 夜雨聆风
夜雨聆风





AI+Stata3.0 红宝书–从重复提示到可复用Skill
AI+Stata3.0红宝书–从重复提示到可复用Skill
开篇案例
想象一下:你每天都要完成文献综述,每次都要写类似的提示:
“帮我写一段关于DID方法最新进展的文献综述,要求包括平行趋势检验、事件研究设计、以及多种稳健估计量的实现。请引用至少5篇最新的顶级期刊论文,注意比较不同方法的优缺点。”
而使用Skill,你只需要说:
“帮我完成一段DID方法最新进展的文献综述。”
AI会自动匹配到你创建的文献综述Skill,直接按照你常用的格式和标准执行。
1 什么是Skill以及为什么需要它们
1.1 Skill的定义
传统Skill定义:在Claude Code中,Skill是一组打包好的代码和配置,告诉AI如何处理特定类型的任务。
更高级的理解:Skill是你个人研究流程的自动化封装,可以让AI代理像你一样思考和行动。
1.2 为什么需要Skill
效率提升:
-
减少重复输入:避免每次都写类似的提示 -
提高一致性:确保每次执行的质量相同 -
节省时间:从每次都需要解释变成一次配置,多次使用
质量保障:
-
标准化流程:确保按照最佳实践执行 -
经验积累:将成功的经验固化为Skill -
可复用性:Skill可以在项目之间分享和复用
错误减少:
-
避免遗忘:所有必要的步骤都已包含在Skill中 -
减少人为错误:AI按照预定义的步骤执行 -
系统化方法:每个步骤都有验证和检查
2 Skill的三类分类和结构
根据Anthropic发布的Claude中文文档,发现常见技能类别,可以分为三类
类别1:文档与资产创建
类别2:工作流自动化
类别3:MCP增强
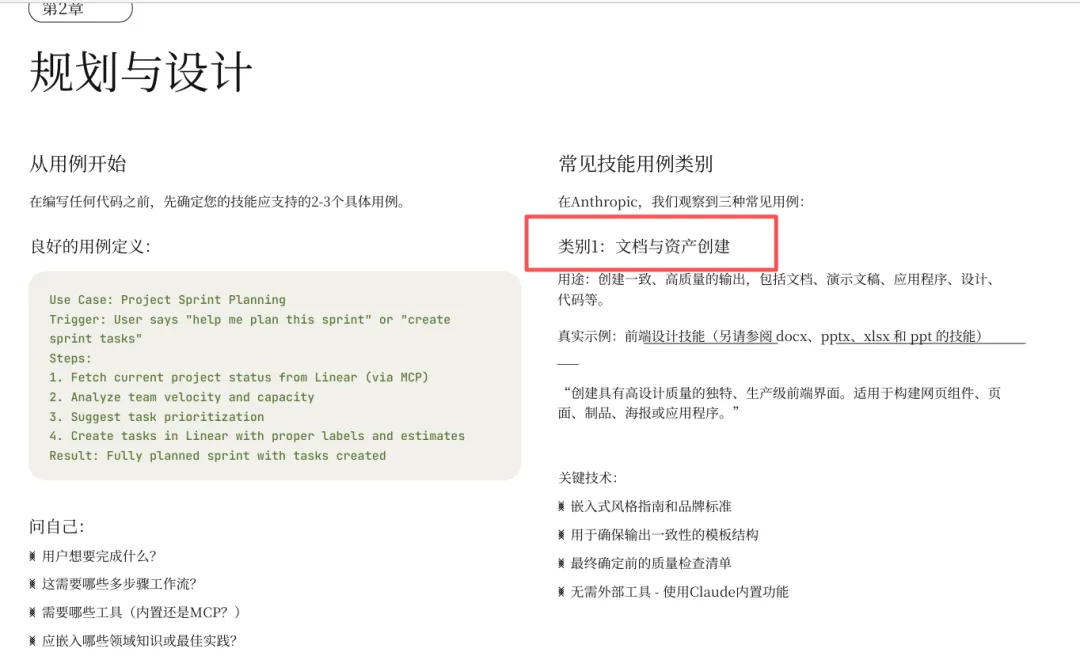

来源:Claude技能构建完全指南
下面将对逐一对其进行介绍
2.1 文档资产型Skill
文档资产型Skill:产生文档或报告的Skill,通常需要用户提供背景信息和结构要求。
---name:literature-reviewdescription:帮我写一段文献综述,要求引用至少5篇顶级期刊论文,比较不同方法的优缺点。适用于DID分析、文献综述等场景。# 文献综述生成Skill## 执行步骤### 第一步:确定主题1.确定文献综述的主题和范围2.识别关键变量和概念3.确定需要引用的文献类型### 第二步:查找文献1.使用学术搜索引擎查找相关文献2.识别核心论文和综述性文章3.检查文献的相关性和质量### 第三步:阅读和理解1.快速阅读摘要和引言部分2.识别研究方法和主要发现3.理解文献之间的联系### 第四步:组织和写作1.制定文献综述的结构2.写作每个部分的内容3.确保逻辑清晰和内容连贯### 第五步:编辑和验证1.检查语法和拼写错误2.验证引用格式3.确保内容符合要求---2.2 流程自动化型Skill
流程自动化型Skill:需要执行多个步骤的Skill,通常涉及代码生成和执行。
---name:stata-data-cleaningdescription:帮我完成Stata数据清洗任务,包括缺失值处理、变量生成、异常值检测。适用于所有需要数据预处理的场景。# Stata数据清洗流程Skill## 执行步骤### 第一步:数据导入1.读取数据文件2.检查数据完整性3.验证数据格式### 第二步:变量检查1.检查每个变量的基本统计量2.验证变量编码3.识别数据类型### 第三步:缺失值处理1.统计缺失值的分布2.确定缺失值处理方法3.执行缺失值处理### 第四步:异常值检测1.使用统计方法识别异常值2.检查异常值的合理性3.决定异常值的处理方法### 第五步:变量生成1.根据研究需要生成新变量2.验证变量生成的正确性3.优化变量命名### 第六步:输出保存1.保存清洗后的数据2.生成数据清洗报告3.验证结果的正确性---2.3 MCP增强型Skill
**MCP增强型Skill:使用MCP协议的Skill,可以访问本地资源和执行代码。
---name:stata-regressiondescription:帮我完成Stata回归分析任务,包括模型设定、估计执行、结果解读。适用于所有统计分析场景。# Stata回归分析Skill## 执行步骤### 第一步:数据准备1.读取并检查数据2.验证模型假设3.优化数据结构### 第二步:模型设定1.确定模型类型(OLS,DID,IV等)2.设定变量和控制变量3.配置估计选项### 第三步:估计执行1.执行回归分析2.检查估计结果3.验证模型假设### 第四步:结果解读1.解释回归系数的经济含义2.评估统计显著性和经济显著性3.讨论政策含义和局限性### 第五步:报告生成1.生成回归结果表格2.生成图表和可视化3.撰写结果解读部分---3 SKILL.md的结构与核心字段的使用
3.1 核心字段
YAMLFrontmatter字段:
---name:stata-regression# Skill名称,必须唯一description:># 描述,告诉AI什么时候使用这个Skill帮我完成Stata回归分析任务,包括模型设定、估计执行、结果解读。适用于所有统计分析场景。# 执行步骤---其他可选字段:
---name:example-skilldescription:> 这是一个示例Skill的描述,告诉AI什么时候使用这个Skill。category:general# 分类标签tags:["analysis","automation"]# 标签,用于分类version:1.0# 版本号,用于管理author:"Your Name"# 作者信息# 执行步骤---3.2 执行步骤的编写原则
步骤应该是可执行的:
// 好的步骤1. 读取并检查数据2. 验证模型假设3. 优化数据结构// 不好的步骤1. 分析数据2. 执行回归3. 解读结果每个步骤都应该有明确的检查点**:
// 包含检查点的步骤1. 读取并检查数据 - [ ] 数据是否成功读取 - [ ] 变量类型是否正确 - [ ] 数据完整性是否良好2. 验证模型假设 - [ ] 残差是否正态分布 - [ ] 是否存在异方差问题 - [ ] 是否存在多重共线性未完待续!
关于AI × Stata3.0,前文回顾详见AI × Stata3.0 红宝书节选:Stata MCP基础:
Jupyter/VSCode与Stata交互方法3-StataMCP
【ClaudeCode教程-1】文科生小白入门–顶级计量经济学家Sant’Anna的 Claude Code 工作流
