 夜雨聆风
夜雨聆风





我把这个 AI Agent 汉化了,然后发现省 token 比汉化更有意思

1
引子
上次写了 Hermes Agent 汉化和桌面端的经历,那之后又做了近一个月的工作,今天想聊点不一样的——改造过程中的工程决策和权衡。
这个故事的主角是 token。
项目地址:github.com/xyshanren/hermes-agent-cn(分支 cn)
2
一切从一行提示词说起
Agent 的工作方式是这样的:系统提示词 + 工具描述 + 对话历史,一起塞进 LLM 的上下文窗口。
关键在于,系统提示词中的每一行内容,都会乘以对话轮数。
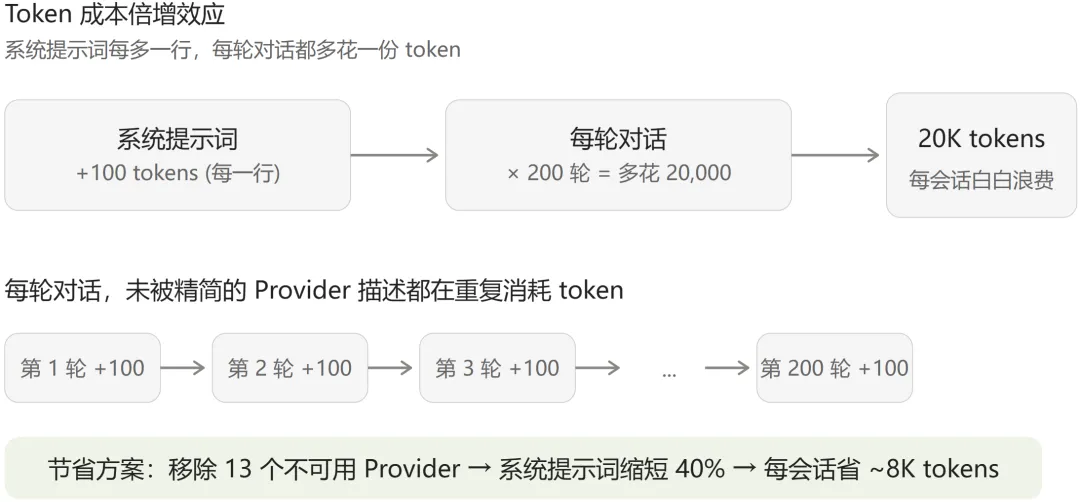
系统提示词每多 100 tokens × 200 轮对话 = 每会话多花 20,000 tokens对于用 API 的用户,这是实打实的成本。对于用本地模型的用户,这意味着上下文窗口被吞噬,导致模型”记不住”更早的对话。
所以我开始认真审视:这个系统提示词里,有哪些东西是不需要的?
3
第一刀:24 个 Provider → 11 个
打开 Hermes 的 Provider 列表,24 个,排了两屏。里面有一大半是普通国内用户永远用不上的服务:
- OpenRouter / Anthropic / OpenAI Codex — 需要翻墙
- Hugging Face / Google Gemini — 时好时坏
- xAI / AWS Bedrock 等 — 需要翻墙
每个 Provider 在系统提示词中都有自己的描述段落。24 个 Provider 的描述加起来,占了系统提示词将近一半的空间。
于是做了第一件事:把 13 个国内不可用的 Provider 从列表中移除。

系统提示词缩短了大约 40%。每轮对话省下的 tokens 不多,但乘以数百轮,效果可观。
但这里有一个工程上的纠结:是直接删掉代码,还是只隐藏配置入口?
删除代码看起来很彻底,但每次上游合并(Hermes 隔几周就合并一次上游更新)都会产生冲突——代码被删了,上游又加了回来,Git 合并工具不知道该怎么办。
最终我选了配置隐藏:代码保留,只把不需要的条目从配置入口隐藏。加起来只改了 23 行代码。
+23 lines / -5 lines ← 总改动量零冲突 ← 每次上游合并不需要手动解决这是一个”短痛 vs 长痛”的选择。有些工程问题,在当下解决的成本远高于延后解决的成本。
4
第二刀:锁定模型,省掉切换开销
Agent 的 /model 命令允许在任何时刻切换模型。这个功能的代价是:运行时必须维护一份完整的 Provider 列表,因为你永远不知道用户什么时候会想切换。
但实际情况是:绝大多数用户一次会话只用一到两个模型。
所以我做了一个有争议的决策:启动时绑定模型,会话中不可切换。
之前:→ 启动对话 → 加载 Provider 列表到上下文 → 用户可能随时切换之后:→ 启动时绑定模型 → 移除运行时 Provider 列表 → 每会话省 ~2K tokens代价是:想换模型就得退出对话,在终端执行 hermes model 再进来。这个体验回退换来了可量化的 token 节省。
这是个取舍问题——通用性 vs 效率。对于个人用户,效率的优先级更高。
详见:
/model命令的设计在 README_CN.md 中有完整说明
5
第三刀:三层路由,让简单任务不走 API
CN 版内置了一个嵌入式 CPU 推理引擎(基于 llama-cpp-python),加上 Ollama 支持,形成了三层路由:
关键不在于这个架构本身,而在于如何让用户无感地搭起来。
传统做法:用户需要自己下载模型、配置路径、测试连通性……
CN 版的做法:一句话搞定。
hermes local-models setup --yes这条命令背后做了:
- 安装 5 个 Python 包(modelscope, llama-cpp-python, faster-whisper, onnxruntime, edge-tts)
- 从 ModelScope 国内 CDN 下载 4 个模型(Whisper-small, Qwen2.5-0.5B, MOSS-TTS-Nano, Edge-TTS),共约 1.58GB
- 自动配置推理引擎
用户不需要知道 llama-cpp-python 是什么,也不需要知道什么叫 GGUF。
零摩擦是我在这轮改造中加上的第二个设计原则。
6
插曲:Skill 不用也会吃 token
前面讲的都是模型层的 token 优化,还有一个容易被忽略的源头——技能系统。
Hermes 有一个独特的技能系统:你可以把写好的工作流存成 skill,下次直接调用。问题是,所有 skill 的描述都会注入系统提示词。
一个项目有 30 多个 skill(第三方安装的、社区共享的、自己写的),每个 skill 的描述加起来,不声不响地占用了大量上下文。
CN 版加了一个 三层管理器,自动做升降级:
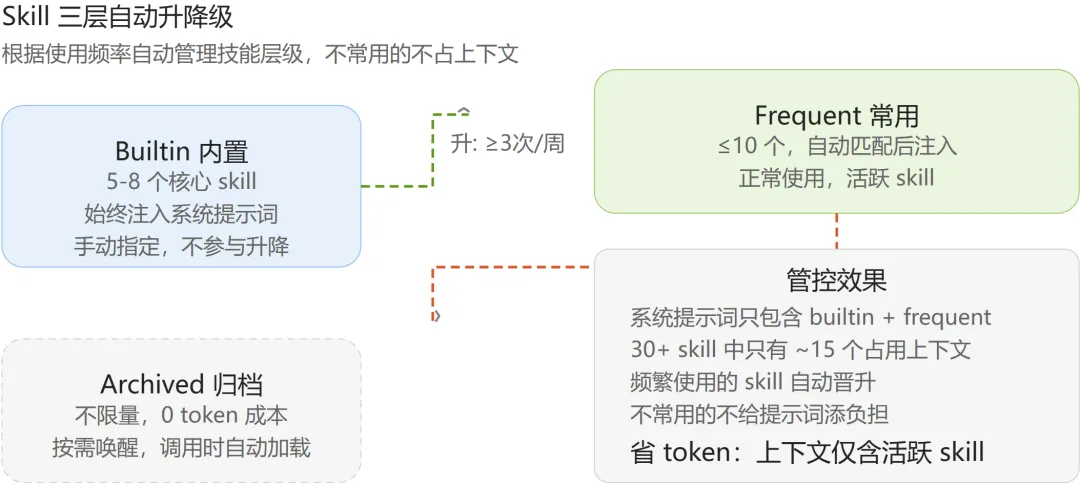
builtin(内置) → 5-8 个核心 skill,始终注入frequent(常用) → ≤10 个,自动匹配后注入archived(归档) → 不限量,0 token 成本,按需唤醒升降级规则:
- 连续 7 天没用 → 自动归档,从系统提示词中移除
- 一周内用了 3 次以上 → 自动晋升到常用层级
- 调用被归档的 skill → 自动加载回来,用户无感
参考实现:agent/skill_tier_manager.py
7
第四刀:从零到对话,三步缩减成一步
原始 Hermes 的配置流程:hermes setup → 选 Provider → 输入 API Key → 选模型 → 确认 → 启动对话。至少 5 步,每一步都是一个决策点。
CN 版改成了一句命令:
hermes quickstart背后做了什么:
- 扫描环境变量(
DEEPSEEK_API_KEY,SILICONFLOW_API_KEY,ZHIPUAI_API_KEY等) - 检测本地 Ollama 是否运行
- 检测本地是否已有离线模型
- 按优先级(API Key → Ollama → 本地模型)自动配置第一个可用的
- 如果三样都没有 → 引导安装本地离线模型
用户不需要做任何选择。
选择是一种认知负担。 对于首次使用的用户,应该尽量减少选项。等他们用熟了,自然会探索其他功能。
详细实现:hermes_cli/quickstart.py
8
工程决策的取舍模型
回顾这轮改造,我总结了一个决策框架:
|
|
|
|
|---|---|---|
| 省 token |
|
|
| 零摩擦 |
|
|
| 低维护 |
|
|
| 可恢复 |
|
|
这四个原则不一定都兼容。”省 token”和”零摩擦”有时冲突——为了省 token 绑定了模型,用户切换就要多一步。关键是要知道自己每个选择的代价。
9
一个还没做的决策:文言文压缩
有个有意思的方向我暂时没做:用文言文压缩上下文。
结构化摘要: {topic, decision, refs} → 压缩率 50-80%文言文压缩: "夫论者三,决者二..." → 压缩率 70-90%文言文的压缩率确实更好,但代价也很明显:
- 不是所有模型都懂文言文(需要 deepseek/zai 级别的古文理解力)
- 文言文有天然的多义性,信息召回风险高
- 开发成本高
我设了三个启动条件,等它们同时满足时才考虑文言试点:
- 上下文占用持续 80%+
- 模型对古文理解准确率 ≥ 90%(A/B 测试)
- 用户主动反馈 JSON 摘要不够用
这叫条件触发——在还没遇到问题之前,没必要过度设计。
10
小结
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
但我觉得最有价值的可能不是这些具体的优化,而是这个思路本身——当你把一个东西”本地化”的时候,不只是在翻界面文字,还要理解用户和环境的不同,并据此调整设计。
11
参考资源
- 项目主页:github.com/xyshanren/hermes-agent-cn(分支
cn) - 更新日志:CHANGELOG_CN.md
- 设计文档:README_CN.md
- 上游项目:NousResearch/hermes-agent
下一阶段准备正式发布 v0.12.0-cn.1。如果你也在折腾 AI Agent 的本地化,欢迎在评论区交流。
求索实验室 · 探索 AI 技术的工程实践