 夜雨聆风
夜雨聆风





文档分块策略对RAG系统可靠性的影响系统性分析
arxiv:http://arxiv.org/abs/2601.14123

这篇论文针对工业级RAG系统中文档分块(chunking)这一常被忽视但关键的设计决策进行了系统性评估。论文在Natural Questions数据集上,使用标准工业配置(SPLADE检索器 + Mistral-8B生成器),全面测试了分块方法、大小、重叠和上下文长度对问答可靠性的影响。以下是核心解读:
一、研究动机:为何关注分块策略?
在工业部署中,RAG系统面临严格约束:
- 延迟要求:用户期望秒级响应
- 存储成本:索引大小直接影响基础设施开销
- 可维护性:配置需简洁、可解释
尽管检索和LLM研究丰富,分块策略常依赖经验法则(如”512 tokens”),缺乏数据驱动的指导。本研究填补这一空白,提供可部署的实践指南。
二、实验设计:控制变量的端到端评估
1. 标准工业管道(图1)
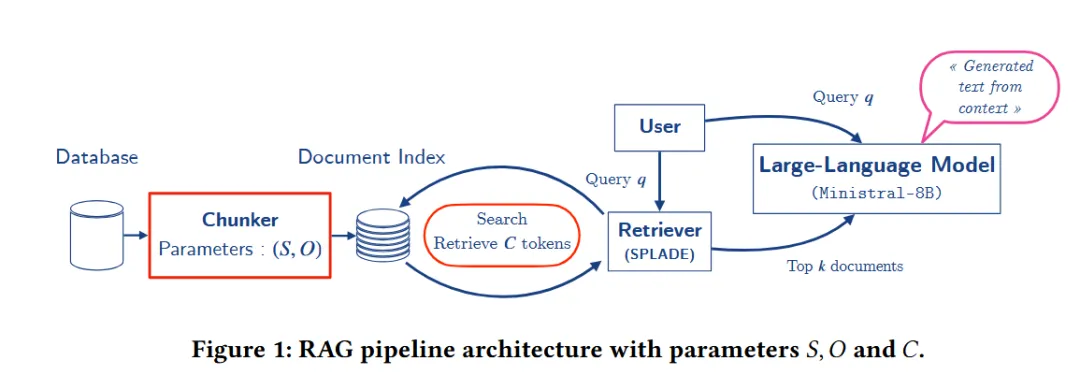
- 关键创新:”填满预算”(fill-to-budget)策略:按排名顺序追加分块直至达到token预算C,消除固定k值的偏差,确保不同分块大小间的公平比较
2. 四种分块方法系统对比
|
Token |
固定大小滑动窗口(50-500 tokens) |
基线方法,简单但破坏语义边界 |
|
Sentence |
严格保留句子边界,不分割句子 |
推荐默认:平衡性能与成本 |
|
Semantic |
句子级合并(余弦相似度>0.5),保持主题连贯 |
大上下文(>5k tokens)时略有优势 |
|
Code |
结构感知解析(函数/类边界) |
仅适用于源代码,文本任务表现差 |
3. 评估维度
- 语义质量:BERTScore(vs. 参考答案)
- 事实准确性:精确匹配(EM,标准化后)
- 可靠性指标:弃权率(None Ratio)— 模型输出”NONE”的比例,反映系统对不确定性的诚实度
三、四大核心发现
🔴 发现1:重叠(Overlap)增加成本但无收益
- 实证结果:10–20%重叠对BERTScore/EM无显著提升(|Δ| ≤ 0.004)
- 机制解释:在句子感知管道中,边界溢出很少改变top-C内容;重叠主要引入近似重复,稀释检索信号
- 成本代价:重叠比例r使分块数膨胀1/(1−r)倍(r=0.2 → 1.25×索引大小)
- 实践建议:默认使用0%重叠,除非有证据表明特定检索器受益于边界冗余
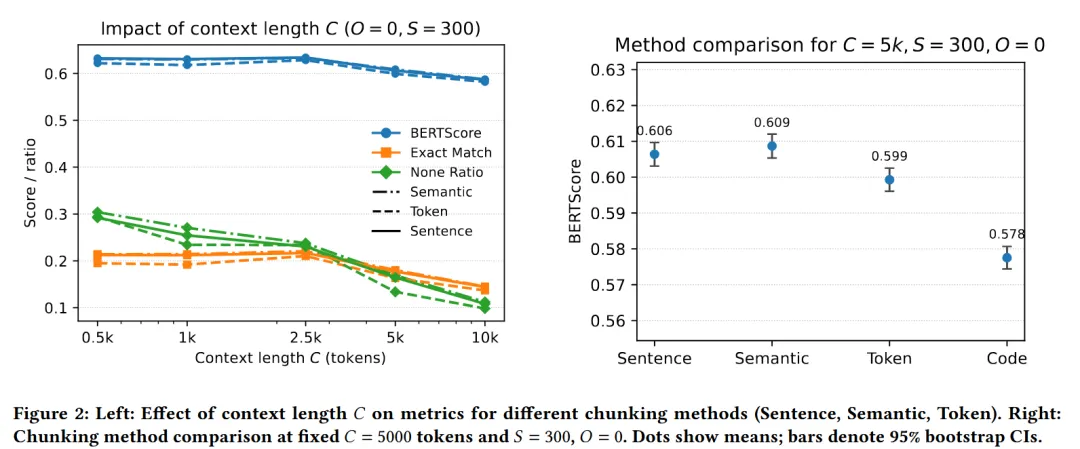
🔴 发现2:方法”层级”:Sentence ≈ Semantic > Token ≫ Code
- 性能对比
(C=5k, S=300): -
Sentence/Semantic:BERTScore ≈ 0.60–0.61 -
Token:0.58–0.59(-2–3%) -
Code:0.57(文本任务不适用) - 机制:保留句子边界的方法维持主题连贯性,减少跨句碎片化,同时提升检索精度和LLM接地能力
- 实践建议:
- 默认使用Sentence分块
(成本更低,性能匹配Semantic至~5k tokens) -
仅当C > 5k或文档高度论述性时考虑Semantic
🔴 发现3:”上下文悬崖”(Context Cliff)— 警惕过度填充
- 关键现象:性能在~2.5k tokens后非单调下降
-
Sentence分块(O=0, S=300):BERTScore在0.5k–2.5k稳定,10k时相对下降4–5% - 机制:
-
长上下文LLM易受干扰与冗余影响 -
大预算检索引入重叠/离题分块,稀释信号密度 - 实践建议:
- QA任务:C ≈ 2.5k tokens(EM峰值)
- 摘要/解释任务:C ≈ 500 tokens(语义忠实度峰值)
- 必须针对具体LLM重新调优(本研究基于Ministral-8B)
🔴 发现4:目标驱动的上下文调优
|
语义质量(摘要/解释) |
~500 tokens |
集中最相关证据,减少干扰 |
较高(~30%) |
|
事实准确性(事实型QA) |
~2.5k tokens |
增加跨分散提及的召回率 |
中等(~15%) |
|
最小化弃权 |
10k tokens |
最大化证据覆盖 |
最低(~11%) |
💡 关键洞察:弃权率可通过增大C和减小S调控——小分块增加检索多样性,大上下文提高证据召回
四、工业部署实用指南(表1精华)
|
重叠O |
0% |
无收益;降低索引成本25% |
|
分块器 |
Sentence |
在~5k tokens内匹配Semantic,计算更高效 |
|
分块大小S |
150–300 tokens |
平衡召回率与弃权(S过大会增加”无答案”) |
|
上下文C(QA) |
~2.5k tokens |
避免上下文悬崖;最大化EM |
|
上下文C(摘要) |
~500 tokens |
最大化语义忠实度 |
|
C > 5k时 |
考虑Semantic |
在超大上下文中有轻微优势 |
五、局限性与未来方向
|
未包含reranker |
有意排除以隔离分块效应 |
医学QA中,reranker可能显著提升精度,需权衡延迟成本 |
|
通用文本语料库 |
Natural Questions代表性有限 |
需在医学专业语料(如MIMIC-III)上验证分块策略 |
|
单模型评估 |
仅用Ministral-8B |
不同医学LLM(如Med-PaLM)可能有不同”上下文悬崖”点 |
未来工作:
-
针对医学文档的领域自适应分块(如按SNOMED CT概念边界) - 动态上下文预算:根据查询复杂度自适应调整C
- 多模态分块:联合处理文本+影像+时序数据
六、总结:分块是RAG可靠性的”第一公里”
论文核心贡献在于证明:分块是影响RAG可靠性的首要设计决策,其影响不亚于模型选择。在工业部署中:
“避免重叠、默认句子分块、根据任务调优上下文大小、警惕2.5k tokens后的性能悬崖” — 这四条原则已在客户-facing代理系统中验证,显著提升鲁棒性。
对于医学AI,这些原则需结合安全优先(高弃权容忍度)和结构感知(保留临床叙事连贯性)进行适配,但核心洞见普适:最优分块不是技术细节,而是可靠性工程的基石。