 夜雨聆风
夜雨聆风





一款能帮助科学家编写专家级实证型软件的人工智能系统

全文速览
本文介绍了经验研究助手(Empirical Research Assistance, ERA),这是一种基于大语言模型(LLM)和树搜索算法的人工智能系统,旨在系统自动地、规模化地创建专家级经验性软件以解决可评分的科学任务。与传统的一次性代码生成不同,ERA通过迭代重写现有软件候选方案,并利用树搜索决定哪些候选值得深入探索,从而在庞大的解空间中进行”大海捞针”式的高效能搜索。该系统在六个不同科学领域的基准测试中展现了超越人类专家的性能:在基因组学中,ERA发现了3440种新的单细胞RNA测序批次整合方法,其在公开排行榜上超越了所有人类开发的顶尖方法;在流行病学中,ERA生成1436个模型,其COVID-19住院率预测性能优于美国疾控中心(CDC)集成模型及所有其他单一模型;此外,ERA还在地理空间分析、斑马鱼神经活动预测、数值积分求解以及时间序列预测等领域产出了专家级软件,甚至发现了全新的基于规则的预测构造。ERA的核心优势在于其能够不知疲倦地以空前规模执行解空间搜索,通过代码层面的突变结合来自高被引论文、专业教科书和搜索引擎的研究想法注入,实现跨学科的自动化经验软件工程。
背景介绍
经验性软件——即以最大化可测量质量分数为目标设计的软件——在现代科学中无处不在,且是许多科研活动的核心支柱。从1998年密度泛函理论、2013年分子动力学模拟到2024年蛋白质结构预测,经验性软件已直接促成多项诺贝尔化学奖成果。它支撑着我们构建复杂系统模型的能力,从地球大气垂直柱参数化用于天气建模,到湍流应力响应参数化,再到社会系统预测。然而,为特定科学领域编写经验性软件历来是一项缓慢而艰巨的任务,通常需要数年的繁琐工作。当软件用于检验复杂假说时,从第一性原理出发编写变得愈发困难;设计选择往往受直觉或权宜之计支配,而非穷尽式实验探索。创建软件的时间成本如此之高,严重限制了可高效探索的科学可能性空间。为应对这一瓶颈,本文作者开发了ERA系统。其技术路线源于Kaggle竞赛的实战打磨:系统以LLM为代码重写引擎,通过树搜索(Tree Search, TS)策略在解空间中进行上置信界(PUCT)驱动的探索,同时允许用户或自动搜索引擎将外部研究想法(如顶尖论文方法、领域教科书知识)直接注入提示词,引导LLM生成更具针对性的代码突变。这种”想法+搜索”的耦合机制使ERA能够复现、重组甚至超越人类专家在公开排行榜上发表的最先进方法。
图文解析
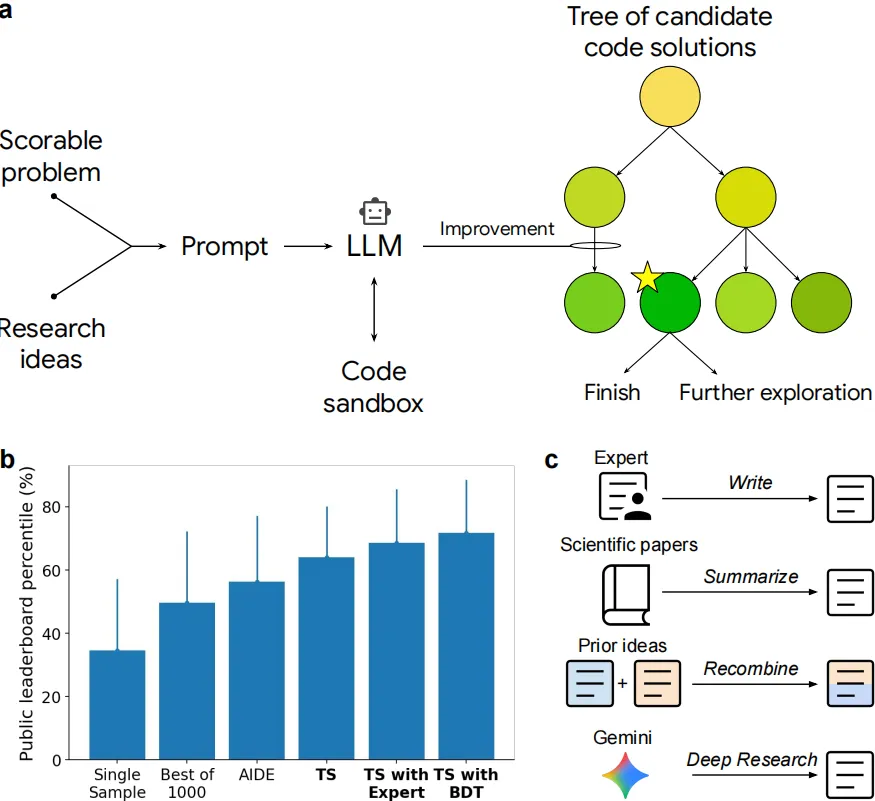
图1展示了ERA系统的整体架构与工作流程。图1a呈现了系统的核心循环:LLM接收任务描述、评估指标和数据后,对现有代码候选进行重写突变,生成的新代码在沙盒中执行并评分;树搜索算法利用该分数及输出日志等信息进行梯度上升式优化,通过平衡利用高分解与探索未知空间的PUCT准则,从全局节点集中选择下一个待扩展节点,从而实现对历史任意节点的回溯与分支。图1b说明ERA的能力是在Kaggle竞赛环境中通过实战竞争逐步开发完善的。图1c展示了系统如何通过多种渠道获取研究想法以增强代码突变,包括高被引论文、专业教科书和搜索引擎结果,这些想法可直接由用户注入或通过自动检索获取,LLM据此在编写代码时整合外部领域知识。
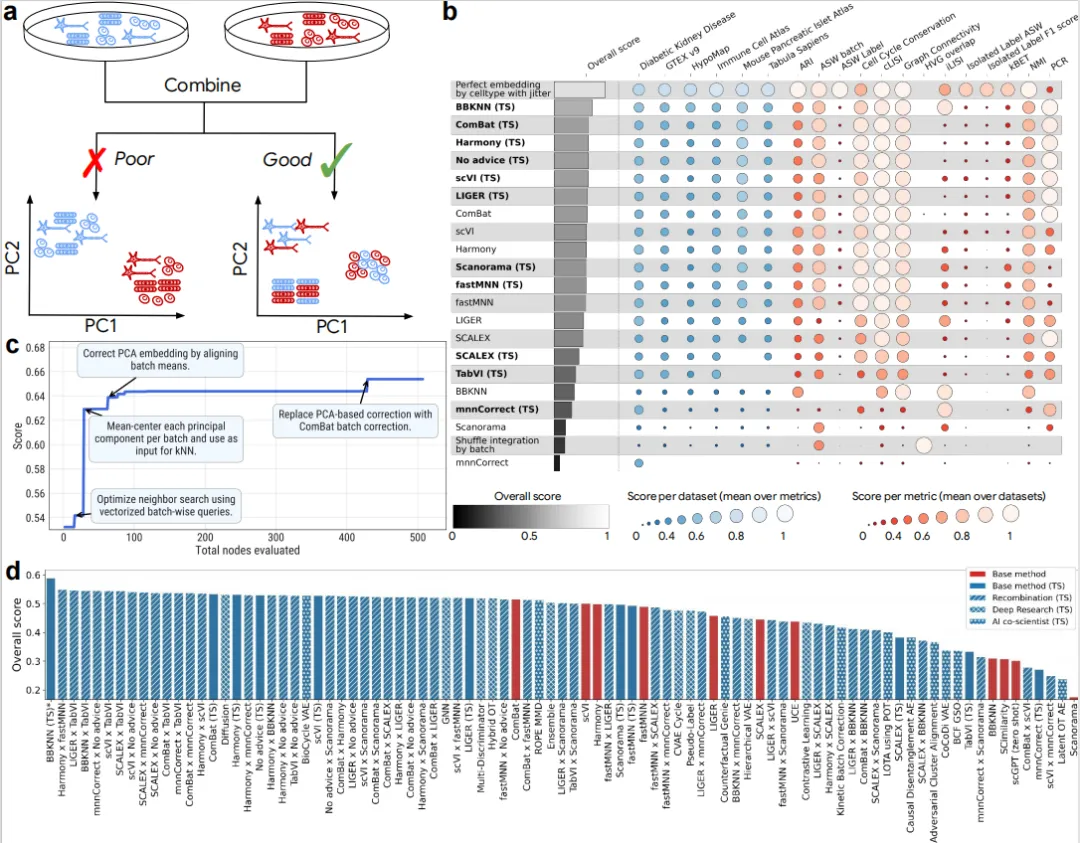
图2聚焦于基因组学领域的单细胞RNA测序批次整合任务。图2a的示意图阐释了批次整合的核心挑战:左侧显示两个不同批次(以蓝色和红色区分)的细胞数据,若直接合并(Combine)而不校正批次效应,则PCA降维结果会按批次而非真实的细胞类型(以鱼形和圆形区分)聚类,导致”差的”整合;右侧展示”好的”整合应保留生物信号,使相同细胞类型跨批次聚类。图2b以热图形式展示了ERA实现的多种方法(包括BBKNN (TS)、ComBat (TS)、Harmony (TS)等)在六个数据集(涵盖人类与小鼠)和十三项指标(如ARI、ASW batch、ASW Label、Cell Cycle Conservation、Graph Connectivity、HVG overlap、Isolated Label ASW、Isolated Label F1 score、kBET、NMI、PCR等)上的性能分布,每个圆点的大小和颜色深浅对应归一化后的得分高低,灰色条带表示总体分数。结果表明,BBKNN (TS)在总体分数上达到最高,且在去除批次效应的同时有效保留了生物变异性。图2c为BBKNN (TS)树搜索的突破图(Breakthrough plot),横轴为评估节点总数,纵轴为得分,曲线展示了最大分数随节点增加而演化的过程;图中标注了四个关键突变节点:初始阶段通过”使用向量化批次查询优化邻居搜索”实现分数跃升,随后”对每个批次的主成分进行均值中心化并作为kNN输入”带来进一步提升,接着”通过对齐批次均值校正PCA嵌入”稳定高分,最后”将PCA校正替换为ComBat批次校正”达到平台期。图2d以条形图对比了多种策略的总体分数,包括基础方法(Base method,红色)、基础方法的树搜索实现(Base method (TS),蓝色)、重组策略(Recombination (TS),斜纹蓝)、深度研究策略(Deep Research (TS),点纹蓝)以及AI协同科学家策略(AI co-scientist (TS),网格蓝);结果显示BBKNN (TS)位居榜首,且多数树搜索实现优于其对应的基础方法,体现了ERA在算法改进与策略融合上的强大能力。
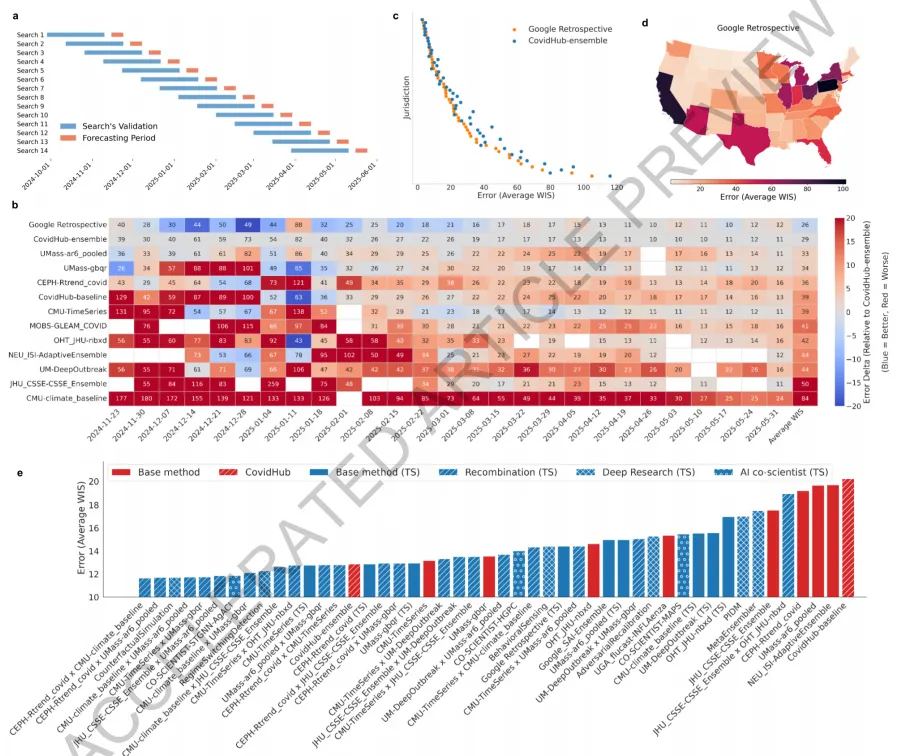
图3展示了ERA在COVID-19住院率预测流行病学任务中的表现。图3a描绘了回顾性研究设计:利用截至2025年5月1日的数据,对每个预测周期使用此前六周的数据进行滚动验证,构建贯穿2024-2025季节的验证窗口。图3b为时间序列排行榜,可视化ERA模型(Google Retrospective)相对于CovidHub集成模型及其他顶尖团队模型的每周性能优势,以加权区间评分(WIS)衡量,分数越低越好。图3c和3d通过美国各州(管辖区)的直接对比确认,ERA模型在大多数州实现了更低(更优)的WIS。图3e展示了ERA对预测策略空间的广泛探索能力,分为三个层次:首先是复制(Replication),仅依据CovidHub上其他团队提交的简短公开描述,ERA的树搜索实现不仅遵循了提供的指令,还在八个案例中的六个超越了原始提交;其次是重组(Recombination),LLM分析两个不同父模型的核心原理后,ERA生成融合两者优势的新型混合策略,26个混合模型中有11个在WIS上优于两个父模型;最后是全新策略生成,利用Gemini Deep Research和AI Co-scientist产生全新预测想法并由ERA实现,最终共有14种不同策略超越了官方CovidHub集成模型。
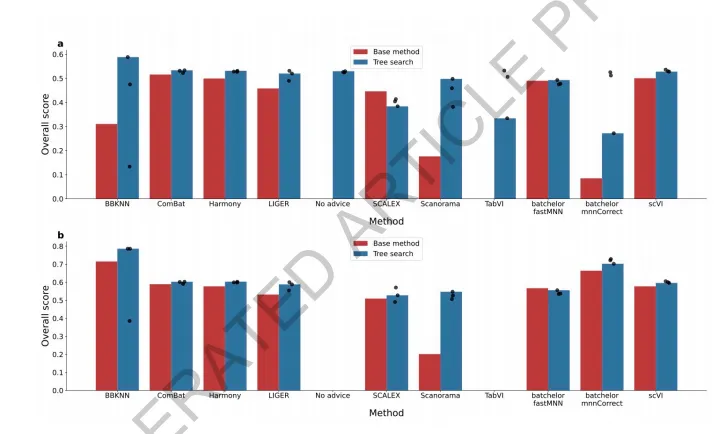
扩展数据图1展示了基础方法与ERA树搜索复制之间的相对性能关系。图a显示所有方法在保留OpenProblems数据集上的总体分数,每个树搜索方法进行了三次完整过程复制,黑点表示每次复制的总体得分,条形柱表示在验证集上表现最佳的那次复制的结果(与图2数值一致);值得注意的是,BBKNN、Scanorama和TabVI的最低性能复制分别仅成功计算了78个指标中的30、57和45个,原因是内存或计算时间限制,而算法并未显式针对这些问题进行选择淘汰。图b则限制为仅保留那些基础方法和全部三个树搜索复制均产生非NaN值的(方法、数据集、指标)组合,计算各方法的平均分数;由于No advice和TabVI没有基础方法对照,故未在此子图中出现。
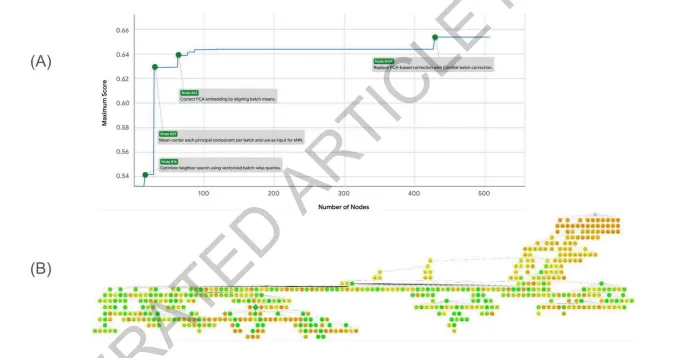
扩展数据图2的上半部分为BBKNN (TS)树搜索的突破图,展示最大分数随节点数增加的演化轨迹,绿色圆点标记分数因代码改进而突然增加的位置,标签描述了导致分数提升的代码变更内容;下半部分为同一搜索过程的树结构可视化,颜色范围从橙色(较低分数)过渡到绿色(较高分数),最高分数节点以菱形标示。
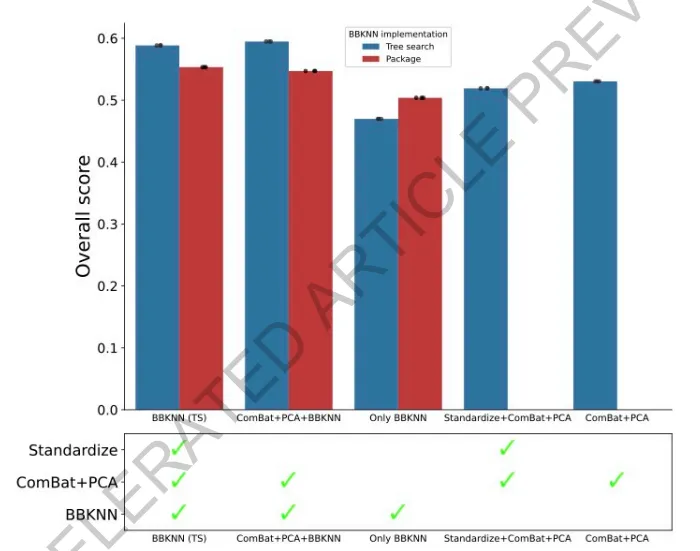
扩展数据图3比较了BBKNN的不同实现方式。条形图展示了五种配置在总体分数上的差异:BBKNN (TS)(树搜索实现的完整流程)、ComBat+PCA+BBKNN(树搜索实现的组合流程)、Only BBKNN(仅BBKNN)、Standardize+ComBat+PCA(标准化+ComBat+PCA)以及ComBat+PCA(ComBat+PCA);蓝色柱代表树搜索实现,红色柱代表现有软件包实现。结果显示,树搜索实现的BBKNN (TS)和ComBat+PCA+BBKNN均优于软件包版本。下方的勾选表格进一步展示了各配置所包含的预处理步骤(Standardize、ComBat+PCA、BBKNN),揭示了树搜索自动发现的有效模块组合。
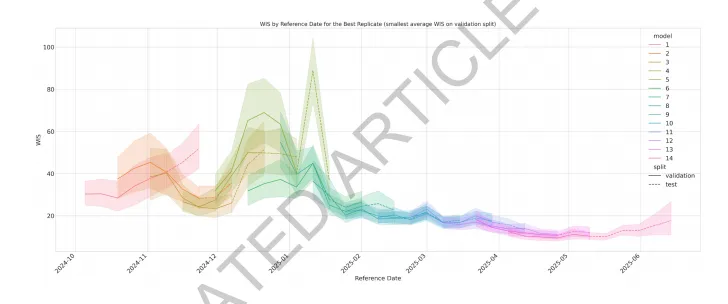
扩展数据图5(绘制了最佳复制(在验证分割上平均WIS最小)随参考日期变化的WIS曲线。图中以不同颜色线条表示14个模型,实线代表验证集(validation),虚线代表测试集(test),阴影区域表示置信区间。时间跨度从2024年10月至2025年6月,清晰展示了在2024年底至2025年初的疫情波动期,各模型WIS显著上升,而ERA优化后的模型在后续时间段保持了相对稳定的低WIS优势。

扩展数据图6展示了一个具有代表性的树搜索结构和对应的突破图,用于COVID-19预测任务,以可视化方式呈现解空间探索过程中的关键突破节点与树形演化路径。

扩展数据图7以系列条形图展示了COVID-19预测重组实验的性能。每个子图代表一次重组实验,左侧浅蓝色条形通常为两个父模型,右侧条形标记为”Recomb”表示混合模型;绿色表示重组模型优于两个父模型,深蓝色表示优于其中一个,红色表示未优于任一父模型。这些结果强调了搜索系统能够结合现有方法论的优势以实现更优预测性能。
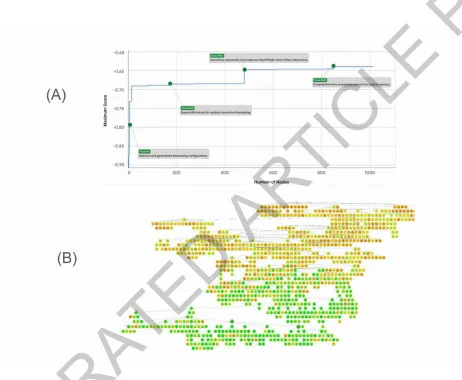
扩展数据图8的上半部分为GIFT-Eval时间序列预测任务树搜索的突破图,展示最大分数随节点数增加的演化,绿色圆点标记代码改进导致的分数跃升位置及其变更描述;下半部分为同一搜索的树结构,颜色从橙色(低分)到绿色(高分)渐变,最高分以菱形节点标示。
总结展望
ERA代表了向自动化科学软件工程迈出的重要一步,其核心贡献在于证明了一个通用AI系统能够在横跨基因组学、流行病学、地理空间科学、神经科学和数学等多个领域的可评分任务上,持续达到甚至超越人类专家水平。与现有技术相比,ERA的独特性体现在三个层面:相较于AlphaCode或OpenAI Codex等一次性代码生成系统,ERA采用迭代精炼循环,通过树搜索将质量分数作为反馈信号持续优化;相较于AutoML系统专注于固定机器学习框架内的架构与超参数搜索,ERA能够重写任意软件,涵盖预处理、复杂模拟、数学启发式等超出典型AutoML范畴的任务;相较于FunSearch或AlphaEvolve等进化算法框架,ERA不仅进行代码层面的进化,更通过LLM提示词在概念空间中直接重组专家想法,实现了对科学文献知识的深度整合。然而,作者明确指出,优化经验预测模型与真正的科学发现之间存在关键区别——后者需要对底层理论、因果机制和数学框架进行推理,而ERA目前主要聚焦于高级经验软件工程的自动化。尽管如此,该系统已展现出向科学发现拓展的潜力。值得警惕的是,LLM系统自主产出专家级经验软件的能力也带来了更广泛的安全风险:它显著降低了执行复杂计算任务所需的技术门槛,在加速有益科学发现的同时,也可能降低在敏感或潜在危险领域部署高级模型的准入壁垒。未来,ERA的开放源代码实现与交互式用户界面将为科学社区提供审视完整树搜索数据、突破轨迹与代码差异的工具,推动可解释、可复现的自动化科研软件工程的发展,同时也呼唤对AI辅助科学研究的伦理与安全框架进行更深入的探讨。
往期推荐-材料设计与人工智能入门教程
一、Anaconda3的使用
(1)编程语言基础-Python入门教学
(2)Pandas入门教学
(3)Numpy 详细入门教程
(4)Matplotlib 详细入门教程
二、材料与机器学习的背景介绍
(1)Pymatgen 详细入门教程
(2)Matminer 详细入门教程
(3)ASE (Atomic Simulation Environment) 详细入门教程
(4)Materials Project API (mp-api) 详细入门教程
(5)DScribe 详细入门教程
(6)材料科学机器学习基准数据集-Matbench 详细入门教程
(7)材料科学领域如何做特征工程-材料特征工程详解
(8)使用多种 Scikit-learn 分类模型对材料进行预测
(9)使用多种 Scikit-learn 回归模型对材料性质进行预测
(10)AFLOW(Automatic FLOW)详细入门教程
(11)OQMD (Open Quantum Materials Database) 详细入门教程
(12)Open Babel 材料结构数据格式与读写:CIF/POSCAR/XYZ全流程
(13)机器学习可解释性分析-完整入门教程
(14)材料数据聚类-sklearn教程
(15)材料数据降维-sklearn教程
(16)材料成分表征:Magpie / Oliynyk / One-hot / Stoichiometry 组合策略
(17)材料结构表征:RDF/ADF、Voronoi 邻域、局域配位环境特征
(18)材料图神经网络 – 入门教程
(19)材料化学的基准图神经网络 – MatDeepLearn教程
(20)MatGL(Materials Graph Library):材料图学习库 – 详细入门教程
(21)PyTorch卷积神经网络在材料领域的应用
(22)PyTorch循环神经网络在材料领域的应用
(23)PyTorch变分自编码器(VAE)在材料生成中的应用
(24)PyTorch生成对抗网络(GAN)在材料设计中的应用
(25)主动学习结合神经网络势函数入门教程
(26)PyTorch对比学习在材料表示学习中的应用
(27)PyTorch强化学习在材料优化中的应用
(28)PyTorch基于流的生成模型在材料表示学习中的应用
(29)PyTorch预训练-微调范式在材料领域的应用
(30)符号回归在材料规律发现中的应用
(31)迁移学习在材料性能预测中的应用
(32)贝叶斯优化在材料实验设计中的应用
(33)多任务学习在材料多性能同时预测中的应用
(34)高斯过程回归在材料不确定性量化中的应用
(35)ML加速DFT计算:主动学习驱动的结构筛选
(36)CALYPSO/USPEX结构预测结合机器学习
(37)催化剂设计中的机器学习
(38)电池材料设计中的机器学习
(39)二维材料发现中的机器学习方法
(40)热电材料设计中的机器学习
(41)材料科学文本挖掘:大规模文献数据提取 Pipeline
(42)HuggingFace Transformers 在材料科学中的应用
(43)RAG(检索增强生成)在材料文献综述中的应用
(44)材料知识图谱构建入门:Neo4j + LLM 三元组抽取