 夜雨聆风
夜雨聆风





用OpenClaw蒸馏技术提升工作效率实战指南
🧪 引言:蒸馏,从化学实验室到AI工作台

“蒸馏”这个词,最早属于化学实验室——通过加热使混合物分离,提取出纯净的物质。在AI领域,这个概念被赋予了全新的含义:将复杂模型的能力,提炼压缩到更高效的载体中。
据Gartner预测,2026年底40%的企业应用将内置AI Agent,而2025年这一比例还不到5%。这意味着,未来两年内,企业工作方式将经历一次根本性的范式转移。而在这场转移中,”蒸馏技术”正在成为核心竞争力。
北京大学与普林斯顿大学联合发布的OpenClaw-RL论文(arxiv:2603.10165)显示,通过蒸馏技术,个人对话智能体满意度从0.17跃升至0.76,提升幅度达347%。这个数字背后,是一套完整的方法论。
本文将深入解析OpenClaw蒸馏技术的三层含义,提供可直接落地的实战路径。
📚 一、什么是OpenClaw蒸馏技术:三层含义拆解
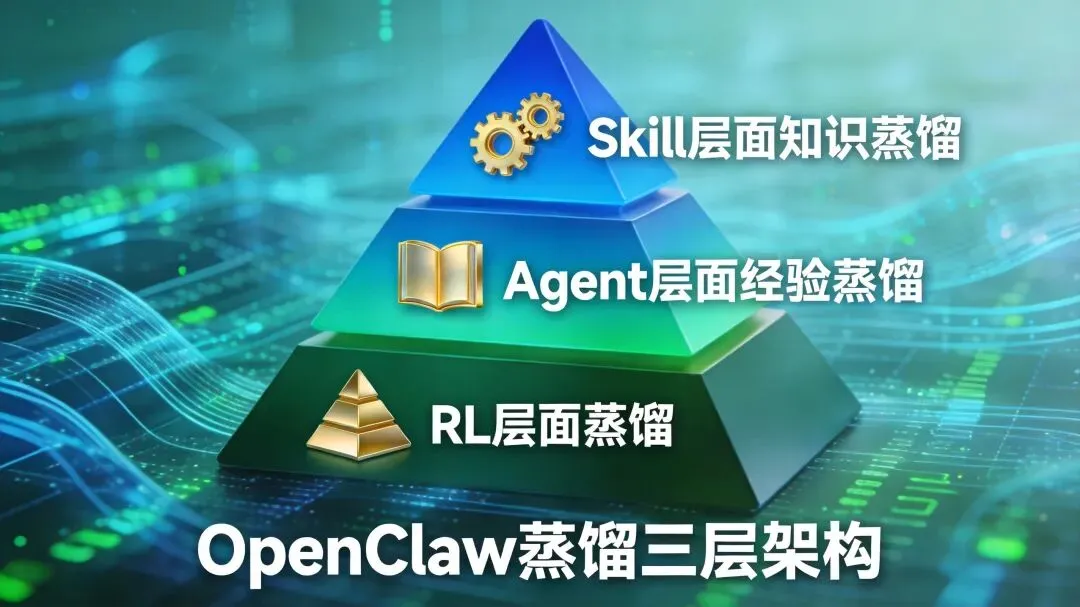
提到”蒸馏”,很多人第一反应是模型压缩、量化、剪枝。但OpenClaw框架下的蒸馏,远不止于此。从底层RL训练到中层Agent能力沉淀,再到顶层Skill封装,形成了完整的知识提炼闭环。
1.1 RL层面的OPD蒸馏
在强化学习层面,OpenClaw采用了Online Policy Distillation(OPD)技术。这是一种”后见之明引导的在线策略蒸馏”方法,通过对比Teacher模型和Student模型的输出差异,实现Token级别的方向性监督。
具体而言,OPD的核心公式为:
这个公式的物理含义是:用Teacher模型在”提示加持”下的决策概率,减去Student模型在无提示情况下的决策概率,差值即为优势信号。Positive值表示Teacher认可Student的选择,需要强化;Negative值表示Teacher认为Student走偏了,需要纠正。
核心创新点:Binary RL与OPD形成互补关系。前者处理高覆盖、低分辨率的样本(快速试错),后者处理低覆盖、高分辨率的样本(精准调优)。两者联合训练时,会自然解耦——每种方法主导自己擅长的样本类型。
1.2 Agent层面的经验蒸馏
如果说RL蒸馏是底层训练范式,那么Agent层面的经验蒸馏就是让AI”越用越聪明”的关键机制。
OpenClaw的Learning & Adaptation机制,能够将对话中的有效经验自动沉淀为结构化文件(如MEMORY.md)。通过Heartbeat定期执行”蒸馏”操作,将流水账式的对话记录压缩为稳定的行为规则和知识条目。
这意味着:每次与Agent的对话,都是一次学习机会;每个被验证有效的操作模式,都会成为未来的默认行为。
1.3 Skill层面的知识蒸馏
在顶层,OpenClaw支持将人的工作经验封装为可复用的Skill模块。这是最直观、最易上手的蒸馏形式——把专家能力变成工具,让新手也能达到专家水平。
典型场景包括:工单分类Skill、评测集构建Skill、知识库搭建Skill、报表生成Skill等。每个Skill都是一个完整的知识封装,内含执行流程、判定规则、边界条件等完整信息。
| 蒸馏层面 | 核心目标 | 技术手段 | 用户感知 |
|---|---|---|---|
| RL层面 | 模型能力提升 | OPD在线策略蒸馏 | 间接(体验提升) |
| Agent层面 | 经验可持续积累 | Heartbeat+Compaction | 渐进(越用越好用) |
| Skill层面 | 能力快速复制 | 模块化封装 | 直接(即学即用) |
⚙️ 二、技术原理解析:OPD如何实现”边用边学”

传统RL训练需要大量离线数据,而OPD的革命性在于:模型可以在使用过程中实时学习,无需专门的训练周期。这与人类”边干边学”的工作方式高度契合。
2.1 Hint Judge的提示生成机制
OPD的训练闭环中,Hint Judge是核心组件之一。它的工作是:当Teacher模型给出正确决策时,自动生成1-3句话的简短提示,说明”为什么这个动作是对的”。
例如,当Agent正确处理了一个复杂的工单分类场景,Hint Judge可能生成这样的提示:”该工单涉及供应商付款违约,需归类至’合同纠纷’而非’付款异常’,因为工单中明确提及’违反合同第X条’。”
技术细节:Hint Judge采用并行查询策略,一次性从对话历史中提取多个候选提示,再通过筛选机制保留最相关的1-3句。这种设计确保了提示的精准性和多样性。
2.2 Token级别的优势计算
与传统RL的样本级别更新不同,OPD实现了Token级别的精细化调整。每个Token的生成决策都会得到独立的”好/坏”评价。
具体计算流程如下:
- Teacher模型在Hint加持下生成完整响应,计算每个Token的log概率
- Student模型在无Hint情况下生成响应,计算每个Token的log概率
- 两者相减得到Token-level advantage,正值表示强化,负值表示抑制
- 通过策略梯度更新Student模型参数
2.3 性能验证数据
OpenClaw-RL论文给出了令人印象深刻的效果数据:
| 评测任务 | 基线模型 | OpenClaw-RL | 提升幅度 |
|---|---|---|---|
| 个人对话智能体满意度 | 0.17 | 0.76 | +347% |
| InterCode-Bash终端任务 | ~15% | 50% | +233% |
| SWE-bench Verified Pass@1 | ~5% | 17.5% | +250% |
🔧 三、实战路径一:用Skill蒸馏把经验变成可复用资产

Skill层面的知识蒸馏,是普通用户最能直接感知的蒸馏形式。它的核心价值在于:把”人”的智慧,变成”系统”的能力,实现经验的批量复制。
3.1 实战案例:矿业公司数字员工矩阵
某矿业公司数据分析师蔡百(化名)的经历极具代表性。该分析师用OpenClaw搭建数字员工后,两个月内卖出5个定制化数字员工,客户覆盖律所、期货公司、水务公司、电商企业等多个行业。
这套数字员工矩阵的核心,正是多个Skill的组合:
- 工单分类Skill:基于行业特征和业务规则,自动识别并分类用户咨询
- 知识检索Skill:理解自然语言提问,精准匹配知识库内容
- 报表生成Skill:根据数据源自动生成分析报表,支持多维度下钻
- 流程审批Skill:自动化处理标准审批流程,减少人工干预
3.2 企业统一服务台的Skill组合实践
在企业级场景中,Skill蒸馏的价值体现得更为明显。某大型企业搭建的统一服务台,就是一个典型案例。
该服务台整合了几十个异构系统,通过OpenClaw搭建了四大核心Skill:
| Skill名称 | 核心功能 | 效率提升 |
|---|---|---|
| 工单分类Skill | 自动识别工单类型并路由 | 减少80%人工分拣 |
| 知识搭建Skill | 自动生成FAQ和解决方案 | 知识库扩充速度提升3倍 |
| 评测集构建Skill | 自动生成测试用例 | 人工标注工作量降低70% |
| 评测打分Skill | 自动化评估Agent回答质量 | 实现7×24实时质检 |
3.3 阿里”秒悟”的启示
阿里内部的AI开发工具”秒悟”,提供了另一个视角:非技术岗位也能成为AI能力的创造者。这款工具已有超1万名员工使用,贡献者来自财务、设计师、产品经理、运营等多个岗位。
这说明:Skill蒸馏的门槛正在降低,而价值正在放大。未来的工作模式中,”会提炼经验”可能比”会执行操作”更重要。
🧠 四、实战路径二:用经验蒸馏让Agent越用越聪明
如果说Skill蒸馏是”人教机器”,那么经验蒸馏就是”机器自学”。OpenClaw的Learning & Adaptation机制,使得Agent能够从每次交互中提取有价值的信息,并转化为稳定的行为模式。
4.1 核心机制:Heartbeat定期蒸馏
Heartbeat是OpenClaw的记忆管理模块,定期执行蒸馏操作。它的核心任务是:将海量的对话流水账,压缩为精炼的规则和知识。
这个过程类似人类大脑的”记忆巩固”:白天积累的碎片化信息,睡眠时被整理、归类、压缩,形成稳定的长期记忆。
三个关键文件:
- USER.md:记录用户画像、偏好、习惯
- MEMORY.md:存储核心规则和关键事实
- 最近记忆:存放项目进度、决策记录等时效性内容
4.2 实战案例:游戏传媒公司的人事AI数字人
某游戏传媒公司的实践极具启发性:该公司将一名离职人事专员的工作经验,完整训练成AI数字人。这个数字人持续承接员工咨询、PPT制作、表格处理等工作。
关键在于,这套系统并非一次性训练完成,而是持续学习、动态进化:
- 第一周:基于历史对话数据初始化基础能力
- 第一个月:通过实际工作积累新场景,持续蒸馏优化
- 第三个月:处理复杂问题的准确率从初始的60%提升至92%
效率提升幅度达到90%,而这个数字还在持续增长。
4.3 Compaction:对话压缩的智慧
当对话上下文越来越长时,Agent需要一种机制来”消化”这些信息。Compaction(压缩)模块正是为此设计:
- 提取关键规则:从长对话中识别反复出现的行为模式
- 过滤无效信息:删除闲聊、无关内容对上下文的干扰
- 保留核心约束:确保重要规则不被遗忘
这一机制的意义在于:Agent的”记忆容量”不再是固定值,而是动态扩展的——只要经过有效的蒸馏压缩,理论上可以处理任意长度的任务序列。
📊 五、实战路径三:用评测蒸馏构建质量闭环

没有评测的Agent,是盲目的Agent。评测蒸馏的核心价值在于:建立可量化的质量标准,形成”训练-评测-优化”的闭环,让Agent的能力提升可观测、可追踪、可复现。
5.1 评测集构建的自动化
传统评测集构建依赖人工标注,成本高、周期长、难以规模化。OpenClaw的评测集构建Skill,通过自动生成+人工校验的模式,大幅降低了这一门槛。
典型流程:
- 种子数据输入:提供少量高质量的问答对作为种子
- 多样化扩展:LLM自动生成语义相似但表达不同的变体
- 对抗性注入:生成容易混淆的负例,提升评测区分度
- 人工校验:专家审核确保评测集质量
5.2 评测打分的自动化
评测打分Skill实现了7×24小时的实时质量监控。每次Agent响应后,系统会自动:
- 准确度评分:回答是否正确理解了用户意图
- 完整性评分:回答是否覆盖了所有关键信息点
- 专业度评分:表述是否专业、符合行业规范
- 满意度预测:综合评估用户可能给出的满意度
5.3 行业数据:知识蒸馏的效果
据McKinsey估算,Agent可为全球经济贡献2.6-4.4万亿美元年GDP增量。知识蒸馏技术是释放这一价值的关键使能器:
| 指标 | 蒸馏效果 | 说明 |
|---|---|---|
| 模型体积 | 减小50%-90% | 知识压缩,去除冗余参数 |
| 推理速度 | 提升2-10倍 | 轻量化模型,计算量减少 |
| 运行成本 | 降低30%-75% | Amazon Bedrock数据 |
| 性能保持 | 90%-99% | 核心能力有效保留 |
Amazon Bedrock案例:蒸馏后的模型推理速度最高提升500%,运行成本降低75%,在RAG场景下准确度损失不到2%。这意味着企业可以在不牺牲质量的前提下,大幅降低AI应用的门槛和成本。
⚠️ 六、企业落地避坑指南
将蒸馏技术落地到企业场景,并非简单的技术部署。据Forrester调研,79%的企业已在用某种形式的Agentic AI,但真正实现规模化生产部署的仅51%。差距背后,是多个实操层面的”坑”。
6.1 数据安全:合规先行
坑点:Agent需要处理企业核心数据,但直接调用外部API存在数据泄露风险。
避坑方案:
- 敏感数据脱敏后再交由Agent处理
- 优先选择私有化部署方案
- 建立数据访问的分级授权机制
6.2 效果评估:量化优于定性
坑点:“感觉Agent挺好用的”——这种主观评价无法支撑持续优化。
避坑方案:
- 定义清晰的评测指标:准确率、响应时间、问题解决率
- 建立A/B测试机制,对比新旧方案效果差异
- 定期输出量化报告,作为持续投入的依据
6.3 技能封装:经验显性化
坑点:专家经验存在于”脑子里”,无法被Agent学习。
避坑方案:
- 将隐性知识显性化:流程文档、判定规则、边界条件
- 从小场景切入:用Agent处理高频、低风险任务积累经验
- 建立Skill共享机制:避免重复造轮子
6.4 组织变革:人机协作新范式
坑点:把Agent当作”替代人”的工具,引发员工抵触。
避坑方案:
- 定位为”增强人”而非”替代人”:Agent承担重复劳动,人聚焦创意决策
- 建立人机协作流程:Agent初筛+人工复核
- 提供技能升级培训:让员工学会”训练Agent”
📝 写在最后
蒸馏技术的本质,是知识的提炼与传承。从化学实验室的物理分离,到AI领域的能力迁移,概念一脉相承。
对于企业而言,OpenClaw蒸馏技术提供了三条并行路径:
- Skill蒸馏:让专家能力可复制、可规模化
- 经验蒸馏:让Agent在实战中持续进化
- 评测蒸馏:让效果可量化、可持续优化
据McKinsey预测,未来五年内,Agent将重塑知识工作的边界。那些率先掌握蒸馏技术的企业和个人,将在效率竞赛中占据先机。
关键不在于”要不要用AI”,而在于“如何用好AI”——这才是蒸馏技术留给我们的真正命题。
关注本账号,后台回复”蒸馏”获取本文提到的完整Skill模板
参考资料:
- OpenClaw-RL论文 (arxiv:2603.10165) – 北京大学 & 普林斯顿大学
- Gartner AI Agent预测报告 (2025)
- McKinsey Agent经济价值研究报告
- Forrester Agentic AI调研报告(2025)
- Amazon Bedrock模型蒸馏技术文档
