 夜雨聆风
夜雨聆风





AI 时代的软件工程:架构与驾驭 (Harness Engineering)
一、一个反直觉的现象
AI 让写代码变便宜了。但软件项目,并没有因此变简单。
数据很直接。Harness 2026 年对 700 名工程师的调查显示,在每天多次使用 AI 编程工具的开发者里,51% 反映代码质量问题变多了,53% 反映安全漏洞事件增加。更关键的是,近 80% 的软件故障发生在编码完成之后——CI/CD 流水线是最大的肇事方。
AI 加速了代码生产,但测试、部署、安全审查这些环节并没有同步跟上。
结果不是系统变简单了,而是速度把混乱放大了。
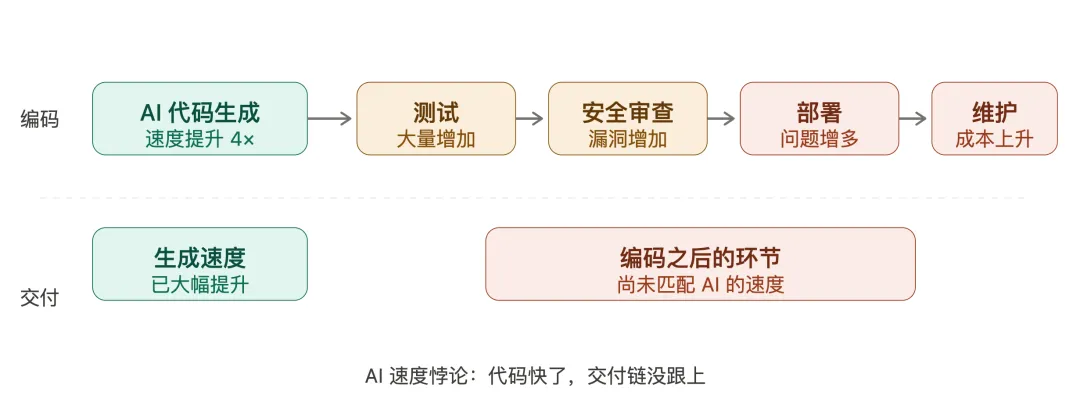
上面这张图描述的,就是这个悖论的结构。
二、架构为什么在 AI 时代反而更重要
很多人直觉上会觉得,AI 会写代码了,架构设计的重要性应该下降。
恰恰相反。
过去讲整洁架构,核心是解决一个经典问题:系统怎么在持续变化里,还能保持稳定。所以才强调分层、边界、依赖方向,让业务规则内聚,让变化快的东西(数据库、框架、UI)待在外围。
这套逻辑的服务对象,主要是”人”。
人有很多补偿能力。文档没写全可以问同事,目录有点乱老员工靠经验也能摸出来,隐含规则靠口头传承也能维持一阵。
AI 没有这些补偿能力。
它会读代码、读文档、执行任务,但对系统的理解高度依赖你有没有把规则明确表达出来。你不写清楚,它只能猜。一旦开始猜,系统就会悄悄变形——而且这种变形通常不是功能错误,代码能跑,测试也能过,但边界松了,依赖乱了,复杂度被悄悄转移了。
所以架构在 AI 时代承担了一个新任务:
不仅要方便人协作,还要让 AI 少犯结构性错误。
三、什么是 Harness Engineering
2026 年 2 月,OpenAI 发布了一篇内部实践文章,介绍了他们用 Codex 代理驱动开发的完整经验,并把这套方法叫做 Harness Engineering。
核心数据很惊人:从空仓库开始,5 个月内生产近百万行代码,3 名工程师平均每人每天合并 3.5 个 PR。更关键的是,团队的核心哲学是人不直接写代码,工程师的工作变成了:为 AI 构建它能在其中工作的环境。
几乎同期,Thoughtworks 的 Birgitta Böckeler 在 martinfowler.com 发布了对这个概念更系统的框架解释。她的定义简洁:
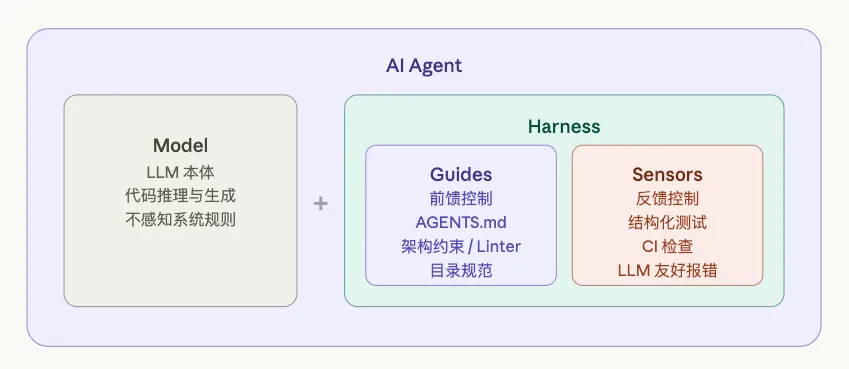
Agent = Model + Harness
Harness,就是 AI Agent 除模型本身以外的一切。
两者讲的是同一件事:当你把代码生成交给 AI,真正的工程工作,是构建让 AI 能够可靠工作的那套系统。
四、Harness 的两个核心机制
Thoughtworks 的框架把 Harness 拆成两类控制:
Guides(前馈控制)
在 Agent 行动之前预先引导,提高它第一次就做对的概率。
具体包括:AGENTS.md 这类说明文档,告诉 AI 项目的结构规则和约束;自定义 Linter,把架构边界变成机器可检查的约束;目录规范和依赖限制,让 AI 知道哪些层不能直接互调,哪些对象不能跨边界传递。
Sensors(反馈控制)
在 Agent 行动之后观察结果,让它能够自我修正。
包括结构化测试、CI 检查、可观测性信号。特别重要的一点是:这些反馈信号要对 LLM 友好——错误提示里最好直接包含修正建议,而不只是报一个错误码让 AI 自己去猜。
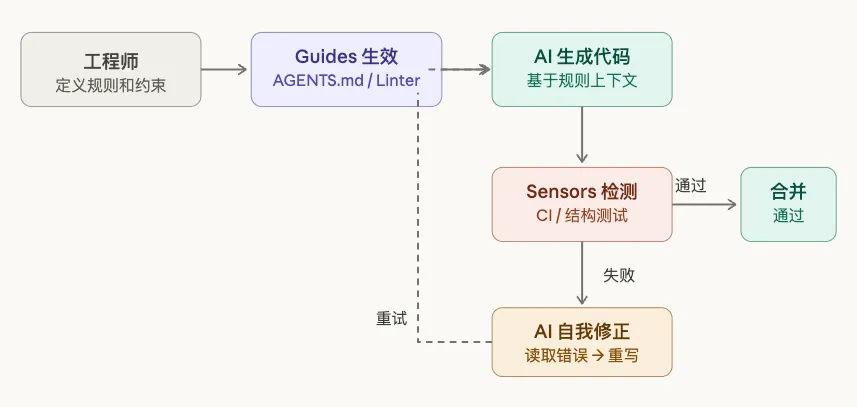
两者缺一不可。
只有 Guides 没有 Sensors:AI 编码了规则,但永远不知道规则有没有被遵守。 只有 Sensors 没有 Guides:AI 一直在犯同样的错误,然后修,然后再犯。
下面这张图展示完整的控制回路:
五、一个具体场景:电商订单系统的演进
抽象讲完了,来看一个真实感更强的案例。
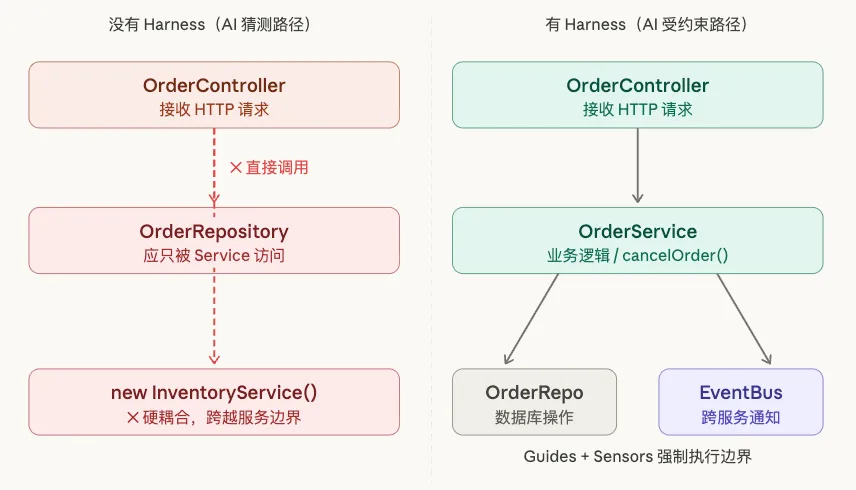
假设你在开发一个电商平台,核心是订单模块。架构上定了三层:OrderController(接收请求)→ OrderService(业务逻辑)→ OrderRepository(数据库操作)。同时,订单完成后要通知库存服务和支付服务,这两个都必须走事件总线(EventBus),不能直接调用。
这套分层规则团队内部都清楚,但从来没有写下来过。
没有 Harness 的情况
某天,新需求来了:取消订单时,要同时回滚库存、退款,并发通知。任务交给 AI 来补充这个功能。
AI 拿到 controller 和 repository 的代码,看到两者都在,于是直接在 OrderController 里调用了 OrderRepository.updateStatus(),同时直接 new InventoryService().rollback() 而不是走事件总线。代码能跑,测试也过了。但从架构角度看:
-
Controller 绕过了 Service 层,把业务逻辑泄漏进来 -
直接依赖 InventoryService,跨越了服务边界,未来 InventoryService 一改接口,这里立刻爆
这种错误不会立刻炸,但会在三个月后、五个人接触过这段代码之后,悄悄成为一个无人敢动的黑洞。
有 Harness 的情况
同样的需求,同样的 AI,但仓库里多了两件东西。
第一件:AGENTS.md(Guide),里面写明:
Controller 层不能直接调用 Repository;跨服务通信必须通过 EventBus;不得
new实例化外部服务。
第二件:一个架构检查脚本(Sensor),挂在 CI 里,只要检测到 Controller 直接引用 Repository,或者出现 new InventoryService(),立刻报错,且错误信息直接写:
违规:OrderController 不应直接依赖 OrderRepository,请通过 OrderService 调用。参考:OrderService.cancelOrder()
AI 第一次生成了错误代码,CI 触发,AI 读到错误信息,自己修正,把逻辑挪进 OrderService,通知改成通过 EventBus.publish()。人工 Review 只需确认业务逻辑是否完整,不再需要 check 架构边界有没有被破坏。
六、它和架构的关系
Harness Engineering 不是一个和架构设计并列的新理论。
更准确的理解是:
-
架构回答”系统该怎么设计” -
Harness 回答”设计之后,怎么让它守得住”
OpenAI 团队发现了一个细节:AI 会复制仓库里已有的模式,包括那些不好的模式。随着时间推移,这种”漂移”会越来越明显。他们的解法是把”黄金原则”直接编码进仓库,并建立定期清理”AI slop”的机制。
这和《架构整洁之道》强调的核心没有本质区别——都是在处理复杂系统如何长期保持秩序。只不过守秩序的方式,从”人来守”变成了”系统来守”。
以前,一个优秀工程师的价值,很大一部分体现在他脑子里装着这套秩序,能在代码 Review 时把守边界。现在,这套秩序必须外化成文档、脚本、测试,让人和 AI 都能遵守,不依赖任何一个人的经验。
七、对工程师意味着什么
AI 会让很多编码工作继续降价,这几乎是确定的。
但工程师的价值不会消失,它会重新分布。
以后更稀缺的能力,不是单点实现能力,而是:
-
能不能把系统边界梳理清楚 -
能不能把模糊的团队规则变成明确的机器约束 -
能不能设计出可靠的验证闭环 -
能不能让系统越迭代越清晰,而不是越做越黏
这些能力以前就重要,只是现在会更快地体现出差距。
原因很简单:AI 会放大一个团队原本的工程水平。
工程底子好,AI 是放大器。工程底子差,AI 也是放大器。
代码更容易有了,好系统反而更难了。
这可能是 AI 编程时代,最值得认真对待的一个现实。