下的动作也至少有三个。
第一个:找一个真问题。 价值闭环的第一段。真问题不长在教科书的习题里,长在某个具体场景的具体低效里。它不需要宏大,需要具体——具体到你能描述「现在它怎么不爽」「如果做出来了怎么会更好」「谁会愿意用」。Petersson 的洗手液比价站、fast-grid 表格、Midjourney 定制网站,全部都是这种具体的真问题。普通本科生能找的真问题可能是「我们学院的选课系统每年都崩」「我们专业的实验数据没有可视化工具」「这个学科的某个文献没有靠谱的中文综述」——比这更小的也行。关键是要从「我应该做什么」转向「我看到什么是不合理的」。
第二个:用最快的速度做出一个能跑的东西。 价值闭环的第二段。AI 在这一段的真正用法是把执行成本降到一周以内——它替你加速执行,但不替你思考。一周做一个能跑的小东西,比四年做一个完美的毕业设计有意义得多。这一段对学生的考验更多落在完成度的容忍度上——能不能接受第一版很丑、有 bug、不完整。Petersson 14 岁倒卖宝可梦卡的时候没有先做完美的市场分析,他是直接开干。
第三个:让作品在公开场合被看到。 价值闭环的第三段,也是中国学生最不熟悉的一段。它不是「自我营销」「炒作」这类带贬义的词能盖掉的事——它是一种对作品负责的延伸。你做了一个东西,它能解决问题,那让它被需要它的人看到,本身就是工作的一部分。GitHub 开源、技术博客、X 推文、B 站视频、小红书笔记——这些在过去十年里被中国学生默认为「不务正业」的渠道,其实是 AI 时代价值闭环的关键基础设施。一个不会让作品被看到的好作品,在 2026 年已经等于不存在。
这三个学生动作合在一起,看起来不像「学习」,更像「创业」。这不是巧合。当知识不再稀缺,「学习」和「创造」之间的边界开始模糊——你最有效的学习方式,是去做一个真东西,然后在做的过程中按需补完所有缺的知识。这一点 Petersson 跑通了,Jeremy Howard 在 fast.ai 上跑通了,Andrej Karpathy 在 nanoGPT 教程上跑通了。三个人的方法各有差别,但底层动作是一致的——把学习装进一个真实任务里。
但学生最需要警惕的也在这里。「装进真实任务」不等于「跳过基础」。这是 Petersson 故事被普遍误读的地方。三段式价值闭环的引擎是「真问题驱动」,但驱动力推动你前进时,你必须沿途真的去补那些被卡住的基础知识,而不是用 ChatGPT 的解释替你假装补过。
学习的形式变了,对学习实质的要求没有变。换了工具,没换 effort。
落到实践
最低成本、也最被忽略的一个动作是让作品先能被看见。MIT Media Lab 著名的「Glass Walls」文化里,所有实验室都是玻璃墙,外面随时能看见里面在做什么。它的真正杠杆不在透明度,在于让做事的人意识到自己在被看见——这种被看见本身就是 driver。一面长期滚动的展示墙,效果可能超过任何一次创新创业大赛。
紧跟在物理场域之后的,是定期的、不打分的 Demo Day。规则只有两条:任何在做项目的人都可以报名展示;不评奖、不打分、不排名。强调”不打分”是因为一旦打分,场域立即退化成另一套绩点体系——作品场域和评分场域必须分开。前者产生连接和反馈,后者产生焦虑和投机。把它们混在一起,前者必然吞噬后者。
还有一个被严重浪费的场域是毕业季。毕业仪式,可以改造成作品季。每个本科毕业生展出至少一件公开作品,不一定是毕业设计,可以是任何在校期间做出的、能拿出去给非本专业的人看的东西。这件事的真正杠杆不在毕业那一周,在低年级学生看到学长学姐都在展示作品的那一刻——它会重新校准低年级学生对”在大学里要干什么”的预期。文化就是这样传下去的。
建造作品场域,不需要新预算、不需要改培养方案、不需要顶层设计。需要的是把已经存在的物理空间、时间节点、评价权力、校友资源、毕业仪式,从”管理学生”的逻辑切换到”展示作品”的逻辑。
一个症状,不是答案
最后回到 Petersson 这个具体的人。
他是这场变革的一个症状,不是答案。22 岁、瑞典、辍学、OpenAI——他个人的成功跟方法论的普适性之间有相当远的距离。但他的故事被广泛讨论这件事本身,反映了一个事实——AI 时代的教育该怎么走,没有一个被普遍接受的方案,所以任何一个看起来跑通了的个人样本都会被无限放大。
Sora app 在 2026 年 4 月 26 日关停,他所在的团队进入解散流程。他个人的下一步在哪里,截至 4 月底没有公开信息。但他的下一步在哪里,并不影响这场变革会继续发生。

问题已经摆好,答案还没到。© Andrea De Santis / Unsplash
变革的真问题,落在另外两个问题上:
当 AI 接走了教科书级别的知识传递,教育者还能为学生提供什么?
当价值闭环的执行速度被 AI 加速十倍,学生应该把多出来的时间花在什么上?
第一个问题的答案,可能藏在「质问、场域、边界提示」这三个动作里——它们是大学过去八百年里在做的事情,只是过去和「知识传递」绑在一起,没有被单独看清楚。AI 替大学做了一次切割手术,把可外包的部分外包出去,剩下的恰好是大学最难复制、最值钱的核心。
第二个问题的答案,可能藏在「发现价值、创造价值、销售价值」这三段动作里——它们过去被默认是创业者的事,跟学生没关系。AI 把执行成本降低之后,这三段动作开始变成每一个学生都可以、也应该练习的基本功。这种练习不以创业为目的;它的目的是在一个知识过剩、价值闭环稀缺的世界里,建立一种可被市场识别的能力。
信息来源
Sigil Wen 主持的 Extraordinary 播客对 Gabriel Petersson 的访谈(2025-11)
David Perkins, Making Learning Whole: How Seven Principles of Teaching Can Transform Education (2010)
Kirschner, Sweller & Clark, “Why Minimal Guidance During Instruction Does Not Work”, Educational Psychologist 41(2): 75–86 (2006)
Kosmyna et al., MIT Media Lab 关于 AI 辅助写作的 fMRI 研究 (2025)
Jeremy Howard / fast.ai 课程 Practical Deep Learning for Coders
Andrej Karpathy 关于 “shortification of learning” 的推文与 Eureka Labs 公开愿景