 夜雨聆风
夜雨聆风





为什么英伟达的护城河是软件,不是芯片
引言
做 Android 开发做久了,对一种东西会有种直觉——就是”生态”这两个字到底意味着什么。🧐
它不是某个 API 好不好用的问题。而是当一群人在一个平台上写了足够久的代码,积累了足够多的经验和社区资源之后,大家就很难搬走了。哪怕旁边出了一个更新的平台、硬件更便宜,绝大多数人也不会真的动。
这种感觉一开始只在 Android 上面有。
后来有一天翻英伟达的资料,越看越觉得奇怪——怎么 CUDA 的生态运转方式,跟在 Android 里感受到的几乎一模一样?
两个飞轮长得几乎一样
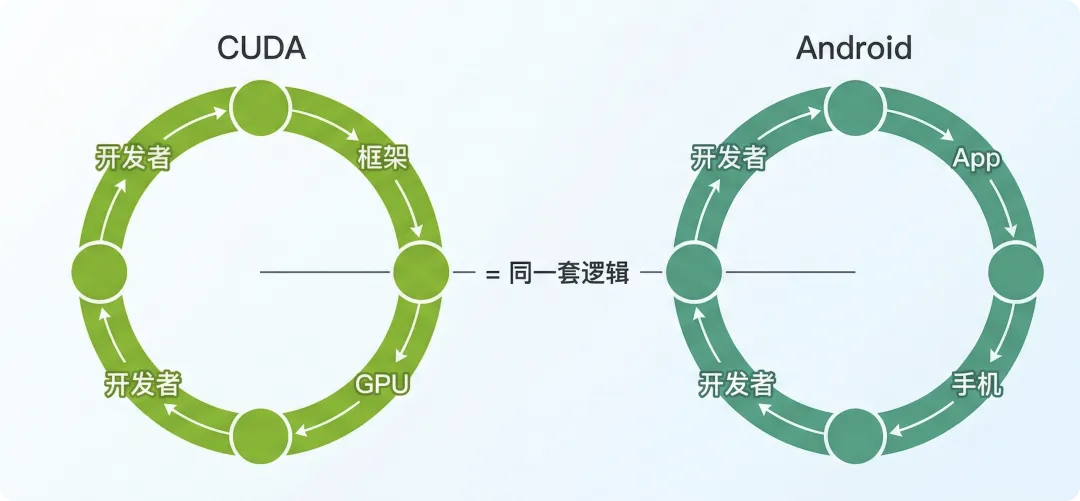
Android 的飞轮大家都见过:
“
开发者写 app → 用户买 Android 手机 → 厂商预装更多 app → 更多开发者进来。
”
当年 Windows Phone 也试过打破这个循环,硬件也不差,但开发者就是不来,最后没做起来。
CUDA 那边,飞轮长得差不多:
“
开发者用 CUDA 写 AI 代码 → PyTorch、TensorFlow 默认为 CUDA 做优化 → NVIDIA 的 GPU 更好卖 → 更多开发者继续选 CUDA。
”
数量上也蛮接近的。CUDA 开发者大约 600 万,Android 开发者大约 700 万,算是同一个量级。👀
有意思的是,两个飞轮都有一个共同点:很多开发者不是自己主动选的平台——是框架替你选的。Android 上,Google Play Services 把很多能力绑在了 Google 生态里。CUDA 上,PyTorch 默认走 CUDA backend,大部分人装好环境就直接用了,不会特意去想”我要不要换个平台”。
不过有一个地方不太一样。Android 的硬件端有成百上千个厂商,碎片化是老问题。而 NVIDIA 自己控制所有 GPU 型号。它同时拥有 Android 级别的开发者数量,和 Apple 级别的硬件控制力。这个组合放在一起,确实不太好打。
写 Android 的人看这张表,应该会觉得眼熟
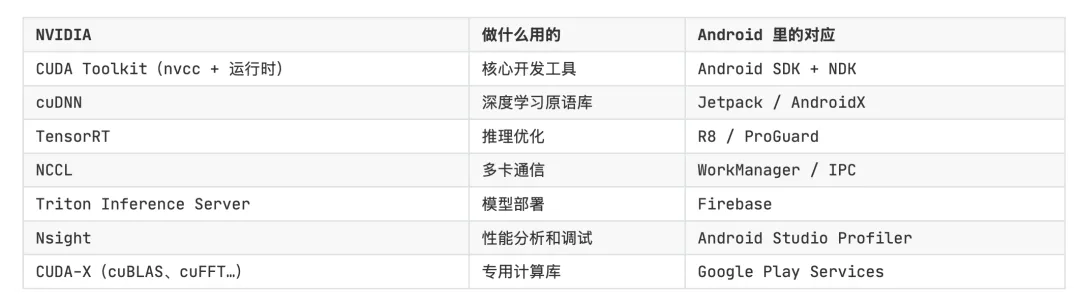
层层都能对上,不是硬套的。
连兼容性模型也像。CUDA 有个东西叫 Compute Capability(SM_70、SM_80、SM_90),决定代码能不能用新特性,和 Android 的 API Level(minSdkVersion / targetSdkVersion)思路一样。两边都做了向后兼容——老代码跑在新硬件上不会挂。
碎片化方面倒是 NVIDIA 更舒服一些。Android 几千种设备配置,适配是日常。而 NVIDIA 自己就那么几款 GPU,写 CUDA 的人基本不用担心兼容问题。
还有一个数据可以感受一下:英伟达大概 36000 名员工里,约 75% 的人在写软件。差不多 27000 人。
一家我们通常叫”芯片公司”的企业,四分之三的人干的活和我们一样——写代码。😂
说白了,英伟达跟 Google 做 Android 的思路挺像的。Google 其实是广告公司,但它养了一个庞大的工程团队来维护 Android。英伟达其实是软件公司,只不过它最终变现的方式是卖芯片。SDK 才是核心产品,芯片更像是 SDK 的硬件载体。
为什么”5% 代码改动就能迁”这句话靠不住
AMD 有个迁移工具叫 HIP,官方说从 CUDA 迁到 ROCm,代码改动不到 5%。
但凡写过 Android 的人,都知道这种”理论上能迁”是怎么回事。一个用了 Camera2、MediaCodec 硬编解码、自定义 View、还带 NDK JNI 的 app,你让它迁到别的系统上?Java/Kotlin 那层或许还行,但凡涉及平台 API 的部分,每一处都是坑。
CUDA 也差不多。简单的矩阵运算可能迁得动,但一旦碰到自定义 kernel、特定的显存访问优化、或者深度依赖 cuBLAS/cuDNN 的调用链,工作量就不是”5%”能概括的了。
所以 AMD MI300 系列便宜 20-30%,性能评测也不差,但 NVIDIA 的市占率还是 92%。📈
不是芯片不行,是那 20 年积累下来的代码资产、社区厚度、框架绑定和开发者习惯,搬不动。
英伟达的对手们,翻译成 Android 语言就很好懂
AMD ROCm,大概对应 Tizen 或 HarmonyOS 的位置。硬件能力不差,Meta 和微软也在用 MI300。但生态厚度跟 CUDA 差得远。当年 Tizen 有三星全球出货量撑着,开发者还是不来。ROCm 现在面对的局面,感觉也是类似的。
Google TPU,更像 iOS 的路线。自己的芯片、自己的框架(JAX)、自己的云,封闭但内部很强,拿下了 58% 的定制云 AI 加速器市场。不过它不开放给所有人。Google 最近有个 TorchTPU 项目,让 PyTorch 代码能直接跑在 TPU 上,这算是第一次在开源层面认真试着撬 CUDA。能不能成还要再看。
Amazon Trainium,对应 Fire OS。主要给自家用——Anthropic 的 Project Rainier 用了 40 万颗 Trainium2——但外面基本没人用。有一组数据是 2024 年 4 月泄露的:AWS 内部 Trainium 的使用量,只有 NVIDIA GPU 用量的 0.5%。
那英伟达是不是就没人能挑战了?也不能这么说。🤔
Google TorchTPU 如果真做成了,PyTorch 开发者迁到 TPU 的摩擦力会大幅下降。AMD MI450(2026 Q3)也在靠近。所有大客户都在自研芯片想降低依赖。
但目前来看,这些挑战者遇到的困难,和当年 Android 的挑战者遇到的困难结构上是同一种:硬件不是问题,生态才是真正的门槛。
71% 毛利率,一种很安静的平台垄断
说一个数字吧。
英伟达的毛利率大约 71%。FY2026 全年收入 2159 亿美元,数据中心占了 1940 亿。
71% 是什么感觉呢?Google Play 抽成 30%(小开发者 15%),全球开发者已经骂了很多年,反垄断官司到现在还没打完。而英伟达在每一块 GPU 上抽走 71%,声音小得多。🤫
因为确实没什么能替代它。
AMD 便宜 20-30%,但 CUDA 在实际任务上性能还是高出 18-27%。这个差距不是来自芯片本身,而是 20 年软件打磨的结果——TensorRT 对推理的加速、cuDNN 对训练的优化、Nsight 对瓶颈的定位,每一层都在为那 71% 提供支撑。
写到最后,一开始看英伟达,以为它是一家芯片公司,和高通、AMD 是同一类选手。后来越看越觉得不对——它做的事情跟 Google 做 Android 更像。用软件生态吸引开发者,用开发者锁定硬件销量,再用硬件的利润回来继续喂生态。飞轮转得越久,别人越难进来。
而这个逻辑里真正值得想一想的也许是:当我们说一家公司有”护城河”,到底在说什么?是某款芯片跑分领先 20%,还是有 600 万人把自己的代码、经验和职业习惯都绑在了这个平台上?
如果是后者,那这个护城河的深度,远比大多数人以为的要深。
这一点,我想作为一个工程师,应该比谁都更清楚。🍃🍃