 夜雨聆风
夜雨聆风





7. AI Agent 是怎么调用工具的?一次讲透
正文
很多人第一次看到 Agent 自动搜索、自动查数据库、自动读文件时,都会下意识觉得:这个模型也太厉害了,什么都能做。
但真相是——
模型什么都没做,它只是说了一句话。
更准确地说,模型做了一件事:它输出了一段结构化的 JSON,大意是”请帮我调一下这个工具,参数是这些”。
然后呢?
真正去联网搜索的,不是模型。真正去读文件的,不是模型。真正去查数据库的,也不是模型。
是宿主程序拿着这段 JSON,帮它完成的。
如果你对这件事没有清晰认知,后面接工具、调模型、做 Agent 系统,很多坑你都不知道为什么会踩。
这篇文章,我们就把工具调用这件事,从头到尾拆开讲一次。
一、先说清一个大前提:模型是决策者,不是执行者
在工具调用这件事上,整个系统有两个核心角色:
- 模型
:负责理解任务,判断要不要用工具,用哪个,传什么参数 - 宿主程序
:负责真正执行工具,拿到结果,再送回给模型
你可以把它理解成:
模型是一个只会"下命令"的领导,宿主程序是那个真正去跑腿干活的人。
模型说:”帮我查一下今天北京的天气。”宿主程序拿着这个请求,去调天气 API,拿到结果,再告诉模型:”今天北京 22°C,晴。”
模型从头到尾没有接触过任何 API、任何网络请求、任何数据库连接。
这是理解工具调用最重要的一个基础认知。
你可以先看这张分工图:
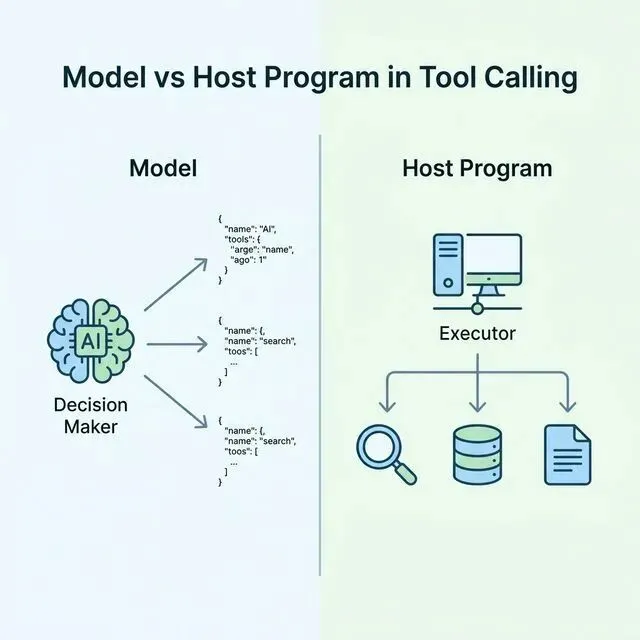
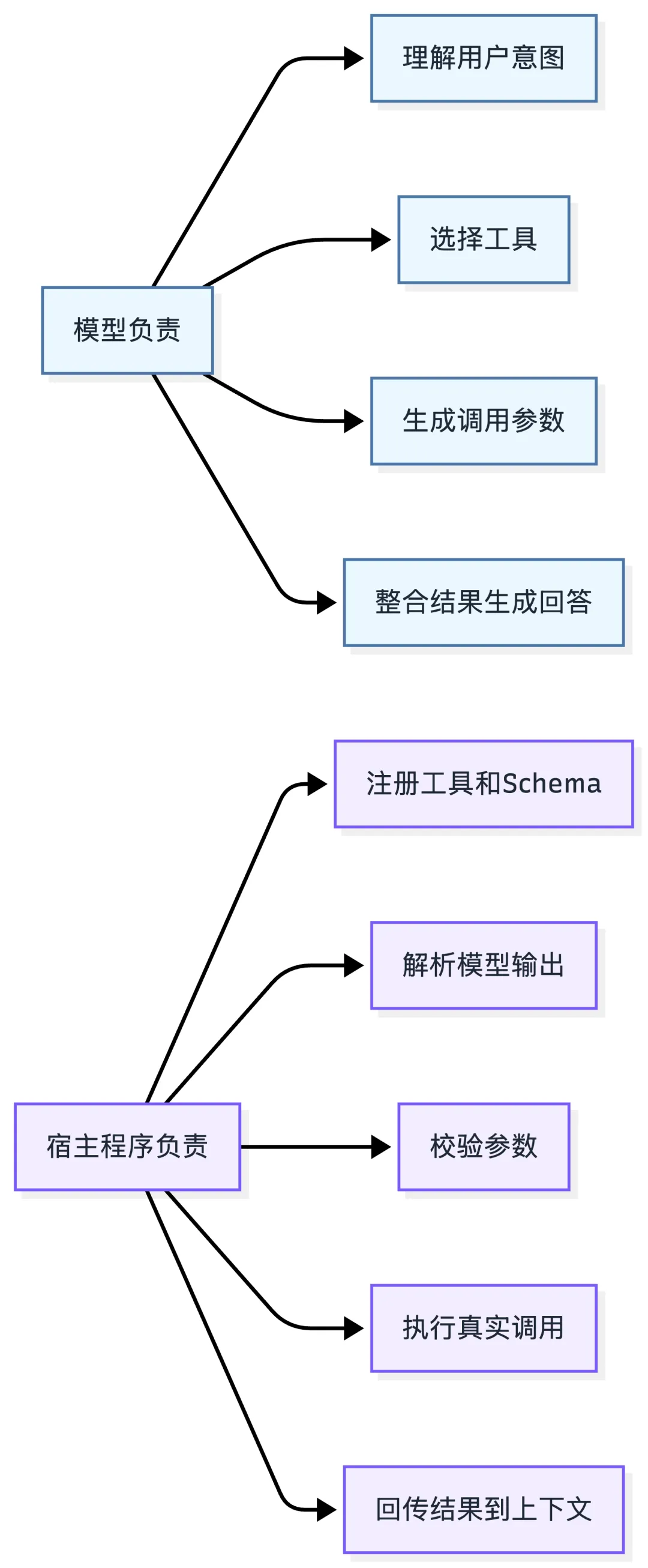
分工不清,后面所有工具相关的问题都会分析错方向。
二、一次工具调用,到底跑了哪几步
很多人听说过”Function Calling””Tool Calling”,但真让他讲清楚一次调用到底跑了几步,大多数人讲不完整。
我把它拆成 5 步:
第 1 步:注册工具——告诉模型”你手头有哪些工具”
在调用模型之前,你的宿主程序需要先告诉模型:你现在有哪些工具可以用。
怎么告诉?通过一段结构化的工具描述,通常叫 Schema。
一个典型的 Schema 长这样:
{ "type":"function", "function":{ "name":"get_weather", "description":"查询指定城市的当前天气信息", "parameters":{ "type":"object", "properties":{ "city":{ "type":"string", "description":"要查询天气的城市名称,比如'北京'" } }, "required":["city"] } }}注意几个关键字段:
name
:工具名字,模型靠它来选工具 description
:工具功能描述,模型靠它来判断”这个工具是干什么的” parameters
:参数定义,模型靠它来知道该传什么
这个 Schema 不是可有可无的补充说明,它几乎决定了模型能不能正确选到你的工具。
第 2 步:模型判断——要不要用工具,用哪个
当用户发来一个问题,模型会结合三方面信息做判断:
-
用户当前的任务目标 -
上下文中已有的信息 -
你注册的工具列表和 Schema
如果模型判断”这个问题我自己能答”,它就直接输出文本回答。
如果模型判断”这个问题我需要借助工具”,它会输出一段特殊格式的内容——不是普通文本,而是一段 JSON 格式的工具调用请求。
比如用户问”今天北京天气怎么样”,模型输出可能是:
{ "tool_calls":[{ "id":"call_abc123", "type":"function", "function":{ "name":"get_weather", "arguments":"{\"city\": \"北京\"}" } }]}注意:这不是模型在执行天气查询,这只是模型在告诉你——”我觉得应该调 get_weather,参数是北京。”
第 3 步:宿主程序执行——真正跑工具
宿主程序拿到模型输出的 JSON 后,做这几件事:
- 解析
:看模型想调哪个工具,传了什么参数 - 校验
:参数合不合法、类型对不对、有没有漏必填项 - 执行
:调用真正的工具函数或 API - 拿结果
:获取工具的返回值
这一步完全是宿主程序的活,和模型没有任何关系。
用伪代码看,大概是这样:
# 解析模型输出tool_name = response.tool_calls[0].function.namearguments = json.loads(response.tool_calls[0].function.arguments)# 根据工具名分发执行if tool_name == "get_weather": result = get_weather(city=arguments["city"])# result = "北京,22°C,晴,东南风3级"第 4 步:结果回传——把工具输出送回模型
这一步非常关键,很多人忘了做。
工具执行完后,宿主程序需要把结果以 tool 角色的消息,追加到对话上下文里,再次发给模型。
messages.append({"role": "tool","tool_call_id": "call_abc123","content": "北京,22°C,晴,东南风3级"})# 再次调用模型final_response = client.chat.completions.create( model="gpt-4", messages=messages)只有这样,模型才能看到工具的执行结果,然后基于结果继续推理、组织最终回答。
如果你没做这一步,模型就不知道工具执行了什么,最终回答可能是编造的。
第 5 步:循环或终止
模型看到工具结果后,会再次判断:
-
信息够了吗?如果够了,生成最终文本回答 -
还需要更多工具吗?如果需要,再输出一轮工具调用请求
这就是为什么工具调用是一个闭环,不是一次性触发。
你可以看这张完整流程图:
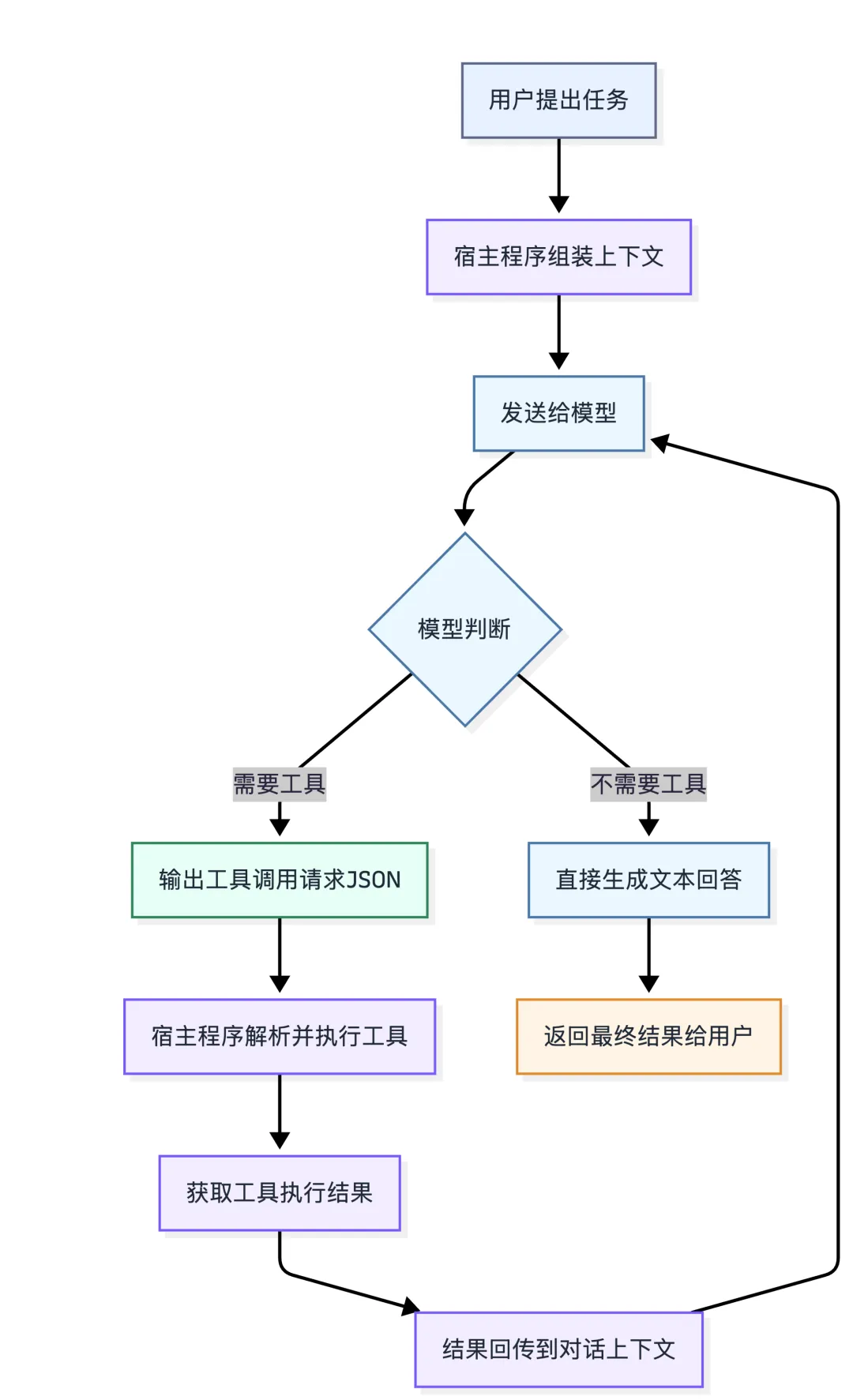
这 5 步跑完,就是一次工具调用的完整生命周期。
三、Function Calling 和 Tool Calling 到底是什么关系
很多人会被这两个名词搞晕,其实非常简单。
Function Calling
这个名字是 OpenAI 在 2023 年 6 月推出 GPT-3.5/GPT-4 API 时首次使用的。
当时的设计是:你在 API 调用里传一组 functions 参数,模型可以选择输出一个函数名和参数 JSON。
但它有个限制:一次只能调一个函数。
Tool Calling
这是 OpenAI 在 2023 年底推出的升级版。
主要变化:
-
参数字段从 functions改为tools -
支持一次调用多个工具(Parallel Tool Calling) -
工具类型可以扩展(不只是 function,未来可能有 code_interpreter、retrieval 等)
本质上的关系
Tool Calling 是 Function Calling 的演进版本。
底层机制完全一样:模型输出结构化 JSON → 宿主程序执行 → 结果回传。
只是接口更规范了,能力更强了。
目前 OpenAI、Anthropic、Google、Mistral 等主流模型提供商都采用了 Tool Calling 的设计。所以你后面再看到这两个词,不用纠结,它们说的是同一件事。
四、模型到底是怎么”选”工具的
这个问题很多人好奇但很少有人讲清楚。
模型选工具,不是”开盲盒”,它有明确的判断依据。
判断依据 1:工具名称
名称越清楚、越贴近功能语义,模型越容易做对判断。
好的工具名:search_web、get_weather、read_file不好的工具名:tool_1、helper、do_stuff
判断依据 2:工具描述
这是最重要的判断依据。
模型是根据你写在 description 里的文字来理解这个工具”能干什么”的。
如果描述模糊,比如”一个有用的工具”,模型根本不知道什么时候该用它。
推荐做法:用一句清楚的话写明工具的用途、适用场景和输入输出。
比如:
-
✅ 查询指定城市的实时天气信息,返回温度、天气状况和风向 -
❌ 天气相关的工具
判断依据 3:参数说明
每个参数的名称、类型、描述、是否必填,都会影响模型传参的准确性。
"city":{"type":"string","description":"要查询天气的城市名称,比如'北京'、'上海'"}参数描述越具体,模型传参越准确。参数描述越模糊,模型越容易猜错。
判断依据 4:上下文和任务目标
模型还会结合当前的对话历史、系统 Prompt 中的指令来做判断。
比如系统 Prompt 写了”优先使用搜索工具获取最新信息”,模型在遇到时效性问题时就会倾向于调搜索工具。
五、用一个真实例子,跑一遍完整链路
场景:用户对 Agent 说——
帮我查一下今天北京的天气,然后根据天气给我一个穿搭建议。
第一轮
模型判断:我需要查天气,但我自己不知道实时天气 → 调 get_weather 工具。
模型输出:
{ "tool_calls":[{ "function":{ "name":"get_weather", "arguments":"{\"city\": \"北京\"}" } }]}宿主程序执行:调用天气 API → 返回 "北京,22°C,晴,微风"
结果回传:把天气信息追加到上下文。
第二轮
模型看到天气结果:北京今天 22°C,晴,微风。
模型判断:信息够了,我可以直接给穿搭建议了,不需要再调工具。
模型输出:
今天北京 22°C,天气晴朗,微风。建议穿一件薄外套或长袖衬衫,搭配休闲裤即可。如果中午出门,外套可以不带。
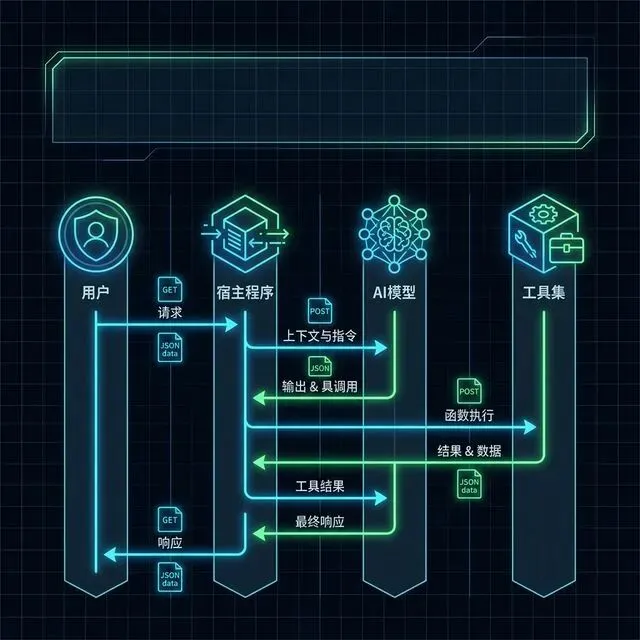
看到没?整个过程就是:
-
模型判断需要工具 → 输出 JSON -
宿主执行 → 拿到结果 -
结果回传 → 模型继续推理 -
模型判断不需要更多工具 → 输出最终回答
这就是工具调用的完整闭环。
你可以用这张时序图更清楚地看到四个参与者的交互:
六、最常见的工具调用踩坑和根因分析
工具调用看起来不复杂,但实际接的时候坑不少。
我把最常见的几类列出来,附带根因分析。
坑 1:模型不调工具,直接瞎答
表现:明明有搜索工具,模型却不调,直接编了一个答案。
根因:工具描述太模糊,或者系统 Prompt 没有强调”先查证再回答”。
处理:优化 Schema 的 description;在 Prompt 中加入”遇到事实性问题优先使用工具”。
坑 2:模型调错工具
表现:有 3 个工具,模型选了功能不对的那个。
根因:多个工具的 description 存在语义重叠,模型分不清。
处理:让每个工具的 description 尽量各自独立,不要写出”都能做这件事”的模糊表述。
坑 3:模型传错参数
表现:参数类型不对、值乱传、必填项漏了。
根因:参数的 type、description、required 没写清楚。
处理:给每个参数加清楚的 description 和 example;在宿主程序中做参数校验。
坑 4:工具结果没回传
表现:工具明明执行了,但模型最终回答时像没看到结果。
根因:宿主程序没有把工具返回值以 tool 角色消息追加到上下文。
处理:确保每次工具执行后,结果都回传到 messages 列表中,然后再调模型。
坑 5:工具太多,模型选择困难
表现:注册了 20 多个工具,模型经常选不准。
根因:工具数量超过模型的有效管理范围。
处理:控制单次上下文中的工具数量;对工具做分组,按任务阶段动态加载。
踩坑自检清单
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
七、那工具 Schema 到底该怎么写
如果这篇文章你只记住一件事,那就是:
工具调用的质量,70% 取决于 Schema 的质量。
一个好的 Schema 应该满足:
- 工具名清晰
:用动词 + 名词的组合,比如 search_web、read_file、send_email - 描述精确
:一句话说明用途、适用场景、返回什么 - 参数完整
:每个参数有 type、description、required - 边界明确
:说清楚这个工具不能做什么、什么情况下不应该调它
示例:
{ "type":"function", "function":{ "name":"search_web", "description":"在互联网上搜索指定关键词的最新信息。适用于用户询问实时事件、新闻、数据等情况。返回搜索结果摘要列表。", "parameters":{ "type":"object", "properties":{ "query":{ "type":"string", "description":"搜索关键词,比如'2024年诺贝尔奖获得者'" }, "max_results":{ "type":"integer", "description":"最多返回的结果条数,默认5,最大20" } }, "required":["query"] } }}八、从上一篇文章到这篇,认知是怎么串起来的
上一篇我们讲了 Prompt 在 Agent 里的真正作用。
当时一个核心结论是:
Prompt 负责告诉 Agent 应该怎么做,系统负责保证 Agent 真能做到。
这篇文章讲的”工具调用”,恰好就是”系统保证 Agent 能做到”的第一个关键能力。
-
Prompt 可以写”先查证再回答”,但真正去查的能力,是工具提供的 -
Prompt 可以写”用表格输出”,但真正拿到数据的能力,也是工具提供的 -
Prompt 可以写”缺信息时先补”,但真正补信息的能力,还是工具提供的
所以你可以这样理解两篇文章的关系:
Prompt 是操作手册,工具是实际装备。手册再好,没有装备也做不了事。
九、总结
如果把这篇文章浓缩成几句话:
模型不执行工具,它只输出调用请求。真正执行的是宿主程序。工具调用是一个闭环:判断→请求→执行→回传→继续推理。工具调不好,大多不是模型的问题,而是 Schema 没写好。Function Calling 和 Tool Calling 本质一样,后者是前者的演进。
后面我们还会讲记忆、规划、多 Agent 协作那些更复杂的能力。
但工具调用是 Agent 从”只会说话”到”真能做事”的第一步。
如果这一步没接好,后面所有链路都建不稳。
这篇文章先把工具调用的机制拆清楚。