姚顺雨重塑混元AI后首份答卷!腾讯混元Hy3 Preview大模型正式发布
4月23号,腾讯正式推出混元系列的最新模型:Hy3 preview。 它被视为混元在技术架构和研发思路上“推倒重来”后的第一份答卷。 此次混元Hy3 Preview的发布时间正好与DeepSeekV4的发布时间撞车,因此很少有人关注到它,但其震撼力一点也不比DeepSeekV4差。 混元Hy3 Preview的发布,不仅仅是腾讯推出了新模型,也不仅仅是姚顺雨入职腾讯后的首份答卷,而是对原有架构的推倒重来。 OpenAI研究科学家到腾讯首席AI科学家 姚顺雨从小就成绩优异,用老一辈的话来说就是:“别人家的孩子”。 16岁就斩获2014年全国青少年信息学奥林匹克竞赛(NOI)银牌,2015年高考,他以704分、安徽省理科第三名的成绩,考入赫赫有名的清华大学“姚班”(清华学堂计算机科学实验班)。 但他的优秀不仅仅只是体现在学习能力上,在清华大学期间,不但担任姚班联席会主席,还联合创办了清华大学学生说唱社。 并且他还开启了以“推理与行动协同”为核心的革命性研究,其ReAct框架与思维树(Tree of Thoughts) 理论至今仍是全球智能体开发的基石。 2019年,姚顺雨远赴普林斯顿大学攻读计算机科学博士学位,专攻自然语言处理与强化学习。他将自己的博士论文答辩全程在B站公开,曾是一段佳话。 博士毕业后,于2024年8月加入OpenAI,任研究科学家。在OpenAI就职期间,他深度参与了智能体产品 Operator 和 Deep Research 的核心研发,是这些代表性产品的核心贡献者之一。 在OpenAI取得一定成绩后,姚顺雨并没有选择继续在硅谷闯荡,而是选择了回国发展。 去年12月,年仅28岁的姚顺雨加盟腾讯,出任“CEO/总裁办公室”首席AI科学家,同时兼任AI Infra部及大语言模型部负责人,向腾讯总裁刘炽平直接汇报。 年仅28岁就能执掌腾讯AI,可想而知他的能力是多么的强大,而上任后,姚顺雨也带着他的理念开始重塑腾讯AI。 对混元AI的彻底重塑 姚顺雨入职后,对腾讯AI从内到外进行了一次彻底的全面重构。不仅是在组织架构和技术路线的“推到重来”,更是要在思想理念上对腾讯AI进行重塑。 在姚顺雨看来,AI的发展已进入“下半场”,核心不再是追求漂亮的“跑分”,而是要解决真实世界中的复杂问题,这一理念促使腾讯放下了对“刷榜”的执念。 过去的混元被困在旧的“公考逻辑”里。团队选择用监督微调(SFT)去迎合公开榜单,虽能能在短期内获得高分,但一遇到真实业务场景,其模型泛化能力差,缺乏实用性的缺点就会被无限放大。 比如腾讯自家的核心业务,甚至对本家的模型都缺乏信心,更倾向于向外寻找解决方案。这种情况如果你是腾讯的老板会不会愿意?一年投入这么多钱,却只搞出了一个花架子,自家的业务都承接不了。 而姚顺雨带来了新的理念,也带来了根本性的改革,确立了实用性的三大原则:
能力体系化:拒绝“偏科”。一个智能体需要会协同推理、长文本处理、指令遵循等多种能力,因此必须在各方面都打牢基础。
评测真实性:跳出易被“刷榜”的公开赛道,通过自建题库、人工评测、产品众测等方式,衡量模型的“真实战斗力”。团队为此构建了“CL-Bench”等自研评测体系。
性价比追求:构建让智能体“用得起、用得好”的理念。在保证能力的同时,将模型参数设计得更加经济,并要持续优化推理成本。
姚顺雨的这次理念上的重塑,可谓是打在了“七寸”上,倡导模型能力的多元化、评测的真实性、性价比的追求,这三条我觉得是集合了国内国外顶尖模型的理念于一身。这也是符合未来AI发展潮流的选择。 腾讯内部长期将AI团队视为配合产品工程的“配角”,组织方式导致研发无法形成有效闭环。 腾讯总裁刘炽平曾复盘,将混元的问题比作“高中生背题应考,真正上了考场就露馅”,每个关键模块都有缺失。 而姚顺雨主导撤销了原有的AI Lab,新设立了AI Infra(基础设施)部、AI Data(数据)部等团队,将AI业务提升至公司级战略高度。 这是一场全链路的重建,从底层基础设施到数据管线、训练流程乃至组织架构,都不再只是修补漏洞,而是“拆了重来”,从头搭建了一个完整的研发闭环。 腾讯以往旧的路线是追求更大的参数规模和单一的模型结构,容易忽视推理成本和实际应用效果。简单来说就是“追求大力出奇迹”。
MoE(混合专家)高效架构:总参数达2950亿(295B),但推理时仅激活约210亿(21B) 参数,激活占比仅7.1%。这意味着能用更低的计算成本,达成更强大的性能,在性价比上极具优势。
“快慢思考”融合:首次将人类“快思考”(System 1,迅速直觉)和“慢思考”(System 2,深度推理)两种机制融入一个模型。Hy3 preview能根据任务难度,自动在速度和质量间取得最优平衡,简单任务秒回,复杂任务则触发多步推理。这一设计也天然适配了姚顺雨提出的ReAct(推理-行动)模式,是打造强大AI智能体的关键。
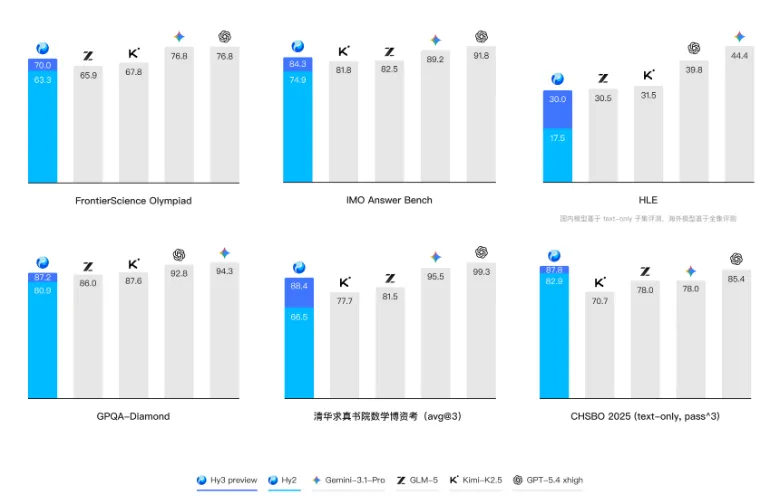
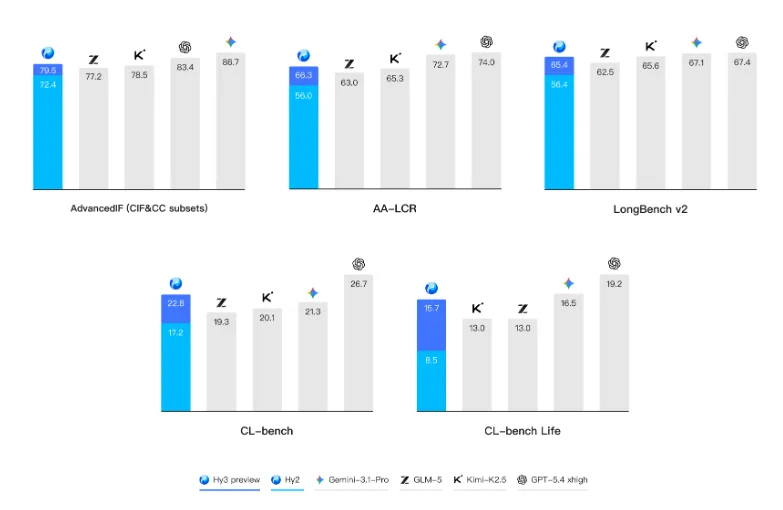
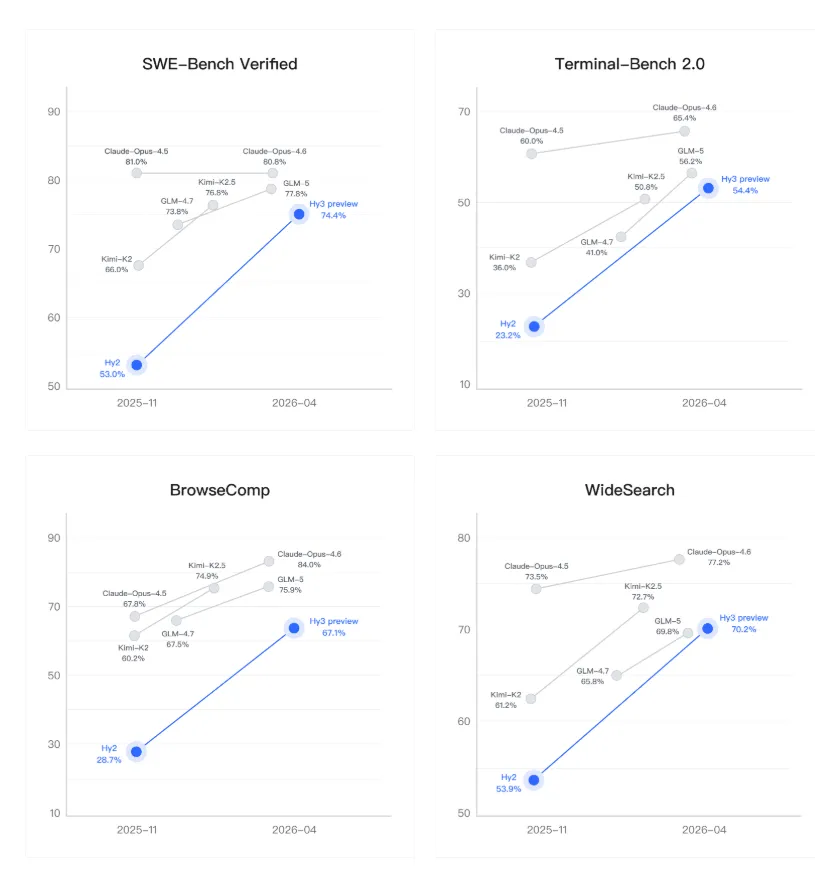
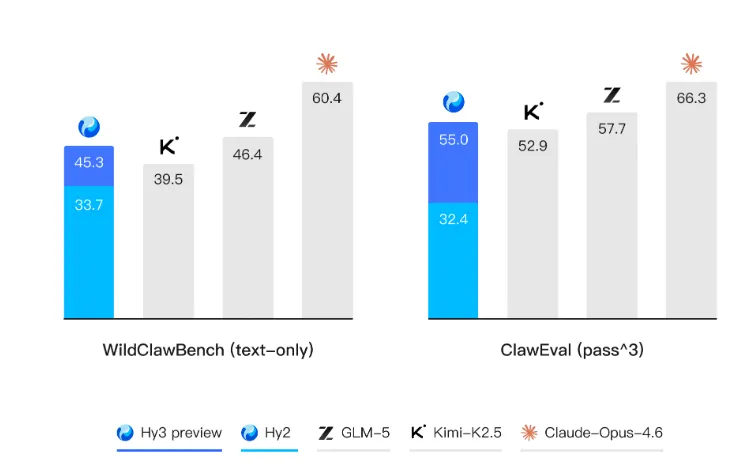
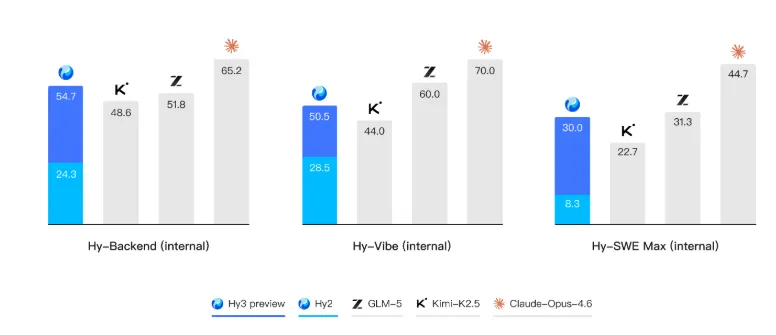
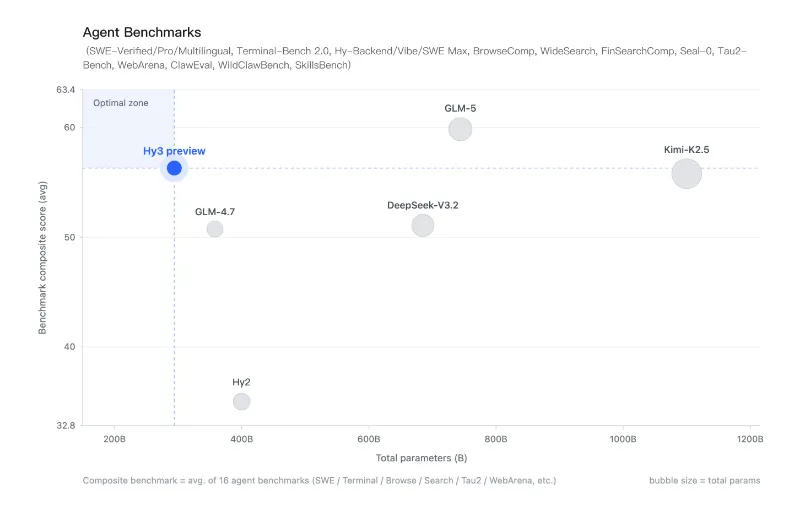
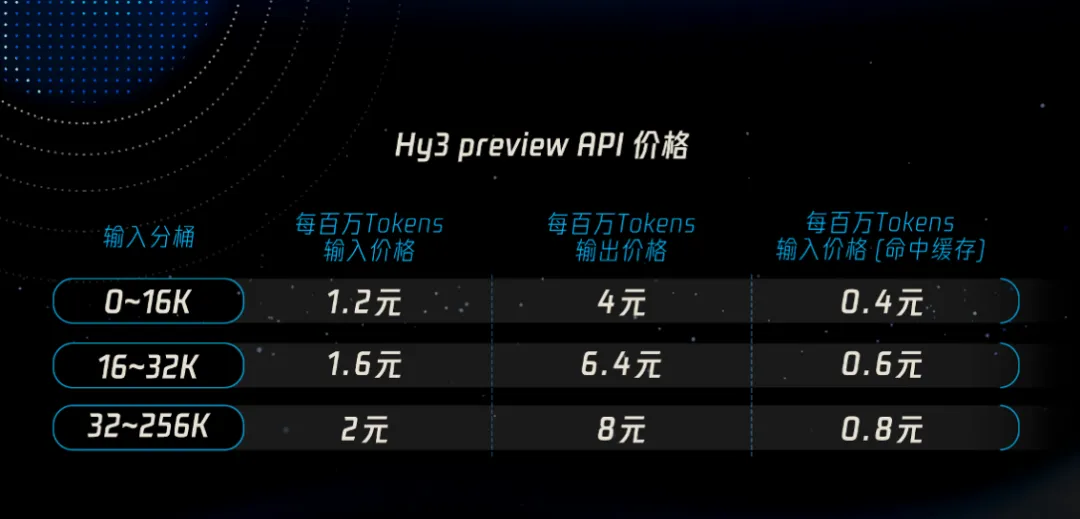
混元Hy3 preview 俗话说的好“光说不练假把式”,前面说了这么多混元的改革,新的模型混元Hy3 preview到底成色几何? 首先腾讯混元 Hy3 preview 语言模型是一款开源模型,是一个快慢思考融合的混合专家模型,总参数 295B,激活参数 21B,最大支持 256K 上下文长度。 它没有刻意追求参数上的“大”和榜单上的绝对领先,而是将核心能力聚焦于复杂推理、代码生成和AI智能体指令遵循、上下文学习等真实、复杂的工程问题上。 Hy3 preview 在 FrontierScience-Olympiad、IMOAnswerBench 等高难度理工科推理任务中表现突出,并在最新的清华大学求真书院数学博资考(26春)和全国中学生生物学联赛(CHSBO 2025)中取得优异成绩,展现出可泛化的强推理能力。 基于腾讯业务场景的灵感,姚顺雨提出了和来创新性地评估模型的上下文学习能力,并在 Hy3 preview 显著地提升了模型上下文学习和指令遵循能力。 代码和智能体是 Hy3 preview 提升最为显著的方向。 得益于预训练及强化学习框架的重建和强化学习任务规模的提升,以较快的速度在 SWE-Bench Verified、Terminal-Bench 2.0 等主流代码智能体基准以及 BrowseComp、WideSearch 等主流搜索智能体基准中取得了强竞争力的结果。 Hy3 preview 在 ClawEval 和 WildClawBench 等评测中表现也非常突出。 除了公开榜单,腾讯进一步构建了多个内部的评测集,对模型在真实开发场景中的表现进行评估。结果表明,无论是在后端工程任务集 Hy-Backend,贴近真实用户开发交互的 Hy-Vibe Bench,还是高难度软件工程开发任务集 Hy-SWE Max 上,Hy3 preview 均体现出了强竞争力。 除了Hy3 preview的能力得到大幅提示外,也展现了高性价比的特点。在没有超大参数的情况下,腾讯混元 Hy3 preview 用“中等身材”,也就是2950亿的总参数(实际激活仅210亿),实现了最高的综合能力得分。 这在学术上称为“帕累托最优”边界上的点,通俗讲就是“花小钱,办大事”,完美契合了姚顺雨提出的“性价比追求”原则。 在腾讯云大模型服务平台TokenHub上,Hy3 preview输入价格最低1.2元/百万tokens,输入命中缓存价格0.4元/百万tokens,输出价格最低4元/百万tokens。 总结一下就是,Hy3 preview没有刻意追求参数上的“大”和榜单上的绝对领先,而是以“性价比追求”为原则, 这些成果表明,姚顺雨推动的这场自上而下的改革已初见成效。这不仅仅是发布了一个新模型,更证明了腾讯在大模型领域的追赶决心和路径正确性。 如果觉得我的内容对您有帮助,请关注我的公众号,每天会分析最新的AI资讯。
 夜雨聆风
夜雨聆风