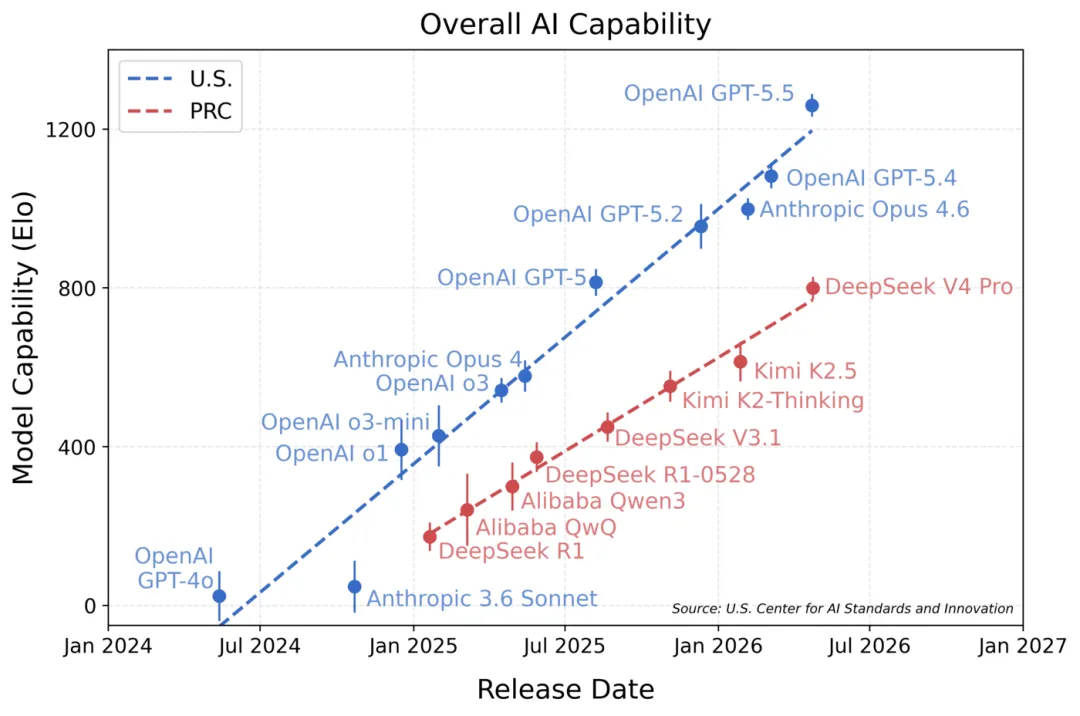
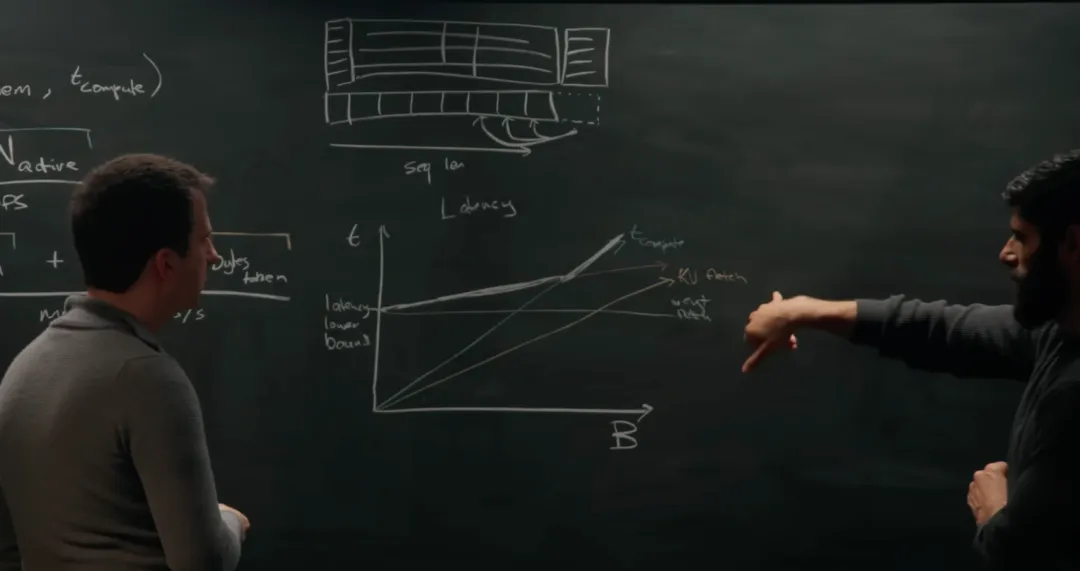
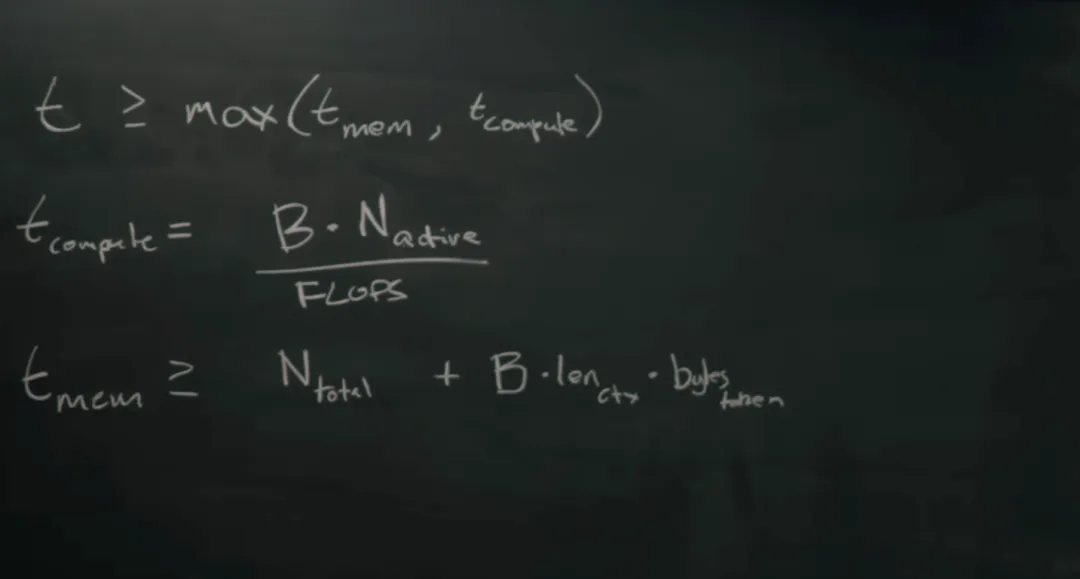数据来源:U.S. Center for AI Standards and Innovation,2026年4月很多人以为,大模型的竞争是一场看谁能买到更多 GPU、砸出更多参数的”军备竞赛”。但前 Google TPU 架构师、MatX CEO Reiner Pope 在黑板前,用几个纯粹的物理方程,把硅谷所有头部 AI 实验室(OpenAI、Anthropic、Google)的底牌全掀开了。结合我在阿里做 AI 基础设施超过十年的经验,今天我想用我的方式,替大家把这本算力账本算清楚:为什么 GPT-5 被过度训练了 100 倍?DeepSeek 又是怎么把硅谷巨头逼到墙角的?中国 AI 团队的突围路径到底在哪里?废话不多说,开聊。
💡 AI 的演进,本质上是一部”如何绕开内存带宽瓶颈”的工程史。Transformer 的每一次架构迭代,都是在和同一堵物理墙做博弈。AGI 的时间线,不只取决于算法突破,也取决于这堵墙什么时候被打穿。
对做 AI 产品的人来说,结论很实际:与其等硬件解决问题,不如现在就设计出在有限上下文内运作良好的记忆架构。这也是我们在 Genomii 构建 TwinState 数字孪生记忆体系时的核心选择:不赌无限上下文,而是用结构化知识图谱和 Agentic Skills,在更小的窗口里实现更高密度的个体化记忆召回。
中国 AI 的突围路径:三层现实判断
硅谷这本账,对中国 AI 产业有三个非常直接的判断。判断一:算力突围的关键不在单卡算力,在互联带宽 H100 和 Blackwell 因出口管制进不来,很多人以为这是 FLOPs 的差距。但 Reiner 的分析说的是另一件事:限制长上下文能力的核心是 HBM 内存带宽,不是算力峰值。华为昇腾集群的 Scale-Up 互联域能做到多大,才是国内大模型长上下文能力的真正天花板。这是一个物理基础设施问题,不是算法问题。判断二:谁能把 Batch 填满,谁就赢了推理端Kimi 长文本、豆包高频场景的爆发,不是因为模型比别人强,而是因为用高频行为把并发 Batch 塞满了。推理 ROI 最极致的,永远是那些用户频率最高、场景最集中的产品。MiniMax、智谱 AI 在垂直场景的表现不输巨头,也是同一个逻辑在发挥作用。判断三:推理端的账算不清楚,就没有下半场国内 AI 创业者必须从第一天起,把 token 成本、KV Cache 内存占用、甚至底层存储介质的 Drain Time,当成产品设计的核心约束条件来对待。不是上线之后的优化项,而是产品定义阶段就要锁死的边界。
写在最后
大模型的上半场,比的是谁能用资本撬动更多算力。大模型的下半场,拼的是谁能看透方程式背后的物理极限,在约束中找到高杠杆的突围路径。Reiner Pope 的黑板上只有几个方程,却推导出了整个行业的竞争格局,乃至 AGI 的时间线。这让我想起在阿里工作时反复被验证的一个判断:真正理解物理约束的人,才能在约束中找到别人看不见的突破口。DeepSeek 的崛起、Kimi 的长文本突破、国内推理芯片的艰难突围——不是偶然,是一批工程师把这些方程搞透之后,做出的必然选择。不在物理规律面前心存侥幸,才是真正的第一性原理。推荐原始内容:Dwarkesh Podcast × Reiner Pope —「The math behind how LLMs are trained and served」
 夜雨聆风
夜雨聆风