









































































































文档内容
专题 41 统计与统计案例
(核心考点精讲精练)
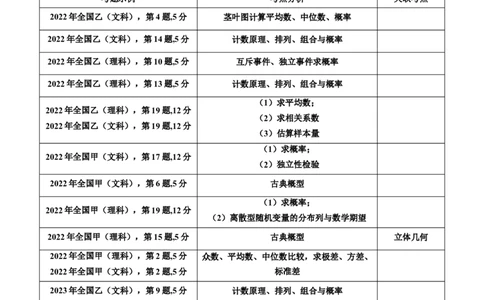
1. 近几年真题考点分布
概率与统计近几年考情
考题示例 考点分析 关联考点
2022年全国乙(文科),第4题,5分 茎叶图计算平均数、中位数、概率
2022年全国乙(文科),第14题,5分 计数原理、排列、组合与概率
2022年全国乙(理科),第10题,5分 互斥事件、独立事件求概率
2022年全国乙(理科),第13题,5分 计数原理、排列、组合与概率
(1)求平均数;
2022年全国乙(理科),第19题,12分
(2)求相关系数
2022年全国乙(文科),第19题,12分
(3)估算样本量
(1)求概率;
2022年全国甲(文科),第17题,12分
(2)独立性检验
2022年全国甲(文科),第6题,5分 古典概型
(1)求概率;
2022年全国甲(理科),第19题,12分
(2)离散型随机变量的分布列与数学期望
2022年全国甲(理科),第15题,5分 古典概型 立体几何
2022年全国甲(理科),第2题,5分 众数、平均数、中位数比较,求极差、方差、
2022年全国甲(文科),第2题,5分 标准差
2023年全国乙(文科),第9题,5分 计数原理、排列、组合与概率
2023年全国乙(理科),第5题,5分
几何概型 圆环面积
2023年全国乙(文科),第7题,5分
2023年全国乙(理科),第9题,5分 计数原理与排列、组合
2023年全国乙(理科),第17题,12分 (1)求样本平均数,方差;
2023年全国乙(文科),第17题,12分 (2)统计新定义
2023年全国甲(文科),第4题,5分 计数原理、排列、组合与概率
2023年全国甲(理科),第6题,5分 条件概率
资料整理【淘宝店铺:向阳百分百】2023年全国甲(理科),第9题,5分 计数原理与排列、组合
(1)离散型随机变量的分布列与数学期望;
2023年全国甲(理科),第19题,12分
(2)独立性检验
(1)求样本平均数;
2023年全国甲(文科),第20题,12分
(2)独立性检验
2. 命题规律及备考策略
【命题规律】1.通常会结合实际情境,例如社会热点问题、经济发展数据、公司业务情况等,要求考生运
用统计知识对实际问题进行分析和解释;
2.注重应用性,即要求考生能够运用统计方法和工具解决实际问题。考生需要在掌握基本概
念和理论的基础上,具备数据处理、分析和解决问题的能力;
3.考查考生的数据分析和处理能力,数据的收集、整理、分析和解释等;掌握各种统计方法
和工具,并能够运用它们对数据进行分析和解释;
4.关注时事热点,了解相关的数据和研究报告,提高自身的数据意识和数据分析能力;
【备考策略】1.了解简单随机抽样的含义及利用其解决问题的过程,掌握两种简单随机抽样方法:抽签法和随
机数法.掌握分层随机抽样的样本均值和样本方差;
2.能根据实际问题的特点,选择恰当的统计图表对数据进行可视化描述,体会合理使用统计图表
的重要性;
3.会求平均数、中位数、众数,理解集中趋势参数的统计含义;
4.能用样本估计总体的离散程度参数(标准差、方差、极差),理解离散程度参数的统计含义;
5.会求百分位数,理解百分位数的统计含义;
6.了解样本相关系数的统计含义,会求样本相关系数;
7.了解最小二乘原理,掌握一元线性回归模型参数的最小二乘估计方法;
8.针对实际问题,会用一元线性回归模型进行预测;
【命题预测】1.需要掌握基本的统计概念和方法,这些概念和方法是解决统计问题的基础,也是命题中常
见的考查内容;
2.数据分析和处理是统计学的核心,需要掌握数据的收集、整理、分析和解释等技能。这部
分内容可能会涉及到数据的预处理、异常值处理、图表制作、数据挖掘等方面的知识;
3.统计学的应用非常广泛,可以用于社会、经济、医学、自然等多个领域。因此,需要了解
和掌握一些实际应用案例;
4.需要掌握一些常用的数据分析工具,这些工具在数据处理、统计分析、可视化等方面都有
着广泛的应用;
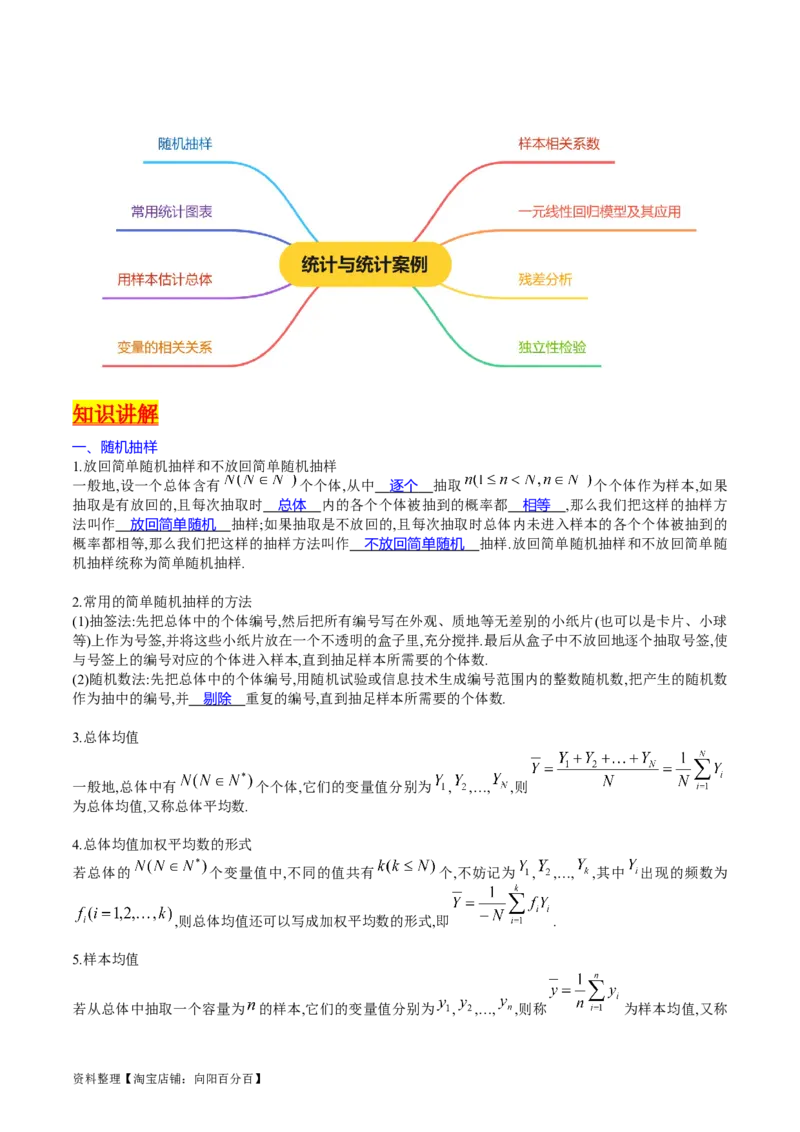
资料整理【淘宝店铺:向阳百分百】知识讲解
一、随机抽样
1.放回简单随机抽样和不放回简单随机抽样
一般地,设一个总体含有 个个体,从中 逐个 抽取 个个体作为样本,如果
抽取是有放回的,且每次抽取时 总体 内的各个个体被抽到的概率都 相等 ,那么我们把这样的抽样方
法叫作 放回简单随机 抽样;如果抽取是不放回的,且每次抽取时总体内未进入样本的各个个体被抽到的
概率都相等,那么我们把这样的抽样方法叫作 不放回简单随机 抽样.放回简单随机抽样和不放回简单随
机抽样统称为简单随机抽样.
2.常用的简单随机抽样的方法
(1)抽签法:先把总体中的个体编号,然后把所有编号写在外观、质地等无差别的小纸片(也可以是卡片、小球
等)上作为号签,并将这些小纸片放在一个不透明的盒子里,充分搅拌.最后从盒子中不放回地逐个抽取号签,使
与号签上的编号对应的个体进入样本,直到抽足样本所需要的个体数.
(2)随机数法:先把总体中的个体编号,用随机试验或信息技术生成编号范围内的整数随机数,把产生的随机数
作为抽中的编号,并 剔除 重复的编号,直到抽足样本所需要的个体数.
3.总体均值
一般地,总体中有 个个体,它们的变量值分别为 , ,…, ,则
为总体均值,又称总体平均数.
4.总体均值加权平均数的形式
若总体的 个变量值中,不同的值共有 个,不妨记为 , ,…, ,其中 出现的频数为
,则总体均值还可以写成加权平均数的形式,即 .
5.样本均值
若从总体中抽取一个容量为 的样本,它们的变量值分别为 , ,…, ,则称 为样本均值,又称
资料整理【淘宝店铺:向阳百分百】样本平均数.我们常用样本均值 估计总体均值 .
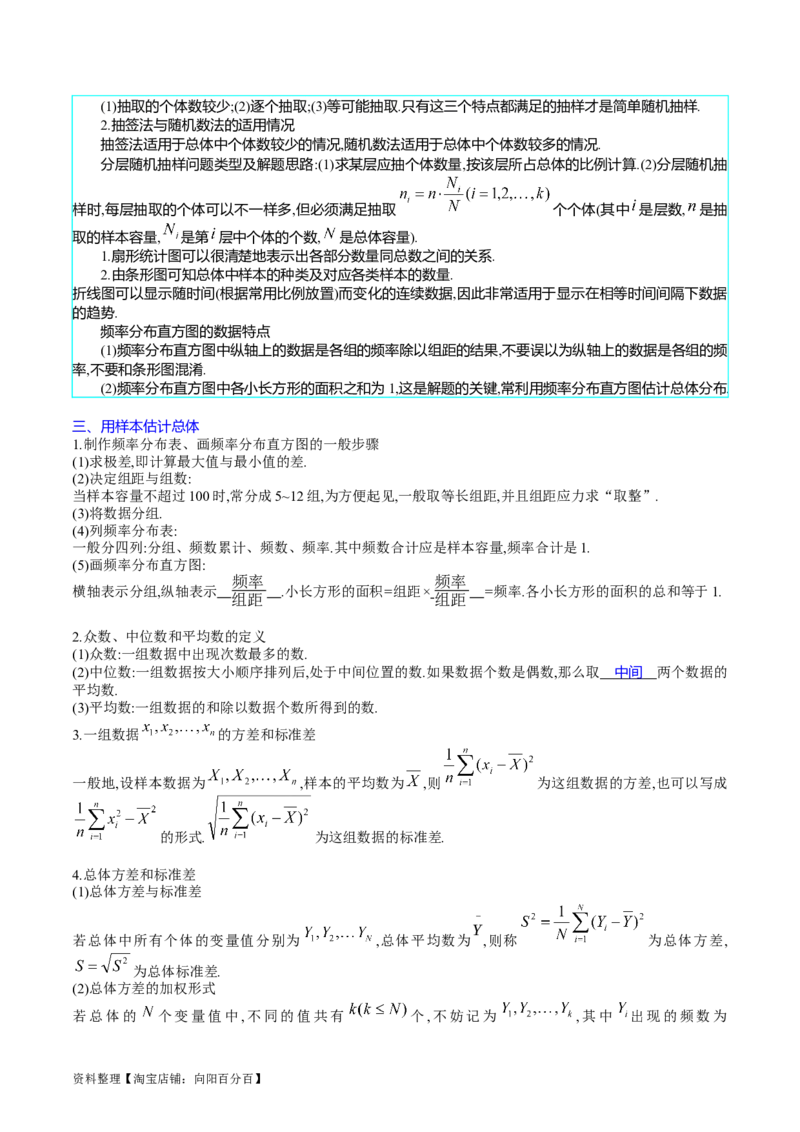
6.分层随机抽样的概念
一般地,按一个或多个变量把总体划分成若干个子总体,每个个体属于且仅属于一个子总体,在每个子总体中
独立地进行简单随机抽样,再把所有子总体中抽取的样本合在一起作为总样本,这样的抽样方法称为 分层
随机抽样 .
(1)层:每个子总体称为层.
(2)比例分配:在分层随机抽样中,如果每层样本量都与层的大小成比例,那么称这种样本量的分配方式为比例
分配.
7.分层随机抽样的样本均值
在分层随机抽样中,如果层数分为2层,第1层和第2层包含的个体数分别为 和 ,抽取的样本量分别为
和 .我们用 , ,…, 表示第1层各个个体的变量值,用 , ,…, 表示第1层样本的各个个体的
变量值;用 , ,…, 表示第2层各个个体的变量值,用 , ,…, 表示第2层样本的各个个体的变量值,
则
(1)第1层的总体平均数和样本平均数分别为 , ;
(2)第2层的总体平均数和样本平均数分别为 , ;
(3)总体平均数和样本平均数分别为 , .
在比例分配的分层随机抽样中,样本平均数 ,可以直接用样本平均数 估计总体平均
数 .
二、常用统计图表
1.频率分布直方图
频率 频率
(1)纵轴表示 ,即小长方形的高= ;
组距 组距
频率
(2)小长方形的面积=组距× =频率;
组距
(3)各小长方形的面积的总和等于1.
2.折线图
3.扇形图
4.条形图
频率分布直方图中的常见结论
(1)众数的估计值为最高矩形的中点对应的横坐标;
(2)平均数的估计值等于频率分布直方图中每个小矩形的面积乘以小矩形底边中点的横坐标之和;
(3)中位数的估计值的左边和右边的小矩形的面积和是相等的.
1.简单随机抽样的特点
资料整理【淘宝店铺:向阳百分百】(1)抽取的个体数较少;(2)逐个抽取;(3)等可能抽取.只有这三个特点都满足的抽样才是简单随机抽样.
2.抽签法与随机数法的适用情况
抽签法适用于总体中个体数较少的情况,随机数法适用于总体中个体数较多的情况.
分层随机抽样问题类型及解题思路:(1)求某层应抽个体数量,按该层所占总体的比例计算.(2)分层随机抽
样时,每层抽取的个体可以不一样多,但必须满足抽取 个个体(其中 是层数, 是抽
取的样本容量, 是第 层中个体的个数, 是总体容量).
1.扇形统计图可以很清楚地表示出各部分数量同总数之间的关系.
2.由条形图可知总体中样本的种类及对应各类样本的数量.
折线图可以显示随时间(根据常用比例放置)而变化的连续数据,因此非常适用于显示在相等时间间隔下数据
的趋势.
频率分布直方图的数据特点
(1)频率分布直方图中纵轴上的数据是各组的频率除以组距的结果,不要误以为纵轴上的数据是各组的频
率,不要和条形图混淆.
(2)频率分布直方图中各小长方形的面积之和为1,这是解题的关键,常利用频率分布直方图估计总体分布.
三、用样本估计总体
1.制作频率分布表、画频率分布直方图的一般步骤
(1)求极差,即计算最大值与最小值的差.
(2)决定组距与组数:
当样本容量不超过100时,常分成5~12组,为方便起见,一般取等长组距,并且组距应力求“取整”.
(3)将数据分组.
(4)列频率分布表:
一般分四列:分组、频数累计、频数、频率.其中频数合计应是样本容量,频率合计是1.
(5)画频率分布直方图:
频率 频率
横轴表示分组,纵轴表示 .小长方形的面积=组距× =频率.各小长方形的面积的总和等于1.
组距 组距
2.众数、中位数和平均数的定义
(1)众数:一组数据中出现次数最多的数.
(2)中位数:一组数据按大小顺序排列后,处于中间位置的数.如果数据个数是偶数,那么取 中间 两个数据的
平均数.
(3)平均数:一组数据的和除以数据个数所得到的数.
3.一组数据 的方差和标准差
一般地,设样本数据为 ,样本的平均数为 ,则 为这组数据的方差,也可以写成
的形式. 为这组数据的标准差.
4.总体方差和标准差
(1)总体方差与标准差
−
Y
若总体中所有个体的变量值分别为 ,总体平均数为 ,则称 为总体方差,
为总体标准差.
(2)总体方差的加权形式
若总体的 个变量值中,不同的值共有 个,不妨记为 ,其中 出现的频数为
资料整理【淘宝店铺:向阳百分百】,则总体方差 .
5.样本方差和标准差
(1)若一个样本中个体的变量值分别为 ,样本平均数为 ,则称 为样本方差,
为样本标准差.
(2)标准差的意义
标准差刻画了数据的离散程度或波动幅度,标准差越大,数据的离散程度越大;标准差越小,数据的离散程度越
小.
6.分层随机抽样的方差
总体划分为3层,通过分层随机抽样,各层的样本容量、样本平均数、样本方差分别为 ; ;
.记总的样本平均数为 ,样本方差为 ,则
(1) ;
(2) .
1.方差的简化计算公式: ,即方差等于原数据平方的平均数减去平均数
的平方.
2.平均数、方差公式的推广
(1)若数据 的平均数为 ,则 的平均数是 .
(2)若数据 的方差为 ,则
①数据 的方差也是 ;
②数据 的方差是 .
1.求平均数时要注意数据的个数,不要重计或漏计.
2.求中位数时一定要先对数据按大小排序,若最中间有两个数据,则中位数是这两个数据的平均数.
3.若有两个或两个以上的数据出现得最多,且出现的次数一样,则这些数据都叫众数;若一组数据中每个
数据出现的次数一样多,则没有众数.
利用样本的方差(标准差)解决优化决策问题的依据
(1)标准差、方差描述了一组数据围绕平均数波动的大小.标准差、方差越大,数据的离散程度越大,越不
稳定;标准差、方差越小,数据的离散程度越小,越稳定.
(2)用样本估计总体就是利用样本的数字特征来描述总体的数字特征.
四、变量的相关关系
1.相关关系:两个变量有关系,但又 没有 确切到可由其中一个去精确地决定另一个的程度,这种关系称为
相关关系.
2.正(负)相关:如果从整体上看,当一个变量的值增加时,另一个变量的相应值也呈现增加的趋势,那么我们就称
这两个变量 正相关 ;当一个变量的值增加时,另一个变量的相应值呈现减少的趋势,那么我们就称这两个
变量 负相关 .
资料整理【淘宝店铺:向阳百分百】3.线性相关:一般地,如果两个变量的取值呈现正相关或负相关,而且散点落在一条直线附近,那么我们就称这
两个变量线性相关.
4.非线性相关:一般地,如果两个变量具有相关性,但不是线性相关,那么我们就称这两个变量非线性相关或曲
线相关.
五、样本相关系数
1.样本相关系数 .
2.样本相关系数的性质
(1)当 时,称成对样本数据正相关.
(2)当 时,称成对样本数据负相关.
(3)样本相关系数 的取值范围为[-1,1].样本相关系数 的绝对值大小可以反映成对数据之间线性相关的程度.
(4)当 越接近1时,成对样本数据的线性相关程度越 强 ;
(5)当 越接近0时,成对样本数据的线性相关程度越 弱 .
六、一元线性回归模型及其应用
{Y =bx+a+e,
1.一元线性回归模型:我们称 E(e)=0, 为 关于 的一元线性回归模型.
D(e)=σ2
2.经验回归方程(直线):我们将 称为 关于 的 经验回归 方程,也称经验回归函数或经验回归
公式,其图形称为经验回归直线.
3.经验回归方程 是两个具有线性相关关系的一组数据 的回归方程,其
中 是待定参数,其最小二乘估计分别为 , .其中
.
说明:经验回归直线 必过样本点的中心 ,这个结论既是检验所求经验回归直线是否准确的依
据,也是求参数的一个依据.
七、残差分析
1.残差:对于响应变量 ,通过观测得到的数据称为观测值,通过经验回归方程得到的 称为预测值,观测值减
去预测值称为残差.
2.残差平方和为 .
3.决定系数 ...
资料整理【淘宝店铺:向阳百分百】八、独立性检验
1.列联表(2×2列联表)
一般地,假设有两个分类变量 和 ,它们的取值分别为 和 ,这种形式的数据统计表称为2×2
列联表.
合计
合计
2×2列联表给出了成对分类变量数据的交叉分类频数.
的计算公式: ,其中 为样本容量.
2.独立性检验
基于小概率值 的检验规则:
当 时,我们就推断 不成立,即认为 和 不独立,该推断犯错误的概率不超过 ;
当 时,我们没有充分证据推断 不成立,可以认为 和 独立.
这种利用 的取值推断分类变量 和 是否独立的方法称为 χ 2 独立性检验 ,读作“卡方独立性检验”,
简称独立性检验.
判断相关关系的两种方法:(1)散点图法,如果所有的样本点都落在某一函数的曲线附近,变量之间就有相
关关系;如果所有的样本点都落在某一直线附近,变量之间就有线性相关关系.(2)相关系数法,利用相关系数判
定,当 越趋近于1时,线性相关性越强.
线性回归分析问题的解题策略
(1)利用最小二乘估计公式,求出回归系数 ;
(2)利用经验回归直线过样本点的中心的性质求系数 ;
(3)写出经验回归方程,并利用经验回归方程进行预测.
非经验回归方程的求法:(1)根据原始数据 作出散点图;(2)根据散点图选择恰当的拟合函数;(3)作恰当的
变换,将其转化成线性函数,求经验回归方程;(4)在(3)的基础上通过相应变换,即可得非经验回归方程.
1.在2×2列联表中,如果两个变量没有关系,则应满足 越小,说明两个变量之间关
系越弱; 越大,说明两个变量之间关系越强.
2.解决独立性检验的应用问题,一定要按照独立性检验的步骤得出结论.独立性检验的一般步骤:
(1)根据样本数据制成2×2列联表.
(2)根据公式 计算 .
(3)通过比较 与临界值的大小关系来作统计推断.
考点一、随机抽样
1.(2019年全国统一高考数学试题(文科)(新课标Ⅰ))某学校为了解1 000名新生的身体素质,将这
些学生编号为1,2,…,1 000,从这些新生中用系统抽样方法等距抽取100名学生进行体质测验,若46
资料整理【淘宝店铺:向阳百分百】号学生被抽到,则下面4名学生中被抽到的是( )
A.8号学生 B.200号学生 C.616号学生 D.815号学生
【答案】C
【分析】等差数列的性质.渗透了数据分析素养.使用统计思想,逐个选项判断得出答案.
【详解】详解:由已知将1000名学生分成100个组,每组10名学生,用系统抽样,46号学生被抽到,
所以第一组抽到6号,且每组抽到的学生号构成等差数列 ,公差 ,所以 ,
若 ,则 ,不合题意;若 ,则 ,不合题意;
若 ,则 ,符合题意;若 ,则 ,不合题意.
【点睛】本题主要考查系统抽样.
2.某工厂利用随机数表对生产的700个零件进行抽样测试,先将700个零件进行编号,001,002,……,
699,700.从中抽取70个样本,下图提供随机数表的第4行到第6行,若从表中第5行第6列开始向右读取
数据,则得到的第6个样本编号是( )
3221183429 7864540732 5242064438 1223435677 3578905642
8442125331 3457860736 2530073286 2345788907 2368960804
3256780843 6789535577 3489948375 2253557832 4577892345
A.623 B.328 C.253 D.007
【答案】A
【分析】根据随机数表法依次读数即可.
【详解】解:从第5行第6列开始向又读取数据,
第一个数为253,第二个数是313,第三个数是457,
下一个数是860,不符合要求,下一个数是736,不符合要求,
下一个是253,重复,第四个是007,第五个是328,第六个是623.
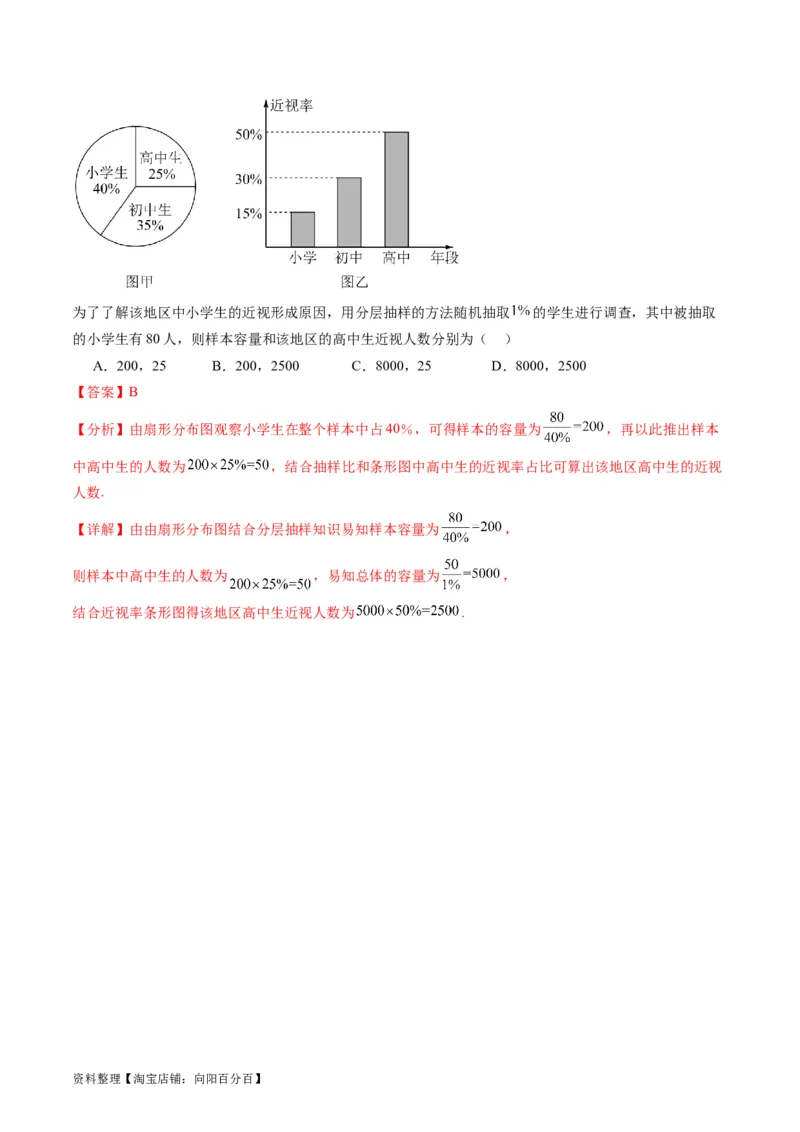
3.某高中学校学生人数和近视情况分别如图①和图②所示.为了解该学校学生近视形成原因,在近视的学
生中按年级用分层抽样的方法抽取部分学生进行问卷调查,已知抽取到的高中一年级的学生36人,则抽取
到的高三学生数为( )
A.32 B.45 C.64 D.90
【答案】D
【分析】根据近视率求出三个年级的近视的人数,结合抽样比例可得答案.
【详解】近视的学生中,高一、高二、高三学生数分别为180人,320人,450人,
资料整理【淘宝店铺:向阳百分百】由于抽取到的高一学生36人,
则抽取到的近视学生中高三人数为90人.
1.北京2022年冬奥会吉祥物“冰墩墩”和冬残奥会吉祥物“雪容融”很受欢迎,现工厂决定从20只“冰
墩墩”,15只“雪容融”和10个北京2022年冬奥会会徽中,采用比例分配分层随机抽样的方法,抽取一
个容量为n的样本进行质量检测,若“冰墩墩”抽取了4只,则n为( )
A.3 B.2 C.5 D.9
【答案】D
【分析】利用分层抽样中的比例列出方程,求出答案.
【详解】 ,解得:
2.从800件产品中抽取6件进行质检,利用随机数表法抽取样本时,先将800件产品按001,002,…,
800进行编号.如果从随机数表第8行第8列的数开始往右读数(随机数表第7行至第9行的数如下),则
抽取的6件产品的编号的75%分位数是( )
……
8442175331 5724550688 77047447672176335025 8392120676
6301637859 1695566711 69105671751286735807 4439523879
3321123429 7864560782 52420744381551001342 9966027954
A.105 B.556 C.671 D.169
【答案】C
【分析】由随机表及编号规则确定抽取的6件产品编号,再从小到大排序,应用百分位数的求法求75%分
位数.
【详解】由题设,依次读取的编号为 ,
根据编号规则易知:抽取的6件产品编号为 ,
所以将它们从小到大排序为 ,
故 ,所以75%分位数为 .
3.已知某地区中小学生人数比例和近视情况分别如图甲和图乙所示,
资料整理【淘宝店铺:向阳百分百】为了了解该地区中小学生的近视形成原因,用分层抽样的方法随机抽取 的学生进行调查,其中被抽取
的小学生有80人,则样本容量和该地区的高中生近视人数分别为( )
A.200,25 B.200,2500 C.8000,25 D.8000,2500
【答案】B
【分析】由扇形分布图观察小学生在整个样本中占40%,可得样本的容量为 ,再以此推出样本
中高中生的人数为 ,结合抽样比和条形图中高中生的近视率占比可算出该地区高中生的近视
人数.
【详解】由由扇形分布图结合分层抽样知识易知样本容量为 ,
则样本中高中生的人数为 ,易知总体的容量为 ,
结合近视率条形图得该地区高中生近视人数为 .
资料整理【淘宝店铺:向阳百分百】考点二、统计图表
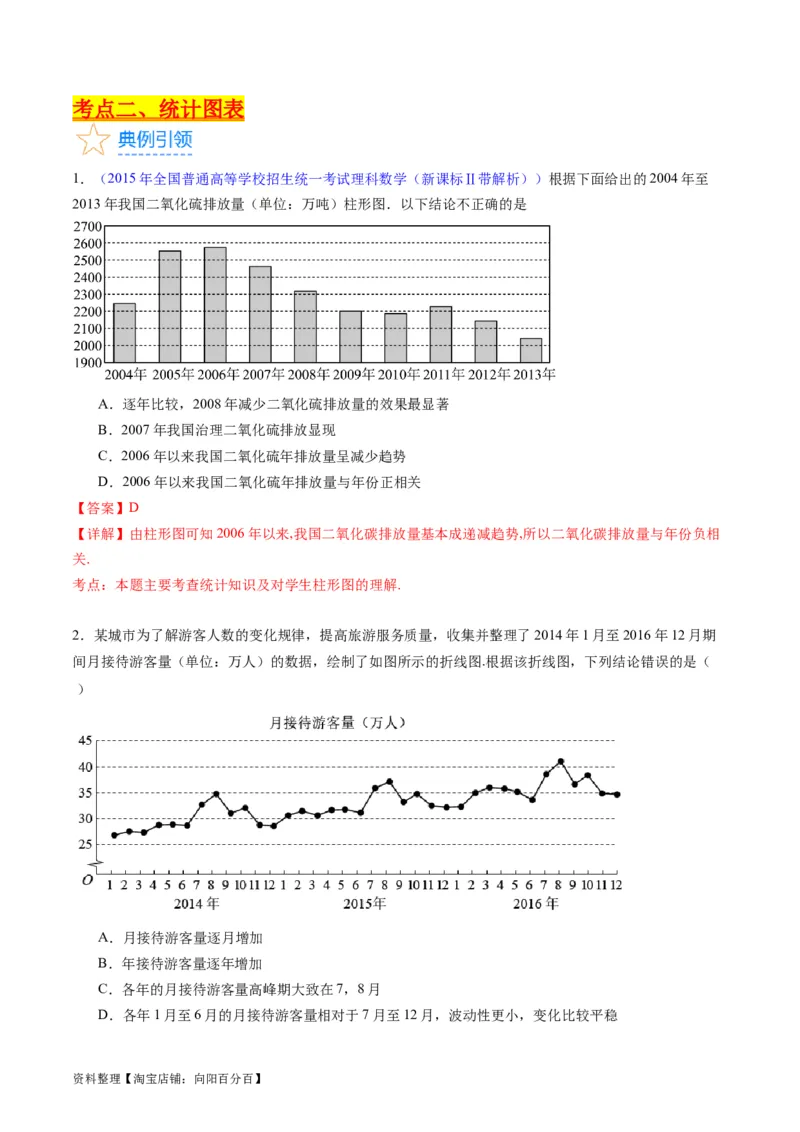
1.(2015年全国普通高等学校招生统一考试理科数学(新课标Ⅱ带解析))根据下面给出的2004年至
2013年我国二氧化硫排放量(单位:万吨)柱形图.以下结论不正确的是
A.逐年比较,2008年减少二氧化硫排放量的效果最显著
B.2007年我国治理二氧化硫排放显现
C.2006年以来我国二氧化硫年排放量呈减少趋势
D.2006年以来我国二氧化硫年排放量与年份正相关
【答案】D
【详解】由柱形图可知2006年以来,我国二氧化碳排放量基本成递减趋势,所以二氧化碳排放量与年份负相
关.
考点:本题主要考查统计知识及对学生柱形图的理解.
2.某城市为了解游客人数的变化规律,提高旅游服务质量,收集并整理了2014年1月至2016年12月期
间月接待游客量(单位:万人)的数据,绘制了如图所示的折线图.根据该折线图,下列结论错误的是(
)
A.月接待游客量逐月增加
B.年接待游客量逐年增加
C.各年的月接待游客量高峰期大致在7,8月
D.各年1月至6月的月接待游客量相对于7月至12月,波动性更小,变化比较平稳
资料整理【淘宝店铺:向阳百分百】【答案】A
【分析】观察折线图,结合选项逐一判断即可
【详解】对于选项A,由图易知月接待游客量每年7,8月份明显高于12月份,故A错;
对于选项B,观察折线图的变化趋势可知年接待游客量逐年增加,故B正确;
对于选项C,观察折线图,各年的月接待游客量高峰期大致在7,8月份,故C正确;
对于D选项,观察折线图,各年1月至6月的月接待游客量相对7月至12月,波动性更小,变化比较平稳,
故D正确.
3.(2018年全国普通高等学校招生统一考试理科数学(新课标I卷))某地区经过一年的新农村建设,农
村的经济收入增加了一倍.实现翻番.为更好地了解该地区农村的经济收入变化情况,统计了该地区新农
村建设前后农村的经济收入构成比例.得到如下饼图:
则下面结论中不正确的是
A.新农村建设后,种植收入减少
B.新农村建设后,其他收入增加了一倍以上
C.新农村建设后,养殖收入增加了一倍
D.新农村建设后,养殖收入与第三产业收入的总和超过了经济收入的一半
【答案】A
【分析】首先设出新农村建设前的经济收入为M,根据题意,得到新农村建设后的经济收入为2M,之后
从图中各项收入所占的比例,得到其对应的收入是多少,从而可以比较其大小,并且得到其相应的关系,
从而得出正确的选项.
【详解】设新农村建设前的收入为M,而新农村建设后的收入为2M,
则新农村建设前种植收入为0.6M,而新农村建设后的种植收入为0.74M,所以种植收入增加了,所以A项
不正确;
新农村建设前其他收入我0.04M,新农村建设后其他收入为0.1M,故增加了一倍以上,所以B项正确;
新农村建设前,养殖收入为0.3M,新农村建设后为0.6M,所以增加了一倍,所以C项正确;
新农村建设后,养殖收入与第三产业收入的总和占经济收入的 ,所以超过了经济
收入的一半,所以D正确;
点睛:该题考查的是有关新农村建设前后的经济收入的构成比例的饼形图,要会从图中读出相应的信息即
可得结果.
4.(2021年全国高考甲卷数学(理)试题)为了解某地农村经济情况,对该地农户家庭年收入进行抽样
调查,将农户家庭年收入的调查数据整理得到如下频率分布直方图:
资料整理【淘宝店铺:向阳百分百】根据此频率分布直方图,下面结论中不正确的是( )
A.该地农户家庭年收入低于4.5万元的农户比率估计为6%
B.该地农户家庭年收入不低于10.5万元的农户比率估计为10%
C.估计该地农户家庭年收入的平均值不超过6.5万元
D.估计该地有一半以上的农户,其家庭年收入介于4.5万元至8.5万元之间
【答案】C
【分析】根据直方图的意义直接计算相应范围内的频率,即可判定ABD,以各组的中间值作为代表乘以相
应的频率,然后求和即得到样本的平均数的估计值,也就是总体平均值的估计值,计算后即可判定C.
【详解】因为频率直方图中的组距为1,所以各组的直方图的高度等于频率.样本频率直方图中的频率即可
作为总体的相应比率的估计值.
该地农户家庭年收入低于4.5万元的农户的比率估计值为 ,故A正确;
该地农户家庭年收入不低于10.5万元的农户比率估计值为 ,故B正确;
该地农户家庭年收入介于4.5万元至8.5万元之间的比例估计值为 ,
故D正确;
该地农户家庭年收入的平均值的估计值为
(万元),超过6.5万元,故C错误.
综上,给出结论中不正确的是C.
【点睛】本题考查利用样本频率直方图估计总体频率和平均值,属基础题,样本的频率可作为总体的频率
的估计值,样本的平均值的估计值是各组的中间值乘以其相应频率然后求和所得值,可以作为总体的平均
值的估计值.注意各组的频率等于 .
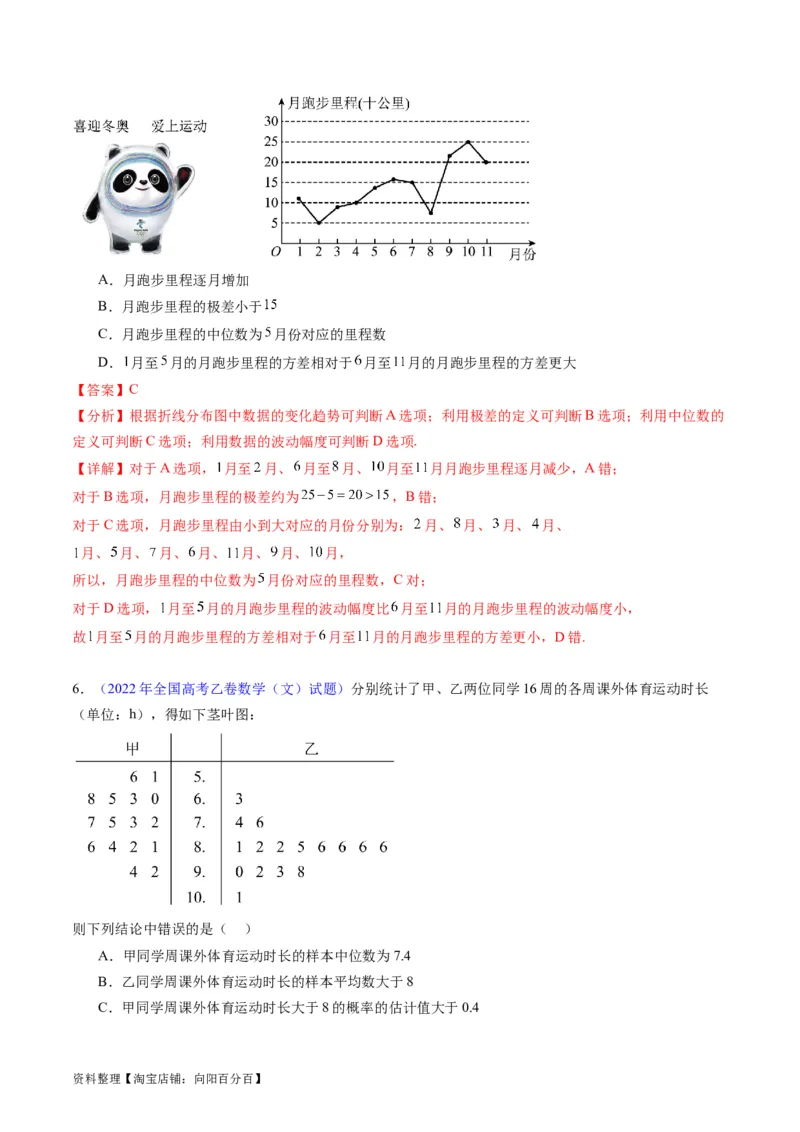
5.(2023届安徽省模拟数学试题)为迎接北京 年冬奥会,小王选择以跑步的方式响应社区开展的
“喜迎冬奥爱上运动”(如图)健身活动.依据小王 年 月至 年 月期间每月跑步的里程(单位:
十公里)数据,整理并绘制的折线图(如图),根据该折线图,下列结论正确的是( )
资料整理【淘宝店铺:向阳百分百】A.月跑步里程逐月增加
B.月跑步里程的极差小于
C.月跑步里程的中位数为 月份对应的里程数
D. 月至 月的月跑步里程的方差相对于 月至 月的月跑步里程的方差更大
【答案】C
【分析】根据折线分布图中数据的变化趋势可判断A选项;利用极差的定义可判断B选项;利用中位数的
定义可判断C选项;利用数据的波动幅度可判断D选项.
【详解】对于A选项, 月至 月、 月至 月、 月至 月月跑步里程逐月减少,A错;
对于B选项,月跑步里程的极差约为 ,B错;
对于C选项,月跑步里程由小到大对应的月份分别为: 月、 月、 月、 月、
月、 月、 月、 月、 月、 月、 月,
所以,月跑步里程的中位数为 月份对应的里程数,C对;
对于D选项, 月至 月的月跑步里程的波动幅度比 月至 月的月跑步里程的波动幅度小,
故 月至 月的月跑步里程的方差相对于 月至 月的月跑步里程的方差更小,D错.
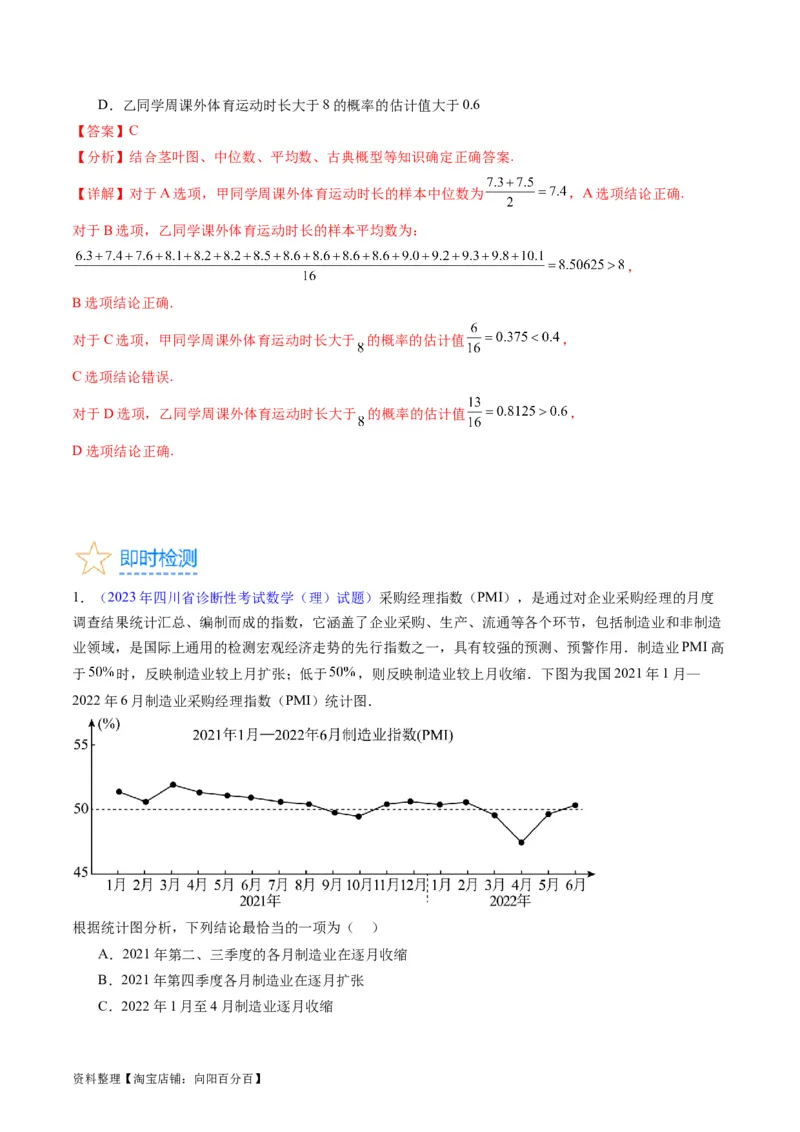
6.(2022年全国高考乙卷数学(文)试题)分别统计了甲、乙两位同学16周的各周课外体育运动时长
(单位:h),得如下茎叶图:
则下列结论中错误的是( )
A.甲同学周课外体育运动时长的样本中位数为7.4
B.乙同学周课外体育运动时长的样本平均数大于8
C.甲同学周课外体育运动时长大于8的概率的估计值大于0.4
资料整理【淘宝店铺:向阳百分百】D.乙同学周课外体育运动时长大于8的概率的估计值大于0.6
【答案】C
【分析】结合茎叶图、中位数、平均数、古典概型等知识确定正确答案.
【详解】对于A选项,甲同学周课外体育运动时长的样本中位数为 ,A选项结论正确.
对于B选项,乙同学课外体育运动时长的样本平均数为:
,
B选项结论正确.
对于C选项,甲同学周课外体育运动时长大于 的概率的估计值 ,
C选项结论错误.
对于D选项,乙同学周课外体育运动时长大于 的概率的估计值 ,
D选项结论正确.
1.(2023年四川省诊断性考试数学(理)试题)采购经理指数(PMI),是通过对企业采购经理的月度
调查结果统计汇总、编制而成的指数,它涵盖了企业采购、生产、流通等各个环节,包括制造业和非制造
业领域,是国际上通用的检测宏观经济走势的先行指数之一,具有较强的预测、预警作用.制造业PMI高
于 时,反映制造业较上月扩张;低于 ,则反映制造业较上月收缩.下图为我国2021年1月—
2022年6月制造业采购经理指数(PMI)统计图.
根据统计图分析,下列结论最恰当的一项为( )
A.2021年第二、三季度的各月制造业在逐月收缩
B.2021年第四季度各月制造业在逐月扩张
C.2022年1月至4月制造业逐月收缩
资料整理【淘宝店铺:向阳百分百】D.2022年6月PMI重回临界点以上,制造业景气水平呈恢复性扩张
【答案】D
【分析】根据题意,将各个月的制造业指数与 比较,即可得到答案.
【详解】对于A项,由统计图可以得到,只有9月份的制造业指数低于 ,故A项错误;
对于B项,由统计图可以得到,10月份的制造业指数低于 ,故B项错误;
对于C项,由统计图可以得到,1、2月份的制造业指数高于 ,故C项错误;
对于D项,由统计图可以得到,从4月份的制造业指数呈现上升趋势,且在2022年6月PMI超过 ,
故D项正确.
2.小张一星期的总开支分布如图所示,一星期的食品开支如图所示,则小张一星期的肉类开支占总开支
的百分比约为( )
A.10% B.8% C.5% D.4%
【答案】A
【分析】求出肉类开支为100元,占食品开支的 ,再由食品开支占总开支的 ,进而求得小张一星期
的肉类开支占总开支的百分比.
【详解】由题图②知,小张一星期的食品开支为 元,
其中肉类开支为100元,占食品开支的 ,而食品开支占总开支的 ,
所以小张一星期的肉类开支占总开支的百分比为 .
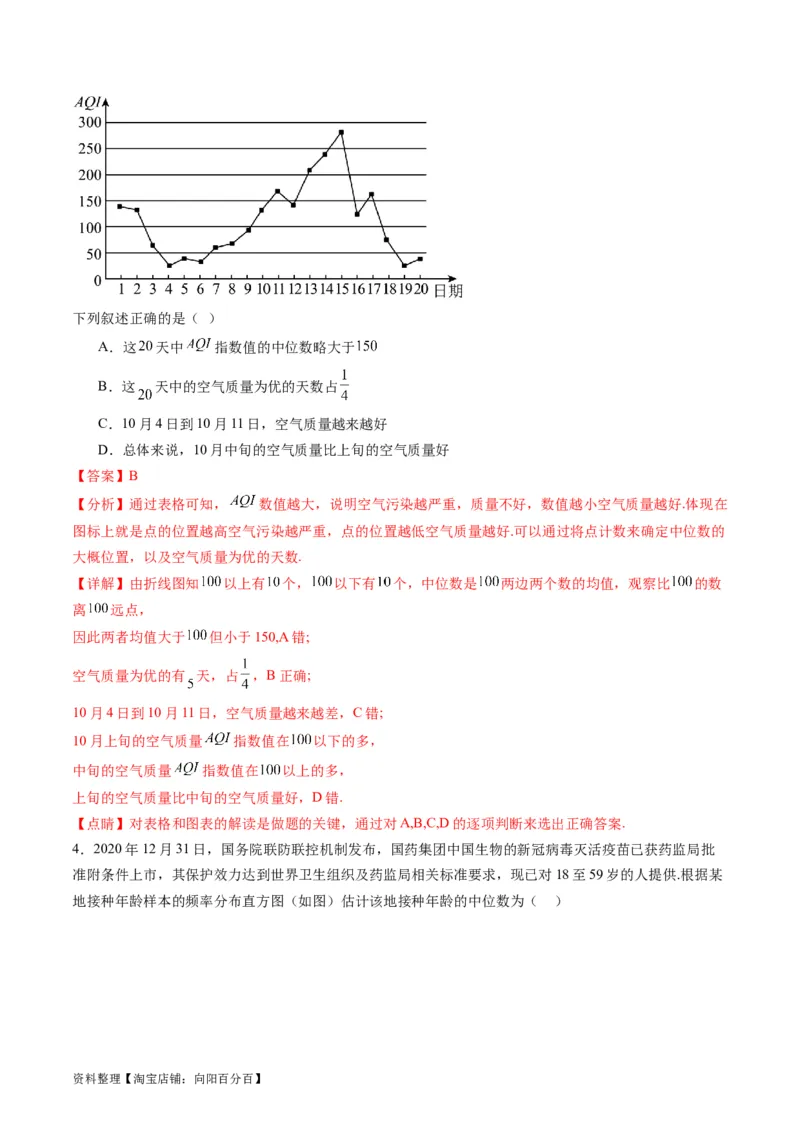
3.空气质量指数 是反映空气质量状况的指数,其对应关系如下表:
指数值
空气质量 优 良 轻度污染 中度污染 重度污染 严重污染
为监测某化工厂排放废气对周边空气质量指数的影响,某科学兴趣小组在校内测得10月1日—20日
指数的数据并绘成折线图如下:
资料整理【淘宝店铺:向阳百分百】下列叙述正确的是( )
A.这 天中 指数值的中位数略大于
B.这 天中的空气质量为优的天数占
C.10月4日到10月11日,空气质量越来越好
D.总体来说,10月中旬的空气质量比上旬的空气质量好
【答案】B
【分析】通过表格可知, 数值越大,说明空气污染越严重,质量不好,数值越小空气质量越好.体现在
图标上就是点的位置越高空气污染越严重,点的位置越低空气质量越好.可以通过将点计数来确定中位数的
大概位置,以及空气质量为优的天数.
【详解】由折线图知 以上有 个, 以下有 个,中位数是 两边两个数的均值,观察比 的数
离 远点,
因此两者均值大于 但小于150,A错;
空气质量为优的有 天,占 ,B正确;
10月4日到10月11日,空气质量越来越差,C错;
10月上旬的空气质量 指数值在 以下的多,
中旬的空气质量 指数值在 以上的多,
上旬的空气质量比中旬的空气质量好,D错.
【点睛】对表格和图表的解读是做题的关键,通过对A,B,C,D的逐项判断来选出正确答案.
4.2020年12月31日,国务院联防联控机制发布,国药集团中国生物的新冠病毒灭活疫苗已获药监局批
准附条件上市,其保护效力达到世界卫生组织及药监局相关标准要求,现已对18至59岁的人提供.根据某
地接种年龄样本的频率分布直方图(如图)估计该地接种年龄的中位数为( )
资料整理【淘宝店铺:向阳百分百】A.40 B.39 C.38 D.37
【答案】C
【分析】利用中位数左右两边的小矩形的面积都等于 即可求解.
【详解】年龄位于 的频率为 ,
年龄位于 的频率为 ,
年龄位于 的频率为 ,
年龄位于 的频率为 ,因为 ,而
,所以中位数位于 ,设中位数为 ,
则 ,
解得: .
5.传承传统文化再掀热潮,我校举行传统文化知识竞赛.其中两位选手在个人追逐赛中的比赛得分如茎叶图
所示,则下列说法正确的是( )
A.甲的平均数大于乙的平均数
B.甲的中位数大于乙的中位数
C.甲的方差大于乙的方差
D.甲的平均数等于乙的中位数
【答案】C
【分析】由茎叶图分别计算出甲和乙的平均数,方差和中位数即可判断选项
资料整理【淘宝店铺:向阳百分百】【详解】对于A,由茎叶图知甲的平均数为 ,
乙的平均数为 ,故A错误;
对于B和D,甲的中位数为26,乙的中位数为28,故BD错误;
对于C,甲的方差为 ,
乙的方差为 ,
故C正确.
考点三、用样本估计总体
1.某地统计局就该地居民的月收入调查了10000人,并根据所得数据画了样本的频率分布直方图(每个分
组包括左端点,不包括右端点,如第一组表示收入在 .
(1)求居民月收入在 的频率;
(2)根据频率分布直方图算出样本数据的中位数;
(3)为了分析居民的收入与年龄、职业等方面的关系,必须按月收入再从这10000人中用分层抽样方法抽出
100人作进一步分析,则月收入在 的这段应抽多少人?
【答案】(1)0.15;(2)2400元;(3)25人;
【分析】(1)根据图中 所对应的频率/组距的值,乘上组距,即可得到月收入在 的频
率.
(2)通过比较几个区间的频率之和与0.5的关系,判断出中位数所在区间,进而求出样本数据的中位数.
(3)根据表格先居民月收入在 的频率,接着计算10000人中月收入在 的人数,再
根据分层抽样抽出100人,计算得出月收入在 的这段应抽取的人数.
【详解】(1)月收入在 的频率为:
资料整理【淘宝店铺:向阳百分百】∴居民月收入在 的频率为0.15.
(2) ,
,
,
,
∴样本数据的中位数为
∴样本数据的中位数为2400元.
(3)居民月收入在 的频率为:
,
∴10000人中月收入在 的人数为:
,
再从10000人中分层抽样方法抽出100人,
则月收入在 的这段应抽取:
,∴月收入在 的这段应抽25人.
2.(2015年全国普通高等学校招生统一考试文科数学(广东卷))某城市 户居民的月平均用电量(单
位:度),以 , , , , , , 分组的频
率分布直方图如图.
(1)求直方图中 的值;
(2)求月平均用电量的众数和中位数;
(3)在月平均用电量为 , , , 的四组用户中,用分层抽样的方法
抽取11户居民,则月平均用电量在 的用户中应抽取多少户?
【答案】(1) ;(2) , ;(3) .
【详解】试题分析:(1)由直方图的性质可得(0.002+0.0095+0.011+0.0125+x+0.005+0.0025)×20=1,解
资料整理【淘宝店铺:向阳百分百】方程可得;(2)由直方图中众数为最高矩形上端的中点可得,可得中位数在[220,240)内,设中位数为
a,解方程(0.002+0.0095+0.011)×20+0.0125×(a-220)=0.5可得;(3)可得各段的用户分别为25,15,
10,5,可得抽取比例,可得要抽取的户数
试题解析:(1)由直方图的性质可得(0.002+0.0095+0.011+0.0125+x+0.005+0.0025)×20=1得:
x=0.0075,所以直方图中x的值是0.0075. ------------- 3分
(2)月平均用电量的众数是 =230. ------------- 5分
因为(0.002+0.0095+0.011)×20=0.45<0.5,所以月平均用电量的中位数在[220,240)内,
设中位数为a,
由(0.002+0.0095+0.011)×20+0.0125×(a-220)=0.5
得:a=224,所以月平均用电量的中位数是224. ------------ 8分
(3)月平均用电量为[220,240)的用户有0.0125×20×100=25户,
月平均用电量为[240,260)的用户有0.0075×20×100=15户,
月平均用电量为[260,280)的用户有0. 005×20×100=10户,
月平均用电量为[280,300]的用户有0.0025×20×100=5户, -------------10分
抽取比例= = ,所以月平均用电量在[220,240)的用户中应抽取25× =5户.-- 12分
考点:频率分布直方图及分层抽样.
3.“2021年全国城市节约用水宣传周”已于5月9日至15日举行、成都市围绕“贯彻新发展理念,建设
节水型城市”这一主题,开展了形式多样,内容丰富的活动,进一步增强全民保护水资源,防治水污染,
节约用水的意识.为了解活动开展成效,某街道办事处工作人员赴一小区调查住户的节约用水情况,随机抽
取了300.名业主进行节约用水调查评分,将得到的分数分成6组: , , , ,
, ,得到如图所示的频率分布直方图.
(1)求a的值,并估计这300名业主评分的众数和中位数;
(2)若先用分层抽样的方法从评分在 和 的业主中抽取5人,然后再从抽出的这5位业主中任
资料整理【淘宝店铺:向阳百分百】意选取2人作进一步访谈:
①写出这个试验的样本空间;
②求这2人中至少有1人的评分在 概率.
【答案】(1) ;众数为 ;中位数为 ;
(2) , , , , , , , , , ;
【分析】(1)由频率分布直方图的的性质,所有小矩形的面积之和为1,可解得 的值,由中位数的定义,
找到频率之和为 的点,众数估计值为最高小矩形的中点;
(2)首先根据两个分组的人数之比,采用分层抽样的方法,得到每个分组抽取的人数,根据古典概型的
概率计算公式求解即可
【详解】(1) 第三组的频率为 ,
又第一组的频率为 ,第二组的频率为 ,第三组的频率为 .
前三组的频率之和为 ,
这 名业主评分的中位数为 .
众数为 .
(2)由频率分布直方图,知评分在 的人数与评分在 的人数的比值为 .
采用分层抽样法抽取 人,评分在 的有 人,评分在 有 人.
不妨设评分在 的 人分别为 ;评分在 的 人分别为 ,
这个试验的样本空间为:
, , , , , , , , , ;
②从 人中任选 人的所有可能情况有共 种.
其中选取的 人中至少有 人的评分在 的情况有:
, , , , , , 共 种.
故这 人中至少有 人的评分在 的概率为 .
4.某超市计划按月订购一种酸奶,每天进货量相同,进货成本每瓶4元,售价每瓶6元,未售出的酸奶降
价处理,以每瓶2元的价格当天全部处理完.根据往年销售经验,每天需求量与当天最高气温(单位:
℃)有关.如果最高气温不低于25,需求量为500瓶;如果最高气温位于区间[20,25),需求量为300瓶;
如果最高气温低于20,需求量为200瓶.为了确定六月份的订购计划,统计了前三年六月份各天的最高气
资料整理【淘宝店铺:向阳百分百】温数据,得下面的频数分布表:
最高气
[10,15) [15,20) [20,25) [25,30) [30,35) [35,40)
温
天数 2 16 36 25 7 4
以最高气温位于各区间的频率估计最高气温位于该区间的概率.(1)求六月份这种酸奶一天的需求量不
超过300瓶的概率;
(2)设六月份一天销售这种酸奶的利润为Y(单位:元),当六月份这种酸奶一天的进货量为450瓶时,
写出Y的所有可能值,并估计Y大于零的概率.
【答案】(1) .(2) .
【分析】(1)由前三年六月份各天的最高气温数据,求出最高气温位于区间[20,25)和最高气温低于20
的天数,由此能求出六月份这种酸奶一天的需求量不超过300瓶的概率.
(2)当温度大于等于25℃时,需求量为500,求出Y=900元;当温度在[20,25)℃时,需求量为300,
求出Y=300元;当温度低于20℃时,需求量为200,求出Y=﹣100元,从而当温度大于等于20时,Y>
0,由此能估计估计Y大于零的概率.
【详解】解:(1)由前三年六月份各天的最高气温数据,
得到最高气温位于区间[20,25)和最高气温低于20的天数为2+16+36=54,
根据往年销售经验,每天需求量与当天最高气温(单位:℃)有关.
如果最高气温不低于25,需求量为500瓶,
如果最高气温位于区间[20,25),需求量为300瓶,
如果最高气温低于20,需求量为200瓶,
∴六月份这种酸奶一天的需求量不超过300瓶的概率p .
(2)当温度大于等于25℃时,需求量为500,
Y=450×2=900元,
当温度在[20,25)℃时,需求量为300,
Y=300×2﹣(450﹣300)×2=300元,
当温度低于20℃时,需求量为200,
Y=400﹣(450﹣200)×2=﹣100元,
当温度大于等于20时,Y>0,
由前三年六月份各天的最高气温数据,得当温度大于等于20℃的天数有:
90﹣(2+16)=72,
∴估计Y大于零的概率P .
【点睛】本题考查概率的求法,考查利润的所有可能取值的求法,考查函数、古典概型等基础知识,考查
推理论证能力、运算求解能力、空间想象能力,考查数形结合思想、化归与转化思想,是中档题.
资料整理【淘宝店铺:向阳百分百】资料整理【淘宝店铺:向阳百分百】1. 年 月 日,我国实施“全国二孩”政策,中国社会科学院在某地随机抽取了 名已婚男性,其中
愿意生育二孩的有 名,经统计,该 名男性的年龄情况对应的频率分布直方图如下:
(1)根据频率分布直方图,估计这 名已婚男性的年龄平均值 、众数和样本方差 (同组数据用区间的
中点值代替,结果精确到个位);
(2)若在愿意生育二孩的且年龄在 、 、 的三组已婚男性中,用分层抽样的方法抽取
人,试估计每个年龄段应各抽取多少人?
【答案】(1)平均值36、众数为 ,方差25
(2)人数分别为 人、 人、 人.
【分析】(1)利用频率分布直方图的平均数,方差公式及众数定义直接求解即可;
(2)利用分层抽样的定义求解即可.
【详解】(1)已婚男性的平均年龄 和样本方差 分别为:
,
,众数为 .
(2)在年龄段 、 、 的频率分别为 、 、 ,
,∴人数分别为 人、 人、 人.
资料整理【淘宝店铺:向阳百分百】2.(2023届北京市模拟数学试题)2023年9月23日至2023年10月8日,第19届亚运会将在中国杭州举
行.杭州某中学高一年级举办了“亚运在我心”的知识竞赛,其中1班,2班,3班,4班报名人数如下:
班号 1 2 3 4
3
人数 40 20 10
0
该年级在报名的同学中按分层抽样的方式抽取10名同学参加竞赛,每位参加竞赛的同学从预设的10个题
目中随机抽取4个作答,至少答对3道的同学获得一份奖品.假设每位同学的作答情况相互独立.
(1)求各班参加竞赛的人数;
(2)2班的小张同学被抽中参加竞赛,若该同学在预设的10个题目中恰有3个答不对,记他答对的题目数为
,求 的分布列及数学期望;
(3)若1班每位参加竞赛的同学答对每个题目的概率均为 ,求1班参加竞赛的同学中至少有1位同学获得
奖品的概率.
【答案】(1)3,4,2,1
(2)分布列见解析,2.8
(3)
【分析】(1)根据分层抽样计算可得;
(2)根据超几何分布求出概率,列出分布列求期望即可得解;
(3)计算1班每位同学获奖的概率,然后根据二项分布求解即可.
【详解】(1)各班报名人数总共100人,抽取10人,抽样比为 ,
故 班分别抽取 (人), (人), (人), (人).
(2)由题意, 的可能取值为1,2,3,4,
,
,
,
,
所以 的分布列为:
1 2 3 4
资料整理【淘宝店铺:向阳百分百】(3)由题意,1班每位同学获奖的概率为
,
设1班获奖人数为 ,则 ,
所以至少1人获奖的概率为 .
3.为了切实维护居民合法权益,提高居民识骗防骗能力,守好居民的“钱袋子”,某社区开展“全民反
诈在行动——反诈骗知识竞赛”活动,现从参加该活动的居民中随机抽取了100名,统计出他们竞赛成绩
分布如下:
成绩
(分)
人数 2 4 22 40 28 4
(1)求抽取的100名居民竞赛成绩的平均分 和方差 (同一组中数据用该组区间的中点值为代表);
(2)以频率估计概率,发现该社区参赛居民竞赛成绩X近似地服从正态分布 ,其中 近似为样本成
绩平均分 , 近似为样本成绩方差 ,若 ,参赛居民可获得“参赛纪念证书”;若
,参赛居民可获得“反诈先锋证书”,
①若该社区有3000名居民参加本次竞赛活动,试估计获得“参赛纪念证书”的居民人数(结果保留整数);
②试判断竞赛成绩为96分的居民能否获得“反诈先锋证书”.
附:若 ,则 , ,
.
【答案】(1) ,
(2)①2456 ;②能
【分析】(1)利用公式直接求出均值、方差即可;
(2)①结合给的概率和正态分布的性质,确定获得“参赛纪念证书”,进而计算可得人数;
②利用正态分布的知识求出 ,即 ,进而可得结果.
【详解】(1)100名居民本次竞赛成绩平均分
资料整理【淘宝店铺:向阳百分百】,
100名居民本次竞赛成绩方差
,
(2)①由于 近似为样本成绩平均分 , 近似为样本成绩方差 ,
所以, ,
可知, ,
由于竞赛成绩X近似地服从正态分布 ,
因此竞赛居民可获得“参赛纪念证书”的概率
估计获得“参赛纪念证书”的居民人数为2456;
②当 时,即 时,参赛居民可获得“反诈先锋证书”,
所以竞赛成绩为96分的居民能获得“反诈先峰证书”.
4.某公司为了解用户对其产品的满意度,从 , 两地区分别随机调查了20个用户,得到用户对产品的
满意度评分如下:
地区:62 73 81 92 95 85 74 64 53 76
78 86 95 66 97 78 88 82 76 89
地区:73 83 62 51 91 46 53 73 64 82
93 48 65 81 74 56 54 76 65 79
(1)根据两组数据完成两地区用户满意度评分的茎叶图,并通过茎叶图比较两地区满意度评分的平均值及分
散程度(不要求计算出具体值,得出结论即可);
资料整理【淘宝店铺:向阳百分百】(2)根据用户满意度评分,将用户的满意度从低到高分为三个等级:
满意度评分 低于70分 70分到89分 不低于90分
满意度等级 不满意 满意 非常满意
记事件 :“ 地区用户的满意度等级高于 地区用户的满意度等级”.假设两地区用户的评价结果相互
独立.根据所给数据,以事件发生的频率作为相应事件发生的概率,求 的概率.
【答案】(1)答案见解析;
(2) .
【分析】(1)根据题目数据以及茎叶图的画法,作出茎叶图,根据茎叶图直接比较可得出对应平均值及
分散程度.
(2)记 表示事件:“A地区用户满意度等级为满意或非常满意”; 表示事件:“A地区用户满意度
等级为非常满意”; 表示事件:“B地区用户满意度等级为不满意”; 表示事件:“B地区用户满
意度等级为满意”.则 ,根据概率的互斥和对立以及概率的运算公式,计算即可.
(1)两地区用户满意度评分的茎叶图如下
通过茎叶图可以看出,A地区用户满意度评分的平均值高于B地区用户满意度评分的平均值;A地区用户
满意度评分比较集中,B地区用户满意度评分比较分散.
(2)记 表示事件:“A地区用户满意度等级为满意或非常满意”; 表示事件:“A地区用户满意度
等级为非常满意”; 表示事件:“B地区用户满意度等级为不满意”; 表示事件:“B地区用户满
意度等级为满意”.则 与 独立, 与 独立, 与 互斥, .
.由所给数据得 ,
, , 发生的概率分别为 , , , .故 , , ,
,故 .
资料整理【淘宝店铺:向阳百分百】考点四、成对数据的相关性分析
1.(2023年新高考天津数学高考真题)调查某种群花萼长度和花瓣长度,所得数据如图所示,其中相关
系数 ,下列说法正确的是( )
A.花瓣长度和花萼长度没有相关性
B.花瓣长度和花萼长度呈现负相关
C.花瓣长度和花萼长度呈现正相关
D.若从样本中抽取一部分,则这部分的相关系数一定是
【答案】C
【分析】根据散点图的特点可分析出相关性的问题,从而判断ABC选项,根据相关系数的定义可以判断D
选项.
【详解】根据散点的集中程度可知,花瓣长度和花萼长度有相关性,A选项错误
散点的分布是从左下到右上,从而花瓣长度和花萼长度呈现正相关性,B选项错误,C选项正确;
由于 是全部数据的相关系数,取出来一部分数据,相关性可能变强,可能变弱,即取出的数据
的相关系数不一定是 ,D选项错误
2.(2023届浙江省教学质量检测(二模)数学试题)某兴趣小组研究光照时长x(h)和向日葵种子发芽
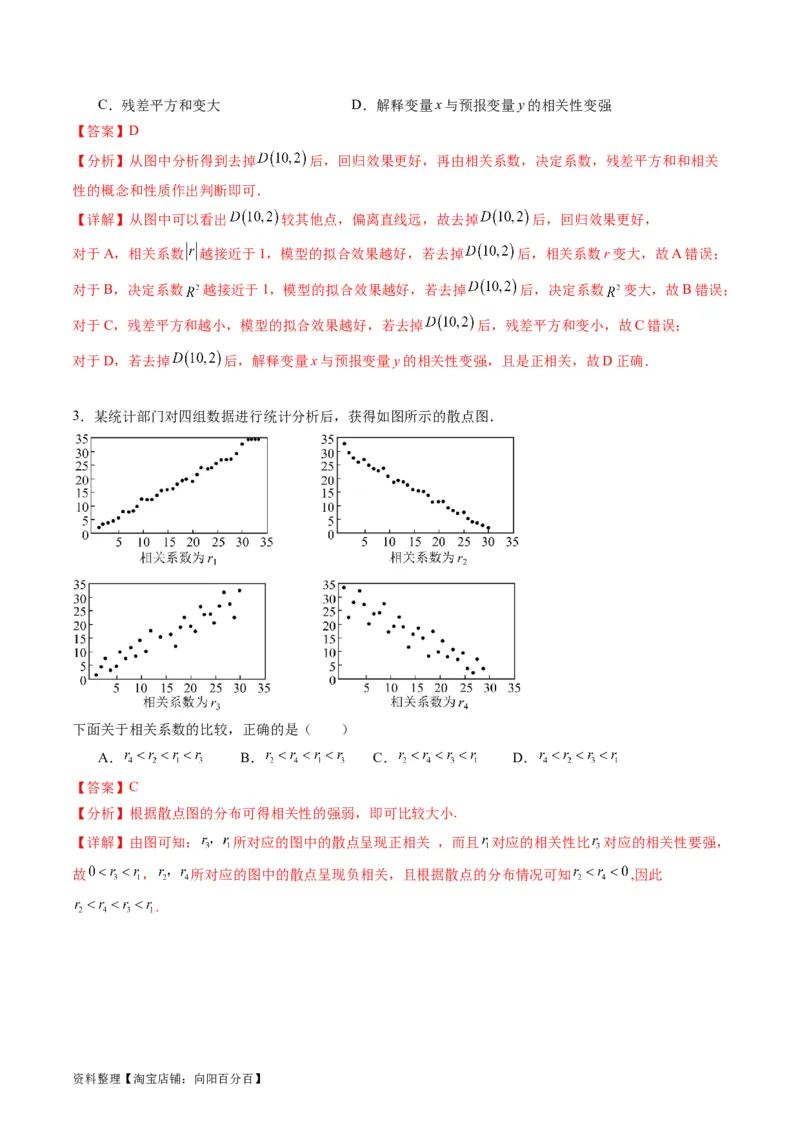
数量y(颗)之间的关系,采集5组数据,作如图所示的散点图.若去掉 后,下列说法正确的是
( )
A.相关系数r变小 B.决定系数 变小
资料整理【淘宝店铺:向阳百分百】C.残差平方和变大 D.解释变量x与预报变量y的相关性变强
【答案】D
【分析】从图中分析得到去掉 后,回归效果更好,再由相关系数,决定系数,残差平方和和相关
性的概念和性质作出判断即可.
【详解】从图中可以看出 较其他点,偏离直线远,故去掉 后,回归效果更好,
对于A,相关系数 越接近于1,模型的拟合效果越好,若去掉 后,相关系数r变大,故A错误;
对于B,决定系数 越接近于1,模型的拟合效果越好,若去掉 后,决定系数 变大,故B错误;
对于C,残差平方和越小,模型的拟合效果越好,若去掉 后,残差平方和变小,故C错误;
对于D,若去掉 后,解释变量x与预报变量y的相关性变强,且是正相关,故D正确.
3.某统计部门对四组数据进行统计分析后,获得如图所示的散点图.
下面关于相关系数的比较,正确的是( )
A. B. C. D.
【答案】C
【分析】根据散点图的分布可得相关性的强弱,即可比较大小.
【详解】由图可知: 所对应的图中的散点呈现正相关 ,而且 对应的相关性比 对应的相关性要强,
故 , 所对应的图中的散点呈现负相关,且根据散点的分布情况可知 ,因此
.
资料整理【淘宝店铺:向阳百分百】4.如下是一个2×2列联表,则 .
y
x 合计
x a 35 45
1
x 7 b n
2
合计 m 73 s
【答案】62
【分析】利用2×2列联表求解.
【详解】根据2×2列联表可知 ,
解得 ,
则 ,
又由 ,解得 ,
则 ,
故 .
5.针对时下的“短视频热”,某高校团委对学生性别和喜欢短视频是否有关联进行了一次调查,其中被
调查的男生、女生人数均为 人,男生中喜欢短视频的人数占男生人数的 ,女生中喜欢短视频
的人数占女生人数的 .零假设为 :喜欢短视频和性别相互独立.若依据 的独立性检验认为喜欢
短视频和性别不独立,则 的最小值为( )
附: ,附表:
0.05 0.01
3.841 6.635
A.7 B.8 C.9 D.10
【答案】C
【分析】依题意,写出 列联表中的 ,算出 的数值,和表格中的参照数据比较后选出答案.
【详解】根据题意,不妨设 ,于是
资料整理【淘宝店铺:向阳百分百】,由于依据 的独立性检验认为喜欢短视频
和性别不独立,根据表格可知 ,解得 ,于是 最小值为 .
6.为了考察某种药物预防疾病的效果,进行动物试验,得到如下列联表:
疾病
药物 合计
未患病 患病
服用 a 50-a 50
未服
80-a a-30 50
用
合计 80 20 100
若在本次考察中得出“在犯错误的概率不超过0.01的前提下认为药物有效”的结论,则a的最小值为
(其中a≥40且a∈ )(参考数据: ≈2.58, ≈3.29)
参考公式
临界值表
0.50 0.40 0.25 0.15 0.10 0.05 0.025 0.010 0.005 0.001
0.455 0.708 1.323 2.072 2.706 3.841 5.024 6.635 7.879 10.828
【答案】46
【分析】根据题意求得 ,即可求出a的最小值.
【详解】解:由题意可得 ,
整理得: ,
所以 或 ,
解得: 或 ,
又因为a≥40且a∈ ,
所以 ,
所以a的最小值为46.
资料整理【淘宝店铺:向阳百分百】1.用模型 拟合一组数 ,若 , ,设 ,
得变换后的线性回归方程为 ,则 ( )
A.12 B. C. D.7
【答案】B
【分析】由已知,可根据 , 先计算出 ,然后把样本中心点带入线性
回归方程为 中计算出 ,从而得到线性回归方程,然后将方程化为指数形式,通过待定系数法分
别对应出 、 的值,即可完成求解.
【详解】由已知, ,所以 ,
, ,所以
,
由题意, 满足线性回归方程为 ,所以 ,所以 ,
此时线性回归方程为 ,即 ,
可将此式子化为指数形式 ,即为 ,
因为模型为模型 ,所以 , ,
所以 .
2.已知变量 , 的关系可以用模型 拟合,设 ,其变换后得到一组数据如下:
4 6 8 10
2 3 5 6
由上表可得线性回归方程 ,则 .
【答案】 /
【分析】根据表格数据求 ,代入回归方程求参数a,结合 得 ,由方程的形式可知
,即可求c.
资料整理【淘宝店铺:向阳百分百】【详解】由表格数据知: .
由 ,得 ,则 .
∴ ,
由 ,得 ,
∴ ,即 .
3.某部门通过随机调查89名工作人员的休闲方式是读书还是健身得到的数据如下表:
单位:人
读书 健身 合计
女 24 31 55
男 8 26 34
合计 32 57 89
在犯错误的概率不超过 的前提下认为性别与休闲方式有关系.
附表:
0.1 0.05 0.01 0.005 0.001
2.706 3.841 6.635 7.879 10.828
【答案】0.1/
【分析】计算卡方,进行独立性检验.
【详解】由题中列联表中的数据,得 ,
因为 ,所以在犯错误的概率不超过0.1的前提下认为性别与休闲方式有关系.
4.2020年2月,全国掀起了“停课不停学”的热潮,各地教师通过网络直播、微课推送等多种方式来指导
学生线上学习.为了调查学生对网络课程的热爱程度,研究人员随机调查了相同数量的男、女学生,发现有
80%的男生喜欢网络课程,有40%的女生不喜欢网络课程,且有99%的把握但没有99.9%的把握认为是否
喜欢网络课程与性别有关,则被调查的男、女学生总数量可能为( )
附: ,其中 .
0.1 0.05 0.01 0.001
2.706 3.841 6.635 10.828
A.130 B.190 C.240 D.250
资料整理【淘宝店铺:向阳百分百】【答案】B
【分析】设男、女学生的人数都为 ,则男、女学生的总人数为 ,建立 列联表,由独立性检验算
出 ,结合观测值和选项可得答案.
【详解】依题意,设男、女学生的人数都为 ,则男、女学生的总人数为 ,建立 列联表如下,
喜欢网络课
不喜欢网络课程 总计
程
男生
女生
总计
故 ,由题意可得 ,
所以 ,结合选项可知,只有B符合题意.
5.在某大学一食品超市,随机询问了70名不同性别的大学生在购买食物时是否查看营养说明,得到如下
的列联表:
女 男 总计
要查看营养说
15 25 40
明
不查看营养说
20 10 30
明
总计 35 35 70
附: ,其中 .
0.50 0.40 0.25 0.15 0.10 0.05 0.025 0.010 0.005
0.455 0.708 1.323 2.072 2.706 3.841 5.024 6.635 7.879
根据列联表的独立性检验,则下列说法正确的是( ).
A.在犯错误的概率不超过0.05的前提下认为该校大学生在购买食物时要查看营养说明的人数中男生
人数更多
B.在犯错误的概率不超过0.010的前提下认为该校女大学生在购买食物时要查看营养说明的人数与不
查看营养说明的人数比为
C.在犯错误的概率不超过0.025的前提下认为性别与是否查看营养说明有关系
资料整理【淘宝店铺:向阳百分百】D.在犯错误的概率不超过0.010的前提下认为性别与是否查看营养说明有关系
【答案】C
【分析】由题可得 ,进而即得.
【详解】由题可得 ,
∴在犯错误的概率不超过0.025的前提下认为性别与是否查看营养说明有关系.
6.有甲、乙两个班级共计105人进行数学考试,按照大于等于85分为优秀,85分以下为非优秀统计成绩,
得到如下所示的列联表:
优秀 非优秀 总计
甲班 10 b
乙班 c 30
已知在全部105人中随机抽取1人,成绩优秀的概率为 ,则下列说法正确的是 .
①列联表中c的值为30,b的值为35;
②列联表中c的值为20,b的值为45;
③根据列联表中的数据,若按95%的可靠性要求,能认为“成绩与班级有关系”;
④根据列联表中的数据,若按95%的可靠性要求,不能认为“成绩与班级有关系”.
【答案】②③/
【分析】根据题意可计算出成绩优秀的学生数,从而求得c,继而求得b,判断①②;根据列联表数据计算
的值并与临界值表中数据进行比较,即可判断③④.
【详解】由题意得在全部105人中随机抽取1人,成绩优秀的概率为 ,
则成绩优秀的学生有 人,甲班有10人,则乙班20人,即c=20,
成绩非优秀的学生有75人,乙班由30人,则甲班哟有45人,即b=45,
故①错误,②正确;
由列联表可得 ,
故按95%的可靠性要求,能认为“成绩与班级有关系”, ③正确,④错误;
故答案为:②③
资料整理【淘宝店铺:向阳百分百】考点 五 、回归分析
1.(2020年全国统一高考数学试题(文科)(新课标Ⅱ))某沙漠地区经过治理,生态系统得到很大改
善,野生动物数量有所增加.为调查该地区某种野生动物的数量,将其分成面积相近的200个地块,从这些
地块中用简单随机抽样的方法抽取20个作为样区,调查得到样本数据(xi,yi)(i=1,2,…,20),其中xi和
yi分别表示第i个样区的植物覆盖面积(单位:公顷)和这种野生动物的数量,并计算得 ,
, , , .
(1)求该地区这种野生动物数量的估计值(这种野生动物数量的估计值等于样区这种野生动物数量的平
均数乘以地块数);
(2)求样本(xi,yi)(i=1,2,…,20)的相关系数(精确到0.01);
(3)根据现有统计资料,各地块间植物覆盖面积差异很大.为提高样本的代表性以获得该地区这种野生动
物数量更准确的估计,请给出一种你认为更合理的抽样方法,并说明理由.
附:相关系数r= , ≈1.414.
【答案】(1) ;(2) ;(3)详见解析
【分析】(1)利用野生动物数量的估计值等于样区野生动物平均数乘以地块数,代入数据即可;
(2)利用公式 计算即可;
(3)各地块间植物覆盖面积差异较大,为提高样本数据的代表性,应采用分层抽样.
【详解】(1)样区野生动物平均数为 ,
地块数为200,该地区这种野生动物的估计值为
(2)样本 (i=1,2,…,20)的相关系数为
资料整理【淘宝店铺:向阳百分百】(3)由(2)知各样区的这种野生动物的数量与植物覆盖面积有很强的正相关性,
由于各地块间植物覆盖面积差异很大,从而各地块间这种野生动物的数量差异很大,
采用分层抽样的方法较好地保持了样本结构与总体结构的一致性,提高了样本的代表性,
从而可以获得该地区这种野生动物数量更准确的估计.
【点晴】本题主要考查平均数的估计值、相关系数的计算以及抽样方法的选取,考查学生数学运算能力,
是一道容易题.
2.(2016年全国普通高等学校招生统一考试理科数学(新课标3卷))下图是我国2008年至2014年生活
垃圾无害化处理量(单位:亿吨)的折线图.
(Ⅰ)由折线图看出,可用线性回归模型拟合y与t的关系,请用相关系数加以说明;
(Ⅱ)建立y关于t的回归方程(系数精确到0.01),预测2016年我国生活垃圾无害化处理量.
附注:
参考数据: , ,
, ≈2.646.
参考公式:相关系数
回归方程 中斜率和截距的最小二乘估计公式分别为:
【答案】(Ⅰ)答案见解析;(Ⅱ)答案见解析.
【详解】试题分析:(Ⅰ)根据相关系数 的公式求出相关数据后,代入公式即可求得 的值,最后根据
值的大小回答即可;(Ⅱ)准确求得相关数据,利用最小二乘法建立 关于 的回归方程,然后预测.
试题解析:(Ⅰ)由折线图中数据和附注中参考数据得
, , ,
资料整理【淘宝店铺:向阳百分百】,
.
因为 与 的相关系数近似为0.99,说明 与 的线性相关相当高,从而可以用线性回归模型拟合 与 的
关系.
(Ⅱ)由 及(Ⅰ)得 ,
.
所以, 关于 的回归方程为: .
将2016年对应的 代入回归方程得: .
所以预测2016年我国生活垃圾无害化处理量将约1.82亿吨.
【考点】线性相关系数与线性回归方程的求法与应用.
【方法点拨】(1)判断两个变量是否线性相关及相关程度通常有两种方法:(1)利用散点图直观判断;
(2)将相关数据代入相关系数 公式求出 ,然后根据 的大小进行判断.求线性回归方程时要严格按照
公式求解,并一定要注意计算的准确性.
3.(2023届福建省适应性练习卷(省质检)数学试题)放行准点率是衡量机场运行效率和服务质量的重
要指标之一.某机场自2012年起采取相关策略优化各个服务环节,运行效率不断提升.以下是根据近10年年
份数 与该机场飞往A地航班放行准点率 ( )(单位:百分比)的统计数据所作的散点图及
经过初步处理后得到的一些统计量的值.
2017.5 80.4 1.5 40703145.0 1621254.2 27.7 1226.8
资料整理【淘宝店铺:向阳百分百】其中 ,
(1)根据散点图判断, 与 哪一个适宜作为该机场飞往A地航班放行准点率y关
于年份数x的经验回归方程类型(给出判断即可,不必说明理由),并根据表中数据建立经验回归方程,
由此预测2023年该机场飞往A地的航班放行准点率.
(2)已知2023年该机场飞往A地、B地和其他地区的航班比例分别为0.2、0.2和0.6.若以(1)中的预测值作
为2023年该机场飞往A地航班放行准点率的估计值,且2023年该机场飞往B地及其他地区(不包含A、B
两地)航班放行准点率的估计值分别为 和 ,试解决以下问题:
(i)现从2023年在该机场起飞的航班中随机抽取一个,求该航班准点放行的概率;
(ii)若2023年某航班在该机场准点放行,判断该航班飞往A地、B地、其他地区等三种情况中的哪种情
况的可能性最大,说明你的理由.
附:(1)对于一组数据 , ,…, ,其回归直线 的斜率和截距的最小二乘估
计分别为 ,
参考数据: , , .
【答案】(1) 适宜,预测2023年该机场飞往A地的航班放行准点率
(2)(i)0.778;(ii)可判断该航班飞往其他地区的可能性最大,理由见解析
【分析】(1)根据线性回归方程的计算公式,选择合适的模型计算即可;
(2)利用全概率公式和条件概率公式,即可根据概率判断可能性最大的情况.
【详解】(1)由散点图判断 适宜作为该机场飞往A地航班放行准点率y关于年份数x
的经验回归方程类型.
令 ,先建立y关于t的线性回归方程.
由于 ,
,
该机场飞往A地航班放行准点率y关于t的线性回归方程为 ,
因此y关于年份数x的回归方程为
所以当 时,该机场飞往A地航班放行准点率y的预报值为
.
资料整理【淘宝店铺:向阳百分百】所以2023年该机场飞往A地航班放行准点率y的预报值为 .
(2)设 “该航班飞往A地”, “该航班飞往B地”, “该航班飞往其他地区”, “该
航班准点放行”,
则 , , ,
, , .
(i)由全概率公式得,
,
所以该航班准点放行的概率为0.778.
(ii) ,
,
,
因为 ,
所以可判断该航班飞往其他地区的可能性最大.
4.(2023届河北省适应性考试数学试题)随着全球新能源汽车市场蓬勃增长,在政策推动下,中国新能
源汽车企业在10余年间实现了“弯道超车”,一跃成为新能源汽车产量连续7年居世界第一的全球新能源
汽车强国.某新能源汽车企业基于领先技术的支持,改进并生产纯电动车、插电混合式电动车、氢燃料电
池车三种车型,生产效益在短期内逐月攀升,该企业在1月份至6月份的生产利润y(单位,百万元)关
于月份 的数据如下表所示,并根据数据绘制了如图所示的散点图.
月份 1 2 3 4 5 6
收入 (百万
6.8 8.6 16.1 19.6 28.1 40.0
元)
资料整理【淘宝店铺:向阳百分百】(1)根据散点图判断, 与 ( , , ,d均为常数)哪一个更适宜作为利润 关于月份
的回归方程类型?(给出判断即可,不必说明理由)
(2)根据(1)的结果及表中的数据,求出y关于 的回归方程;
(3)该车企为提高新能源汽车的安全性,近期配合中国汽车技术研究中心进行了包括跌落、追尾、多车碰撞
等一系列安全试验项目,其中在实验场进行了一项甲、乙、丙三车同时去碰撞实验车的多车碰撞实验,测
得实验车报废的概率为0.188,并且当只有一车碰撞实验车发生,实验车报废的概率为0.1,当有两车碰撞
实验车发生,实验车报废的概率为0.2,由于各种因素,实验中甲乙丙三车碰撞实验车发生概率分别为
0.7,0.5,0.4,且互不影响,求当三车同时碰撞实验车发生时实验车报废的概率.
参考数据:
19.87 2.80 17.50 113.75 6.30
其中,设 , .
参考公式:对于一组具有线性相关关系的数据 ,其回归直线 的斜率和截距
的最小二乘估计公式分别为 , .
【答案】(1)选用 作为利润 关于月份 的回归方程更合适
(2)
(3)
【分析】(1)由散点的分布在一条曲线附近,即可选择非线性的.
(2)由对数运算,结合最小二乘法即可求解,
(3)由概率的乘法公式,结合全概率公式即可求解.
【详解】(1)散点图中的点的分布不是一条直线,相邻两点在 轴上的差距是增大的趋势.故选用
作为利润 关于月份 的回归方程更合适.
资料整理【淘宝店铺:向阳百分百】(2)由 ,取对数可得 ,设 ,所以 ,
, , , ,
所以 ,
,所以 ,
,即 .
(3)设事件 为“实验车报废”,事件 为“只有一车碰撞实验车”,事件 为“恰有两车碰撞实验
车”,事件 为“三车碰撞实验车”,
则
由已知得 ,
利用全概率公式得
解得
所以当三车同时碰撞实验车发生时实验车报废的概率为0.5.
1.(2023届广东省模拟数学试题)一企业生产某种产品,通过加大技术创新投入降低了每件产品成本,
为了调查年技术创新投入 (单位:千万元)对每件产品成本 (单位:元)的影响,对近 年的年技术
创新投入 和每件产品成本 的数据进行分析,得到如下散点图,并计算得: ,
, , , .
资料整理【淘宝店铺:向阳百分百】(1)根据散点图可知,可用函数模型 拟合 与 的关系,试建立 关于 的回归方程;
(2)已知该产品的年销售额 (单位:千万元)与每件产品成本 的关系为 .该
企业的年投入成本除了年技术创新投入,还要投入其他成本 千万元,根据(1)的结果回答:当年技术
创新投入 为何值时,年利润的预报值最大?
(注:年利润=年销售额一年投入成本)
参考公式:对于一组数据 、 、 、 ,其回归直线 的斜率和截距的最小乘估
计分别为: , .
【答案】(1)
(2)当年技术创新投入为 千万元时,年利润的预报值取最大值
【分析】(1)令 ,可得出 关于 的线性回归方程为 ,利用最小二乘法可求出 、 的
值,即可得出 关于 的回归方程;
(2)由 可得 ,可计算出年利润 关于 的函数关系式,结合二次函数的基本性质
可求得 的最小值及其对应的 值.
【详解】(1)解:令 ,则 关于 的线性回归方程为 ,
由题意可得 ,
,则 ,
资料整理【淘宝店铺:向阳百分百】所以, 关于 的回归方程为 .
(2)解:由 可得 ,
年利润
,
当 时,年利润 取得最大值,此时 ,
所以,当年技术创新投入为 千万元时,年利润的预报值取最大值.
2.人们用大数据来描述和定义信息时代产生的海量数据,并利用这些数据处理事务和做出决策,某公司
通过大数据收集到该公司销售的某电子产品1月至5月的销售量如下表.
月份x 1 2 3 4 5
销售量y(万件) 4.9 5.8 6.8 8.3 10.2
该公司为了预测未来几个月的销售量,建立了y关于x的回归模型: .
(1)根据所给数据与回归模型,求y关于x的回归方程( 的值精确到0.1);
(2)已知该公司的月利润z(单位:万元)与x,y的关系为 ,根据(1)的结果,问该公司
哪一个月的月利润预报值最大?
参考公式:对于一组数据 ,其回归直线 的斜率和截距的最小二乘估计
公式分别为 , .
【答案】(1) ;
(2)第9个月的月利润预报值最大
【分析】(1)根据数据与回归方程的公式进行求解 ,得到回归方程;(2)结合第一问所求得到 关于
的函数,通过导函数求出单调区间,极值及最值,求出答案.
【详解】(1)令 ,则 , ,
,
资料整理【淘宝店铺:向阳百分百】,所以y关于x的回归方程为 ;
(2)由(1)知: ,
,令 ,
令 得: ,令 得: ,令 得: ,所以
在 处取得极大值,也是最大值,
所以第9个月的月利润预报值最大.
3.千百年来,人们一直在通过不同的方式传递信息.在古代,烽火狼烟、飞鸽传书、快马驿站等通信方式
被人们广泛应用;第二次工业革命后,科技的进步带动了电讯事业的发展,电报电话的发明让通信领域发生
了翻天覆地的变化;之后,计算机和互联网的出现则使得“千里眼”“顺风耳”变为现实.现在, 的到来
给人们的生活带来颠覆性的变革,某科技创新公司基于领先技术的支持, 经济收入在短期内逐月攀升,
该创新公司在第 月份至6月份的 经济收入 (单位:百万元)关于月份 的数据如表:
时间(月份) 1 2 3 4 5 6
收入(百万元)
根据以上数据绘制散点图,如图.
(1)根据散点图判断, 与 均为常数)哪一个适宜作为 经济收入 关于月份 的回
归方程类型?(给出判断即可,不必说明理由)
(2)根据(1)的结果及表中的数据,求出 关于 的回归方程,并预测该公司8月份的 经济收入;
(3)从前6个月的收入中抽取 个﹐记月收入超过 百万的个数为 ,求 的分布列和数学期望.
参考数据:
资料整理【淘宝店铺:向阳百分百】其中设
参考公式和数据:对于一组具有线性相关关系的数据 ,其回归直线 的斜率和
截距的最小二乘估计公式分别为: ,
【答案】(1) ;
(2) , 百万元;
(3)分布列见解析,2.
【分析】(1)根据散点图的分布即可得到答案;
(2)根据题意, ,然后根据参考数据求出方程,进而得到y关于x的回归方程,最后将
代入方程即可得到答案;
(3)根据超几何分布求概率的方法求得概率,然后列出分布列,最后根据期望公式求出期望.
(1)
根据散点图判断, 适宜作为 经济收入 关于月份 的回归方程类型.
(2)
因为 ,所以两边同时取自然对数﹐得 ,
设 ,所以 ,又因为 ,
所以 , ,
所以 ,即 ,
令 ,得 ,故预测该公司 月份的 经济收入为 百万元.
(3)
前 个月的收入中,月收入超过 百万的有 个,所以 的取值为 ,
, , ,
所以 的分布列为
资料整理【淘宝店铺:向阳百分百】所以 .
4.“不关注分数,就是对学生的今天不负责:只关注分数,就是对学生的未来不负责.”为锻炼学生的综合
实践能力,长沙市某中学组织学生对雨花区一家奶茶店的营业情况进行调查统计,得到的数据如下:
月份x 2 4 6 8 10 12
净利润(万元〕y 0.9 2.0 4.2 3.9 5.2 5.1
(1)设 .试建立y关于x的非线性回归方程 和 (保留2位有效数字);
(2)从相关系数的角度确定哪一个模型的拟合效果更好,并据此预测次年2月( )的净利润(保留
1位小数).
附:①相关系数 ,回归直线 中斜率和截距的最小二乘估计公式分
别为 ;②参考数据:
,
【答案】(1) 和 ;
(2)模型 的拟合效果更好,次年2月净利润为 万元
【分析】(1)根据数据和公式直接计算可得;
(2)根据数据和公式计算出相关系数即可求出.
【详解】(1) ,
,
,
,
资料整理【淘宝店铺:向阳百分百】所以 , ,
所以模型 的方程为 ,
,
,
,
所以 , ,
所以模型 的方程为;
(2)
,
所以 ,
,
因为 更接近1,所以模型 的拟合效果更好,
则次年2月净利润为 万元.
考点 六 、独立性检验
1.(2023年全国高考甲卷数学(理)试题)一项试验旨在研究臭氧效应.实验方案如下:选40只小白鼠,
随机地将其中20只分配到实验组,另外20只分配到对照组,实验组的小白鼠饲养在高浓度臭氧环境,对
照组的小白鼠饲养在正常环境,一段时间后统计每只小白鼠体重的增加量(单位:g).
(1)设 表示指定的两只小白鼠中分配到对照组的只数,求 的分布列和数学期望;
(2)实验结果如下:
对照组的小白鼠体重的增加量从小到大排序为:
15.2 18.8 20.2 21.3 22.5 23.2 25.8 26.5 27.5 30.1
资料整理【淘宝店铺:向阳百分百】32.6 34.3 34.8 35.6 35.6 35.8 36.2 37.3 40.5 43.2
实验组的小白鼠体重的增加量从小到大排序为:
7.8 9.2 11.4 12.4 13.2 15.5 16.5 18.0 18.8 19.2
19.8 20.2 21.6 22.8 23.6 23.9 25.1 28.2 32.3 36.5
(i)求40只小鼠体重的增加量的中位数m,再分别统计两样本中小于m与不小于的数据的个数,完成如
下列联表:
对照
组
实验
组
(ii)根据(i)中的列联表,能否有95%的把握认为小白鼠在高浓度臭氧环境中与正常环境中体重的增加
量有差异.
附:
0.100 0.050 0.010
2.706 3.841 6.635
【答案】(1)分布列见解析,
(2)(i) ;列联表见解析,(ii)能
【分析】(1)利用超几何分布的知识即可求得分布列及数学期望;
(2)(i)根据中位数的定义即可求得 ,从而求得列联表;
(ii)利用独立性检验的卡方计算进行检验,即可得解.
【详解】(1)依题意, 的可能取值为 ,
则 , , ,
所以 的分布列为:
故 .
(2)(i)依题意,可知这40只小白鼠体重增量的中位数是将两组数据合在一起,从小到大排后第20位
资料整理【淘宝店铺:向阳百分百】与第21位数据的平均数,观察数据可得第20位为 ,第21位数据为 ,
所以 ,
故列联表为:
合计
对照组 6 14 20
实验组 14 6 20
合计 20 20 40
(ii)由(i)可得, ,
所以能有 的把握认为小白鼠在高浓度臭氧环境中与正常环境中体重的增加量有差异.
2.(2021年全国高考甲卷数学(理)试题)甲、乙两台机床生产同种产品,产品按质量分为一级品和二
级品,为了比较两台机床产品的质量,分别用两台机床各生产了200件产品,产品的质量情况统计如下表:
一级
二级品 合计
品
甲机床 150 50 200
乙机床 120 80 200
合计 270 130 400
(1)甲机床、乙机床生产的产品中一级品的频率分别是多少?
(2)能否有99%的把握认为甲机床的产品质量与乙机床的产品质量有差异?
附:
0.050 0.010 0.001
k 3.841 6.635 10.828
【答案】(1)75%;60%;
(2)能.
【分析】根据给出公式计算即可
【详解】(1)甲机床生产的产品中的一级品的频率为 ,
乙机床生产的产品中的一级品的频率为 .
资料整理【淘宝店铺:向阳百分百】(2) ,
故能有99%的把握认为甲机床的产品与乙机床的产品质量有差异.
3.(2022年全国高考甲卷数学(文)试题)甲、乙两城之间的长途客车均由A和B两家公司运营,为了
解这两家公司长途客车的运行情况,随机调查了甲、乙两城之间的500个班次,得到下面列联表:
准点班次数 未准点班次数
A 240 20
B 210 30
(1)根据上表,分别估计这两家公司甲、乙两城之间的长途客车准点的概率;
(2)能否有90%的把握认为甲、乙两城之间的长途客车是否准点与客车所属公司有关?
附: ,
0.100 0.050 0.010
2.706 3.841 6.635
【答案】(1)A,B两家公司长途客车准点的概率分别为 ,
(2)有
【分析】(1)根据表格中数据以及古典概型的概率公式可求得结果;
(2)根据表格中数据及公式计算 ,再利用临界值表比较即可得结论.
【详解】(1)根据表中数据,A共有班次260次,准点班次有240次,
设A家公司长途客车准点事件为M,
则 ;
B共有班次240次,准点班次有210次,
设B家公司长途客车准点事件为N,
则 .
A家公司长途客车准点的概率为 ;
B家公司长途客车准点的概率为 .
(2)列联表
资料整理【淘宝店铺:向阳百分百】未准点班次
准点班次数 合计
数
A 240 20 260
B 210 30 240
合计 450 50 500
= ,
根据临界值表可知,有 的把握认为甲、乙两城之间的长途客车是否准点与客车所属公司有关.
4.(2018年全国卷Ⅲ理数高考试题)某工厂为提高生产效率,开展技术创新活动,提出了完成某项生产
任务的两种新的生产方式.为比较两种生产方式的效率,选取40名工人,将他们随机分成两组,每组20
人,第一组工人用第一种生产方式,第二组工人用第二种生产方式.根据工人完成生产任务的工作时间
(单位:min)绘制了如下茎叶图:
(1)根据茎叶图判断哪种生产方式的效率更高?并说明理由;
(2)求40名工人完成生产任务所需时间的中位数 ,并将完成生产任务所需时间超过 和不超过 的工
人数填入下面的列联表:
超过
不超过
第一种生产方式
第二种生产方式
(3)根据(2)中的列联表,能否有99%的把握认为两种生产方式的效率有差异?附:
,
【答案】(1)第二种生产方式的效率更高. 理由见解析
(2)80
资料整理【淘宝店铺:向阳百分百】(3)能
【详解】分析:(1)计算两种生产方式的平均时间即可.
(2)计算出中位数,再由茎叶图数据完成列联表.
(3)由公式计算出 ,再与6.635比较可得结果.
详解:(1)第二种生产方式的效率更高.
理由如下:
(i)由茎叶图可知:用第一种生产方式的工人中,有75%的工人完成生产任务所需时间至少80分钟,用
第二种生产方式的工人中,有75%的工人完成生产任务所需时间至多79分钟.因此第二种生产方式的效率
更高.
(ii)由茎叶图可知:用第一种生产方式的工人完成生产任务所需时间的中位数为85.5分钟,用第二种生
产方式的工人完成生产任务所需时间的中位数为73.5分钟.因此第二种生产方式的效率更高.
(iii)由茎叶图可知:用第一种生产方式的工人完成生产任务平均所需时间高于80分钟;用第二种生产方
式的工人完成生产任务平均所需时间低于80分钟,因此第二种生产方式的效率更高.
(iv)由茎叶图可知:用第一种生产方式的工人完成生产任务所需时间分布在茎8上的最多,关于茎8大
致呈对称分布;用第二种生产方式的工人完成生产任务所需时间分布在茎7上的最多,关于茎7大致呈对
称分布,又用两种生产方式的工人完成生产任务所需时间分布的区间相同,故可以认为用第二种生产方式
完成生产任务所需的时间比用第一种生产方式完成生产任务所需的时间更少,因此第二种生产方式的效率
更高.
以上给出了4种理由,考生答出其中任意一种或其他合理理由均可得分.
(2)由茎叶图知 .
列联表如下:
超过
不超过
第一种生产方式 15 5
第二种生产方式 5 15
(3)由于 ,所以有99%的把握认为两种生产方式的效率有差异.
点睛:本题主要考查了茎叶图和独立性检验,考查学生的计算能力和分析问题的能力,贴近生活.
5.(2023届安徽省质量检查数学试题)文旅部门统计了某网红景点在2022年3月至7月的旅游收入
(单位:万),得到以下数据:
月份 3 4 5 6 7
旅游收入 1 12 11 12 20
资料整理【淘宝店铺:向阳百分百】0
(1)根据表中所给数据,用相关系数 加以判断,是否可用线性回归模型拟合 与 的关系?若可以,求出
关于 之间的线性回归方程;若不可以,请说明理由;
(2)为调查游客对该景点的评价情况,随机抽查了200名游客,得到如下列联表,请填写下面的 列联表,
依据 的独立性检验,能否认为“游客是否喜欢该网红景点与性别有关联”.
喜欢 不喜欢 总计
男 100
女 60
总计 110
参考公式:相关系数 ,参考数据: .线性回归方程: ,其
中 , .
临界值表:
【答案】(1)可用线性回归模型拟合 与 的关系, ;
(2)列联表见解析,游客是否喜欢该网红景点与性别有关联.
【分析】(1)根据相关系数公式求出相关系数,再应用最小二乘法求回归直线即可;
(2)由已知写出列联表,根据卡方公式求卡方值,结合独立检验的基本思想得到结论.
【详解】(1)由已知得: ,
,因为 ,
说明 与 的线性相关关系很强.,可用线性回归模型拟合 与 的关系,
,
则 关于 的线性回归方程为: .
资料整理【淘宝店铺:向阳百分百】(2) 列联表如下所示:
喜欢 不喜欢 总计
男 70 30 100
女 40 60 100
总计 110 90 200
零假设 :游客是否喜欢该网红景点与性别无关联,
根据列联表中数据, ,
依据小概率值 的独立性检验,我们推断 不成立,即游客是否喜欢该网红景点与性别有关联.
1.(2020年全国统一高考数学试卷(理科)(新课标Ⅲ))某学生兴趣小组随机调查了某市100天中每
天的空气质量等级和当天到某公园锻炼的人次,整理数据得到下表(单位:天):
锻炼人次
[0,200] (200,400] (400,600]
空气质量等级
1(优) 2 16 25
2(良) 5 10 12
3(轻度污染) 6 7 8
4(中度污染) 7 2 0
(1)分别估计该市一天的空气质量等级为1,2,3,4的概率;
(2)求一天中到该公园锻炼的平均人次的估计值(同一组中的数据用该组区间的中点值为代表);
(3)若某天的空气质量等级为1或2,则称这天“空气质量好”;若某天的空气质量等级为3或4,则称
这天“空气质量不好”.根据所给数据,完成下面的2×2列联表,并根据列联表,判断是否有95%的把握
认为一天中到该公园锻炼的人次与该市当天的空气质量有关?
人次
人次>400
≤400
空气质量好
空气质量不好
附: ,
P(K2≥k) 0.050 0.010 0.001
资料整理【淘宝店铺:向阳百分百】k 3.841 6.635 10.828
【答案】(1)该市一天的空气质量等级分别为 、 、 、 的概率分别为 、 、 、 ;
(2) ;(3)有,理由见解析.
【分析】(1)根据频数分布表可计算出该市一天的空气质量等级分别为 、 、 、 的概率;
(2)利用每组的中点值乘以频数,相加后除以 可得结果;
(3)根据表格中的数据完善 列联表,计算出 的观测值,再结合临界值表可得结论.
【详解】(1)由频数分布表可知,该市一天的空气质量等级为 的概率为 ,等级为 的概
率为 ,等级为 的概率为 ,等级为 的概率为 ;
(2)由频数分布表可知,一天中到该公园锻炼的人次的平均数为
(3) 列联表如下:
人次 人次
空气质量好
空气质量不
好
,
因此,有 的把握认为一天中到该公园锻炼的人次与该市当天的空气质量有关.
【点睛】本题考查利用频数分布表计算频率和平均数,同时也考查了独立性检验的应用,考查数据处理能
力,属于基础题.
2.(2020年新高考全国卷Ⅰ数学高考试题(山东))为加强环境保护,治理空气污染,环境监测部门对
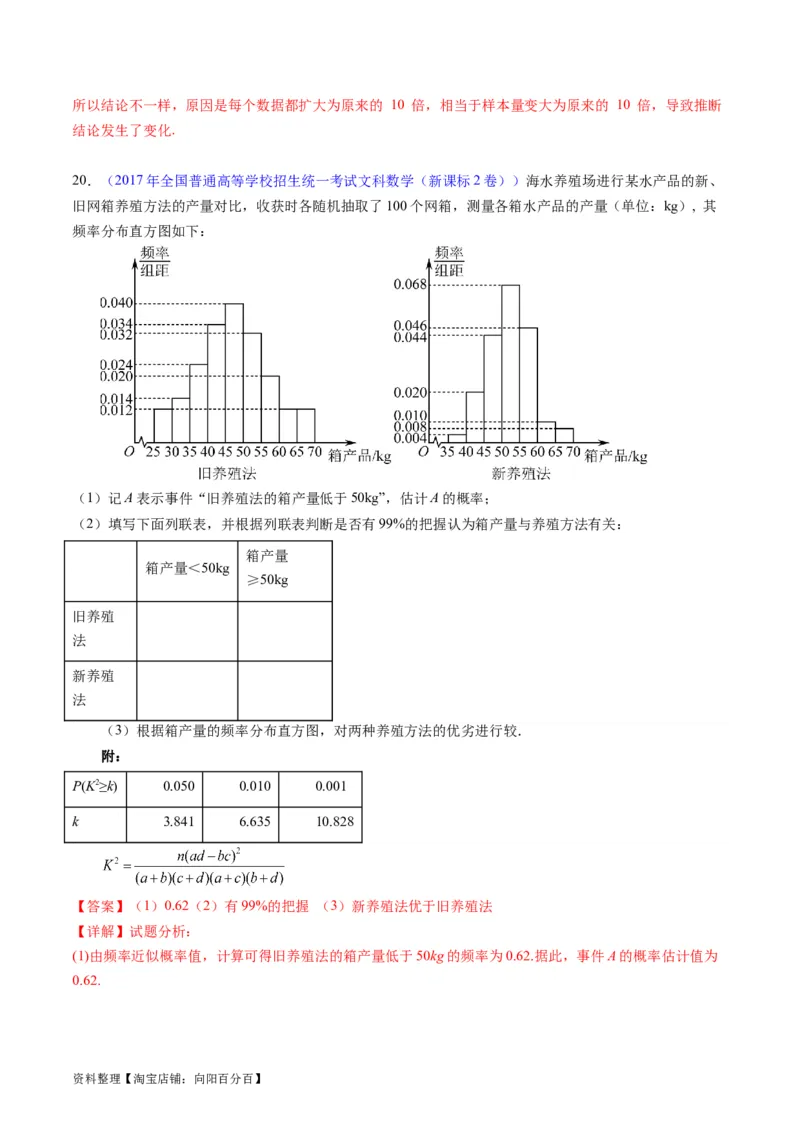
某市空气质量进行调研,随机抽查了 天空气中的 和 浓度(单位: ),得下表:
资料整理【淘宝店铺:向阳百分百】(1)估计事件“该市一天空气中 浓度不超过 ,且 浓度不超过 ”的概率;
(2)根据所给数据,完成下面的 列联表:
(3)根据(2)中的列联表,判断是否有 的把握认为该市一天空气中 浓度与 浓度有关?
附: ,
【答案】(1) ;(2)答案见解析;(3)有.
【分析】(1)根据表格中数据以及古典概型的概率公式可求得结果;
(2)根据表格中数据可得 列联表;
(3)计算出 ,结合临界值表可得结论.
【详解】(1)由表格可知,该市100天中,空气中的 浓度不超过75,且 浓度不超过150的天
数有 天,
所以该市一天中,空气中的 浓度不超过75,且 浓度不超过150的概率为 ;
资料整理【淘宝店铺:向阳百分百】(2)由所给数据,可得 列联表为:
合计
64 16 80
10 10 20
合计 74 26 100
(3)根据 列联表中的数据可得
,
因为根据临界值表可知,有 的把握认为该市一天空气中 浓度与 浓度有关.
【点睛】本题考查了古典概型的概率公式,考查了完善 列联表,考查了独立性检验,属于中档题.
3.(2019年全国统一高考数学试卷(文科)(新课标Ⅰ))某商场为提高服务质量,随机调查了50名男
顾客和50名女顾客,每位顾客对该商场的服务给出满意或不满意的评价,得到下面列联表:
满意 不满意
男顾客 40 10
女顾客 30 20
(1)分别估计男、女顾客对该商场服务满意的概率;
(2)能否有95%的把握认为男、女顾客对该商场服务的评价有差异?
附: .
P(K2≥k) 0.050 0.010 0.001
k 3.841 6.635 10.828
【答案】(1) ;
(2)能有 的把握认为男、女顾客对该商场服务的评价有差异.
【分析】(1)从题中所给的 列联表中读出相关的数据,利用满意的人数除以总的人数,分别算出相应
的频率,即估计得出的概率值;
(2)利用公式求得观测值与临界值比较,得到能有 的把握认为男、女顾客对该商场服务的评价有差
异.
【详解】(1)由题中表格可知,50名男顾客对商场服务满意的有40人,
资料整理【淘宝店铺:向阳百分百】所以男顾客对商场服务满意率估计为 ,
50名女顾客对商场满意的有30人,
所以女顾客对商场服务满意率估计为 ,
(2)由列联表可知 ,
所以能有 的把握认为男、女顾客对该商场服务的评价有差异.
【点睛】该题考查的是有关概率与统计的知识,涉及到的知识点有利用频率来估计概率,利用列联表计算
的值,独立性检验,属于简单题目.
4.为推行“新课堂”教学法,某老师分别用传统教学和“新课堂”两种不同的教学方式在甲、乙两个平行
班进行教学实验,为了解教学效果,期中考试后,分别从两个班级中各随机抽取20名学生的成绩进行统计,作出
如图所示的茎叶图,若成绩大于70分为“成绩优良”.
(1)分别计算甲、乙两班的样本中,前10名成绩的平均分,并据此判断哪种教学方式的教学效果更佳;
(2)由以上统计数据填写下面2×2列联表,并判断能否在犯错误的概率不超过0.05的前提下认为“成绩优良
与教学方式有关”?
甲
乙班 总计
班
成绩优良
成绩不优良
总计
(3)从甲、乙两班40个样本中,成绩在60分以下(不含60分)的学生中任意选取2人,记ξ为所抽取的2人中来
自乙班的人数,求ξ的分布列及数学期望.
附:K2= (n=a+b+c+d),
P(K2≥k) 0.10 0.05 0.025 0.010
0
k 2.706 3.841 5.024 6.635
0
【答案】(1)见解析;(2)见解析;(3)见解析
资料整理【淘宝店铺:向阳百分百】【分析】(1)由平均数是的计算公式,分布求得甲班样本前10名成绩和乙班样本前10名成绩的平均分,比
较即可得到结论.
(2)根据茎叶图中的数据作出 列联表,利用公式计算 的值,即可得到结论.
(3)求得随机变量的所有可能取值为 ,求出随机变量取值的概率,列出随机变量的分布列,利用公式,
即可求解数学期望.
【详解】(1)由数据的平均数是的计算公式,可得甲班样本前10名成绩的平均分为
= ;
乙班样本前10名成绩的平均分为
= ;
因为甲班样本前10名成绩的平均分低于乙班样本前10名成绩的平均分,
所以据此判断“新课堂”教学方式的教学效果更佳.
(2)根据茎叶图中的数据作出 列联表如表所示:
甲
乙班 总计
班
成绩优良 10 16 26
成绩不优良 10 4 14
总计 20 20 40
根据 列联表中的数据,得 的观测值为 ,
所以能在犯错误的概率不超过0.05的前提下认为“成绩优良与教学方式有关”.
(3)样本中成绩在60分以下的学生中甲班有4人,乙班有2人,
所以 的所有可能取值为 ,
则 = , , = ,
则随机变量 的分布列为:
0 1 2
P
则数学期望 .
【点睛】本题主要考查了数据的平均数和独立性检验的应用,以及随机变量的分布列与数学期望的计算,
其中解答中认真审题,合理利用平均数、独立性检验的公式准确计算,以及正确得出随机变量的取值及概
资料整理【淘宝店铺:向阳百分百】率,列出相应的分布列是解答的关键,着重考查了分析问题和解答问题的能力,属于中档试题.
5.(2020年海南省高考数学试卷(新高考全国Ⅱ卷))为加强环境保护,治理空气污染,环境监测部门
对某市空气质量进行调研,随机抽查了 天空气中的 和 浓度(单位: ),得下表:
32 18 4
6 8 12
3 7 10
(1)估计事件“该市一天空气中 浓度不超过 ,且 浓度不超过 ”的概率;
(2)根据所给数据,完成下面的 列联表:
(3)根据(2)中的列联表,判断是否有 的把握认为该市一天空气中 浓度与 浓度有关?
附: ,
0.050 0.010 0.001
3.841 6.635 10.828
【答案】(1) ;(2)答案见解析;(3)有.
【分析】(1)根据表格中数据以及古典概型的概率公式可求得结果;
(2)根据表格中数据可得 列联表;
(3)计算出 ,结合临界值表可得结论.
【详解】(1)由表格可知,该市100天中,空气中的 浓度不超过75,且 浓度不超过150的天
数有 天,
所以该市一天中,空气中的 浓度不超过75,且 浓度不超过150的概率为 ;
(2)由所给数据,可得 列联表为:
资料整理【淘宝店铺:向阳百分百】合计
64 16 80
10 10 20
合计 74 26 100
(3)根据 列联表中的数据可得
,
因为根据临界值表可知,有 的把握认为该市一天空气中 浓度与 浓度有关.
【点睛】本题考查了古典概型的概率公式,考查了完善 列联表,考查了独立性检验,属于中档题.
【基础过关】
1.(2023届湖南省联考数学试题)已知某班共有学生46人,该班语文老师为了了解学生每天阅读课外书
籍的时长情况,决定利用随机数表法从全班学生中抽取10人进行调查.将46名学生按01,02,…,46进
行编号.现提供随机数表的第7行至第9行:
84 42 17 53 31 57 24 55 06 88 77 04 74 47 67 21 76 33 50 25 83 92 12 06 76
63 01 63 78 59 16 95 56 57 19 98 10 50 71 75 12 86 73 58 07 44 39 52 38 79
33 21 12 34 29 78 64 56 07 82 52 42 07 44 38 15 51 00 13 42 99 66 02 79 54
若从表中第7行第41列开始向右依次读取2个数据,每行结束后,下一行依然向右读数,则得到的第8个
样本编号是( )
资料整理【淘宝店铺:向阳百分百】A.07 B.12 C.39 D.44
【答案】D
【分析】根据读数要求,利用随机数依次读数即可得出结果.
【详解】由题意可知得到的样本编号依次为12,06,01,16,19,10,07,44,39,38,则得到的第8个
样本编号是44.
2.(2023年四川省模拟文科数学试题)关于统计数据的分析,有以下几个结论,其中正确的是( )
A.样本数据9、3、5、7、12、13、1、8、10、18的中位数是8或9
B.将一组数据中的每个数据都减去同一个数后,平均数与方差均没有变化
C.利用残差进行回归分析时,若残差点比较均匀地落在宽度较窄的水平带状区域内,则说明线性回归
模型的拟合精度较高
D.调查影院中观众观后感时,从15排(每排人数相同)每排任意抽取一人进行调查是系统抽样法
【答案】C
【分析】按照中位数,平均数和方差的计算方法判断选项A,B的正误,根据残差图的含义判断选项C的
正误,区分不同抽样方法的概念判断D的正误.
【详解】对于A,样本数据1、3、5、7、8、9、10、12、13、18的中位数为 ,A错误;
对于B,每个数据都减去同一个数后,平均数也应为原平均数减去这个数,B错误;
对于C,残差点比较均匀地落在宽度较窄的水平带状区域内,则拟合精度高,C正确;
对于D,每排任意抽取一人应为简单随机抽样,D错误;
3.某班数学兴趣小组组织了线上“统计”全章知识的学习心得交流:
甲同学说:“在频率分布直方图中,各小长方形的面积的总和小于1”;
乙同学说:“简单随机抽样因为抽样的随机性,可能会出现比较‘极端’的样本.相对而言,分层随机抽
样的样本平均数波动幅度更均匀”;
丙同学说:“扇形图主要用于直观描述各类数据占总数的比例”;
丁同学说:“标准差越大,数据的离散程度越小”.
以上四人中,观点正确的同学个数为( )
A.1 B.2 C.3 D.4
【答案】B
【分析】利用统计的相关知识可逐个判断各同学观点的正误即可.
【详解】“在频率分布直方图中,各小长方形的面积的总和等于1”,故甲的观点错误;
“简单随机抽样因为抽样的随机性,可能会出现比较‘极端’的样本,相对而言,分层随机抽样的样本平
均数波动幅度更均匀”,故乙的观点正确;
“扇形图主要用于直观描述各类数据占总数的比例”,故丙的观点正确;
“标准差越大,数据的离散程度越大”,故丁的观点错误.
资料整理【淘宝店铺:向阳百分百】4.对高三某班级的学生进行体能测试,所得成绩统计如下图所示,则该班级学生体能测试成绩的中位数
为( )
A.80 B.85 C.82.5 D.83
【答案】C
【分析】由频率确定中位数在80至90之间,然后由比例计算可得.
【详解】解:依题意,成绩不大于80分的概率为 ,而成绩在区间 的概率
为0.4,因此中位数在80至90之间,
所求中位数为 .
5.甲,乙两人在5天中每天加工零件的个数用茎叶图表示如图,中间一列的数字表示零件个数的十位数,
两边的数字表示零件个数的个位数,则下列结论正确的是( )
A.在这5天中,甲,乙两人加工零件数的极差相同
B.在这5天中,甲,乙两人加工零件数的中位数相同
C.在这5天中,甲日均加工零件数大于乙日均加工零件数
D.在这5天中,甲加工零件数的方差小于乙加工零件数的方差
【答案】C
【分析】由茎叶图的数据,分别计算甲、乙加工零角个数的极差,中位数,平均数,方差,进而得解.
【详解】甲在5天中每天加工零件的个数为:18,19,23,27,28;乙在5天中每天加工零件的个数为:
17,19,21,23,25
对于A,甲加工零件数的极差为 ,乙加工零件数的极差为 ,故A错误;
对于B,甲加工零件数的中位数为 ,乙加工零件数的中位数为 ,故B错误;
资料整理【淘宝店铺:向阳百分百】对于C,甲加工零件数的平均数为 ,乙加工零件数的平均数为
,故C正确;
对于D,甲加工零件数的方差为 ,乙加工零件数的方差为 ,
故D错误;
6.(2023届天津市模拟数学试题)下列命题错误的是( )
A.两个随机变量的线性相关性越强,相关系数的绝对值越接近于
B.设 ,且 ,则
C.线性回归直线 一定经过样本点的中心
D.随机变量 ,若 ,则
【答案】B
【分析】利用相关关系判断A;由正态分布的性质判断B;由线性回归直线的性质判断C;由随机变量条
件建立方程组解出即可判断D.
【详解】根据相关系数的意义可知,两个随机变量的线性相关性越强,
相关系数的绝对值越接近于 ,
故A正确;
由 ,知 ,
即概率密度函数的图像关于直线 对称,
所以 ,则 ,
故B错误;
根据线性回归直线的性质可知,线性回归直线 一定经过样本点的中心 ,
故C正确;
随机变量 ,若 ,则 ,
故D正确;
7.为考察一种新药预防疾病的效果,某科研小组进行动物实验,收集整理数据后将所得结果填入相应的
列联表中,由列联表中的数据计算得 .参照附表,下列结论正确的是( )
附表:
资料整理【淘宝店铺:向阳百分百】0.050 0.025 0.010 0.005 0.001
3.841 5.02 6.635 7.879 10.828
A.在犯错误的概率不超过0.1%的前提下,认为“药物有效”
B.在犯错误的概率不超过0.1%的前提下,认为“药物无效”
C.有99%以上的把握认为“药物有效”
D.有99%以上的把握认为“药物无效”
【答案】C
【分析】根据 与参考值比较,结合独立性检验的定义,即可判断;
【详解】解:因为 ,即 ,所以有 以上的把握认为“药物有效”.
8.根据分类变量 与 的成对样本数据,计算得到 .依据 的独立性检验 ,
结论为( )
A.变量 与 不独立
B.变量 与 不独立,这个结论犯错误的概率不超过
C.变量 与 独立
D.变量 与 独立,这个结论犯错误的概率不超过
【答案】C
【分析】直接利用独立性检验的知识求解.
【详解】按照独立性检验的知识及比对的参数值,当 ,我们可以下结论变量 与 独立.故排除
选项A,B;
依据 的独立性检验 ,6.147<6.635,所以我们不能得到“变量 与 独立,这个结论犯
错误的概率不超过 ”这个结论.故C正确,D错误.
9.(2023年山东省模拟数学试题)下列说法正确的是( )
A.将一组数据中的每一个数据都加上同一个常数后,平均数和方差都不变
B.设具有线性相关关系的两个变量x,y的相关系数为r,则|r|越接近于0,x和y之间的线性相关程度
越强
C.在一个2×2列联表中,由计算得K²的值,则K²的值越小,判断两个变量有关的把握越大
D.若 ,则
【答案】D
【分析】对A根据方差与平均数定义即可判断,对B利用线性相关定义则可判断,对C根据 的含义即
可判断,对D对于正态分布的特点,即可求出区间概率.
【详解】对于A,方差反映一组数据的波动大小,将一组数据中的每个数据都加上或减去同一个常数后,方差
资料整理【淘宝店铺:向阳百分百】不变,但平均数变化,故A错误,
对于B,具有线性相关关系的两个变量 , 的相关系数为 ,则 越接近于 , 和 之间的线性相关程度越强,
故B错误,
对于C,在一个 列联表中,由计算得 的值,则 的值越大,判断两个变量有关的把握越大,故C错误,
对于D, ,
故D正确.
10.(2019年全国统一高考数学试题(理科)(新课标Ⅱ))我国高铁发展迅速,技术先进.经统计,在
经停某站的高铁列车中,有10个车次的正点率为0.97,有20个车次的正点率为0.98,有10个车次的正点
率为0.99,则经停该站高铁列车所有车次的平均正点率的估计值为 .
【答案】0.98.
【分析】本题考查通过统计数据进行概率的估计,采取估算法,利用概率思想解题.
【详解】由题意得,经停该高铁站的列车正点数约为 ,其中高铁个数为
10+20+10=40,所以该站所有高铁平均正点率约为 .
【点睛】本题考点为概率统计,渗透了数据处理和数学运算素养.侧重统计数据的概率估算,难度不大.
易忽视概率的估算值不是精确值而失误,根据分类抽样的统计数据,估算出正点列车数量与列车总数的比
值.
11.某社会爱心组织面向全市征召义务宣传志愿者.现从符合条件的志愿者中随机抽取 名按年龄分组:
第 组 ,第 组 ,第 组 ,第 组 ,第 组 ,得到的频率分布直方图如
图所示.若从第 , , 组中用分层抽样的方法抽取 名志愿者参与广场的宣传活动,应从第 组抽取
名志愿者.
【答案】
【分析】先分别求出这3组的人数,再利用分层抽样的方法即可得出答案.
【详解】第3组的人数为 ,
第4组的人数为 ,
第5组的人数为 ,
所以这三组共有60名志愿者,
资料整理【淘宝店铺:向阳百分百】所以利用分层抽样的方法在60名志愿者中抽取6名志愿者,第三组应抽取 名.
【点睛】关键点点睛:该题考查的是有关频率分布直方图的识别以及分层抽样某层抽取个数的问题,正确
解题的关键是掌握在抽取过程中每个个题被抽到的机会均等.
12.第24届冬季奥林匹克运动会(The XXIV Olympic Winter Games),即2022年北京冬季奥运会,计划于
2022年2月4日星期五开幕,2月20日星期日闭幕.北京冬季奥运会设7个大项,15个分项,109个小项.
某大学青年志愿者协会接到组委会志愿者服务邀请,计划从大一至大三青年志愿者中选出24名志愿者,参
与北京冬奥会高山滑雪比赛项目的服务工作.已知大一至大三的青年志愿者人数分别为50,40,30,则按
分层抽样的方法,在大一青年志愿者中应选派 人.
【答案】10
【分析】根据分层抽样原理求出抽取的人数.
【详解】解:根据分层抽样原理知, ,
所以在大一青年志愿者中应选派10人.
13.一次性医用口罩是适用于覆盖使用者的口、鼻及下颌,用于普通医疗环境中佩戴、阻隔口腔和鼻腔呼
出或喷出污染物的一次性口罩,按照我国医药行业标准,口罩对细菌的过滤效率达到95%及以上为合格,
98%及以上为优等品,某部门为了检测一批口置对细菌的过滤效率.随机抽检了200个口罩,将它们的过滤
效率(百分比)按照[95,96),[96,97),[97,98),[98,99),[99,100]分成5组,制成如图所示的
频率分布直方图.
(1)求图中m的值并估计这一批口罩中优等品的概率;
(2)为了进一步检测样本中优等品的质量,用分层抽样的方法从[98,99)和[99,100]两组中抽取7个口罩,
再从这7个口罩中随机抽取3个口罩做进一步检测,记取自[98,99)的口罩个数为X,求X的分布列与期
资料整理【淘宝店铺:向阳百分百】望.
【答案】(1)0.25,0.35
(2)分布列见解析,
【分析】(1)根据频率之和等于1可得m,然后直接计算优等品的概率即可;
(2)先由分层抽样取得各层样板个数,然后由超几何分布计算可得.
(1)
由图可知
估计这一批口罩中优等品的概率为
(2)
因为 ,所以从[98,99)中抽取 个,从[99,100]中抽取 个.
则X的可能取值为1,2,3,
且
故X的分布列为
X 1 2 3
P
.
14.新冠病毒传播以来,在世界各地造成极大影响.“动态清零”政策是我国根据疫情防控经验的总结和
提炼,是现阶段我们疫情防控的一个最佳选择和总方针.为落实动态清零政策下的常态化防疫,要求学校作
为重点人群,每天要进行核酸检测.某高中学校核酸抽检工作:每天下午 开始,当天安排 位师
生核酸检测,教职员工每天都要检测,学生五天时间全员覆盖.
(1)该校教职员工有 人,高二学生有 人,高三学生有 人,
①用分层抽样的方法,求高一学生每天抽检人数;
②高一年级共 个班,该年级每天抽检的学生有两种安排方案,方案一:集中来自部分班级;方案二:分
散来自所有班级,每班随机抽取 .你认为哪种方案更合理,并给出理由.
(2)学校开展核酸抽检的某轮核酸抽检用时记录如下:
第 天 1 2 3 4 5
资料整理【淘宝店铺:向阳百分百】用时 (小
2.5 2.3 2.1 2.1 2.0
时)
计算变量 和 的相关系数 (精确到 ),说明两变量线性相关的强弱;并根据 的计算结果,判定变
量 和 是正相关,还是负相关,给出可能的原因.
参考数据和公式: ,相关系数
【答案】(1)①250;②分散抽检,理由见解析;
(2)-0.95,负相关,答案见解析.
【分析】(1)①直接利用分层抽样的公式求出高一学生每天抽检人数;②答案见解析;
(2)求出相关系数 即得解.
(1)
解:①高一学生每天抽检人数为 .
②方案二更合理,因为新冠病毒奥密克戎毒株传染性更强、潜伏期更短,分散抽检可以全面检测年级中每
班学生的状况,更有利于防控筛查工作.
(2)
解:
变量 和 的相关系数为:
因为 ,可知两变量线性相关性很强,由 可知变量 和 是负相关.
可能的原因:随着抽检工作的开展,学校相关管理协调工作效率提高,因此用时缩短.
15.(2023年江苏省模拟数学试题)云计算是信息技术发展的集中体现,近年来,我国云计算市场规模持
续增长.从中国信息通信研究院发布的《云计算白皮书(2022年)》可知,我国2017年至2021年云计算市
场规模数据统计表如下:
年份 2017年 2018年 2019年 2020年 2021年
年份代码x 1 2 3 4 5
资料整理【淘宝店铺:向阳百分百】云计算市场规模y/亿元 692 962 1334 2091 3229
经计算得: =36.33, =112.85.
(1)根据以上数据,建立y关于x的回归方程 ( 为自然对数的底数).
(2)云计算为企业降低生产成本、提升产品质量提供了强大助推力.某企业未引入云计算前,单件产品尺寸与
标准品尺寸的误差 ,其中m为单件产品的成本(单位:元),且 =0.6827;引入云
计算后,单件产品尺寸与标准品尺寸的误差 .若保持单件产品的成本不变,则 将会
变成多少?若保持产品质量不变(即误差的概率分布不变),则单件产品的成本将会下降多少?
附:对于一组数据 其回归直线 的斜率和截距的最小二乘估计分别为 =
, .
若 ,则 , ,
【答案】(1)
(2) ,成本下降3元.
【分析】(1)将非线性回归模型转化为线性回归模型求解;
(2)利用正态分布的概率模型求解,并结合特殊概率值求解.
【详解】(1)因为 ,所以 ,
所以 ,
所以 ,
所以 .
(2)未引入云算力辅助前, ,所以 ,
又 ,所以 ,所以 .
引入云算力辅助后, ,所以 ,
资料整理【淘宝店铺:向阳百分百】若保持产品成本不变,则 ,所以
若产品质量不变,则 ,所以 ,所以单件产品成本可以下降 元.
16.(2023届四川省模拟理科数学试题)某旅游公司针对旅游复苏设计了一款文创产品来提高收益.该公
司统计了今年以来这款文创产品定价 (单位:元)与销量 (单位:万件)的数据如下表所示:
产品定价 (单位:
9 9.5 10 10.5 11
元)
销量 (单位:万件) 11 10 8 6 5
(1)依据表中给出的数据,判断是否可用线性回归模型拟合 与 的关系,请计算相关系数并加以说明(计
算结果精确到0.01);
(2)建立 关于 的回归方程,预测当产品定价为8.5元时,销量可达到多少万件.
参考公式: .
参考数据: .
【答案】(1) ,说明 与 的线性相关性很强,可以用线性回归模型拟合 与 的关系
(2)12.8万件
【分析】(1)先计算出 、 的平均值,再结合相关性系数的参考公式计算即可,根据数值得到相关性强
弱,
(2)根据公式,计算出 关于 的回归方程,将 代入回归方程即可得到结果.
【详解】(1)由题条件得 ,
.
,
,
.
与 的相关系数近似为 ,说明 与 的线性相关性很强,从而可以用线性回归模型拟合 与 的
资料整理【淘宝店铺:向阳百分百】关系.
(2) ,
关于 的线性回归方程为 .
当 时, .
∴当产品定价为8.5元时,预测销量可达到12.8万件.
17.(2023年四川省诊断性考试数学(理)试题)某企业为改进生产,现 某产品及成本相关数据进行统
计.现收集了该产品的成本费y(单位:万元/吨)及同批次产品生产数量x(单位:吨)的20组数据.现
分别用两种模型① ,② 进行拟合,据收集到的数据,计算得到如下值:
14.5 0.08 665 0.04 -450 4
表中 , .
若用 刻画回归效果,得到模型①、②的 值分别为 , .
(1)利用 和 比较模型①、②的拟合效果,应选择哪个模型?并说明理由;
(2)根据(1)中所选择的模型,求y关于x的回归方程;并求同批次产品生产数量为25(吨)时y的预报值.
附:对于一组数据 , ,…, ,其回归直线 的斜率和截距的最小二乘法估
计分别为 , .
【答案】(1)选择模型②,理由见解析;
(2)6.
【分析】(1)根据已知 ,根据 的意义,即可得出模型②的拟合效果好,选择模型②;
(2) 与 可用线性回归来拟合,有 ,求出系数 ,得到回归方程 ,即可得到成本
费 与同批次产品生产数量 的回归方程为 ,代入 ,即可求出结果.
【详解】(1)应该选择模型②.
资料整理【淘宝店铺:向阳百分百】由题意可知, ,则模型②中样本数据的残差平方和 比模型①中样本数据的残差平方和
小,即模型②拟合效果好.
(2)由已知 ,成本费 与 可用线性回归来拟合,有 .
由已知可得, ,
所以 ,则 关于 的线性回归方程为 .
成本费 与同批次产品生产数量 的回归方程为 ,当 (吨)时, (万
元/吨).
所以,同批次产品生产数量为25(吨)时y的预报值为6万元/吨.
18.2022年2月4日北京冬奥运会正式开幕,“冰墩墩”作为冬奥会的吉祥物之一,受到各国运动员的
“追捧”,成为新晋“网红”,尤其在我国,广大网友纷纷倡导“一户一墩”,为了了解人们对“冰墩
墩”需求量,某电商平台采用预售的方式,预售时间段为2022年2月5日至2022年2月20日,该电商平
台统计了2月5日至2月9日的相关数据,这5天的第x天到该电商平台参与预售的人数y(单位:万人)
的数据如下表:
日期 2月5日 2月6日 2月7日 2月8日 2月9日
第 天 1 2 3 4 5
人数 (单位:万人) 45 56 64 68 72
(1)依据表中的统计数据,请判断该电商平台的第 天与到该电商平台参与预售的人数 (单位:万人)是
否具有较高的线性相关程度?(参考:若 ,则线性相关程度一般,若 ,则线性相关
程度较高,计算 时精确度为 )
(2)求参与预售人数 与预售的第 天的线性回归方程;用样本估计总体,请预测2022年2月20日该电商
平台的预售人数(单位:万人).
参考数据: ,附:相关系数
【答案】(1)具有较高的线性相关程度;(2) , 万人;
【分析】(1)根据已知数据计算出相关系数 可得;
资料整理【淘宝店铺:向阳百分百】(2)由已知数据求出回归方程的系数得回归方程,然后在回归方程中令 代入计算可得估计值.
【详解】(1)由表中数据可得 ,
所以
又
所以
所以该电商平台的第 天与到该电商平台参与预售的人数 (单位:万人)具有较高的线性相关程度即可
用线性回归模型拟合人数 与天数 之间的关系.
(2)由表中数据可得
则
所以
令 ,可得 (万人)
故预测2022年2月20日该电商平台的预售人数 万人
19.(2023届广东省模拟数学试题)飞盘运动是一项入门简单,又具有极强的趣味性和社交性的体育运动,
目前已经成为了年轻人运动的新潮流.某俱乐部为了解年轻人爱好飞盘运动是否与性别有关,对该地区的年
轻人进行了简单随机抽样,得到如下列联表:
飞盘运动
性别 合计
不爱好 爱好
男 6 16 22
女 4 24 28
合计 10 40 50
(1)在上述爱好飞盘运动的年轻人中按照性别采用分层抽样的方法抽取10人,再从这10人中随机选取3人
访谈,记参与访谈的男性人数为X,求X的分布列和数学期望;
(2)依据小概率值 的独立性检验,能否认为爱好飞盘运动与性别有关联?如果把上表中所有数据都
扩大到原来的10倍,在相同的检验标准下,再用独立性检验推断爱好飞盘运动与性别之间的关联性,结论
还一样吗?请解释其中的原因.
资料整理【淘宝店铺:向阳百分百】附: ,其中 .
0.1 0.01 0.001
2.706 6.635 10.828
【答案】(1)答案见解析;(2)答案见解析;
【分析】(1)分别写出对相应概率列分布列求数学期望即可;
(2)先求 再根据数表对应判断相关性即可,对比两次 的值可以得出结论说明原因.
【详解】(1)样本中爱好飞盘运动的年轻人中男性 16 人,女性 24 人,比例为 ,
按照性别采用分层抽样的方法抽取 10 人,则抽取男性 4人,女性 6人.
随机变量 的取值为: .
,
,
随机变量 的分布列为
随机变量 的数学期望 .
(2)零假设为 :爱好飞盘运动与性别无关联.
根据列联表重的数据,经计算得到
根据小概率值 的独立性检验,没有充分证据推断 不成立,因此可以认为 成立,即认为爱好
飞盘运动与性别无关联.
列联表中所有数据都扩大到原来的10倍后,
根据小概率值 的独立性检验,推断 不成立,即认为爱好飞盘运动与性别有关联.
资料整理【淘宝店铺:向阳百分百】所以结论不一样,原因是每个数据都扩大为原来的 10 倍,相当于样本量变大为原来的 10 倍,导致推断
结论发生了变化.
20.(2017年全国普通高等学校招生统一考试文科数学(新课标2卷))海水养殖场进行某水产品的新、
旧网箱养殖方法的产量对比,收获时各随机抽取了100个网箱,测量各箱水产品的产量(单位:kg), 其
频率分布直方图如下:
(1)记A表示事件“旧养殖法的箱产量低于50kg”,估计A的概率;
(2)填写下面列联表,并根据列联表判断是否有99%的把握认为箱产量与养殖方法有关:
箱产量
箱产量<50kg
≥50kg
旧养殖
法
新养殖
法
(3)根据箱产量的频率分布直方图,对两种养殖方法的优劣进行较.
附:
P(K2≥k) 0.050 0.010 0.001
k 3.841 6.635 10.828
【答案】(1)0.62(2)有99%的把握 (3)新养殖法优于旧养殖法
【详解】试题分析:
(1)由频率近似概率值,计算可得旧养殖法的箱产量低于50kg的频率为0.62.据此,事件A的概率估计值为
0.62.
资料整理【淘宝店铺:向阳百分百】(2)由题意完成列联表,计算K2的观测值k= ≈15.705>6.635,则有99%的把握认为
箱产量与养殖方法有关.
(3)箱产量的频率分布直方图表明:新养殖法的箱产量较高且稳定,从而新养殖法优于旧养殖法.
试题解析:
(1)旧养殖法的箱产量低于50kg的频率为
(0.012+0.014+0.024+0.034+0.040)×5=0.62.
因此,事件A的概率估计值为0.62.
(2)根据箱产量的频率分布直方图得列联表
箱产量
箱产量<50kg
≥50kg
旧养殖法 62 38
新养殖法 34 66
K2的观测值k= ≈15.705.
由于15.705>6.635,故有99%的把握认为箱产量与养殖方法有关.
(3) 由频率分布直方图可得:
旧养殖法100个网箱产量的平均数 =
1
(27.5×0.012+32.5×0.014+37.5×0.024+42.5×0.034+47.5×0.040+52.5×0.032+57.5×0.032+62.5×0.012+67.5×0.01
2)×5
=5×9.42=47.1;
新养殖法100个网箱产量的平均数 =
2
(37.5×0.004+42.5×0.020+47.5×0.044+52.5×0.054+57.5×0.046+62.5×0.010+67.5×0.008)×5=5×10.47=
52.35;
比较可得: ,
1 2
故新养殖法更加优于旧养殖法.
点睛:利用频率分布直方图求众数、中位数和平均数时,应注意三点:①最高的小长方形底边中点的横坐
标即是众数;②中位数左边和右边的小长方形的面积和是相等的;③平均数是频率分布直方图的“重心”,
等于频率分布直方图中每个小长方形的面积乘以小长方形底边中点的横坐标之和.独立性检验得出的结论是
带有概率性质的,只能说结论成立的概率有多大,而不能完全肯定一个结论,因此才出现了临界值表,在
分析问题时一定要注意这点,不可对某个问题下确定性结论,否则就可能对统计计算的结果作出错误的解
释.
21.致敬百年,读书筑梦,某学校组织全校学生参加“学党史颂党恩,党史网络知识竞赛”活动.并对某
年级的100位学生竞赛成绩进行统计,得到如下人数分布表.规定:成绩在 内,为成绩优秀.
资料整理【淘宝店铺:向阳百分百】成绩
人数 5 10 15 25 20 20 5
(1)根据以上数据完成 列联表,并判断是否有90%的把握认为此次竞赛成绩与性别有关;
优秀 非优秀 合计
男 10
女 35
合计
(2)某班级实行学分制,为鼓励学生多读书,推出“读书抽奖额外赚学分”趣味活动方案:规定成绩达到优
秀的同学,可抽奖2次,每次中奖概率为 (每次抽奖互不影响,且 的值等于成绩分布表中不低于80分
的人数频率),中奖1次学分加5分,中奖2次学分加10分.若学生甲成绩在 内,请列出其本次
读书活动额外获得学分数 的分布列并求其数学期望.
参考公式: , .
附表:
0.150 0.100 0.050 0.010 0.005
2.072 2.706 3.841 6.635 7.879
【答案】(1)列联表见解析,没有90%的把握认为此次竞赛成绩与性别有关
(2)分布列见解析,期望值为2.5分
【分析】(1)根据成绩分段表得到优秀人数,结合列联表中的男生优秀人数求得女生优秀人数,然后可
以完成列联表;根据列联表数据,利用公式计算K2的观测值k,与相应临界值比较即可得到结论;
0
(2)先根据成绩分段表求得p的值,然后利用二项分布列计算X的各个取值的概率,列出分布列,根据分
布列计算期望即可.
【详解】(1)
优秀 非优秀 合计
男 10 40 50
女 15 35 50
合计 25 75 100
假设 : 此次竞赛成绩与性别无关.
资料整理【淘宝店铺:向阳百分百】,
所以没有90%的把握认为此次竞赛成绩与性别有关;
(2)p ,
P(X=0)=
P(X=5)= ,
P(X=10)= ,
X的分布列为:
X 0 5 10
P
期望值E(X)=5× +10× = 2.5(分)
22.(2023年山东省模拟数学试题)由中央电视台综合频道(CCTV-1)和唯众传媒联合制作的《开讲
啦》是中国首档青年电视公开课.每期节目由一位知名人士讲述自己的故事,分享他们对于生活和生命的
感悟,给予中国青年现实的讨论和心灵的滋养,讨论青年们的人生问题,同时也在讨论青春中国的社会问
题,受到了青年观众的喜爱.为了了解观众对节目的喜爱程度,电视台随机调查了A,B两个地区的100
名观众,得到如下所示的2×2列联表.
非常喜
喜欢 合计
欢
A 30 15
B x y
合计
已知在被调查的100名观众中随机抽取1名,该观众来自B地区且喜爱程度为“非常喜欢”的概率为0.
35.
(1)现从100名观众中根据喜爱程度用分层抽样的方法抽取20名进行问卷调查,则应抽取喜爱程度为“非
常喜欢”的A,B地区的人数各是多少?
(2)完成上述表格,并根据表格判断是否有95%的把握认为观众的喜爱程度与所在地区有关系.
(3)若以抽样调查的频率为概率,从A地区随机抽取3人,设抽到喜爱程度为“非常喜欢”的观众的人数为
X,求X的分布列和期望.
资料整理【淘宝店铺:向阳百分百】附: , ,
0.001
0.05 0.010
3.841 6.635 10.828
【答案】(1)从A地抽取6人,从B地抽取7人.
(2)没有95%的把握认为观众的喜爱程度与所在地区有关系.
(3)分布列见解析,期望为2.
【分析】(1)求出x的值,由分层抽样在各层的抽样比相同可得结果.
(2)补全 列联表,再根据独立性检验求解即可.
(3)由题意知 ,进而根据二项分布求解即可.
【详解】(1)由题意得 ,解得 ,
所以应从A地抽取 (人),从B地抽取 (人).
(2)完成表格如下:
非常喜
喜欢 合计
欢
A 30 15 45
B 35 20 55
合计 65 35 100
零假设为 :观众的喜爱程度与所在地区无关.
,
所以没有95%的把握认为观众的喜爱程度与所在地区有关系.
(3)从A地区随机抽取1人,抽到的观众的喜爱程度为“非常喜欢”的概率为 ,
从A地区随机抽取3人,则 ,X的所有可能取值为0,1,2,3,
则 ,
资料整理【淘宝店铺:向阳百分百】,
,
.
所以X的分布列为
X 0 1 2 3
P
方法1: .
方法2: .
【能力提升】
1.某中学有学生300人,其中一年级120人,二,三年级各90人,现要利用抽样方法取10人参加某项调
查,考虑选用简单随机抽样、分层抽样和系统抽样三种方案,使用简单随机抽样和分层抽样时,将学生按
一,二,三年级依次统一编号为1,2,…,300;使用系统抽样时,将学生统一编号为1,2,…,300,并将
整个编号依次分为10段.如果抽得的号码有下列四种情况:
①7,37,67,97,127,157,187,217,247,277;
②5,9,100,107,121,180,195,221,265,299;
③11,41,71,101,131,161,191,221,251,281;
④31,61,91,121,151,181,211,241,271,299.
关于上述样本的下列结论中,正确的是( )
A.②④都不能为分层抽样 B.①③都可能为分层抽样
C.①④都可能为系统抽样 D.②③都不能为系统抽样
【答案】B
【分析】根据系统抽样和分层抽样的定义分别进行判断即可.
资料整理【淘宝店铺:向阳百分百】【详解】若采用简单随机抽样,根据简单随机抽样的特点,1~300之间任意一个号码都有可能出现;
若采用分层抽样,则1~120号为一年级,121~210为二年级,211~300为三年级.且根据分层抽样的概念,
需要在1~120之间抽取4个,121~210与211~300之间各抽取3个;
若采用系统抽样,根据系统抽样的概念,需要在1~30,31~60,61~90,91~ 120,121~150,151~180,
181~210,211~240,241~270,271~300之间各抽一个.
①项,1~120之间有 4个,121~210之间有 3个,211~300之间有 3个,并且满足系统抽样的条件,所以
①项为系统抽样或分层抽样;
②项,1~120之间有 4个,121~210之间有 3个,211~300之间有 3个,可能为分层抽样;
③项,1~120之间有 4个,121~210之间有 3个,211~300之间有 3个,并且满足系统抽样的条件,所以
③项为系统抽样或分层抽样;
④项,第一个数据大于30,所以④项不可能为系统抽样,并且④项不满足分层抽样的条件.
综上所述,B选项正确.
【点睛】本题主要考查系统抽样和分层抽样,掌握系统抽样和分层抽样的定义是解题的关键,属于基础题.
(1)系统抽样适用于总体容量较大的情况.将总体平均分成若干部分,按事先确定的规则在各部分中抽取,
在起始部分抽样时采用简单随机抽样;
(2)分层抽样适用于已知总体是由差异明显的几部分组成的.将总体分成互不交叉的层,然后分层进行抽
取,各层抽样时采用简单随机抽样或系统抽样.
2.某乡镇实现脱贫目标后,在奔小康的道路上,继续大步前进,依托本地区苹果种植的优势,经过3年的
发展,苹果总产量翻了一番,统计苹果的品质得到了如下饼图:70,80是指苹果的外径,则以下说法中不
正确的是( )
A.80以上优质苹果所占比例增加
B.经过3年的努力,80以上优质苹果产量实现翻了一番的目标
C.70~80的苹果产量翻了一番
D.70以下次品苹果产量减少了一半
【答案】D
【分析】设原苹果总产量为 ,从而3年后苹果总产量为 ;根据饼图,分别计算出3年前和3年后各类
苹果的产量,从而可判断选项.
【详解】设原苹果总产量为 ,则经过3年的发展,苹果总产量为 ,
3年前80以上优质苹果所占比例 ,3年后80以上优质苹果所占比例 ,所占比例增加,故选项A
正确;
3年前80以上优质苹果的产量为 ,3年后80以上优质苹果的产量为 ,故80
资料整理【淘宝店铺:向阳百分百】以上优质苹果产量实现翻了一番的目标,选项B正确;
3年前70~80苹果的产量为 ,3年后70~80苹果的产量为 ,故70~80的苹果产
量翻了一番,选项C正确;
3年前70以下次品苹果的产量为 ,3年后70以下次品苹果的产量为 ,故70
以下次品苹果的产量没变,选项D错误.
3.(2023届湖南省联考数学试题)下列关于统计概率知识的判断,正确的是( )
A.将总体划分为2层,通过分层随机抽样,得到两层的样本平均数和样本方差分别为 和 ,
且已知 ,则总体方差
B.在研究成对数据的相关关系时,相关关系越强,相关系数 越接近于1
C.已知随机变量 服从正态分布 ,若 ,则
D.按从小到大顺序排列的两组数据:甲组: ;乙组: ,若这两组
数据的第30百分位数、第50百分位数都分别对应相等,则
【答案】C
【分析】对于A项,由分层抽样的方差公式判断即可;对于B项,运用 越大相关性越强可判断;对于C
项,由正态分布的对称性可求得结果;对于D项,运用百分位数计算公式即可求得结果.
【详解】对于A项,总体方差与样本容量有关,故A项错误;
对于B项,相关性越强, 越接近于1;故B项错误;
对于C项,若 ,则 ,所以 ,故C项正确;
对于D项,甲组:第30百分位数为30,第50百分位数为 ,乙组:第30百分位数为 ,第50百分
位数为 ,
所以 ,解得: ,故 .故D项错误.
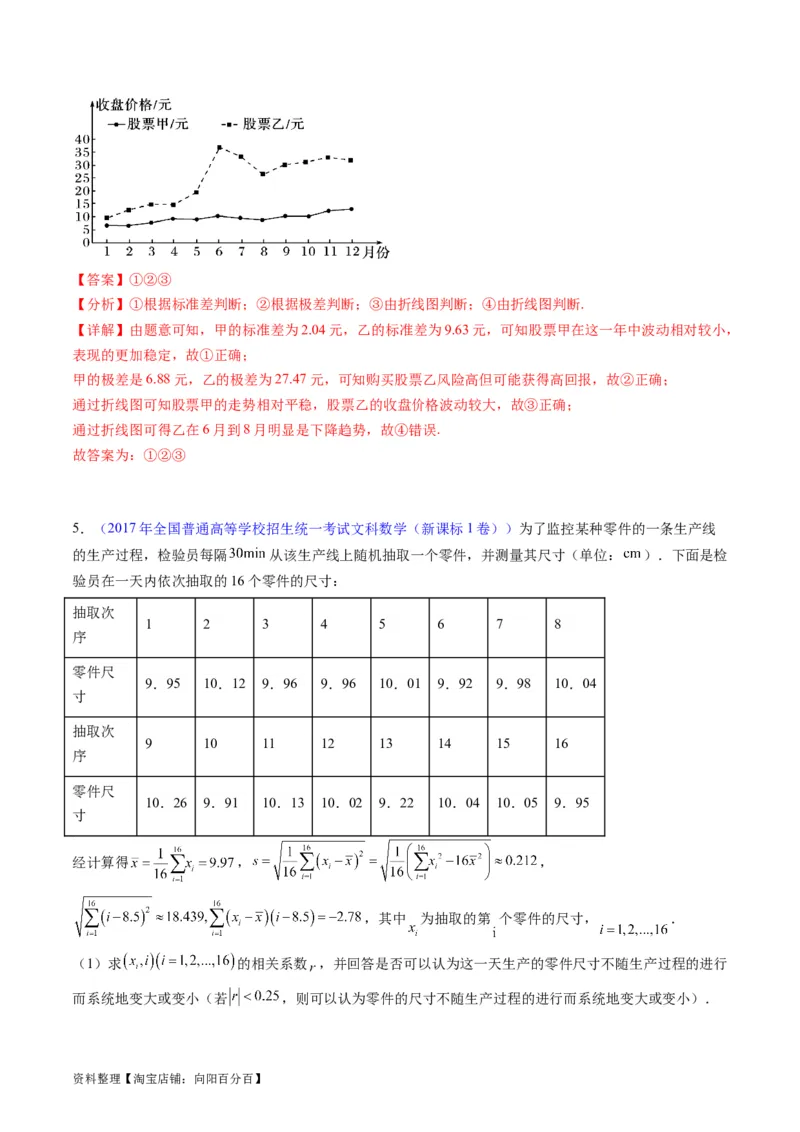
4.下面的折线图给出的是甲、乙两只股票在某年中每月的收盘价格,已知股票甲的极差是6.88元,标准
差为2.04元;股票乙的极差为27.47元,标准差为9.63元,根据这两只股票在这一年中的波动程度,给出
下列结论:①股票甲在这一年中波动相对较小,表现的更加稳定;②购买股票乙风险高但可能获得高回报;
③股票甲的走势相对平稳,股票乙的收盘价格波动较大;④两只股票在全年都处于上升趋势.其中正确的结
论是 (填序号).
资料整理【淘宝店铺:向阳百分百】【答案】①②③
【分析】①根据标准差判断;②根据极差判断;③由折线图判断;④由折线图判断.
【详解】由题意可知,甲的标准差为2.04元,乙的标准差为9.63元,可知股票甲在这一年中波动相对较小,
表现的更加稳定,故①正确;
甲的极差是6.88元,乙的极差为27.47元,可知购买股票乙风险高但可能获得高回报,故②正确;
通过折线图可知股票甲的走势相对平稳,股票乙的收盘价格波动较大,故③正确;
通过折线图可得乙在6月到8月明显是下降趋势,故④错误.
故答案为:①②③
5.(2017年全国普通高等学校招生统一考试文科数学(新课标1卷))为了监控某种零件的一条生产线
的生产过程,检验员每隔 从该生产线上随机抽取一个零件,并测量其尺寸(单位: ).下面是检
验员在一天内依次抽取的16个零件的尺寸:
抽取次
1 2 3 4 5 6 7 8
序
零件尺
9.95 10.12 9.96 9.96 10.01 9.92 9.98 10.04
寸
抽取次
9 10 11 12 13 14 15 16
序
零件尺
10.26 9.91 10.13 10.02 9.22 10.04 10.05 9.95
寸
经计算得 , ,
,其中 为抽取的第 个零件的尺寸, .
(1)求 的相关系数 ,并回答是否可以认为这一天生产的零件尺寸不随生产过程的进行
而系统地变大或变小(若 ,则可以认为零件的尺寸不随生产过程的进行而系统地变大或变小).
资料整理【淘宝店铺:向阳百分百】(2)一天内抽检零件中,如果出现了尺寸在 之外的零件,就认为这条生产线在这一天的生
产过程可能出现了异常情况,需对当天的生产过程进行检查.
(ⅰ)从这一天抽检的结果看,是否需对当天的生产过程进行检查?
(ⅱ)在 之外的数据称为离群值,试剔除离群值,估计这条生产线当天生产的零件尺寸的均
值与标准差.(精确到 )附:样本 的相关系数
, .
【答案】(1)可以;(2)(ⅰ)需要;(ⅱ) , .
【分析】(1)依公式求 ;
(2)(i)由 ,得抽取的第13个零件的尺寸在 以外,因此需对当天的生产
过程进行检查;(ii)剔除第13个数据,则均值的估计值为10.02,方差为0.09.
【详解】(1)由样本数据得 的相关系数为
.
由于 ,因此可以认为这一天生产的零件尺寸不随生产过程的进行而系统地变大或变小.
(2)(i)由于 ,
由样本数据可以看出抽取的第13个零件的尺寸在 以外,
因此需对当天的生产过程进行检查.
(ii)剔除离群值,即第13个数据,
剩下数据的平均数为 ,
这条生产线当天生产的零件尺寸的均值的估计值为10.02.
,
剔除第13个数据,剩下数据的样本方差为
,
这条生产线当天生产的零件尺寸的标准差的估计值为 .
【点睛】解答新颖的数学题时,一是通过转化,化“新”为“旧”;二是通过深入分析,多方联想,以
“旧”攻“新”;三是创造性地运用数学思想方法,以“新”制“新”,应特别关注创新题型的切入点和
生长点.
资料整理【淘宝店铺:向阳百分百】6.(2023届山东省模拟数学试题)某学校研究性学习小组在学习生物遗传学的过程中,为验证高尔顿提
出的关于儿子成年后身高y(单位: )与父亲身高x(单位: )之间的关系及存在的遗传规律,随机
抽取了5对父子的身高数据,如下表:
17
父亲身高 160 170 185 190
5
儿子身高 17
170 174 180 186
5
(1)根据表中数据,求出 关于 的线性回归方程,并利用回归直线方程分别确定儿子比父亲高和儿子比父
亲矮的条件,由此可得到怎样的遗传规律?
(2)记 ,其中 为观测值, 为预测值, 为对应 的残差.求
(1)中儿子身高的残差的和、并探究这个结果是否对任意具有线性相关关系的两个变量都成立?若成立加
以证明;若不成立说明理由.
参考数据及公式:
.
【答案】(1) , 时,儿子比父亲高; 时,儿子比父亲矮,
儿子身高有一个回归,回归到全种群平均高度的趋势.
(2)0;任意具有线性相关关系的变量 ,证明见解析
【分析】(1)根据已知求得回归方程的系数,即可得回归方程,解不等式可得到结论;
(2)结合题中数据进行计算,可求得儿子身高的残差的和,从而可得结论,结合回归方程系数的计算公
式即可证明.
【详解】(1)由题意得 ,
, ,所
以回归直线方程为 ,
令 得 ,即 时,儿子比父亲高;
令 得 ,即 时,儿子比父亲矮,
资料整理【淘宝店铺:向阳百分百】可得当父亲身高较高时,儿子平均身高要矮于父亲,即儿子身高有一个回归,回归到全种群平均高度的趋
势.
(2)由 可得 ,
所以 ,
又 ,所以 ,
结论:对任意具有线性相关关系的变量 ,
证明: .
7.(2023届广东省模拟数学试题)某高科技公司对其产品研发年投资额x(单位:百万元)与其年销售量
y(单位:千件)的数据进行统计,整理后得到如下统计表和散点图.
x 1 2 3 4 5 6
y 0.5 1 1.5 3 6 12
-0.7 0 0.4 1.1 1.8 2.5
(1)该公司科研团队通过分析散点图的特征后,计划分别用① 和② 两种方案作为年销售量
y关于年投资额x的回归分析模型,请根据统计表的数据,确定方案①和②的经验回归方程;(注:系数
b,a,d,c按四舍五入保留一位小数)
(2)根据下表中数据,用相关指数 (不必计算,只比较大小)比较两种模型的拟合效果哪个更好,并选
择拟合精度更高、更可靠的模型,预测当研发年投资额为8百万元时,产品的年销售量是多少?
经验回归方
程
残差平方和
资料整理【淘宝店铺:向阳百分百】18.29 0.65
参考公式及数据: , ,
,
, .
【答案】(1) ,
(2)30(千件)
【分析】(1)求出 ,根据公式计算出 得线性回归方程;求出 ,再求得系数 , ,代入得非线
性回归方程;
(2)根据(1)回归方程分别求得相关指数 ,比较可得,然后估算销售量即可.
【详解】(1)由题可得 , ,
, ,
所以 , ,
方案①回归方程 ,
对 两边取对数得: ,令 , 是一元线性回归方程.
,
,
,
方案②回归方程 ;
资料整理【淘宝店铺:向阳百分百】(2)方案①相关指数 ;
方案②相关指数 ,
(有此结论即给分),
故模型②的拟合效果更好,精度更高.
当研发年投资额为8百万元时,产品的年销售量 (千件).
8.某企业新研发了一种产品,产品的成本由原料成本及非原料成本组成.每件产品的非原料成本 (元)
与生产该产品的数量 (千件)有关,经统计得到如下数据:
x 1 2 3 4 5 6 7 8
y 56.5 31 22.75 17.8 15.95 14.5 13 12.5
根据以上数据绘制了散点图观察散点图,两个变量间关系考虑用反比例函数模型 和指数函数模型
分别对两个变量的关系进行拟合.已求得用指数函数模型拟合的回归方程为 ,
与x的相关系数 .
(1)用反比例函数模型求y关于x的回归方程;
(2)用相关系数判断上述两个模型哪一个拟合效果更好(精确到0.001),并用其估计产量为10千件时每件
产品的非原料成本;
(3)根据企业长期研究表明,非原料成本y服从正态分布 ,用样本平均数 作为 的估计值 ,用
样本标准差s作为 的估计值 ,若非原料成本y在 之外,说明该成本异常,并称落在
之外的成本为异样成本,此时需寻找出现异样成本的原因.利用估计值判断上述非原料成本数
据是否需要寻找出现异样成本的原因?
参考数据(其中 ):
资料整理【淘宝店铺:向阳百分百】0.34 0.115 1.53 184 5777.555 93.06 30.705 13.9
参考公式:对于一组数据 ,其回归直线 的斜率和截距的最小二乘估计
公式分别为: , ,相关系数 .
【答案】(1)
(2)反比例函数模型拟合效果更好,产量为10千件时每件产品的非原料成本约为11元,
(3)见解析
【分析】(1)令 ,则 可转化为 ,求出样本中心,回归方程的斜率,转化求回归方
程即可,
(2)求出 与 的相关系数 ,通过比较 ,可得用反比例函数模型拟合效果更好,然后将 代
入回归方程中可求结果
(3)利用已知数据求出样本标准差s,从而可得非原料成本y服从正态分布 ,再计算
,然后各个数据是否在此范围内,从而可得结论
【详解】(1)令 ,则 可转化为 ,
因为 ,
所以 ,
所以 ,所以 ,
所以y关于x的回归方程为
(2) 与 的相关系数为
资料整理【淘宝店铺:向阳百分百】因为 ,所以用反比例函数模型拟合效果更好,
把 代入回归方程得 (元),
所以产量为10千件时每件产品的非原料成本约为11元
(3)因为 ,所以 ,
因为样本标准差为 ,
所以 ,
所以非原料成本y服从正态分布 ,
所以
因为 在 之外,所以需要此非原料成本数据寻找出现异样成本的原因.
9.(2023届湖北省联考数学试题)某数学兴趣小组为研究本校学生数学成绩与语文成绩的关系,采取有
放回的简单随机抽样,从学校抽取样本容量为200的样本,将所得数学成绩与语文成绩的样本观测数据整
理如下:
语文成绩
合计
优
不优秀
秀
数 优秀 50 30 80
学
成
不优秀 40 80 120
绩
合计 90 110 200
(1)根据 的独立性检验,能否认为数学成绩与语文成绩有关联?
(2)在人工智能中常用 表示在事件 发生的条件下事件 发生的优势,在统计中称为似然
比.现从该校学生中任选一人, 表示“选到的学生语文成绩不优秀”, 表示“选到的学生数学成绩不优
资料整理【淘宝店铺:向阳百分百】秀”请利用样本数据,估计 的值.
(3)现从数学成绩优秀的样本中,按分层抽样的方法选出8人组成一个小组,从抽取的8人里再随机抽取3
人参加数学竞赛,求这3人中,语文成绩优秀的人数 的概率分布列及数学期望.
附:
【答案】(1)认为数学成绩与语文成绩有关;
(2) ;
(3)分布列见解析, .
【分析】(1)零假设 后,计算 的值与 比较即可;
(2)根据条件概率公式计算即可;
(3)分层抽样后运用超几何分布求解.
【详解】(1)零假设 :数学成绩与语文成绩无关.
据表中数据计算得:
根据小概率值 的 的独立性检验,我们推断 不成立,而认为数学成绩与语文成绩有关;
(2)∵ ,
∴估计 的值为 ;
(3)按分层抽样,语文成绩优秀的5人,语文成绩不优秀的3人,随机变量 的所有可能取值为 .
, ,
, ,
∴ 的概率分布列为:
0 1 2 3
资料整理【淘宝店铺:向阳百分百】∴数学期望 .
10.(2023届湖南省适应性考试数学试题)我市为了解学生体育运动的时间长度是否与性别因素有关,从
某几所学校中随机调查了男、女生各100名的平均每天体育运动时间,得到如下数据:
分钟
(0,40] (40,60] (60,90] (90,120]
性别
女生 10 40 40 10
男生 5 25 40 30
根据学生课余体育运动要求,平均每天体育运动时间在(60,120]内认定为“合格”,否则被认定为“不
合格”,其中,平均每天体育运动时间在(90,120]内认定为“良好”.
(1)完成下列2 2列联表,并依据小概率值 的独立性检验,分析学生体育运动时间与性别因素有
无关联;
不合格 合格 合计
女生
男生
合计
(2)从女生平均每天体育运动时间在 的100人中用分层抽样的方法抽取20人,
再从这20人中随机抽取2人,记 为2人中平均每天体育运动时间为“良好”的人数,求 的分布列及
数学期望;
(3)从全市学生中随机抽取100人,其中平均每天体育运动时间为“良好”的人数设为 ,记“平均每天体
育运动时间为'良好'的人数为 ”的概率为 ,视频率为概率,用样本估计总体,求 的表达
式,并求 取最大值时对应 的值.
附: ,其中 .
0.010 0.005 0.001
6.635 7.879 10.828
【答案】(1)列联表见解析,认为性别因素与学生体育运动时间有关联,此推断犯错误的概率不大于 ;
(2)分布列见解析,数学期望为 ;
资料整理【淘宝店铺:向阳百分百】(3) ,
【分析】(1)通过题意可得列联表,计算 的值,可得结论;
(2)根据分层抽样的比例可得抽取的女生平均每天体育运动时间在 的人数,
确定 的取值,根据超几何分布可求得每个值对应的概率,即得分布列,从而计算数学期望;
(3)通过题意可得 满足二项分布,能得到 ,然后通过作商法可得到当 时,
,当 时, ,即可得到答案
【详解】(1)由题意可知,2 2列联表如下表
不合格 合格 合计
女生 50 50 100
男生 30 70 100
合计 80 120 200
零假设为 :性别与学生体育运动时间无关联.
根据列联表中的数据,经计算得到
,
根据小概率值 的独立性检验,我们推断 不成立即认为性别因素与学生体育运动时间有关联,
此推断犯错误的概率不大于 ;
(2)抽取的20人中,女生平均每天运动时间在 的人数分别为2人,8人,
8人,2人,易知 的所有可能取值为 ,
, , ,
所以 的分布列为
0 1 2
所以数学期望为 ;
(3)平均每天运动时间在 的频率为 ,
由题意可知 ,
所以 ,
资料整理【淘宝店铺:向阳百分百】由 ,得 ,
所以,当 时, ,即 ,
当 时, ,即 ,
所以 ,即 取最大值时, .
11.(2023届湖南省质量检测数学试题)为了研究学生每天整理数学错题情况,某课题组在某市中学生中
随机抽取了100名学生调查了他们期中考试的数学成绩和平时整理数学错题情况,并绘制了下列两个统计
图表,图1为学生期中考试数学成绩的频率分布直方图,图2为学生一个星期内整理数学错题天数的扇形
图.若本次数学成绩在110分及以上视为优秀,将一个星期有4天及以上整理数学错题视为“经常整理”,
少于4天视为“不经常整理”.已知数学成绩优秀的学生中,经常整理错题的学生占 .
数学成绩优秀 数学成绩不优秀 合计
经常整理
不经常整理
合计
(1)求图1中 的值以及学生期中考
试数学成绩的上四分位数;
(2)根据图1、图2中的数据,补全上方 列联表,并根据小概率值 的独立性检验,分析数学成绩
优秀与经常整理数学错题是否有关?
(3)用频率估计概率,在全市中学生中按“经常整理错题”与“不经常整理错题”进行分层抽样,随机抽取
5名学生,再从这5名学生中随机抽取2人进行座谈.求这2名同学中经常整理错题且数学成绩优秀的人数
X的分布列和数学期望.
附:
资料整理【淘宝店铺:向阳百分百】【答案】(1) , 分
(2)有关
(3)分布列见解析,
【分析】(1)利用频率分布直方图各个小矩形的面积和为1,求出 的值,进而可求出上四分位数;
(2)先求出数学优秀和不优秀的人,常整理错题和不经常整理错题的人,得到 列联表,根据 列联
表求出 值,从而得出判断;
(3)先求出 的可能取值,并求出相应取值的概率,从而求出分布列和期望.
【详解】(1)由题意可得 ,
解得 ,
学生期中考试数学成绩的上四分位数为: 分;
(2)数学成绩优秀的有 人,不优秀的人 人,经常整理错题的有
人,不经常整理错题的是 人,经常整理错题且成绩优秀的有
人,则
数学成绩优秀 数学成绩不优秀 合计
经常整理 35 25 60
不经常整理 15 25 40
合计 50 50 100
零假设为 :数学成绩优秀与经常整理数学错题无关,
根据列联表中的数据,经计算得到可得 ,
根据小概率值 的独立性检验,我们推断 不成立,
即认为数学成绩优秀与经常整理数学错题有关联,此推断犯错误的概率不大于 ;
(3)由分层抽样知,随机抽取的5名学生中经常整理错题的有3人,不经常整理错题的有2人,则 可能
取为0,1,2,
经常整理错题的3名学生中,恰抽到k人记为事件 ,则
参与座谈的2名学生中经常整理错题且数学成绩优秀的恰好抽到 人记为事件
则 , , , ,
, ,
资料整理【淘宝店铺:向阳百分百】,
,
,
故X的分布列如下:
X 0 1 2
P
则可得X的数学期望为
12.某公司对40名试用员工进行业务水平测试,根据测试成绩评定是否正式录用以及正式录用后的岗位等
级,测试分笔试和面试两个环节.笔试环节所有40名试用员工全部参加;参加面试环节的员工由公司按规
则确定.公司对40名试用员工的笔试得分 笔试得分都在 内 进行了统计分析,得到如下的频率分
步直方图和 列联表.
男 女 合计
优
8
得分不低于90分
良
12
得分低于90分
合计 40
(1)请完成上面的 列联表,并判断是否有 的把握认为“试用员工的业务水平优良与否”与性别有关;
(2)公司决定:在笔试环节中得分低于85分的员工直接淘汰,得分不低于85分的员工都正式录用.笔试得
资料整理【淘宝店铺:向阳百分百】分在 内的岗位等级直接定为一级 无需参加面试环节 ;笔试得分在 内的岗位等级初定为二
级,但有 的概率通过面试环节将二级晋升为一级;笔试分数在 内的岗位等级初定为三级,但有
的概率通过面试环节将三级晋升为二级.若所有被正式录用且岗位等级初定为二级和三级的员工都需参加
面试.已知甲、乙为该公司的两名试用员工,以频率视为概率.
①若甲已被公司正式录用,求甲的最终岗位等级为一级的概率;
②若乙在笔试环节等级初定为二级,求甲的最终岗位等级不低于乙的最终岗位等级的概率.
参考公式: ,
【答案】(1)表格见解析,没有;
(2)① ;② .
【分析】(1)根据频率直方图求出得分不低于90分的人数,结合所给的公式和数据进行求解判断即可;
(2)①根据古典概型的计算公式,结合和事件的概率公式进行求解即可;
②分类运算即可得解.
【详解】(1)得分不低于90分的人数为: ,所以填表如下:
男 女 合计
优 得分不低于90分 8 4 12
1
良 得分低于90分 12 28
6
2
合计 16 40
4
所以 ,
因此没有 的把握认为“试用员工的业务水平优良与否”与性别有关;
(2)不低于85分的员工的人数为: ,
直接定为一级的概率为 ,
岗位等级初定为二级的概率为: ,
岗位等级初定为三级的概率为: .
资料整理【淘宝店铺:向阳百分百】①甲的最终岗位等级为一级的概率为: ;
②甲的最终岗位等级不低于乙的最终岗位等级的概率为:
.
13.(2023届浙江省模拟数学试题)2022年卡塔尔世界杯决赛圈共有32队参加,其中欧洲球队有13支,
分别是德国、丹麦、法国、西班牙、英格兰、克罗地亚、比利时、荷兰、塞尔维亚、瑞士、葡萄牙、波兰、
威尔士.世界杯决赛圈赛程分为小组赛和淘汰赛,当进入淘汰赛阶段时,比赛必须要分出胜负.淘汰赛规
则如下:在比赛常规时间90分钟内分出胜负,比赛结束,若比分相同,则进入30分钟的加时赛.在加时
赛分出胜负,比赛结束,若加时赛比分依然相同,就要通过点球大战来分出最后的胜负.点球大战分为2
个阶段.第一阶段:前5轮双方各派5名球员,依次踢点球,以5轮的总进球数作为标准(非必要无需踢
满5轮),前5轮合计踢进点球数更多的球队获得比赛的胜利.第二阶段:如果前5轮还是平局,进入
“突然死亡”阶段,双方依次轮流踢点球,如果在该阶段一轮里,双方都进球或者双方都不进球,则继续
下一轮,直到某一轮里,一方罚进点球,另一方没罚进,比赛结束,罚进点球的一方获得最终的胜利.
下表是2022年卡塔尔世界杯淘汰赛阶段的比赛结果:
淘汰赛 比赛结果 淘汰赛 比赛结果
荷兰 美国 克罗地亚 巴西
阿根廷 澳大利亚 荷兰 阿根廷
1/4决赛
法国 波兰 摩洛哥 葡萄牙
英格兰 塞内加尔 英格兰 法国
1/8决赛
日本 克罗地亚 阿根廷 克罗地亚
半决赛
巴西 韩国 法国 摩洛哥
摩洛哥 西班牙 季军赛 克罗地亚 摩洛哥
葡萄牙 瑞士 决赛 阿根廷 法国
注:“阿根廷 法国”表示阿根廷与法国在常规比赛及加时赛的比分为 ,在点球大战中阿根廷
战胜法国.
(1)请根据上表估计在世界杯淘汰赛阶段通过点球大战分出胜负的概率.
(2)根据题意填写下面的 列联表,并通过计算判断是否能在犯错的概率不超过0.01的前提下认为“32支
决赛圈球队闯入8强”与是否为欧洲球队有关.
欧洲球 其他球队 合计
资料整理【淘宝店铺:向阳百分百】队
闯入8强
未闯入8强
合计
(3)若甲、乙两队在淘汰赛相遇,经过120分钟比赛未分出胜负,双方进入点球大战.已知甲队球员每轮踢
进点球的概率为p,乙队球员每轮踢进点球的概率为 ,求在点球大战中,两队前2轮比分为 的条件
下,甲队在第一阶段获得比赛胜利的概率(用p表示).
参考公式:
0.1 0.05 0.01 0.005 0.001
2.706 3.841 6.635 7.879 10.828
【答案】(1) ;(2)分布列见解析,不能;;(3)
【分析】(1)根据古典概型概率公式求解;
(2)由条件数据填写列联表,提出零假设,计算 ,比较其与临界值的大小,确定是否接受假设;
(3)根据实际比赛进程,根据独立重复试验概率公式,独立事件概率公式和互斥事件概率公式求概率.
【详解】(1)由题意知卡塔尔世界杯淘汰赛共有16场比赛,其中有5场比赛通过点球大战决出胜负,
所以估计在世界杯淘汰赛阶段通过点球大战分出胜负的概率 ;
(2)下面为 列联表:
欧洲球
其他球队 合计
队
进入8强 5 3 8
未进入8强 8 16 24
合计 13 19 32
零假设 支决赛圈球队闯入8强与是否为欧洲球队无关.
.
根据小概率值 的独立性检验,没有充分证据推断 不成立,
即不能在犯错的概率不超过0.01的前提下认为“决赛圈球队闯入8强”与是否为欧洲球队有关.
(3)根据实际比赛进程,假定点球大战中由甲队先踢.两队前2轮比分为 的条件下,甲在第一阶段获
资料整理【淘宝店铺:向阳百分百】得比赛胜利,则后3轮有5种可能的比分, .
当后3轮比分为 时,甲乙两队均需踢满5轮, .
当后3轮比分为 时,有如下3种情况:
3 4 5 3 4 5 3 4 5
甲 √ √ 甲 √ × √ 甲 × √ √
乙 × × 乙 × × 乙 × ×
则 .
当后3轮比分为 时,有如下6种情况:
3 4 5 3 4 5 3 4 5
甲 √ √ × 甲 √ √ × 甲 √ × √
乙 √ × × 乙 × √ × 乙 √ × ×
3 4 5 3 4 5 3 4 5
甲 √ × √ 甲 × √ √ 甲 × √ √
乙 × √ × 乙 √ × × 乙 × √ ×
则 .
当后3轮比分为 时,有如下2种情况:
3 4 5 3 4 5
甲 √ √ √ 甲 √ √ √
乙 √ × 乙 × √
则
当后3轮比分为 时,有如下1种情况:
3 4 5
资料整理【淘宝店铺:向阳百分百】甲 √ √ √
乙 √ √ ×
则 .
综上,在点球大战中两队前2轮比分为 的条件下,甲在第一阶段获得比赛胜利的概率
.
【点睛】方法点睛:有关古典概型的概率问题,关键是正确求出基本事件总数和所求事件包含的基本事件
数.
(1)基本事件总数较少时,用列举法把所有基本事件一一列出时,要做到不重复、不遗漏,可借助“树
状图”列举;
(2)注意区分排列与组合,以及计数原理的正确使用.
14.(2023届福建省联考数学试题)中国在第75届联合国大会上承诺,将采取更加有力的政策和措施,
力争于2030年之前使二氧化碳的排放达到峰值,努力争取2060年之前实现碳中和(简称“双碳目标”),
此举展现了我国应对气候变化的坚定决心,预示着中国经济结构和经济社会运转方式将产生深刻变革,极
大促进我国产业链的清洁化和绿色化.新能源汽车、电动汽车是重要的战略新兴产业,对于实现“双碳目
标”具有重要的作用.为了解某一地区电动汽车销售情况,一机构根据统计数据,用最小二乘法得到电动汽
车销量 (单位:万台)关于 (年份)的线性回归方程为 ,且销量 的方差为 ,
年份 的方差为 .
(1)求 与 的相关系数 ,并据此判断电动汽车销量 与年份 的相关性强弱;
(2)该机构还调查了该地区90位购车车主的性别与购车种类情况,得到的数据如下表:
购买电动汽
性别 购买非电动汽车 总计
车
男性 39 6 45
女性 30 15 45
总计 69 21 90
依据小概率值 的独立性检验,能否认为购买电动汽车与车主性别有关;
(3)在购买电动汽车的车主中按照性别进行分层抽样抽取7人,再从这7人中随机抽取3人,记这3人中,
男性的人数为 ,求 的分布列和数学期望.
①参考数据: ;
资料整理【淘宝店铺:向阳百分百】②参考公式:(i)线性回归方程: ,其中 ;
(ii)相关系数: ,若 ,则可判断 与 线性相关较强.
(iii) ,其中 .附表:
【答案】(1) , 与 线性相关较强
(2)认为购买电动汽车与车主性别有关,此推断犯错误的概率不大于
(3)分布列答案见解析,数学期望:
【分析】(1)利用相关系数 的求解公式,并转化为 和方差之间的关系,代入计算即可;
(2)直接利用独立性检验公式求出 ,根据零点假设定理判断购买电动汽车与车主性别是否有关;
(3)采用分层抽样先得出男性车主和女性车主的选取人数,得出 可能取值0,1,2,分别求出对应概率,即
可得 的分布列,再结合期望公式,即可求解.
【详解】(1)(1)相关系数为
故 与 线性相关较强.
(2)零假设为 :购买电动汽车与车主性别相互独立,
即购买电动汽车与车主性别无关.
所以依据小概率值 的独立性检验,我们推断 不成立,
资料整理【淘宝店铺:向阳百分百】即认为购买电动汽车与车主性别有关,此推断犯错误的概率不大于 .
(3)抽样比 ,男性车主选取2人,女性车主选取5人,则 的可能取值为 故
, ,
故 的分布列为:
0 1 2
.
【真题感知】
1.(2023年高考全国甲卷数学(文)真题)一项试验旨在研究臭氧效应,试验方案如下:选40只小白鼠,
随机地将其中20只分配到试验组,另外20只分配到对照组,试验组的小白鼠饲养在高浓度臭氧环境,对
照组的小白鼠饲养在正常环境,一段时间后统计每只小白鼠体重的增加量(单位:g).试验结果如下:
对照组的小白鼠体重的增加量从小到大排序为
15.2 18.8 20.2 21.3 22.5 23.2 25.8 26.5 27.5 30.1
32.6 34.3 34.8 35.6 35.6 35.8 36.2 37.3 40.5 43.2
试验组的小白鼠体重的增加量从小到大排序为
7.8 9.2 11.4 12.4 13.2 15.5 16.5 18.0 18.8 19.2
19.8 20.2 21.6 22.8 23.6 23.9 25.1 28.2 32.3 36.5
(1)计算试验组的样本平均数;
(2)(ⅰ)求40只小白鼠体重的增加量的中位数m,再分别统计两样本中小于m与不小于m的数据的个数,
完成如下列联表
对照组
试验组
(ⅱ)根据(i)中的列联表,能否有95%的把握认为小白鼠在高浓度臭氧环境中与在正常环境中体重的增
加量有差异?
附: ,
资料整理【淘宝店铺:向阳百分百】0.100 0.050 0.010
2.706 3.841 6.635
【答案】(1)
(2)(i) ;列联表见解析,(ii)能
【分析】(1)直接根据均值定义求解;
(2)(i)根据中位数的定义即可求得 ,从而求得列联表;
(ii)利用独立性检验的卡方计算进行检验,即可得解.
【详解】(1)试验组样本平均数为:
(2)(i)依题意,可知这40只小鼠体重的中位数是将两组数据合在一起,从小到大排后第20位与第21
位数据的平均数,
由原数据可得第11位数据为 ,后续依次为 ,
故第20位为 ,第21位数据为 ,
所以 ,
故列联表为:
合计
对照
6 14 20
组
试验
14 6 20
组
合计 20 20 40
(ii)由(i)可得, ,
所以能有 的把握认为小白鼠在高浓度臭氧环境中与在正常环境中体重的增加量有差异.
2.(2022年全国新高考II卷数学试题)在某地区进行流行病学调查,随机调查了100位某种疾病患者的
年龄,得到如下的样本数据的频率分布直方图:
资料整理【淘宝店铺:向阳百分百】(1)估计该地区这种疾病患者的平均年龄(同一组中的数据用该组区间的中点值为代表);
(2)估计该地区一位这种疾病患者的年龄位于区间 的概率;
(3)已知该地区这种疾病的患病率为 ,该地区年龄位于区间 的人口占该地区总人口的 .从该
地区中任选一人,若此人的年龄位于区间 ,求此人患这种疾病的概率.(以样本数据中患者的年龄
位于各区间的频率作为患者的年龄位于该区间的概率,精确到0.0001).
【答案】(1) 岁;
(2) ;
(3) .
【分析】(1)根据平均值等于各矩形的面积乘以对应区间的中点值的和即可求出;
(2)设 {一人患这种疾病的年龄在区间 },根据对立事件的概率公式 即可解出;
(3)根据条件概率公式即可求出.
【详解】(1)平均年龄
(岁).
(2)设 {一人患这种疾病的年龄在区间 },所以
.
(3)设 “任选一人年龄位于区间[40,50)”, “从该地区中任选一人患这种疾病”,
则由已知得:
,
则由条件概率公式可得
从该地区中任选一人,若此人的年龄位于区间 ,此人患这种疾病的概率为
.
3.(2023年新课标全国Ⅱ卷数学真题)某研究小组经过研究发现某种疾病的患病者与未患病者的某项医
资料整理【淘宝店铺:向阳百分百】学指标有明显差异,经过大量调查,得到如下的患病者和未患病者该指标的频率分布直方图:
利用该指标制定一个检测标准,需要确定临界值c,将该指标大于c的人判定为阳性,小于或等于c的人判
定为阴性.此检测标准的漏诊率是将患病者判定为阴性的概率,记为 ;误诊率是将未患病者判定为阳
性的概率,记为 .假设数据在组内均匀分布,以事件发生的频率作为相应事件发生的概率.
(1)当漏诊率 %时,求临界值c和误诊率 ;
(2)设函数 ,当 时,求 的解析式,并求 在区间 的最小值.
【答案】(1) , ;
(2) ,最小值为 .
【分析】(1)根据题意由第一个图可先求出 ,再根据第二个图求出 的矩形面积即可解出;
(2)根据题意确定分段点 ,即可得出 的解析式,再根据分段函数的最值求法即可解出.
【详解】(1)依题可知,左边图形第一个小矩形的面积为 ,所以 ,
所以 ,解得: ,
.
(2)当 时,
;
当 时,
,
故 ,
所以 在区间 的最小值为 .
资料整理【淘宝店铺:向阳百分百】4.(2022年全国高考乙卷数学(理)试题)某地经过多年的环境治理,已将荒山改造成了绿水青山.为
估计一林区某种树木的总材积量,随机选取了10棵这种树木,测量每棵树的根部横截面积(单位: )
和材积量(单位: ),得到如下数据:
样本号i 1 2 3 4 5 6 7 8 9 10 总和
根部横截面积 0.04 0.06 0.04 0.08 0.08 0.05 0.05 0.07 0.07 0.06 0.6
材积量 0.25 0.40 0.22 0.54 0.51 0.34 0.36 0.46 0.42 0.40 3.9
并计算得 .
(1)估计该林区这种树木平均一棵的根部横截面积与平均一棵的材积量;
(2)求该林区这种树木的根部横截面积与材积量的样本相关系数(精确到0.01);
(3)现测量了该林区所有这种树木的根部横截面积,并得到所有这种树木的根部横截面积总和为 .已
知树木的材积量与其根部横截面积近似成正比.利用以上数据给出该林区这种树木的总材积量的估计值.
附:相关系数 .
【答案】(1) ;
(2)
(3)
【分析】(1)计算出样本的一棵根部横截面积的平均值及一棵材积量平均值,即可估计该林区这种树木
平均一棵的根部横截面积与平均一棵的材积量;
(2)代入题给相关系数公式去计算即可求得样本的相关系数值;
(3)依据树木的材积量与其根部横截面积近似成正比,列方程即可求得该林区这种树木的总材积量的估
计值.
【详解】(1)样本中10棵这种树木的根部横截面积的平均值
样本中10棵这种树木的材积量的平均值
据此可估计该林区这种树木平均一棵的根部横截面积为 ,
平均一棵的材积量为
资料整理【淘宝店铺:向阳百分百】(2)
则
(3)设该林区这种树木的总材积量的估计值为 ,
又已知树木的材积量与其根部横截面积近似成正比,
可得 ,解之得 .
则该林区这种树木的总材积量估计为 .
5.(2022年全国新高考I卷数学试题)一医疗团队为研究某地的一种地方性疾病与当地居民的卫生习惯
(卫生习惯分为良好和不够良好两类)的关系,在已患该疾病的病例中随机调查了100例(称为病例组),
同时在未患该疾病的人群中随机调查了100人(称为对照组),得到如下数据:
不够良
良好
好
病例组 40 60
对照组 10 90
(1)能否有99%的把握认为患该疾病群体与未患该疾病群体的卫生习惯有差异?
(2)从该地的人群中任选一人,A表示事件“选到的人卫生习惯不够良好”,B表示事件“选到的人患有该
疾病”. 与 的比值是卫生习惯不够良好对患该疾病风险程度的一项度量指标,记该指标
为R.
(ⅰ)证明: ;
(ⅱ)利用该调查数据,给出 的估计值,并利用(ⅰ)的结果给出R的估计值.
附 ,
资料整理【淘宝店铺:向阳百分百】0.050 0.010 0.001
k 3.841 6.635 10.828
【答案】(1)答案见解析
(2)(i)证明见解析;(ii) ;
【分析】(1)由所给数据结合公式求出 的值,将其与临界值比较大小,由此确定是否有99%的把握认为
患该疾病群体与未患该疾病群体的卫生习惯有差异;(2)(i) 根据定义结合条件概率公式即可完成证明;(ii)
根据(i)结合已知数据求 .
【详解】(1)由已知 ,
又 , ,
所以有99%的把握认为患该疾病群体与未患该疾病群体的卫生习惯有差异.
(2)(i)因为 ,
所以
所以 ,
(ii)
由已知 , ,
又 , ,
所以 .
6.(2020年全国统一高考数学试卷(理科)(新课标Ⅲ))在一组样本数据中,1,2,3,4出现的频率
分别为 ,且 ,则下面四种情形中,对应样本的标准差最大的一组是( )
A. B.
C. D.
【答案】B
【分析】计算出四个选项中对应数据的平均数和方差,由此可得出标准差最大的一组.
【详解】对于A选项,该组数据的平均数为 ,
资料整理【淘宝店铺:向阳百分百】方差为 ;
对于B选项,该组数据的平均数为 ,
方差为 ;
对于C选项,该组数据的平均数为 ,
方差为 ;
对于D选项,该组数据的平均数为 ,
方差为 .
因此,B选项这一组的标准差最大.
【点睛】本题考查标准差的大小比较,考查方差公式的应用,考查计算能力,属于基础题.
7.(2020年全国统一高考数学试卷(文科)(新课标Ⅲ))设一组样本数据x,x,…,xn的方差为
1 2
0.01,则数据10x,10x,…,10xn的方差为( )
1 2
A.0.01 B.0.1 C.1 D.10
【答案】C
【分析】根据新数据与原数据关系确定方差关系,即得结果.
【详解】因为数据 的方差是数据 的方差的 倍,
所以所求数据方差为
【点睛】本题考查方差,考查基本分析求解能力,属基础题.
8.(2019年全国统一高考数学试卷(理科)(新课标Ⅱ))演讲比赛共有9位评委分别给出某选手的原
始评分,评定该选手的成绩时,从9个原始评分中去掉1个最高分、1个最低分,得到7个有效评分.7个有
效评分与9个原始评分相比,不变的数字特征是
A.中位数 B.平均数
C.方差 D.极差
【答案】A
【分析】可不用动笔,直接得到答案,亦可采用特殊数据,特值法筛选答案.
【详解】设9位评委评分按从小到大排列为 .
则①原始中位数为 ,去掉最低分 ,最高分 ,后剩余 ,
中位数仍为 , A正确.
②原始平均数 ,后来平均数
平均数受极端值影响较大, 与 不一定相同,B不正确
资料整理【淘宝店铺:向阳百分百】③
由②易知,C不正确.
④原极差 ,后来极差 可能相等可能变小,D不正确.
【点睛】本题旨在考查学生对中位数、平均数、方差、极差本质的理解.
资料整理【淘宝店铺:向阳百分百】

