 夜雨聆风
夜雨聆风





微软开源了一个很好用的工具,PDF、Word、PPT 一键转换
前言
在做 AI 应用开发的时候,有个问题经常被忽略,但其实特别烦。
要交给 AI 处理的文件,可能是 PDF、Word、PowerPoint、Excel,甚至还有图片和音频,但大模型( LLM )最喜欢的是纯文本或者 Markdown。
这中间有个“格式差”,以前基本都要自己写脚本或者装一堆工具来转。
详细介绍
现在微软直接把这个问题解决了,开源了一个叫 MarkItDown 的 Python 工具,说白了就是“万能转 Markdown 工具”。
一行命令就能把各种文件转成 LLM 能直接用的格式,目前在 GitHub 上已经超过 4.8 万星,热度很高。
MarkItDown:把 PDF、Word、PPT 一键转成 AI 能看懂的 Markdown
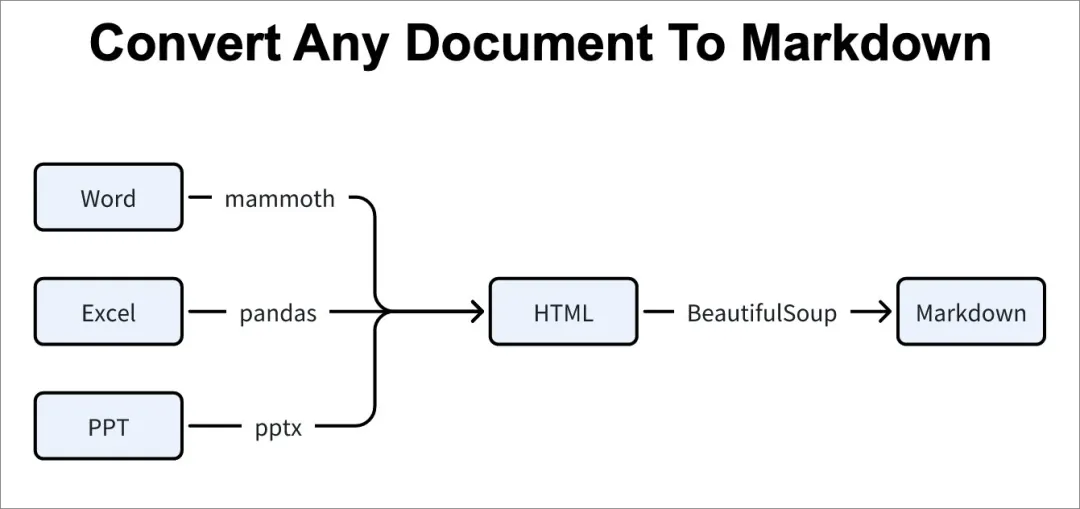
支持的格式多到离谱,MarkItDown 最厉害的地方,就是支持的文件类型特别多:
-
办公文件:PDF、Word( DOCX )、PowerPoint( PPTX )、Excel( XLSX / XLS )
-
网页内容:HTML,或者直接丢 URL
-
图片文件:JPG、PNG(可以配合 OCR 识别文字,或者用 AI 生成图片描述)
-
音频文件:WAV、MP3(自动转文字)
-
数据格式:CSV、JSON、XML
-
其他:ZIP 压缩包(自动解压再转换)、Outlook 邮件、YouTube 视频(提取字幕)、EPub 电子书
而且在转换的时候,会尽量保留原本结构,比如标题层级、表格、列表、超链接这些,都会变成对应的 Markdown 格式,不会变成一堆乱文本。
安装和使用也很简单
安装只要一行命令:
pip install 'markitdown[all]'如果只需要部分功能,也可以按需安装,这样可以少装一些依赖。
pip install 'markitdown[pdf,docx,pptx]用起来也很简单,命令行直接:
markitdown 报告.pdf -o 报告.md或者在 Python 里这样用:
from markitdown import MarkItDownmd = MarkItDown()result = md.convert("文件.docx")print(result.markdown)
就这么几行代码,就能把一个 Word 文件转成干净的 Markdown。
进阶玩法:配合 AI 更强
MarkItDown 不只是格式转换,还能配合 AI 做更多事情:
-
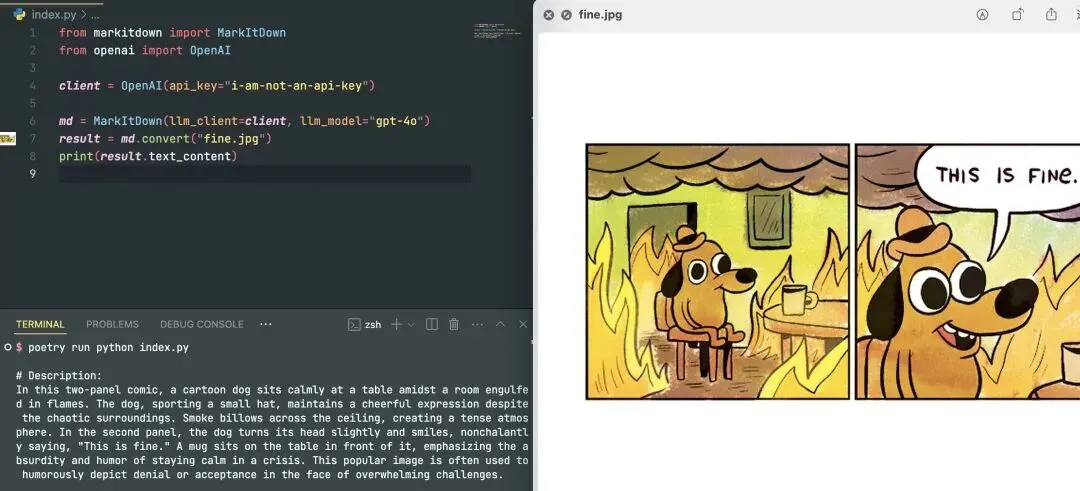
图片 AI 描述:配合 OpenAI 的视觉模型,可以自动给图片生成描述,让 AI 能理解图片内容(需要 API Key)。
-
OCR 识别:整合 Azure Document Intelligence,可以从扫描件或者图片里提取文字。
-
MCP 支持:原生支持 Model Context Protocol,可以直接接入 Claude Desktop 等支持 MCP 的工具。
-
插件系统:支持自定义插件,可以自己写规则处理特殊格式。
实际能用在哪
这个工具能用的地方挺多,比如:
-
喂 AI 文件:把 PDF 报告、PPT、Excel 全部转成 Markdown,再丢给 ChatGPT 或 Claude 去分析。有开发者测试过,先转换再喂,最多能省 80% 的 Token。
-
做知识库:批量转文件,然后丢进向量数据库,做 RAG(检索增强生成)。
-
自动化流程:在 AI Agent 流程里当预处理,让 Agent 能读各种文件。
-
会议记录:把录音转文字再转 Markdown,自动整理结构化会议纪要。
也不是万能的
当然,这工具也不是完美的。
复杂图表、可视化内容转换效果一般,排版特别复杂的文档也可能丢细节。
它本质是“快速提取文本给 AI 用”,如果需要的是高度还原排版,那像 Pandoc 这种工具可能更合适。
但如果只是想让 AI 能读懂内容,那 MarkItDown 已经很好用了。
安装也很简单,把 GitHub 地址丢给 Agent,让它自己装就行。
总结:AI 时代的文件瑞士军刀
Microsoft 这个 MarkItDown,其实就是解决一个很实际的问题:让 AI 能顺畅读取各种格式的文件。
免费开源、安装简单、支持格式多,还能配合 AI 做更高级的处理。
如果平时经常要把文件交给 AI 处理,这工具基本可以直接收进工具箱里了。
为小妹转发和点赞
如果您喜欢小妹的分享,请点击文章末尾的点赞、分享、在看,这对您来说不会花费太多时间,但是对小妹的成长有很大的帮助,谢谢您的支持!
